1. Introduction
Ollama Official Website: https://github.com/ollama/ollama Ollama is an open-source platform for artificial intelligence (AI) and machine learning (ML) tools, specifically designed to simplify the deployment and usage process of large language models (LLMs). Users can conveniently run various large language models locally, such as Llama 2 and other open-source models, using Ollama. The main advantages and features of this tool include:
-
Ease of Use: Provides a simple interface similar to the OpenAI API, allowing users to quickly get started and call models for content generation, and also includes a chat interface similar to ChatGPT for direct interaction with the model. -
Cross-Platform Support: Supports macOS, Linux, and Windows operating systems, enabling users to run large language models locally across different platforms. -
Model Management and Deployment: Ollama integrates model weights, configurations, and data into a package called Modelfile. With optimized Docker container technology, users can deploy and manage LLMs locally with a single command. It supports hot-swapping of models, making it flexible and adaptable. -
Efficiency: It significantly reduces the hardware requirements and technical barriers needed to use large language models, allowing more developers and researchers to quickly access and utilize advanced AI technologies. -
Flexibility: In addition to supporting pre-trained models, Ollama also allows users to customize and create their own models. In summary, Ollama is a tool aimed at promoting AI democratization, simplifying the deployment and usage process, enabling more people to run complex large language models on personal computers, thus advancing the widespread adoption and innovative application of AI technologies.
2. Installation
2.1 Installation
Official Documentation: https://github.com/ollama/ollama/blob/main/docs/linux.md
curl -fsSL https://ollama.com/install.sh | shAfter completing the installation, the Ollama service generally starts automatically and is set to start at boot. After installation, you can use the following command to check if Ollama is running properly. If it shows “Active: active (running)” as in the example below, it indicates that Ollama has started normally.
[root@localhost ~]# systemctl status ollama
● ollama.service - Ollama Service
Loaded: loaded (/etc/systemd/system/ollama.service; enabled; vendor preset: disabled)
Active: active (running) since Sun 2024-04-07 11:26:30 CST; 1 day 21h ago
Main PID: 4293 (ollama)
CGroup: /system.slice/ollama.service
└─4293 /usr/local/bin/ollama serve
Apr 07 11:26:30 localhost.localdomain ollama[4293]: time=2024-04-07T11:26:30.908+08:00 level=INFO source=payload_common.go:113 msg="Extracting dynamic libraries to /tmp/ollama3707241284/runners ..."
Apr 07 11:26:36 localhost.localdomain ollama[4293]: time=2024-04-07T11:26:36.058+08:00 level=INFO source=payload_common.go:140 msg="Dynamic LLM libraries [cpu_avx2 rocm_v60000 cpu_avx cpu cuda_v11]"
Apr 07 11:26:36 localhost.localdomain ollama[4293]: time=2024-04-07T11:26:36.059+08:00 level=INFO source=gpu.go:115 msg="Detecting GPU type"
Apr 07 11:26:36 localhost.localdomain ollama[4293]: time=2024-04-07T11:26:36.059+08:00 level=INFO source=gpu.go:265 msg="Searching for GPU management library libcudart.so*"
Apr 07 11:26:36 localhost.localdomain ollama[4293]: time=2024-04-07T11:26:36.062+08:00 level=INFO source=gpu.go:311 msg="Discovered GPU libraries: [/tmp/ollama3707241284/runners/cuda_v11/libcudart.so.11.0]"
Apr 07 11:26:36 localhost.localdomain ollama[4293]: time=2024-04-07T11:26:36.063+08:00 level=INFO source=gpu.go:340 msg="Unable to load cudart CUDA management library /tmp/ollama3707241284/runners/cuda_v11/libcudar...it failure: 35"
Apr 07 11:26:36 localhost.localdomain ollama[4293]: time=2024-04-07T11:26:36.064+08:00 level=INFO source=gpu.go:265 msg="Searching for GPU management library libnvidia-ml.so"
Apr 07 11:26:36 localhost.localdomain ollama[4293]: time=2024-04-07T11:26:36.066+08:00 level=INFO source=gpu.go:311 msg="Discovered GPU libraries: []"
Apr 07 11:26:36 localhost.localdomain ollama[4293]: time=2024-04-07T11:26:36.066+08:00 level=INFO source=cpu_common.go:15 msg="CPU has AVX"
Apr 07 11:26:36 localhost.localdomain ollama[4293]: time=2024-04-07T11:26:36.066+08:00 level=INFO source=routes.go:1141 msg="no GPU detected"
Hint: Some lines were ellipsized, use -l to show in full.If Ollama is not running on Linux, you can start the Ollama service with the following command: ollama serve, or sudo systemctl start ollama. By analyzing the Linux installation script install.sh, you can see that ollama serve is configured as a system service, so you can use systemctl to start/stop the Ollama process.
