

Recently, Google DeepMind launched its most powerful and versatile multimodal model, Gemini 1.0!
Gemini 1.0 has three different versions: Gemini Ultra, Gemini Pro, and Gemini Nano:
Gemini Ultra — the largest and strongest model, suitable for highly complex tasks.
Gemini Pro — the best model that can be scaled to various tasks.
Gemini Nano — the most efficient model for device-side tasks.
The evaluation report released by Google claims that Gemini Ultra surpasses GPT-4 in various tasks, while Gemini Pro is said to be comparable to GPT-3.5.
However, it was quickly pointed out by netizens that Gemini Ultra used many tricks during the evaluation, suspected of “winning unfairly”! There are allegations of deliberately inflating rankings and exaggerating performance, and the demonstration video was also revealed to be “synthetic fraud”… We also reported this news in detail. Google admitted that the Gemini video was “cut together” and that they were crazy to catch up with GPT-4.
Not only does Gemini Ultra’s surpassing of GPT-4 raise suspicion of cheating, but Gemini Pro’s performance exceeding GPT-3.5 is also questionable.
Scholars from Carnegie Mellon University conducted an in-depth discussion on the language capabilities of OpenAI GPT and Google Gemini models, testing abilities including reasoning, answering knowledge-based questions, solving mathematical problems, language translation, code generation, and instruction-following agents, and publicly released reproducible code and completely transparent results.
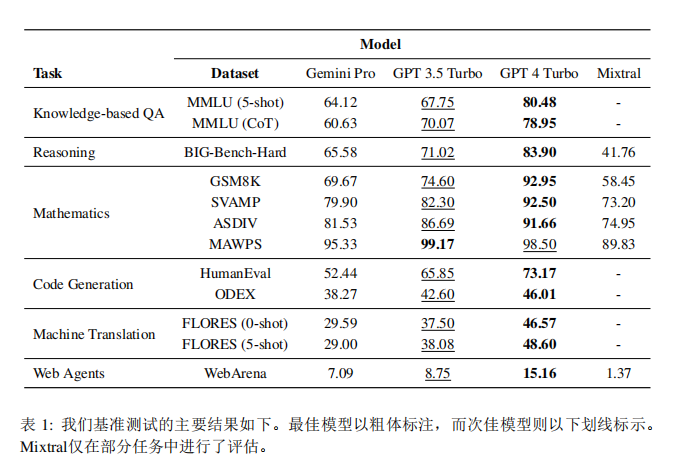
The results found that Gemini Pro performed worse than GPT 3.5 Turbo in all evaluation tasks and was significantly behind GPT 4 Turbo.
Paper Title:An In-depth Look at Gemini’s Language Abilities
Paper Link:https://arxiv.org/abs/2312.11444
GitHub Code: https://github.com/neulab/gemini-benchmark
In response, Google threw out the Gemini evaluation report and stated that Gemini Pro’s performance is superior to GPT 3.5, and the more powerful version Gemini Ultra, which will be launched in early 2024, scored higher than GPT 4 in Google’s internal research. The excerpt from the response is as follows:
“In our technical paper, we compared Gemini Pro and Ultra with a set of external LLMs and our previous best model PaLM 2 through a series of text-based academic benchmarks, covering reasoning, reading comprehension, STEM, and programming. The results on page 7 in Table 2 indicate that Gemini Pro’s performance exceeds reasoning-optimized models like GPT-3.5, comparable to some of the currently available strongest models, while Gemini Ultra’s performance exceeds all existing models. Notably, Gemini Ultra can exceed all existing models on MMLU, achieving an accuracy of 90.04%. It is also the first model to exceed this threshold, with the previous state-of-the-art accuracy being 86.4%.”
Google also acknowledged that the reliability of the evaluation may be challenged due to data contamination and other issues, but has ensured that the results are as truthful and reliable as possible.
‘The evaluations on these benchmarks are challenging and may be affected by data contamination. We conducted extensive leakage data analysis after training to ensure that the results we report here are as scientifically reliable as possible, but we still found some minor issues and decided not to report results for, for example, LAMBADA (Paperno et al., 2016).”
