Click the above“Beginner Learning Vision” to select “Star” or “Pin”
Valuable Insights Delivered First-Hand
Valuable Insights Delivered First-Hand
Jishi Guide
Is there a close relationship between the configuration of Transformers and their training objectives?
This article aims to introduce work from ICML 2023:

Paper Link:
https://arxiv.org/abs/2205.10505
01 TL;DR
This paper studies the relationship between the design of Transformer-like model structures (configuration) — specifically model depth and width — and training objectives. The conclusion is that token-level training objectives (e.g., masked token prediction) are relatively more suitable for scaling deeper models, while sequence-level training objectives (e.g., sentence classification) are less suitable for training deep neural networks, encountering the over-smoothing problem during training. When configuring the model structure, we should pay attention to the model’s training objectives.
Generally speaking, when discussing different models, we use the same configuration for fairness in comparison. However, if a model is structurally more suited to the training objective, it may outperform others in the comparison. For different training tasks, if corresponding model configuration searches are not conducted, its potential may be underestimated. Therefore, to fully understand the application potential of each novel training objective, we recommend researchers conduct reasonable studies and customize structural configurations.
02 Concept Explanation
The following will focus on explaining some concepts for quick understanding:
2.1 Training Objective
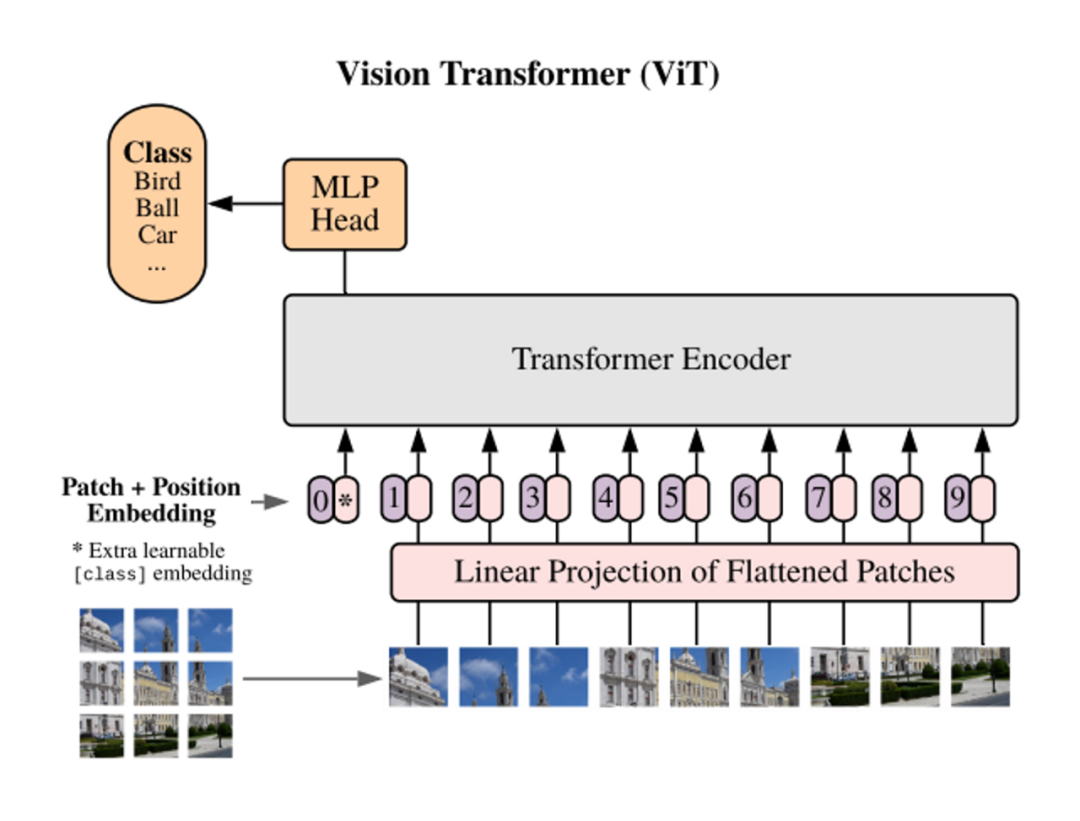
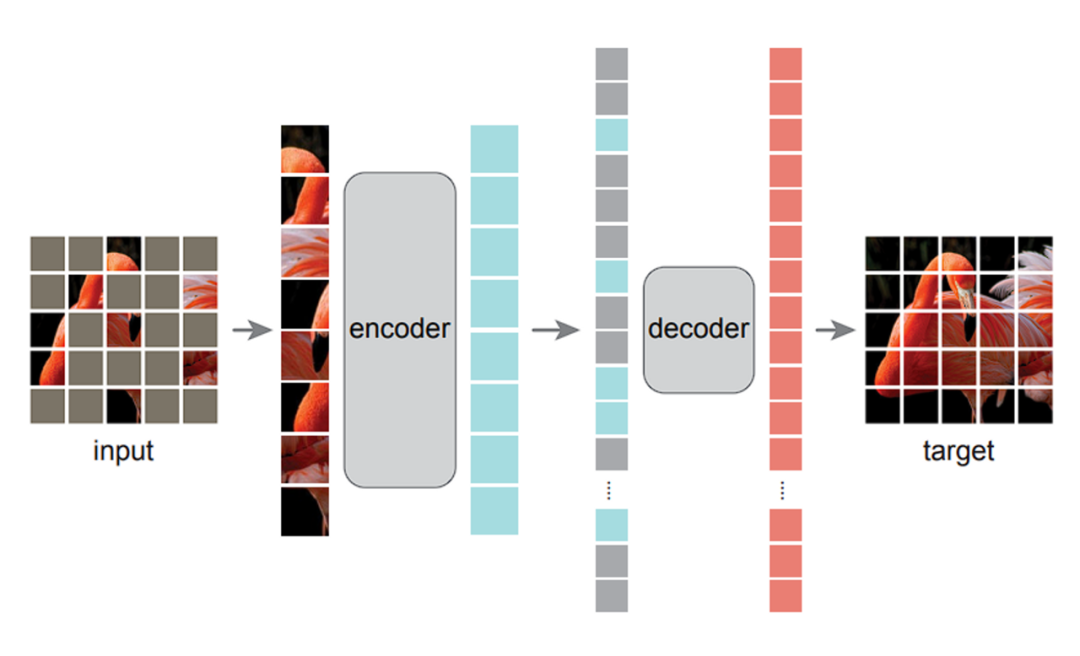
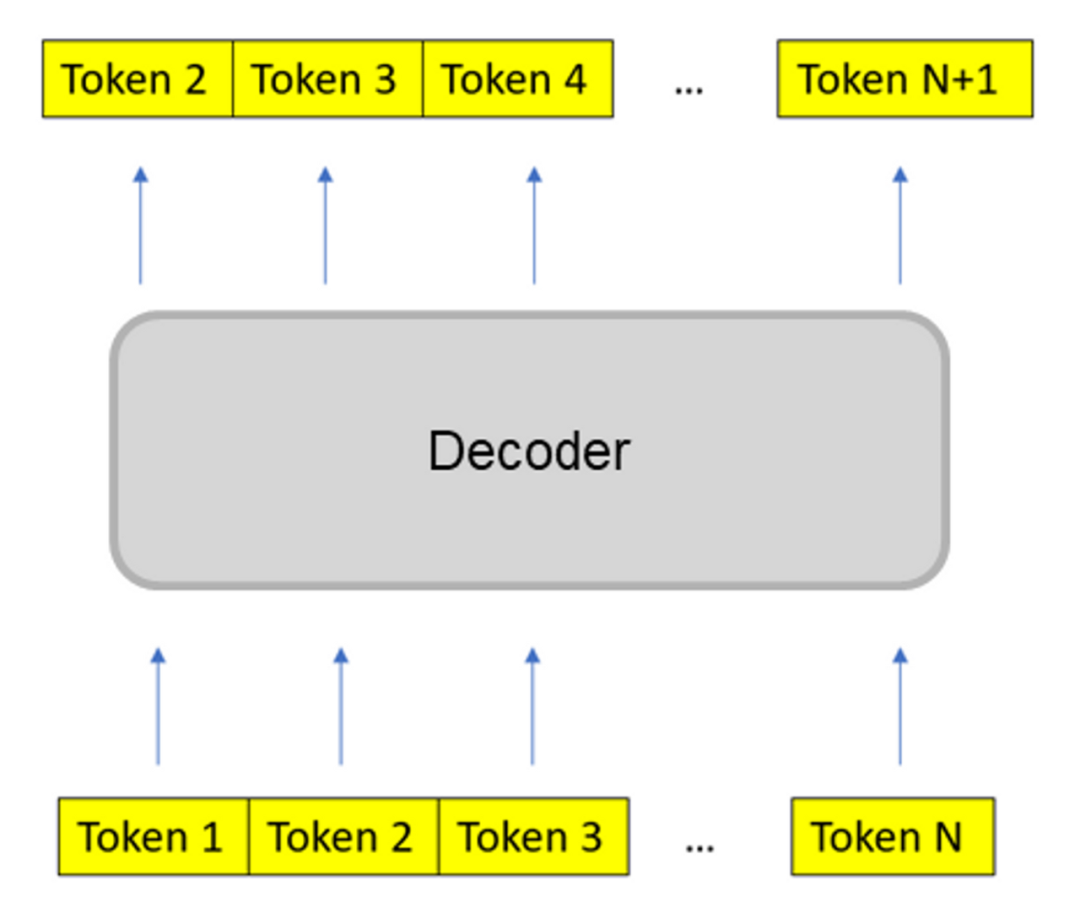
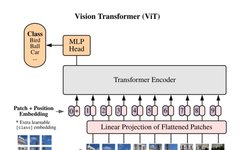
The training objective is the task the model is to accomplish during training, which can also be understood as the loss function it needs to optimize. During model training, various training objectives can be employed; here we list three different training objectives categorized as token level and sequence level:
-
sequence level:
-
classification tasks as supervised training tasks. Simple classification (Vanilla Classification) requires the model to classify the input directly, such as sentiment classification of sentences or image classification; while the classification task of CLIP requires the model to match images with sentences. -
token level: (unsupervised)
-
masked autoencoder: masked token prediction task, where the model reconstructs partially masked input -
next token prediction: predicting the next token in a sequence
2.2 Transformer Configuration
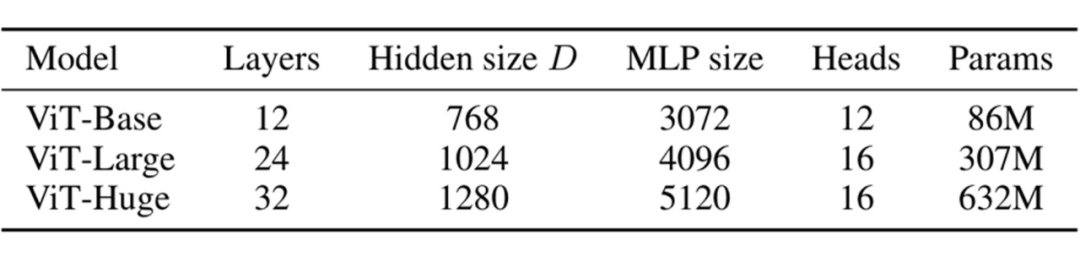
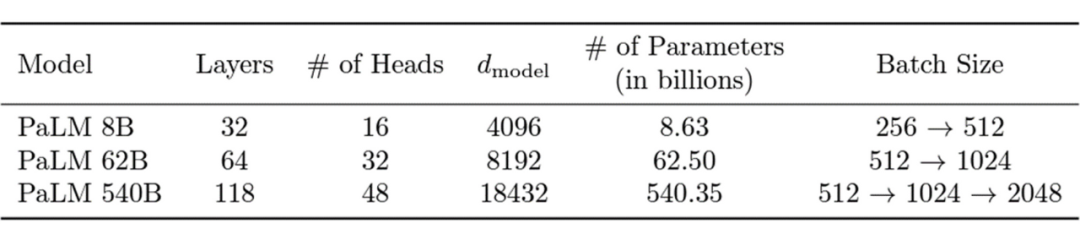
The configuration of Transformers refers to the hyperparameters that define the structure and size of the Transformer model, including the number of layers (depth), size of hidden layers (width), and the number of attention heads, etc.