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=$BINDIR/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=$PATH"2.2 Start
sudo systemctl start ollama2.3 Update
Update Ollama by running the install script again:
curl -fsSL https://ollama.com/install.sh | shOr by downloading the Ollama binary:
sudo curl -L https://ollama.com/download/ollama-linux-amd64 -o /usr/bin/ollama
sudo chmod +x /usr/bin/ollama2.4 View Logs
journalctl -u ollama3. Enable Remote Access
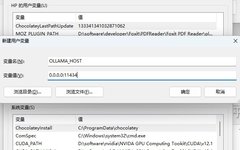
Ollama binds to 127.0.0.1 port 11434 by default. You can change the binding address using the OLLAMA_HOST environment variable.
3.1 Set Environment Variable on Linux
If Ollama runs as a systemd service, you should set the environment variable using OLLAMA_HOST:
-
Edit the systemd service by calling systemctl edit ollama.service. This will open an editor. Alternatively, create the configuration file/etc/systemd/system/ollama.service.d/environment.conf. -
Add a line Environmentfor each environment variable under the[Service]section:
[Service]
Environment="OLLAMA_HOST=0.0.0.0"-
Save and exit. -
Reload systemdand restart Ollama:
systemctl daemon-reload
systemctl restart ollama3.2 Set Environment Variable on Windows
On Windows, Ollama inherits your user and system environment variables.
-
First, exit the Ollama app via the taskbar. -
Edit system environment variables from the Control Panel. -
Edit or create variables for your user account, such as OLLAMA_HOST,OLLAMA_MODELS, etc. -
Click OK/Apply to save. -
Restart the ollama app.exeservice.
As shown in the configuration below: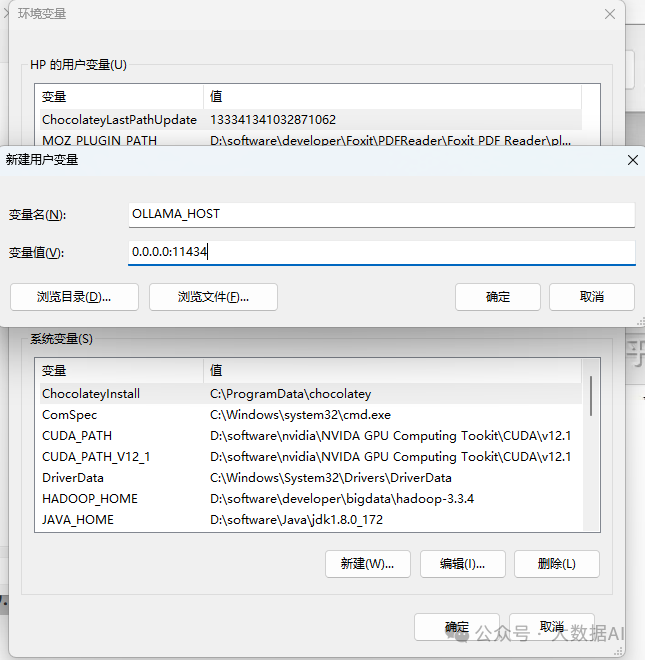
4. Deploying Models
4.1 Model Repository
Model repository address: https://ollama.com/library Ollama is a simple and easy-to-use local model running framework developed in Go language. It can be likened to Docker; after installing Ollama, it is also a command, and interaction with models is done through commands.
