This series of tutorials serves as notes for the book “Hands-On Machine Learning.” First, let’s discuss the reasons for writing this series: First, the code in “Hands-On Machine Learning” is written in Python 2, and some of the code will throw errors when run on Python 3. This tutorial revises the code based on Python 3; second, I previously read several machine learning books without taking notes, which led to quickly forgetting the content. Writing this tutorial also serves as a review process; third, machine learning is more challenging to learn compared to web scraping and data analysis. I hope this series of written tutorials can help readers avoid detours on their machine learning journey.
Features of This Series:
-
Based on “Hands-On Machine Learning”
-
Avoid excessive mathematical formulas, explaining each algorithm’s principles in a simple and straightforward manner
-
Detailed explanation of the code for algorithm implementation
Who Can Benefit:
-
Those who understand the basic terminology of machine learning
-
Those who can code in Python
-
Those familiar with the use of numpy and pandas libraries
K-Nearest Neighbors (KNN) Algorithm Principle
The KNN algorithm is a classification algorithm. A saying to describe the KNN algorithm is: “Birds of a feather flock together.” The principle of the algorithm is to calculate the distance between the test sample and each training sample (the method for distance calculation is described below), take the k training samples with the smallest distances, and finally choose the most frequent classification among these k samples as the classification for the test sample. As shown in the figure, the green point is the test sample. When k is 3, this sample belongs to the red class; when k is 5, it belongs to the blue class. Therefore, the choice of k value greatly affects the result of the algorithm, and typically, k should not exceed 20.
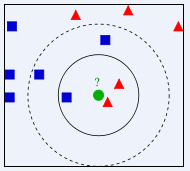
KNN Algorithm Principle
After introducing the principle, let’s look at the pseudocode flow of the KNN algorithm:
Calculate the distance between the test sample and all training samples
Sort the distances in ascending order and take the top k
Calculate the most frequent classification among the k samples
KNN for Dating Object Classification
Problem Description and Data Situation
Helen uses a dating website to find a partner. After some time, she discovers that she has dated three types of people:
-
People she does not like
-
People of average charm
-
Highly charming people
Here, Helen collected 1000 rows of data, with three features: the number of frequent flyer miles earned per year, the percentage of time spent playing video games, and the number of liters of ice cream consumed weekly. The type labels of the objects are shown in the figure.
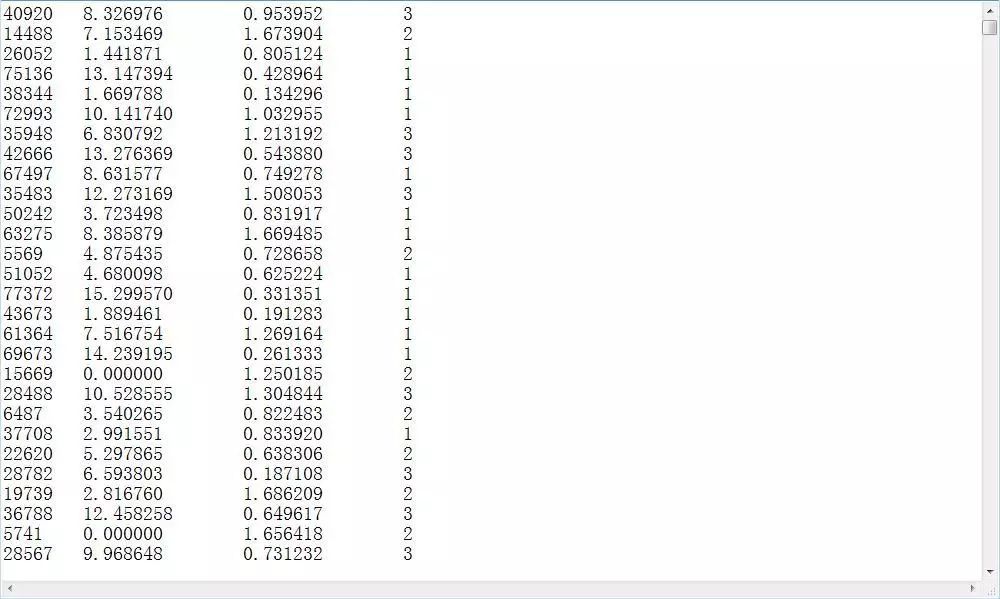
Data Situation
Data Parsing
import numpy as np
import operator
def file2matrix(filename):
fr = open(filename)
arrayOLines = fr.readlines()
numberOflines = len(arrayOLines)
returnMat = np.zeros((numberOflines, 3))
classLabelVector = []
index = 0
for line in arrayOLines:
line = line.strip()
listFromLine = line.split('\t')
returnMat[index, :] = listFromLine[0:3]
classLabelVector.append(int(listFromLine[-1]))
index = index + 1
return returnMat, classLabelVector
The function defined to parse the data: lines 4-9 read the file and get the number of lines, creating a Numpy array of zeros with the same number of rows (1000) and 3 columns, and creating a list classLabelVector to store class labels. Lines 10-17 loop through the file, storing the first three columns of data in the returnMat array and the last column in the classLabelVector list. The result is shown in the figure.
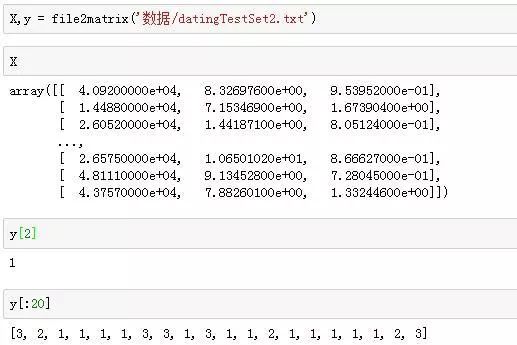
Data Parsing
The code above is what is written in the book. In fact, using pandas to read the data is much more convenient. The code is as follows:
import numpy as np
import operator
import pandas as pd
def file2matrix(filename):
data = pd.read_table(open(filename), sep='\t', header=None)
returnMat = data[[0,1,2]].values
classLabelVector = data[3].values
return returnMat, classLabelVector
Normalization
Due to the large differences in values between features, when calculating distances, attributes with larger values will have a greater impact on the results. Therefore, normalization of the data is needed: new = (old-min)/(max-min). The code is as follows:
def autoNorm(dataSet):
minval = dataSet.min(0)
maxval = dataSet.max(0)
ranges = maxval - minval
normDataSet = np.zeros(np.shape(dataSet))
m = dataSet.shape[0]
normDataSet = dataSet - np.tile(minval, (m,1))
normDataSet = normDataSet/np.tile(ranges, (m,1))
return normDataSet, ranges, minval
The parameter passed is the test data (which is returnMat); first, the min and max are calculated along axis 0 (i.e., by column), as shown in the simple example; then a zero matrix of the same size as the data (normDataSet) is constructed; the tile function is used to repeat a one-dimensional array m times, as shown in the example, which allows for the calculation of data normalization.