2.3 Over-smoothing
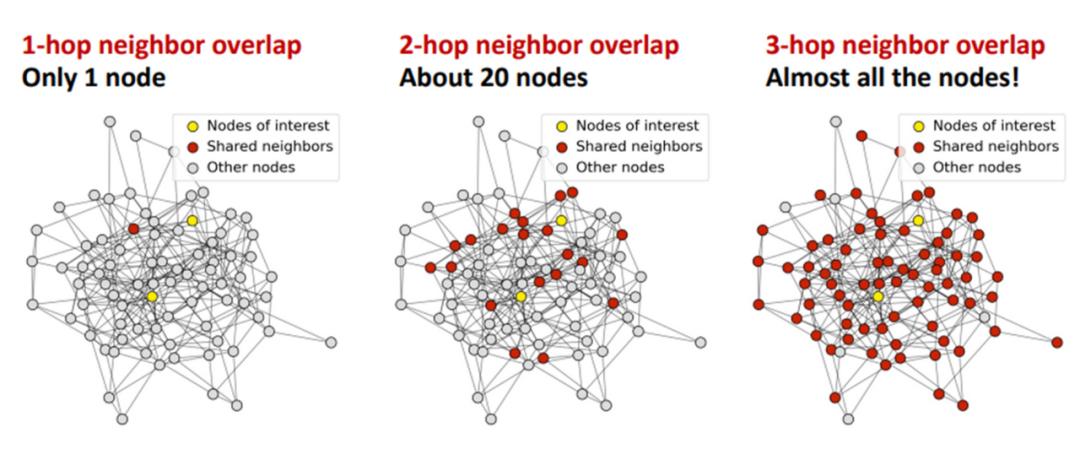
Over-smoothing is a concept in graph neural networks, specifically indicating the phenomenon where model outputs tend to become smooth and consistent, lacking detail and variation. This phenomenon has been widely studied in graph neural networks, but it also exists in Transformer models. (Existing studies) have found that the over-smoothing problem encountered by Transformer models hinders their deepening. Specifically, when stacking multiple layers of Transformer layers, the token representations (vectors) output by the transformer layer tend to become consistent, losing uniqueness. This hinders the scalability of Transformer models, particularly in terms of depth. Increasing the depth of Transformer models only brings slight performance improvements, and sometimes even harms the performance of the original model.
1. Over-smoothing in ViT and MAE
Intuitively, the training objective of the masked autoencoder framework (e.g., BERT, BEiT, MAE) is to recover masked tokens based on unmasked tokens. Compared to training Transformers with simple classification objectives, the masked autoencoder framework adopts a sequence labeling objective. We first assume that masked autoencoder training can alleviate over-smoothing, which may be one reason why MAE helps improve Transformer performance.
Since different masked tokens have different adjacent unmasked tokens, unmasked tokens must possess sufficient semantic information to accurately predict their neighboring masked tokens. That is, the semantic information of the representations of unmasked tokens is important, which suppresses their tendency to become consistent. In summary, we can infer that the training objective of masked autoencoders helps alleviate the over-smoothing problem by regularizing the differences between tokens.
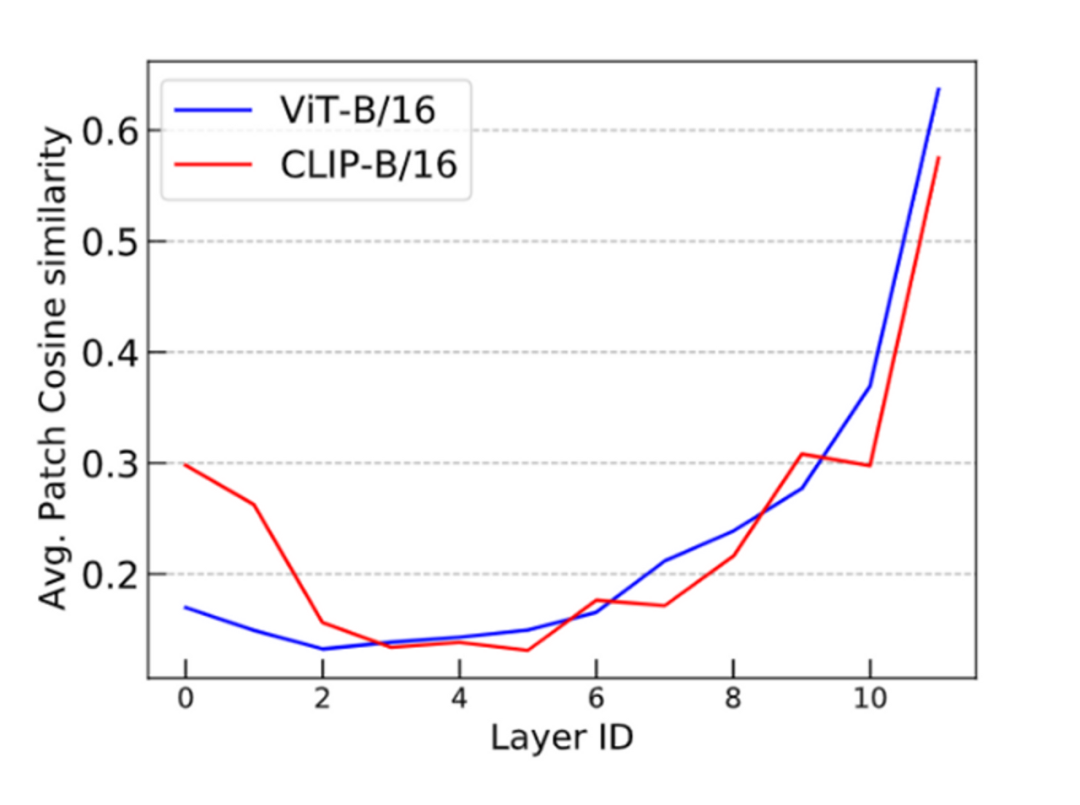
We validated this viewpoint through visual experiments. We found that the token representations of ViT become closer in deeper layers, while the MAE model avoids this issue, indicating that the over-smoothing problem is mitigated in masked autoencoders. Training Transformer models with simple classification tasks does not possess this characteristic.