Gemini Evaluation Report:https://storage.googleapis.com/deepmind-media/gemini/gemini_1_report.pdf

Let’s first take a look at what the Carnegie Mellon University report specifically says~
Experimental Setup
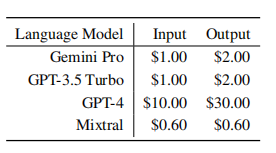
The four models compared in the text are Gemini Pro, GPT-3.5 Turbo, GPT-4, and Mixtral, all using the unified interface provided by LiteLLM for querying. Everyone should be familiar with the other three models, so I won’t introduce them. Among them, Mixtral is an open-source expert mixture model composed of eight 7B parameter models, and its accuracy is comparable to GPT 3.5 Turbo, so it is also included in the comparison. The author also listed the pricing for accessing each model via API:
Next, let’s take a look at the detailed PK situation in each task!
Knowledge-Based Question Answering
The dataset used is MMLU, covering multiple-choice questions on various topics such as science, technology, engineering, mathematics, humanities, and social sciences, with a total of 14,042 test samples, generated answers using standard prompts and thinking chain prompts under 5-shot.
From the overall results in Figure 1, Gemini Pro’s accuracy is lower than that of GPT 3.5 Turbo and far below that of GPT 4 Turbo. In addition, there is almost no difference in performance when using thinking chain guidance. This may be because MMLU is primarily a knowledge-based question-answering task that may not benefit significantly from stronger reasoning-oriented prompts.
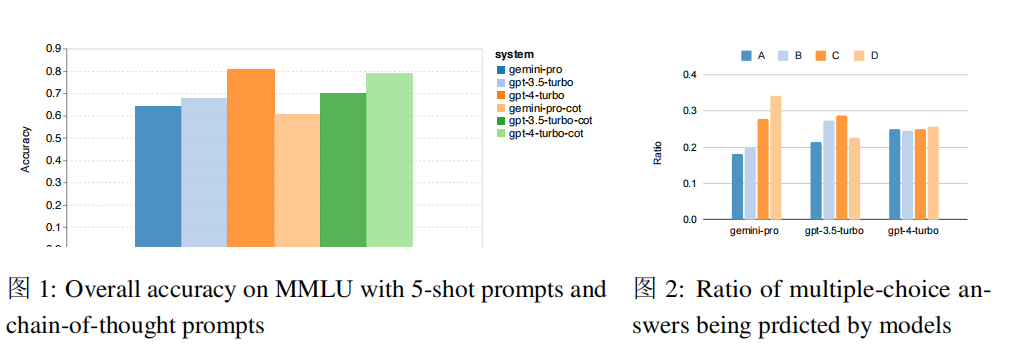
Figure 2 shows the proportion of times each model chose each multiple-choice answer. Gemini tends to choose the last answer “D”, while the GPT model’s option distribution is more balanced. This may indicate that Gemini has not undergone rigorous guided adjustments in solving multiple-choice questions, leading to bias in answer rankings.
In addition, the author further explored Gemini Pro’s performance in the worst/best tasks. As shown in the figure below, Gemini Pro lags behind GPT3.5 in multiple tasks, and the two tasks it won only maintained a slight advantage.
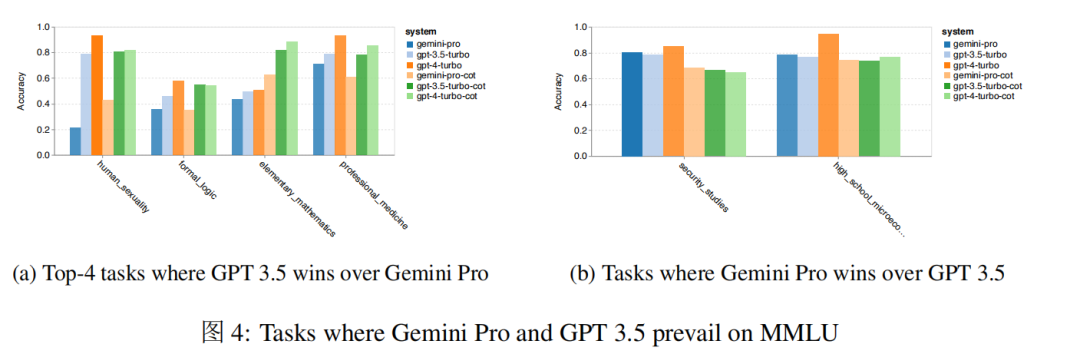
Gemini Pro’s poor performance on specific tasks may be due to its overly strong content filtering mechanism. In some cases, Gemini cannot return answers, especially when it involves potentially illegal or sensitive material. In most MMLU sub-tasks, the API response rate is greater than 95%, but Gemini’s response rate is 85% in moral_scenarios and as low as 28% in human_sexuality tasks. Secondly, Gemini Pro performs poorly in basic mathematical reasoning tasks required for solving formal_logic and elementary_mathematics tasks.
