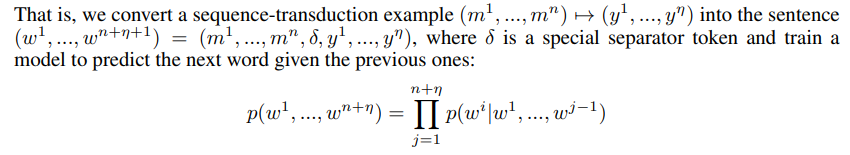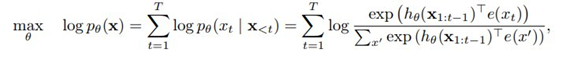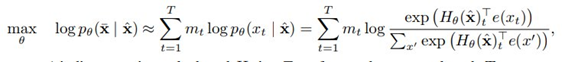This article starts from the ancestor level word2vec and systematically sorts out the “genealogy” of GPT and the large NLP “family group” led by word2vec.
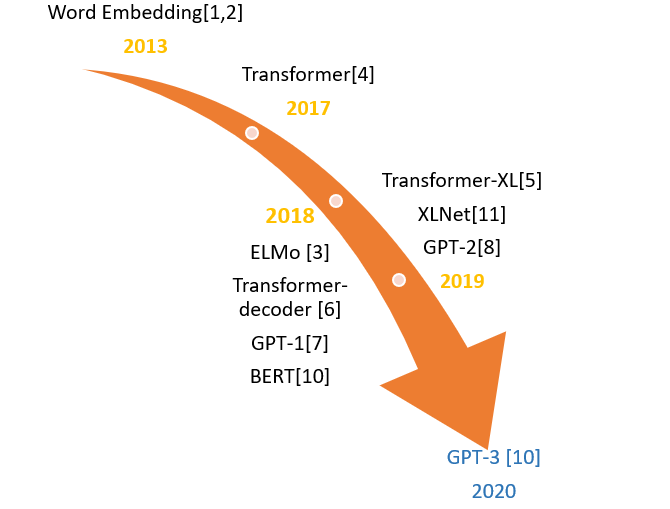
GPT did not emerge out of nowhere; it is the result of the efforts of many people and a long period of evolution. Therefore, it is necessary to sort out the vast “family” of GPT to see what it has inherited, learned, and improved, which helps in better understanding the principles behind each part of GPT.Now many people regard 2018 (the year BERT was proposed) as the inaugural year of NLP (similar to the introduction of ImageNet at that time), and its trend is extremely similar to that of the image field back then—models are getting larger. The parameter count of BERT-large (the largest BERT model) in 2018 was 340M, while by 2020, GPT-3 had multiplied this number countless times. Many people first learned about GPT around 2018, when GPT was still a supporting character (brought to light by its brother BERT), with BERT being the protagonist. BERT’s success also made ELMo and GPT, which were predecessors in the papers at that time, gain popularity. In fact, GPT at that time was not as poor as stated in the first version of the BERT paper; the comparative images from that time have also disappeared from the recent BERT papers, while the recent GPT-3 has summarized the failures of the past and has begun to emphasize media promotion, allowing GPT to successfully debut as the main character.When GPT-3 is mentioned, the first impression everyone has is probably its extraordinarily large parameter count—175 billion, which is 100 times more than its predecessor and 10 times more than the previous largest NLP model of its kind. In fact, today’s GPT-3 is the result of a long period of evolution (gathering the excellent wisdom of its ancestors). Starting from word2vec, various language models began to dazzle people, and many provided significant inspiration for the birth of GPT. Today, we will start from the ancestor level word2vec, systematically sorting out the “genealogy” of GPT and the large NLP “family group” led by word2vec.It is worth noting that the family members listed here are all closely related to GPT, so the content listed in this article cannot fully encompass the development of all language models. The main purpose of this article is to sort out the principles of GPT and make necessary comparisons with similar models to deepen understanding.Overview of GenealogyTo better establish a “genealogy” for GPT and let you know what this article will cover, we first need to macroscopically compare the birth dates of the various members of this large family (Figure 1).
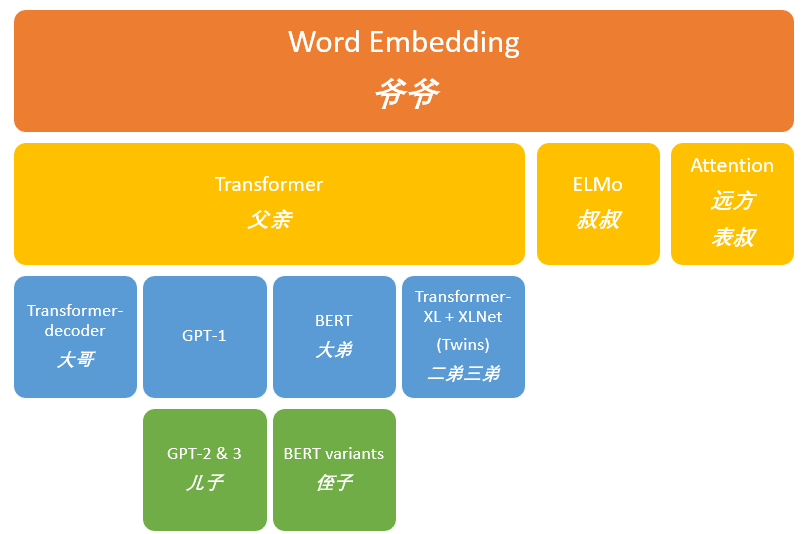
Figure 1: Birth dates of family members.With this birth date table, and after having some understanding of them (the main purpose of this article), their relationships can be easily determined. Therefore, the genealogy of this large family can be roughly illustrated as shown in Figure 2.