-
ollama list: Displays the list of models. -
ollama show: Displays information about a model. -
ollama pull: Pulls a model. -
ollama push: Pushes a model. -
ollama cp: Copies a model. -
ollama rm: Deletes a model. -
ollama run: Runs a model.
Additionally, the official provides a repository similar to GitHub and DockerHub, which can be understood as ModelHub, used for storing large models (including models like Llama 2, Mistral, Qwen, etc., and you can also upload your custom models to the repository for others to use).
Here are some example models that can be downloaded:
| Model | Parameters | Size | Download |
|---|---|---|---|
| Llama 2 | 7B | 3.8GB | ollama run llama2 |
| Mistral | 7B | 4.1GB | ollama run mistral |
| Dolphin Phi | 2.7B | 1.6GB | ollama run dolphin-phi |
| Phi-2 | 2.7B | 1.7GB | ollama run phi |
| Neural Chat | 7B | 4.1GB | ollama run neural-chat |
| Starling | 7B | 4.1GB | ollama run starling-lm |
| Code Llama | 7B | 3.8GB | ollama run codellama |
| Llama 2 Uncensored | 7B | 3.8GB | ollama run llama2-uncensored |
| Llama 2 13B | 13B | 7.3GB | ollama run llama2:13b |
| Llama 2 70B | 70B | 39GB | ollama run llama2:70b |
| Orca Mini | 3B | 1.9GB | ollama run orca-mini |
| Vicuna | 7B | 3.8GB | ollama run vicuna |
| LLaVA | 7B | 4.5GB | ollama run llava |
| Gemma | 2B | 1.4GB | ollama run gemma:2b |
| Gemma | 7B | 4.8GB | ollama run gemma:7b |
The official recommendation: You should have at least 8 GB of available RAM to run the 7B model, 16 GB to run the 13B model, and 32 GB to run the 33B model.
You can search for the model you want to run on the model repository’s official website.
4.2 Run a Model
Here, I choose to download the Qwen1.5 model open-sourced by Alibaba for demonstration. The model address is: https://github.com/QwenLM/Qwen1.5. You can also search for it in the model repository, as shown in the image below: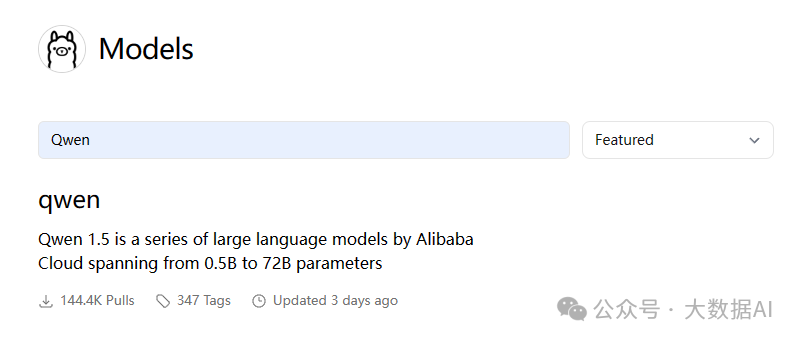 Since my computer has 32GB, I chose the 14B model for debugging. First, check if the model exists locally:
Since my computer has 32GB, I chose the 14B model for debugging. First, check if the model exists locally:
[root@localhost ~]# ollama list
NAME ID SIZE MODIFIEDDownload and run the model:
[root@localhost ~]# ollama run qwen:14b
>>> Hello
Hello! I am glad to assist you. How can I help you?After the download is complete, you can directly converse with the large model in the terminal. With such simplicity, you have your own private chat AI. If the model is not available locally, it will be downloaded before running. The initial startup may be slightly slow. Check the local model repository again:
[root@localhost ~]# ollama list
NAME ID SIZE MODIFIED
qwen:14b 80362ced6553 8.2 GB 6 minutes ago4.3 Specify GPU
If you have multiple GPUs locally, how to run Ollama using a specified GPU? On Linux, create the following configuration file and set the environment variable CUDA_VISIBLE_DEVICES to specify which GPU to run Ollama, then restart the Ollama service.
