The explosive popularity of ChatGPT proves the capabilities of large language models (LLMs) in generating knowledge and reasoning. However, ChatGPT is a model pre-trained on public datasets, which may not provide specific answers or results related to user businesses.
So, how can we maximize the capabilities of LLMs using private data? LlamaIndex can solve this problem. LlamaIndex is a simple, flexible, and centralized interface for connecting external data with LLMs.
Recently, Zilliz collaborated with LlamaIndex to hold a highly informative webinar. During the event, Jerry Liu, co-founder and CEO of LlamaIndex, introduced how to enhance LLM capabilities using private data through LlamaIndex.

01.
LlamaIndex: The Magic Tool for Enhancing LLM with Private Data
“How to enhance LLM with private data” is a major challenge for many LLM developers. In the webinar, Jerry proposed two methods: fine-tuning and context learning.
Fine-tuning refers to retraining the network using private data, but this approach is costly, lacks transparency, and may only be effective in certain cases. The other method is context learning. “Context learning” combines pre-trained models, external knowledge, and retrieval models, allowing developers to add context during the input prompt process. However, combining retrieval and content generation, and managing vast source data can make the entire process quite challenging. LlamaIndex tools are designed to address these issues.
The open-source tool LlamaIndex provides centralized data management and query interfaces for LLM applications. The LlamaIndex suite primarily consists of three components:
-
Data connector – used to receive data from various sources.
-
Data index – used to adjust data structures for different application scenarios.
-
Query interface – used to input prompts and receive results generated after knowledge expansion.
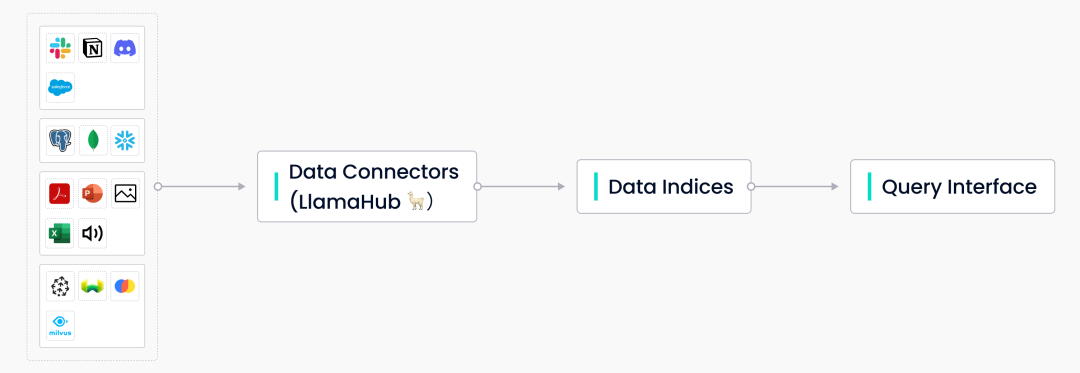
The Three Main Components of LlamaIndex
LlamaIndex is also an important tool for developing LLM applications. It acts like a black box, receiving detailed query descriptions and returning corresponding answers along with rich references. LlamaIndex can also manage the application integration between language models and private data, thus providing accurate results.

LlamaIndex in the Entire Application Process
02.
LlamaIndex vs Vector Retrieval
-
How LlamaIndex Vector Index Works
LlamaIndex supports various indexes, including list indexes, vector indexes, tree indexes, and keyword indexes. Jerry demonstrated the working principle of the LlamaIndex index using vector indexing as an example during the webinar. Vector indexing is a common retrieval and data integration pattern that pairs vector repositories with language models. LlamaIndex vector indexing first receives a set of source document data, splits the documents into text segments, and stores these segments in a built-in vector repository, each segment corresponding to a respective vector. When a user queries, the query is first converted into a vector, and then the top-k most similar vector data is retrieved from the vector storage system. Subsequently, these retrieved similar vector data will be used in the corresponding synthesis module to generate results.
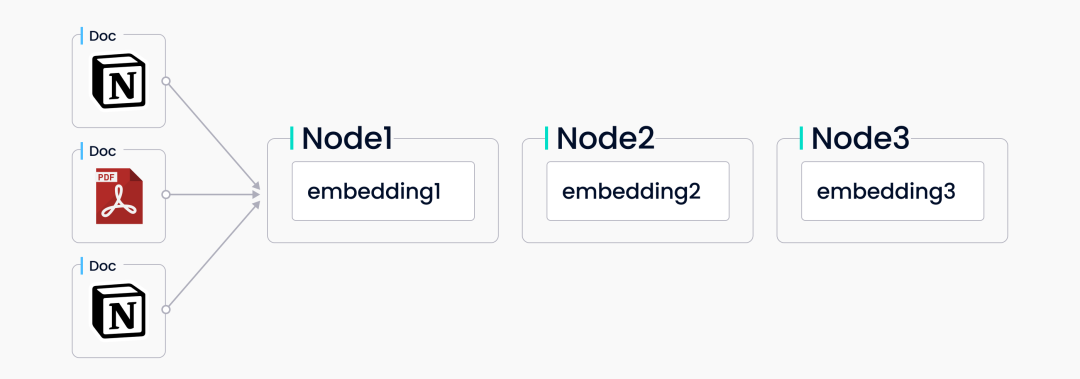
LlamaIndex Receives Data
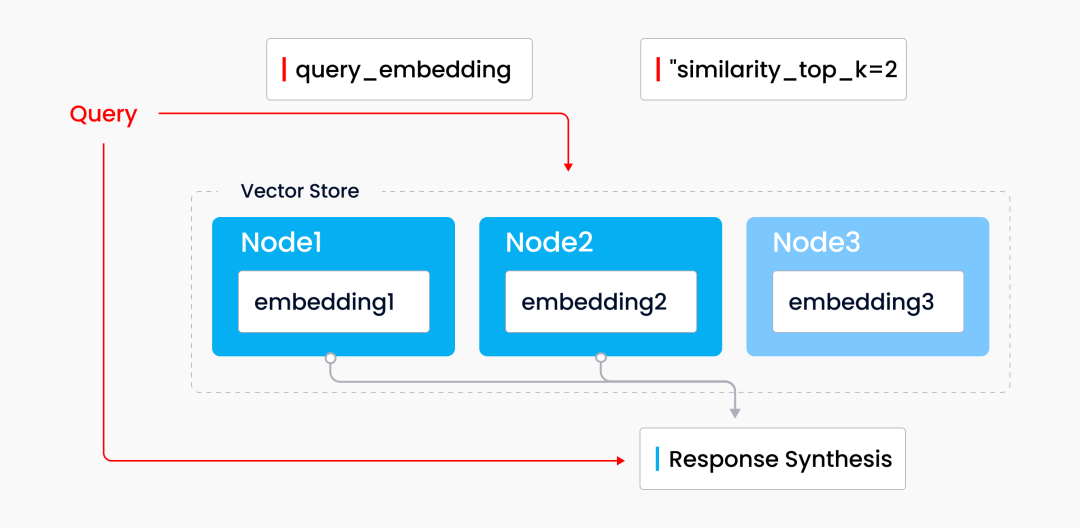
Querying Through the Vector Storage System
For users who have a strong need for similarity retrieval in LLM applications, the index of the vector storage system is the best choice. This type of index is particularly suitable for semantic similarity retrieval as it can compare different texts. For example, vector storage indexes are suitable for building Q&A bots that can answer various questions about specific open-source projects (see OSSChat).
-
Integrating Milvus and LlamaIndex
LlamaIndex integration is diverse and lightweight. In this webinar, Jerry emphasized the integration of Milvus and LlamaIndex (see: https://milvus.io/docs/integrate_with_llama.md).