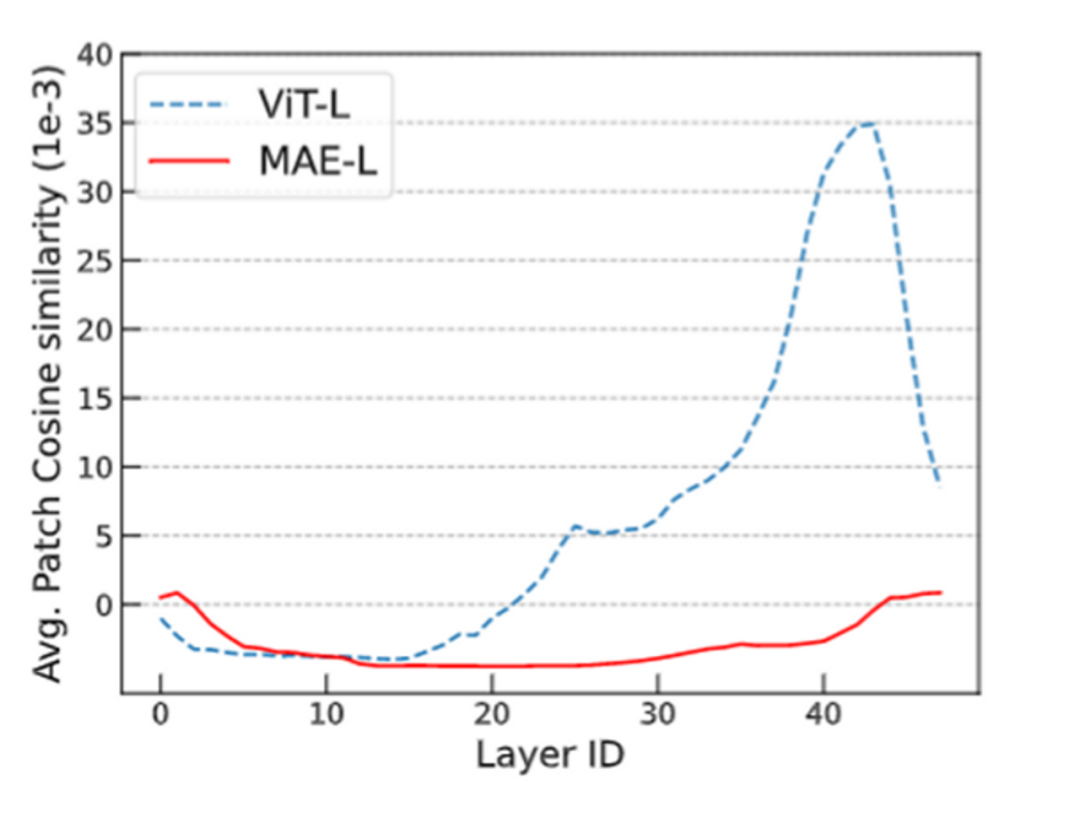
Furthermore, we also studied this issue through Fourier methods, which can be referenced in our paper.