General Reasoning
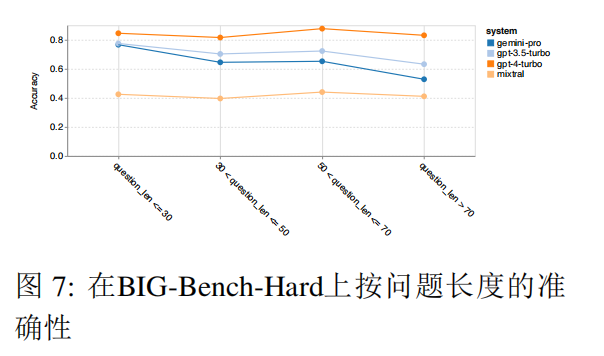
The evaluation dataset used is BIG-Bench Hard, which includes 27 different reasoning tasks, including arithmetic reasoning, symbolic reasoning, multilingual reasoning, and factual knowledge understanding tasks. Most tasks consist of 250 question-answer pairs.
First, let’s look at the overall accuracy, where Gemini Pro’s accuracy is slightly lower than that of GPT 3.5 Turbo and far below that of GPT 4 Turbo, while the accuracy of the Mixtral model is much lower.

Then the author analyzed the reasons for Gemini’s poor performance from multiple aspects.
-
Gemini Pro performs poorly on longer and more complex questions, while the GPT model is more robust. Notably, GPT 4 Turbo shows almost no degradation on longer questions, while Mixtral is not affected by question length, but has a lower overall accuracy.
-
Gemini Pro is not good at tracking item states, as shown in the “swap items” task in the figure below, where the item state update is incorrect in step 2.

-
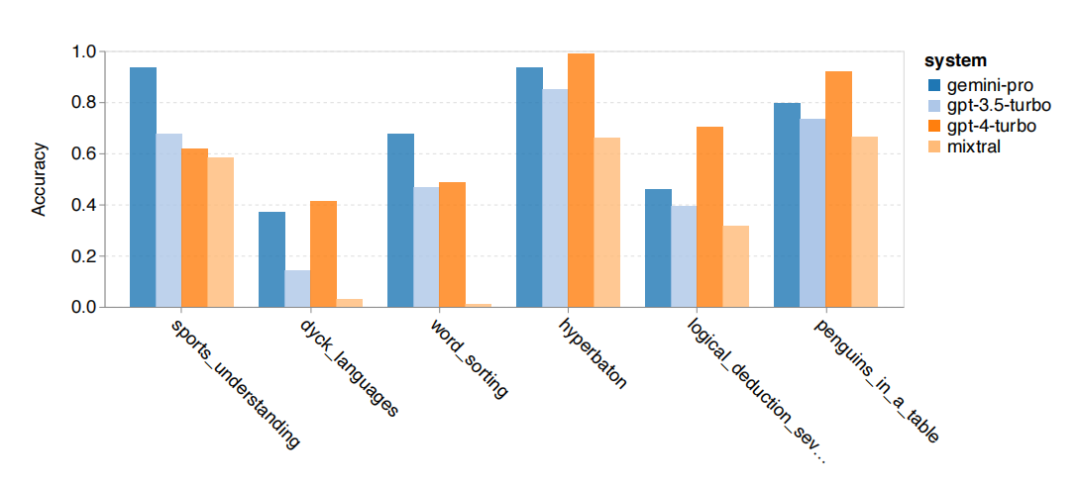
Gemini also has advantageous subjects, such as outperforming GPT 3.5 Turbo in tasks that require world knowledge, tasks that manipulate symbol stacks, tasks that sort words alphabetically, and tasks that parse tables.