$ cat /etc/systemd/system/ollama.service.d/environment.conf
[Service]
Environment=CUDA_VISIBLE_DEVICES=1,24.4 Change Storage Path
By default, the storage paths for large models on different operating systems are as follows:
-
macOS: ~/.ollama/models -
Linux: /usr/share/ollama/.ollama/models -
Windows: C:\Users \.ollama\models
When installing Ollama on Linux, a user named ollama is created by default, and model files are stored in that user’s directory /usr/share/ollama/.ollama/models. However, since large model files are often particularly large, it may be necessary to store them on a dedicated data disk. In this case, the official method is to set the environment variable OLLAMA_MODELS. On Linux, create the following configuration file and set the environment variable OLLAMA_MODELS to specify the storage path, then restart the Ollama service.
$ cat /etc/systemd/system/ollama.service.d/environment.conf
[Service]
Environment=OLLAMA_MODELS=<path>/OLLAMA_MODELS</path>5. REST API
If you do not wish to interact with the large language model directly in the terminal, you can use the command ollama serve to start a local server. Once this command runs successfully, you can interact with the local language model via the REST API. Ollama has a REST API for running and managing models.
5.1 Generate a Response
curl http://localhost:11434/api/generate -d '{
"model": "qwen:14b",
"prompt":"Hello"
}'The output is as follows:
[root@localhost ~]# curl http://localhost:11434/api/generate -d '{
> "model": "qwen:14b",
> "prompt":"Hello"
> }'
{"model":"qwen:14b","created_at":"2024-04-09T06:02:32.544936379Z","response":"Hello","done":false}
{"model":"qwen:14b","created_at":"2024-04-09T06:02:33.102577518Z","response":"!","done":false}
{"model":"qwen:14b","created_at":"2024-04-09T06:02:33.640148118Z","response":"Glad to","done":false}
{"model":"qwen:14b","created_at":"2024-04-09T06:02:34.175936317Z","response":"assist you.","done":false}
{"model":"qwen:14b","created_at":"2024-04-09T06:02:34.767553169Z","response":"What can I help","done":false}
{"model":"qwen:14b","created_at":"2024-04-09T06:02:35.413131616Z","response":"you with?","done":false}
{"model":"qwen:14b","created_at":"2024-04-09T06:02:36.52352589Z","response":".","done":false}
{"model":"qwen:14b","created_at":"2024-04-09T06:02:37.080783596Z","response":"What can I assist you?","done":false}