2. Over-smoothing in CLIP and LLM
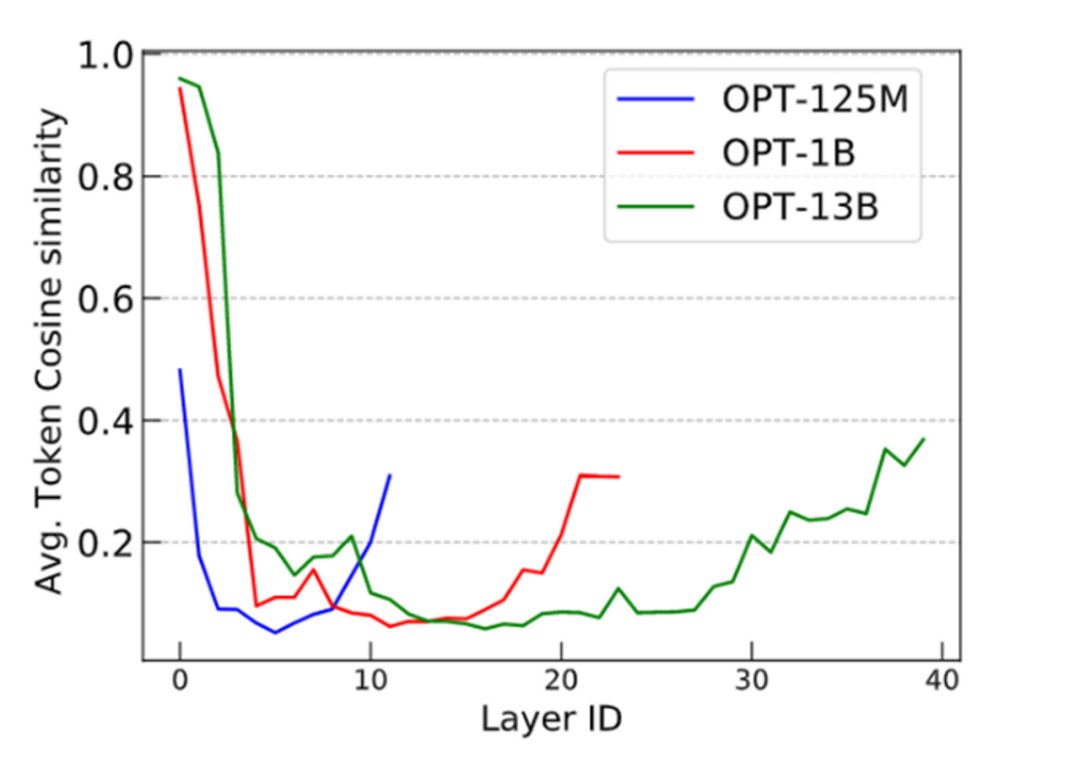
Based on the above analysis, we can conclude that token-level training objectives (such as next token prediction in language modeling) exhibit lighter over-smoothing. On the other hand, sequence-level objectives (such as contrastive pre-training of images) are more prone to over-smoothing. To verify this conclusion, we conducted similar cosine similarity experiments using CLIP and OPT. We observed that the CLIP model exhibited over-smoothing phenomena similar to Vanilla ViT. This observation aligns with our expectations.
Additionally, to explore whether the widely adopted next-token prediction language modeling pre-training objective can alleviate over-smoothing, we evaluated OPT and found it effectively addresses over-smoothing. This finding is significant as it helps explain why language modeling models outperform many visual models in terms of scalability (e.g., ultra-large-scale pre-trained language models).
03 Tracing Back: How Existing Transformer Architectures Came About
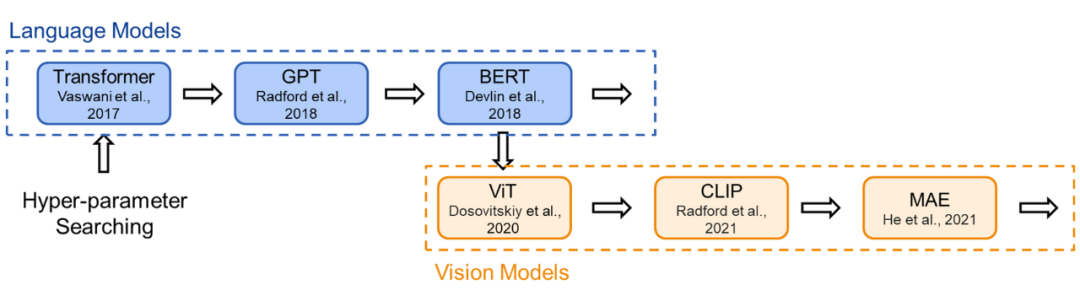
To ensure fair comparisons in research, existing Transformer-like models typically follow fixed structures (small, base, large…), meaning the same width and depth. For example, the aforementioned transformer-base has a width of 768 (hidden layers) and a depth of 12 (number of layers). However, for different research fields and model functionalities, why still adopt the same hyperparameters?