Mathematical Reasoning
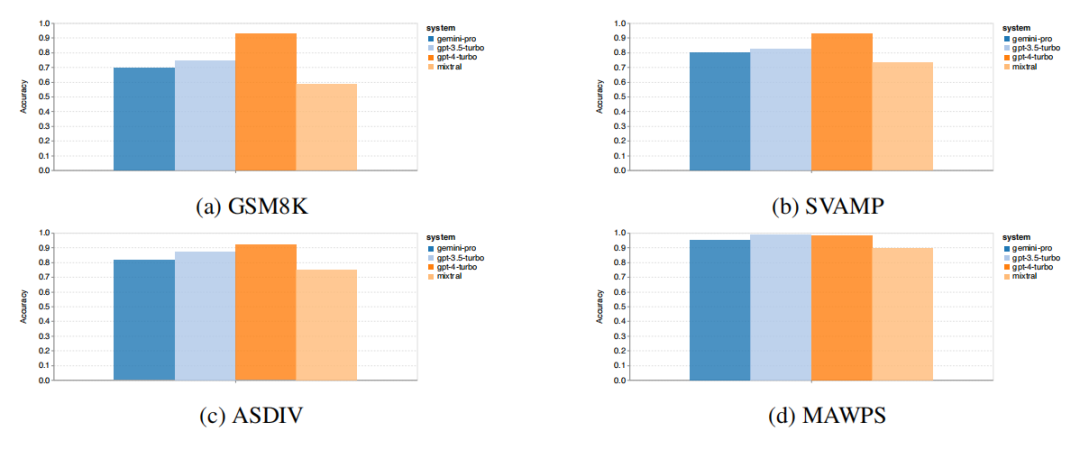
In terms of mathematical reasoning ability, it can be seen from the figure below that Gemini Pro’s accuracy is slightly lower than that of GPT 3.5 Turbo across four mathematical reasoning datasets.
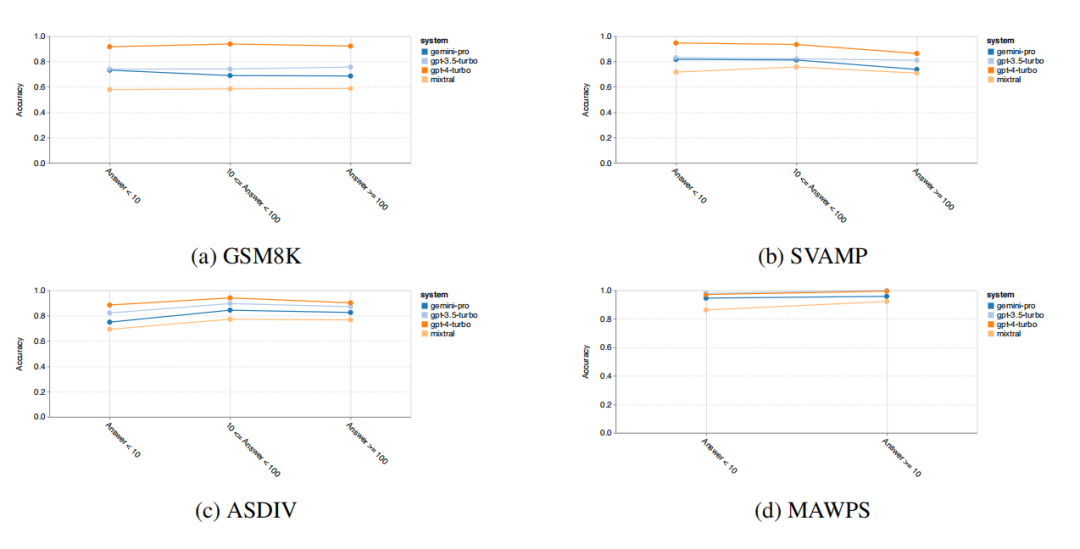
Additionally, the author compared the models’ accuracy in generating answers of different digit lengths, including one-digit, two-digit, and three-digit numbers. The results indicate that GPT 3.5 Turbo appears more robust on multi-digit mathematical problems, while Gemini Pro’s performance declines.
Code Generation
The author used two code generation datasets, HumanEval and ODEX, to test the models’ coding abilities.
As seen in the figure below, Gemini Pro’s performance on the two tasks is lower than that of GPT 3.5 Turbo and far below that of GPT 4 Turbo, indicating that Gemini’s code generation ability still has room for improvement.