Figure 2: The genealogy of GPT.At this point, if you are not familiar with these models or have never heard of them, that’s okay. Observant readers may notice that the birth date of Attention is not listed in Figure 1, as Attention is considered a distant relative of GPT. Due to the particularity of Attention’s business (mainly outsourcing work, which will be detailed later), GPT does not have a complete inheritance relationship with it, but GPT and its siblings all bear the influence of Attention.Having gained a macro understanding of the genealogy of GPT, we can formally enter the main topic.Word Embedding [1,2]Word Embedding, as the founder of this large family group, has laid a solid foundation for the vigorous development of the entire “group”. Up to now, word embedding has always been the backbone of the NLP group. Methods such as Word2Vec and Glove are good examples. To avoid misunderstanding the foundation of the “group”, a brief introduction to word embedding will be given here.For words that need to be processed by machine learning models, they need to be represented in some form of numerical representation for use in the model (vectors). The idea of Word2Vec is that we can use a vector (number) to represent the semantics of a word and the relationships between words (similar or opposite, for example, the relationship between “Stockholm” and “Sweden” is similar to that between “Cairo” and “Egypt”), as well as grammatical relationships (such as the relationship between ‘had’ and ‘has’ in English is similar to that between ‘was’ and ‘is’).This founder quickly realized that he could pre-train the model on a large amount of text data to obtain embeddings, which is more effective than training on specific tasks (with less data). Thus, downloadable pre-trained word vector tables like word2vec and Glove (where each word has its corresponding word vector) emerged. Figure 3 shows the corresponding word embedding of the word ‘stick’ in GloVe (partial).
Figure 3: The word vector of “stick” (Image source: [15])ELMo [3] – Context is Important!After the grandfather created this family business, many descendants continued to develop it, and among GPT’s close relatives, there is one—ELMo (February 2018). This uncle of GPT-3 was showcased alongside GPT-1 by BERT in 2018 (for comparison), so it should be familiar to everyone. When ELMo was established, the Transformer had not yet been refined, and the son of Transformer, Transformer-decoder (January 2018), had not yet gained popularity. Therefore, he did not use the Transformer (which is why he was compared with BERT in the initial paper), but he noticed that word vectors cannot be invariant. For example, when learning word embeddings, the following two sentences were used:
“Oh! You bought my favorite pizza, I love you!”
“Ah, I really love you! You dropped my favorite pizza on the ground?”
Here, the meaning of “love” is obviously different, but because the training did not see the words that follow “love”, it was defined as a positive word in the word embedding space. First, we need to know that ELMo (Embedding from Language Model) also uses a “language model” task to complete contextual learning, which is also an important reason for mentioning ELMo in this article (another reason is its method to solve the problem posed above). To prevent anyone from being unfamiliar with the language model, here is a definition of a language model—A language model is actually a model that predicts the next word given a string of words..Understanding the concept of a language model makes it easy to understand the reason for the problem above—the model sees the preceding text but not the following text.To solve this problem, ELMo used a bidirectional LSTM to obtain bidirectional context.At the same time, the problems involved above are not just about bidirectional context; there is also a serious issue—word embeddings should not be invariant. In other words, the same word may have different meanings in different sentences, and thus the word embeddings should also be different.Therefore,ELMo proposed to provide the embedding of this word based on the understanding of the entire sentence.In other words, the source of the word embedding is no longer past lookup tables, but rather obtained through pre-trained models (isn’t that similar to transfer learning in the image field?). Look at the original paper’s definition of ELMo:
Our word vectors are learned functions of the internal states of a deep bidirectional language model (biLM), which is pretrained on a large text corpus.
Ultimately, these ideas brought great inspiration to his nephews (GPT, BERT, etc.). If you are interested in the computational details of ELMo, I have attached references at the end of this article; you can take a look at the original paper, as it contains many clever ideas. However, it is not the main character of our discussion today, so I won’t elaborate further.[Side Note] AttentionAfter discussing ELMo, we should have started introducing the backbone of the current family group, BERT and GPT. However, before that, it is necessary to briefly review attention and self-attention. I guess many people who have recently joined NLP, like me, have received the concept of self-attention and the calculation process of self-attention from various popular science articles, but many authors of popular science articles are confused about the origin of the name self-attention, leading to many different versions when I tried to verify my understanding. However, we must stay true to the original paper, so let’s start with the original definition of Attention in the earliest paper. Many popular science articles on attention will begin with a vivid description of the principles of attention. As the name suggests, we want our model to focus on important points when providing us with results, rather than blindly looking at everything. Machine Heart has many interesting explanations for attention, but I won’t waste space repeating them; let’s go straight to the formal definition:
An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key.