{"model":"qwen:14b","created_at":"2024-04-09T06:02:38.229425561Z","response":"?","done":false}
{"model":"qwen:14b","created_at":"2024-04-09T06:02:39.355910894Z","response":"
","done":false}
{"model":"qwen:14b","created_at":"2024-04-09T06:02:40.020951528Z","response":"","done":true,
"context":[151644,872,198,108386,151645,198,151644,77091,198,108386,6313,112169,106184,47874,1773,104139,111728,103929,101037,94432],"total_duration":21400599076,"load_duration":10728843813,"prompt_eval_count":9,"prompt_eval_duration":3192013000,"eval_count":14,"eval_duration":7474825000}5.2 Chat with a Model
curl http://localhost:11434/api/chat -d '{
"model": "qwen:14b",
"messages": [
{ "role": "user", "content": "Hello" }
]
}'The output is as follows:
[root@localhost ~]# curl http://localhost:11434/api/chat -d '{
> "model": "qwen:14b",
> "messages": [
> { "role": "user", "content": "Hello" }
> ]
> }'
{"model":"qwen:14b","created_at":"2024-04-09T06:05:06.900324407Z","message":{"role":"assistant","content":"Hello"},"done":false}
{"model":"qwen:14b","created_at":"2024-04-09T06:05:07.470563314Z","message":{"role":"assistant","content":"!"},"done":false}
{"model":"qwen:14b","created_at":"2024-04-09T06:05:08.06014135Z","message":{"role":"assistant","content":"Glad to"},"done":false}
{"model":"qwen:14b","created_at":"2024-04-09T06:05:08.659460583Z","message":{"role":"assistant","content":"assist you"},"done":false}
{"model":"qwen:14b","created_at":"2024-04-09T06:05:09.198527345Z","message":{"role":"assistant","content":"provide"},"done":false}
{"model":"qwen:14b","created_at":"2024-04-09T06:05:09.86445663Z","message":{"role":"assistant","content":"help"},"done":false}
{"model":"qwen:14b","created_at":"2024-04-09T06:05:10.373454235Z","message":{"role":"assistant","content":"."},"done":false}
{"model":"qwen:14b","created_at":"2024-04-09T06:05:11.001192023Z","message":{"role":"assistant","content":"What can I help"},"done":false}
{"model":"qwen:14b","created_at":"2024-04-09T06:05:11.5422106Z","message":{"role":"assistant","content":"you with"},"done":false}
{"model":"qwen:14b","created_at":"2024-04-09T06:05:12.135530288Z","message":{"role":"assistant","content":"chat"},"done":false}
{"model":"qwen:14b","created_at":"2024-04-09T06:05:12.737720245Z","message":{"role":"assistant","content":"?"},"done":false}
{"model":"qwen:14b","created_at":"2024-04-09T06:05:13.236999733Z","message":{"role":"assistant","content":"?"},"done":false}