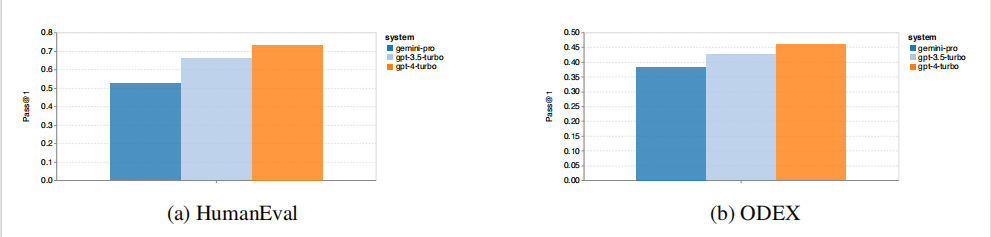
Additionally, the author analyzed the relationship between solution length and model performance. Solution length can somewhat represent the difficulty of the task; longer tasks are more difficult. When the solution length is less than 100 (simpler cases), Gemini Pro can achieve a level comparable to GPT 3.5, but as the solution becomes longer, it significantly lags behind.

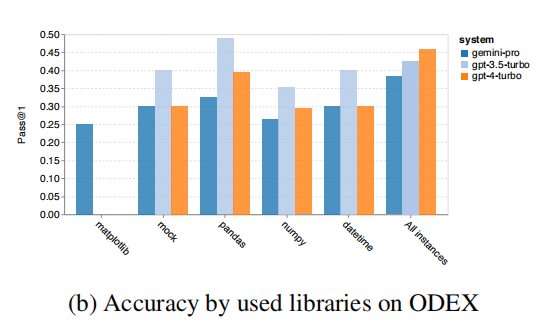
Moreover, the author found that when using libraries such as mock, pandas, numpy, and datetime, Gemini Pro performs worse than GPT 3.5, while in the matplotlib case, it outperforms both GPT 3.5 and GPT 4, indicating stronger capabilities in visualizing through code.
Machine Translation
The author used the FLORES-200 machine translation benchmark, limiting the task scope to translating only from English to other languages. Open-source machine translation model NLLB-MoE and Google Translate were also added for comparison.
The figures below show the comparison results in zero-shot and 5-shot:
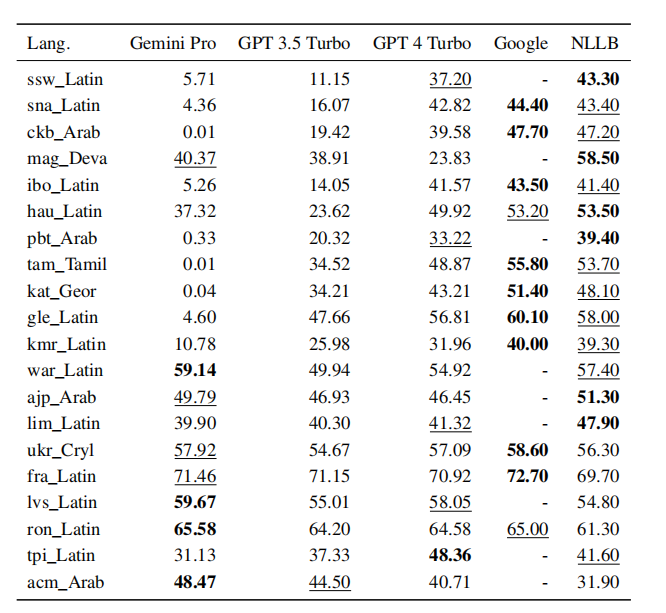
▲zero-shot
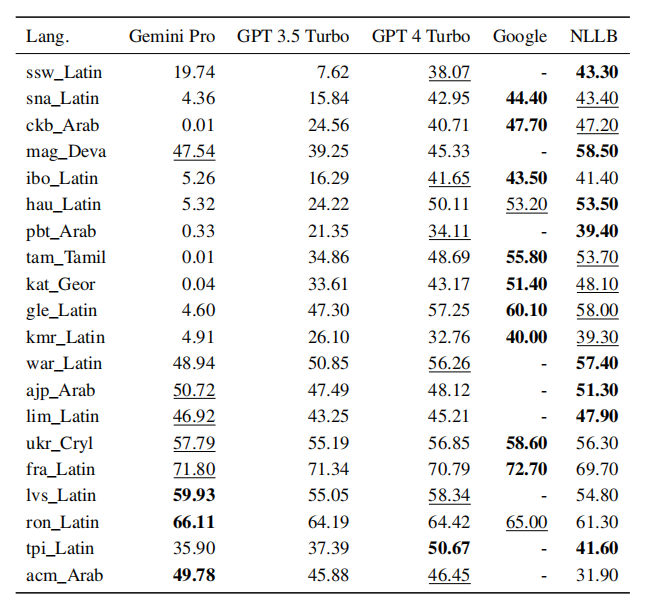
▲5-shot
The results show that proprietary machine translation systems outperform conventional language models, and among language models, GPT 4 Turbo still excels, even competing with proprietary machine translation systems in low-resource languages. Gemini Pro outperformed GPT 3.5 Turbo and GPT 4 Turbo in 8 languages and showed the best performance in 4 languages.