The open-source vector database Milvus can handle vector datasets ranging from millions to billions or even trillions. In this integration, Milvus acts as the back-end vector library for storing text segments and vectors. Integrating Milvus and LlamaIndex is also quite simple – just input a few parameters and add Milvus during the vector storage phase to obtain answers through the query engine.
Of course, Zilliz Cloud, which provides fully managed cloud-native Milvus services, also supports integration with LlamaIndex (see: https://zilliz.com/doc/integrate_with_llama).
03.
LlamaIndex Application Cases
In the webinar, Jerry also shared many typical application scenarios of LlamaIndex, including:
-
Semantic search
-
Summarization
-
Text to SQL structured data conversion
-
Synthesizing heterogeneous data
-
Comparison/contrast queries
-
Multi-step queries
For more details on use cases, you can click 【Read Original】 to watch the video explanation.
04.
Highlights from the Q&A Session
1. What are your thoughts on OpenAI’s plugins? How can OpenAI plugins work in conjunction with LlamaIndex?
Jerry Liu: That’s a good question. On one hand, we are actually one of OpenAI’s plugins and can be called by any external agent, whether it is ChatGPT or LangChain; any external agent can call us. The client agent sends an input request to us, and we execute it in the best way. For example, our plugin can be found in the ChatGPT chatgpt-retrieval-plugin repository. On the other hand, from the client’s perspective, we support integration with any software service, as long as that service is a [chatgpt-retrieval-plugin]. (See https://github.com/openai/chatgpt-retrieval-plugin/blob/main/datastore/providers/llama_datastore.py).
2. You mentioned trade-offs in performance and latency. What bottlenecks or challenges have you encountered in this regard?
Jerry Liu: If the context is richer and the text blocks are larger, the latency will also be higher. Some believe that larger text blocks lead to more accurate generated results, while others are skeptical. Overall, whether the size of text blocks affects performance results is still a matter of debate.
GPT-4 performs better than GPT-3 when handling questions with more context. But generally speaking, I believe that the size of text blocks and performance results are still positively correlated. Another trade-off is that any advanced LLM system needs to be called in a chain method, which also increases the time required for execution.
3. Is it safe to transmit private data when using external models to execute queries?
Jerry Liu: It depends on the API services used. For example, OpenAI does not use API data to train or optimize its models. However, some enterprises still worry about OpenAI sending sensitive data to third parties. Therefore, we recently added a PII module to address this issue. Another solution is to use local models.
4. What are the pros and cons of the following two methods? Method 1: Using a vector database like Milvus for similarity retrieval and graph indexing optimization before loading data and building indexes on LlamaIndex. Method 2: Using LlamaIndex’s native vector store integration?
Jerry Liu: Both methods are viable. We are planning to integrate these two methods. Stay tuned.
If you load data using Milvus, users can use LlamaIndex on existing data. If you use the vector index provided by Milvus in LlamaIndex, we will redefine the data structure based on existing data. The advantage of the former is that users can directly use existing data, while the advantage of the latter is that metadata can be defined.
5. I need to analyze about 6,000 PDF and PowerPoint files locally. How can I get the best analysis results without using OpenAI and LlamaIndex’s llama65b model?
Jerry Liu: If you can accept the Llama license, I still recommend trying Llama.
Check the link for open-source models on GitHub (https://github.com/underlines/awesome-marketing-datascience/blob/master/awesome-ai.md#llama-models).
🌟【Special Reminder】To provide users with a smoother experience on Zilliz Cloud, we will also be landing on Alibaba Cloud by the end of June this year, and cooperation with several other cloud providers is also on the agenda. Stay tuned!