{"model":"qwen:14b","created_at":"2024-04-09T06:05:15.073687823Z","message":{"role":"assistant","content":"
"},"done":false}
{"model":"qwen:14b","created_at":"2024-04-09T06:05:15.675686469Z","message":{"role":"assistant","content":""},"done":true,
"total_duration":12067791340,"load_duration":4094567,"prompt_eval_duration":3253826000,"eval_count":16,"eval_duration":8773552000}See the API Documentation for all endpoints.
6. Web UI
6.1 UI Tools
The Web and Desktop UI have the following tools: Here, I recommend the above Web UI: Open WebUI (formerly Ollama WebUI).
Here, I recommend the above Web UI: Open WebUI (formerly Ollama WebUI).
6.2 Open WebUI
OpenWebUI is an extensible, feature-rich, and user-friendly self-hosted Web UI that supports full offline operation and is compatible with both Ollama and OpenAI APIs. This provides users with a visual interface, making interaction with large language models more intuitive and convenient.
6.2.1 Installation
Official documentation: How To Install
docker run -d --network=host -v open-webui:/app/backend/data -e OLLAMA_BASE_URL=http://127.0.0.1:11434 --name open-webui --restart always ghcr.io/open-webui/open-webui:mainThen visit http://localhost:8080:
6.2.2 Usage
On first login, enter your email and password to register and log in.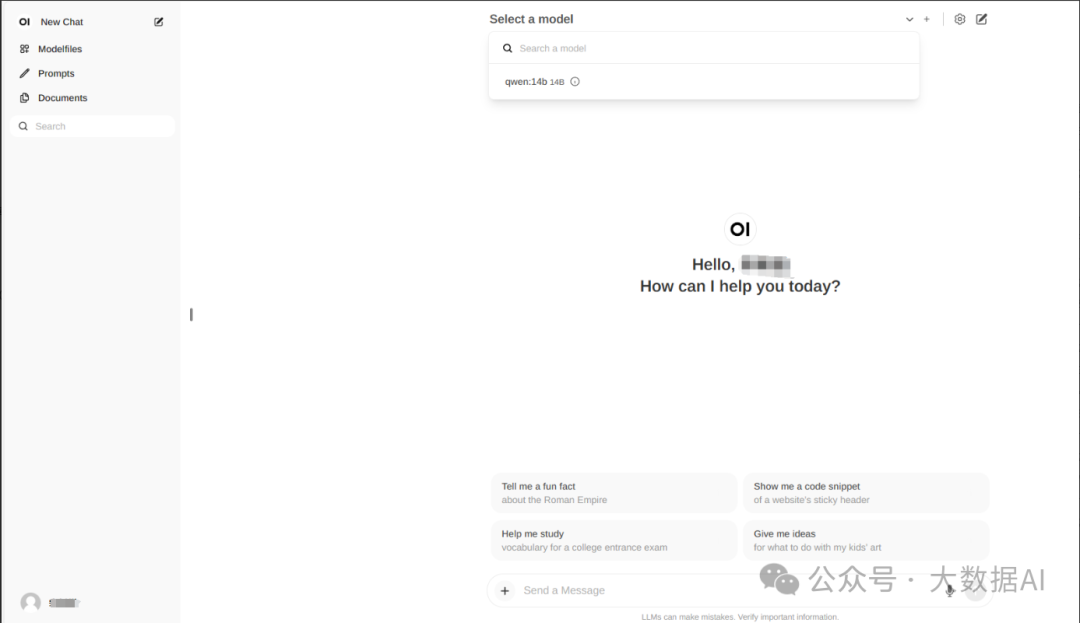 Select the model
Select the model qwen:14b, and you can start a conversation by entering text in the dialog box. Isn’t the interface very familiar, resembling ChatGPT, making it much more convenient to use?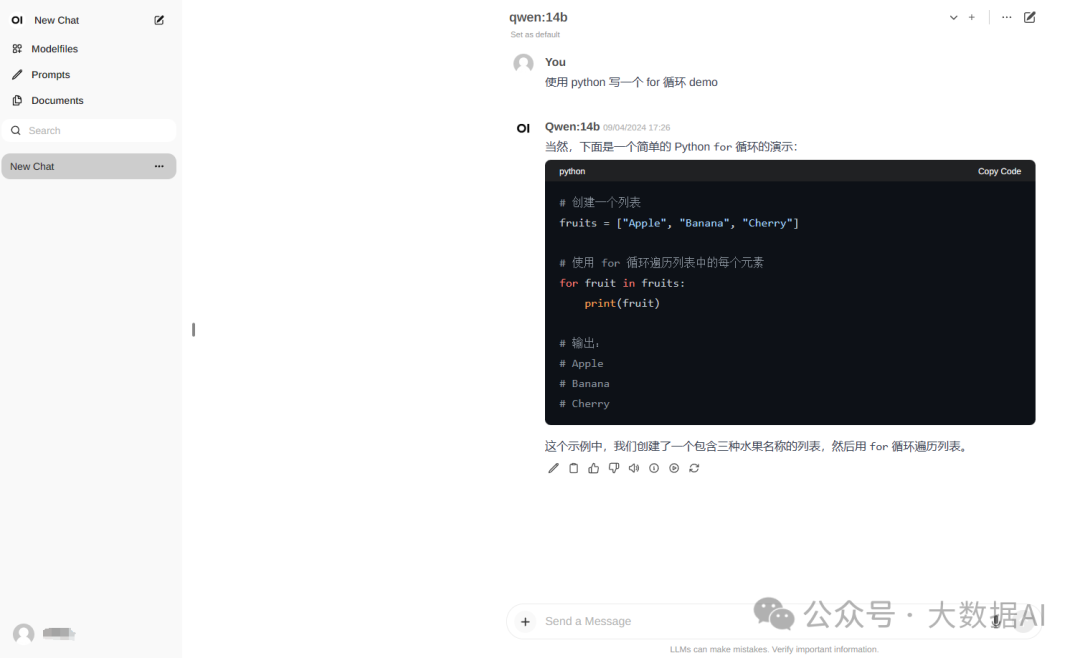 Open WebUI also has many other features, such as built-in RAG. You can enter “#” followed by a URL in the dialog box to access the implementation information of the webpage and generate content. You can also upload documents for deeper knowledge interaction based on text. If your requirements for the knowledge base are not high, after achieving this, it can basically meet the needs of most individuals.
Open WebUI also has many other features, such as built-in RAG. You can enter “#” followed by a URL in the dialog box to access the implementation information of the webpage and generate content. You can also upload documents for deeper knowledge interaction based on text. If your requirements for the knowledge base are not high, after achieving this, it can basically meet the needs of most individuals.