Example
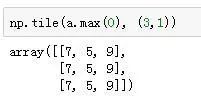
Example

Result
KNN Algorithm
The distance used here is the Euclidean distance, with the formula:
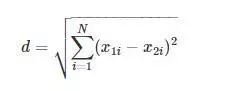
Euclidean Distance
def classify(inX, dataSet, labels, k):
dataSize = dataSet.shape[0]
diffMat = np.tile(inX, (dataSize,1)) -dataSet
sqdiffMat = diffMat ** 2
sqDistance = sqdiffMat.sum(axis = 1)
distances = sqDistance ** 0.5
sortedDist = distances.argsort()
classCount ={}
for i in range(k):
voteIlable = labels[sortedDist[i]]
classCount[voteIlable] = classCount.get(voteIlable, 0) + 1
sortedClassCount = sorted(classCount.items(),
key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
inX is the training data; dataSet is the test data; labels are the class labels; k is the value; lines 2-6 calculate the Euclidean distance; lines 7 to the end sort the calculated distances (argsort) and then sort the dictionary to obtain the most frequent classification.
Testing the Classifier
Here, the first 10% of the data is selected as the test sample to test the classifier.
def test():
r = 0.1
X, y = file2matrix('data/datingTestSet2.txt')
new_X, ranges, minval = autoNorm(X)
m = new_X.shape[0]
numTestVecs = int(m*r)
error = 0.0
for i in range(numTestVecs):
result = classify(new_X[i, :],new_X[numTestVecs:m, :], y[numTestVecs:m], 3)
print('Classification result: %d, Actual data: %d' %(result, y[i]))
if (result != y[i]):
error = error + 1.0
print('Error rate: %f' % (error/float(numTestVecs)))

Result
Testing System
Finally, a simple testing system is written. This code allows for manual input of three attribute features to automatically obtain the classification label of the dating object.
def system():
style = ['Dislike', 'Average', 'Like']
ffmile = float(input('Frequent flyer miles'))
game = float(input('Games'))
ice = float(input('Ice cream'))
X, y = file2matrix('data/datingTestSet2.txt')
new_X, ranges, minval = autoNorm(X)
inArr = np.array([ffmile, game, ice])
result = classify((inArr - minval)/ranges, new_X, y, 3)
print('This person is', style[result - 1])

Result
Advantages and Disadvantages of the Algorithm
-
Advantages: High accuracy, insensitive to outliers
-
Disadvantages: Computational complexity (consider that each test sample must calculate distances with all training samples)
Author:Luolopan, Column author of Python Chinese Community, Author of the book “Learning Web Scraping from Scratch.” Column address: http://www.jianshu.com/u/9104ebf5e177

The Python Chinese Community, as a decentralized global technology community, aims to become the spiritual tribe of 200,000 Chinese Python developers worldwide. It currently covers major mainstream media and collaboration platforms and has established extensive connections with well-known companies and technology communities such as Alibaba, Tencent, Baidu, Microsoft, Amazon, Open Source China, CSDN, etc. It has tens of thousands of registered members from more than a dozen countries and regions, with members from government agencies, research institutions, financial institutions, and well-known companies both domestically and internationally, including the Ministry of Public Security, the Ministry of Industry and Information Technology, Tsinghua University, Peking University, Beijing University of Posts and Telecommunications, the People’s Bank of China, the Chinese Academy of Sciences, China International Capital Corporation, Huawei, BAT, Google, Microsoft, etc. Nearly 200,000 developers follow the platform.

▼ Click belowto read the original text, and become acommunity member for free