However, Gemini Pro exhibits a strong tendency to generate “Blocked Response” errors in about 10 language pairs when confidence is low, resulting in suboptimal final scores.
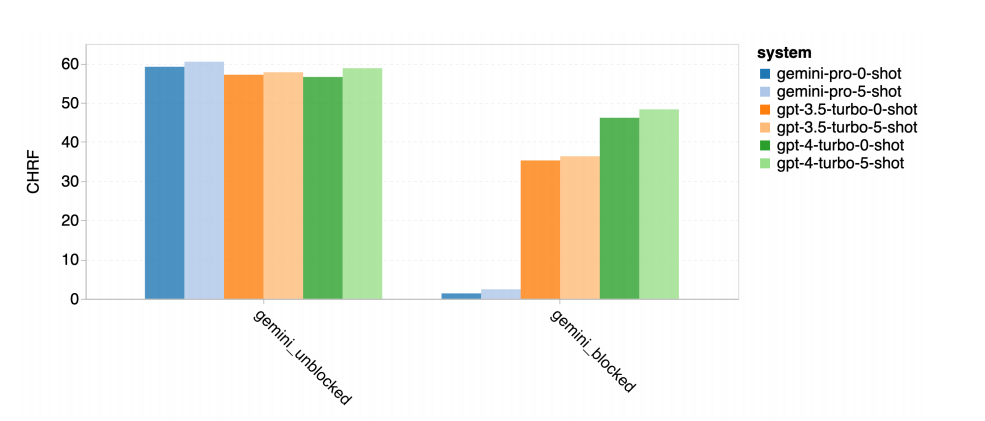
▲Performance on blocked and non-blocked samples
Web Navigation Agent
The web navigation agent task requires long-term planning and complex data understanding. The author used the execution-based simulation environment WebArena, with tasks given to the agent including information search, site navigation, and content and configuration operations. The author tested with CoT prompts with and without UA prompts. The so-called UA prompt tells the model to terminate execution when the task cannot be completed.
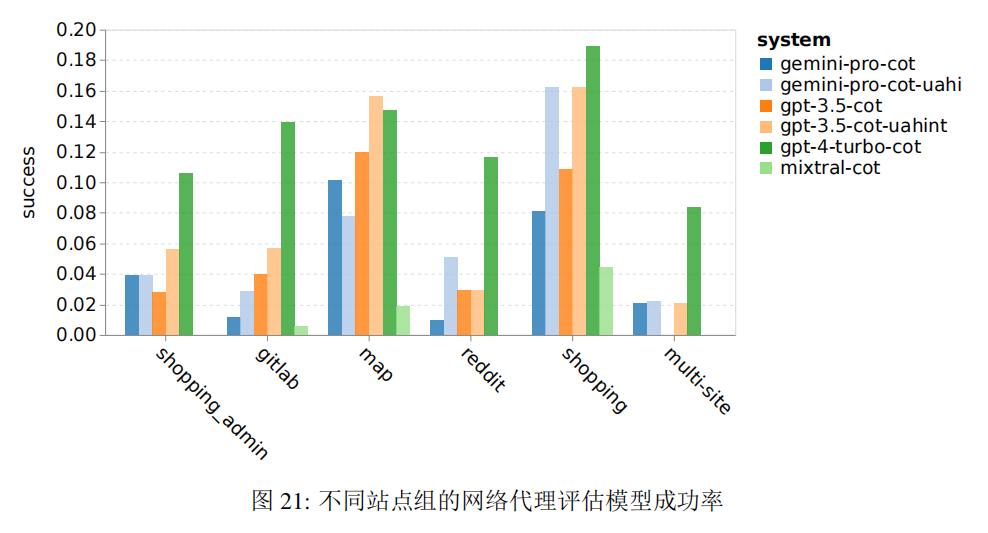
Overall, Gemini Pro’s performance is slightly inferior to that of GPT-3.5 Turbo. Similar to GPT-3.5 Turbo, Gemini Pro performs better in the presence of UA prompts, achieving a success rate of 7.09%.