To address this, we first traced back the Transformer architecture, reviewing the origins of the Transformer structure in representative works: the authors of Vision Transformer based their ViT model configuration on the transformer-base structure in BERT; BERT followed the method of OpenAI GPT when choosing configurations; OpenAI referenced the original Transformer paper.
In the original Transformer paper, the best configuration stemmed from experiments on machine translation tasks. In other words, for different tasks, we all adopted configurations based on the Transformer for machine translation tasks. (Referencing the above, this is a sequence-level task)
04 Current Situation: Different Models Employ Different Training Objectives
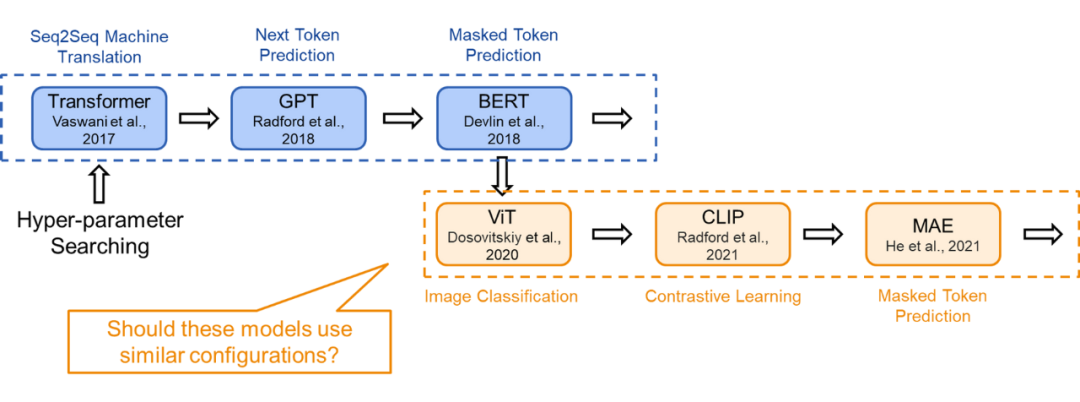
Currently, Transformer models are trained using various training objectives. Taking ViT as an example, we can train Transformer models from scratch in a supervised learning environment for image classification. In this direct image classification task, each image is modeled as a token sequence, where each token corresponds to a patch in the image. We use the global information from all tokens (i.e., patches) from the image to predict a single label, namely the image class.
Here, since the training objective is to capture the global information of the image, the differences between token representations are not directly considered. This training objective is completely different from machine translation tasks, which require the model to understand the token sequence and generate another sequence based on it.
Accordingly, we can reasonably assume that there should be different optimal Transformer configurations for these two different tasks.
05 Adjusting Model Structure for MAE Training Objectives
Based on the discussions above, we have the following insights:
-
Existing Transformer models encounter the over-smoothing problem when deepening model depth, hindering model scaling in depth. -
Compared to simple classification training objectives, the masked prediction task of MAE can alleviate over-smoothing. (Furthermore, token-level training objectives can alleviate over-smoothing to some extent.) -
The existing model structure of MAE inherits the best structural settings from machine translation tasks, which may not be reasonable.

Considering the above three points, it can be inferred that MAE should be able to scale better in depth, meaning using deeper model architectures. This paper explores the performance of MAE under deeper, narrower model settings: using the Bamboo model configuration proposed in this paper (deeper, narrower), we can achieve significant performance improvements in vision and language tasks.
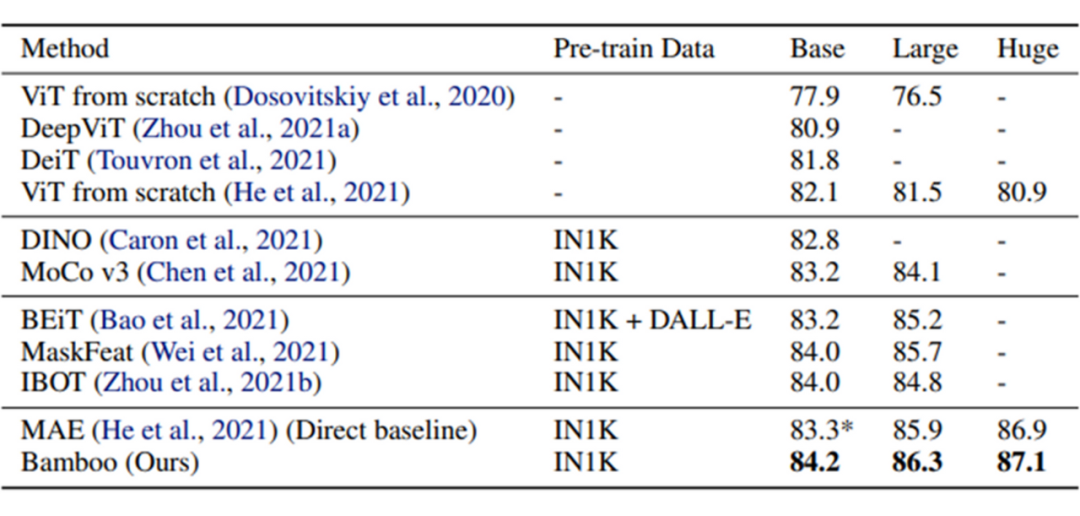
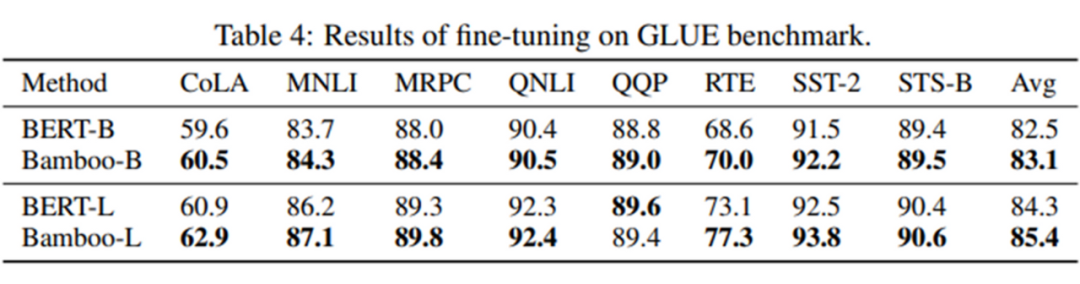
Additionally, we also conducted experiments on deep scalability and found that when using the Bamboo configuration, MAE can achieve significant performance improvements, while deeper models for ViT are harmful. MAE maintains performance improvements even when the depth increases to 48 layers, while ViT consistently trends towards performance decline.
The above results support the viewpoint proposed in this paper: training objectives can influence the scaling behavior of models. Training objectives can greatly change the scaling behavior.
06 Conclusion
This paper finds that there is a close relationship between the configuration of Transformers and their training objectives. Sequence-level training objectives, such as direct classification and CLIP, often encounter over-smoothing. In contrast, token-level training objectives, such as MAE and next token prediction in LLMs, can better alleviate over-smoothing. This conclusion explains many model scalability research results, such as the scalability of GPT-based LLMs and the phenomenon that MAE is more scalable than ViT. We believe this perspective will help our academic community understand the scaling behavior of many Transformer models.
Download 1: OpenCV-Contrib Extension Module Chinese Tutorial
Reply "Chinese Tutorial for Extension Module" in the backend of the "Beginner Learning Vision" public account to download the first Chinese version of the OpenCV extension module tutorial, covering installation of extension modules, SFM algorithms, stereo vision, object tracking, biological vision, super-resolution processing, and more than twenty chapters of content.
Download 2: Python Vision Practical Projects 52 Lectures
Reply "Python Vision Practical Projects" in the backend of the "Beginner Learning Vision" public account to download 31 vision practical projects including image segmentation, mask detection, lane line detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, facial recognition, etc., to assist in quickly learning computer vision.
Download 3: OpenCV Practical Projects 20 Lectures
Reply "OpenCV Practical Projects 20 Lectures" in the backend of the "Beginner Learning Vision" public account to download 20 practical projects based on OpenCV, achieving advanced learning of OpenCV.
Group Chat
Welcome to join the public account reader group to communicate with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (will gradually be subdivided in the future). Please scan the WeChat number below to join the group, and note: "Nickname + School/Company + Research Direction", for example: "Zhang San + Shanghai Jiao Tong University + Vision SLAM". Please follow the format, otherwise, it will not be approved. After successfully adding, you will be invited to the relevant WeChat group based on your research direction. Please do not send advertisements in the group, otherwise, you will be removed from the group. Thank you for your understanding~