The web navigation agent task includes various websites, and it can be seen that Gemini Pro performs worse than GPT-3.5 Turbo on GitLab and maps, while being close to GPT-3.5 Turbo on shopping admin, Reddit, and shopping sites. In addition, on multi-site tasks, Gemini Pro outperforms GPT-3.5 Turbo, indicating that Gemini performs better on more complex subtasks in various benchmark tests.
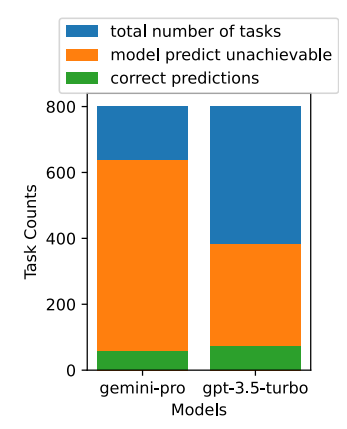
Gemini Pro is more inclined to predict more tasks as unachievable, especially in the presence of UA prompts. When given UA prompts, Gemini Pro predicts 80.6% of tasks as unachievable, while GPT-3.5 Turbo predicts 47.7%. However, in reality, only 4.4% of tasks in the dataset are unachievable, so both overpredict the number of tasks that are actually unachievable.
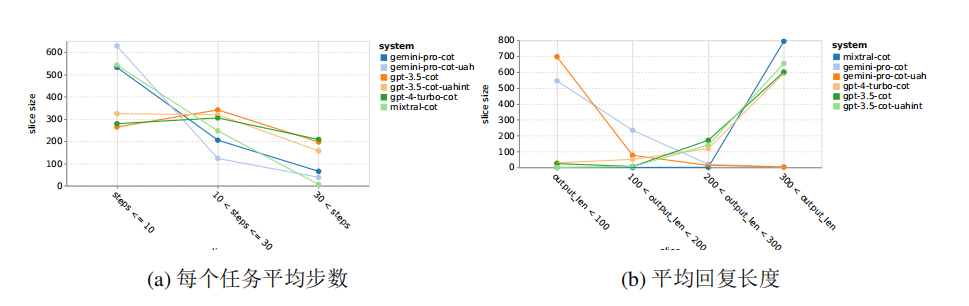
Additionally, Gemini Pro tends to respond with shorter phrases and takes fewer steps to reach conclusions. As shown in the figure below, more than half of Gemini Pro’s trajectories are under ten steps, while GPT 3.5 Turbo and GPT 4 Turbo’s trajectories mostly fall between 10 to 30 steps. Similarly, most of Gemini’s response lengths do not exceed 100 characters, while GPT 3.5 Turbo, GPT 4 Turbo, and Mixtral’s response lengths mostly exceed 300 characters.
Conclusion
Through the comparison of multiple tasks, the summary is as follows:
-
Gemini Pro is comparable to GPT 3.5 Turbo in model size and type but performs slightly worse in certain tasks.
-
Gemini Pro has some shortcomings compared to other models, such as answer order bias in multiple-choice questions, shorter reasoning steps, and response failures due to strict content filtering mechanisms.
-
Of course, there are also advantages: Gemini performs better in particularly long and complex reasoning tasks and shows excellent capabilities in unfiltered multilingual tasks, while GPT 3.5 Turbo is slightly inferior.
It is worth mentioning that the above conclusions are as of December 19, 2023, and rely on the specific prompts and generation parameters chosen by the authors. With the upgrade of models and systems, results may change at any time. Additionally, Gemini is a multimodal model, but this paper focuses only on Gemini’s performance in language understanding, generation, and translation capabilities, while its multimodal capabilities await further exploration.
Gemini currently only released the pro version, let’s look forward to the release of the Gemini Ultra version that can compete with GPT 4.
References
[1]https://venturebeat.com/ai/google-gemini-is-not-even-as-good-as-gpt-3-5-turbo-researchers-find/

Scan the QR code to add assistant WeChat
About Us