——Attention is all you need
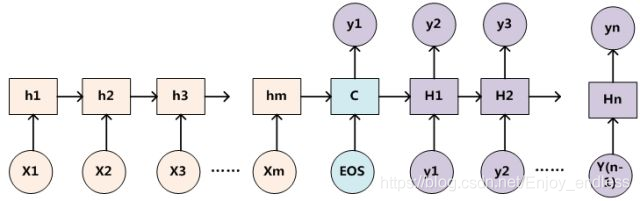
This means that in the attention mechanism, there are mainly three vectors—key, query, and value. In fact, the attention mechanism can be viewed as a form of soft addressing: Source can be seen as a storage box for a Chinese medicine shop, where the medicines in the box are composed of address Key (medicine name) and value Value (medicine). When there is a query Key=Query (prescription), the goal is to retrieve the corresponding Value (medicine) from the storage box, which is the Attention value. By comparing the similarity between the Query and the elements’ Key in the storage box, we can address it. The reason it is called soft addressing is that we not only find one medicine from the storage box but may take out content from each Key address, and the importance of the content (the amount) is determined by the similarity between Query and Key. After that, we perform a weighted sum on the Value to obtain the final Value (a prescription), which is also the Attention value. Therefore, many researchers consider the attention mechanism as a special case of soft addressing, which is very reasonable[12]. Just stating the theory without details is meaningless, so let’s look at who the clients of Attention as an outsourcing company are.RNN & LSTMIn this section, we will use the machine translation task as an example to introduce the problems raised by the client RNN and the solutions provided by Attention. First, let’s look at the original solution proposed by RNN (Figure 4).
Figure 4: Original RNN solution (Image source: [12])In the original solution, the information of the sequence to be translated (X) is summarized in the last hidden state (h_m), which bears the heavy responsibility of carrying all the information of the original sentence. This h_m is ultimately used to generate the translated language (Y), and the problem with this scheme is obvious. The capacity of h_3 is limited, and when the sentence is long, it is easy to lose important information. The question has been raised; what solution did Attention provide?
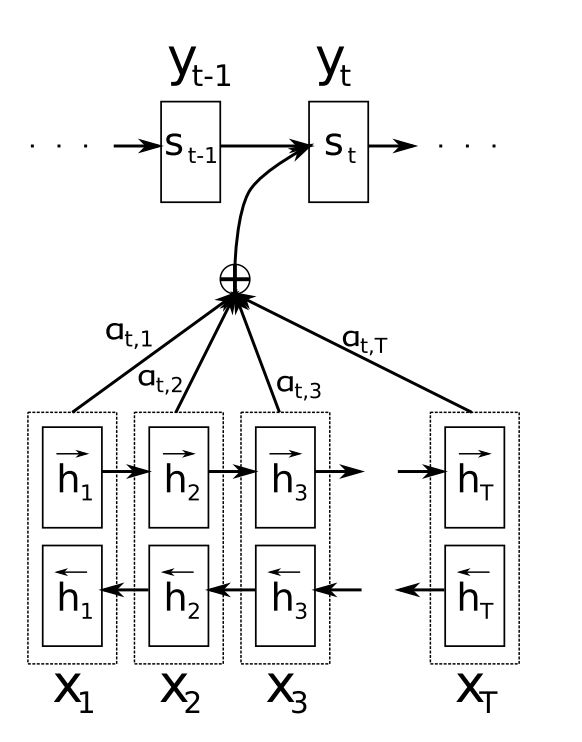
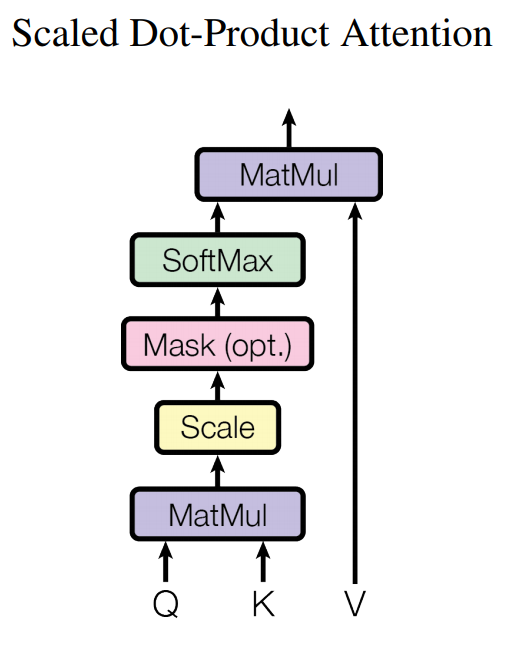
Figure 5: The final solution provided by Attention (Image source: [13])Before formally introducing the solution provided by Attention, let’s briefly review the calculation process of Attention (the Attention mentioned here is referred to as Scaled Dot-Product Attention in Transformer).
Figure 6: Attention calculation process (Image source: [4])As shown in Figure 6, Q and K first calculate the degree of connection (using dot-product here), and then through scaling and softmax, the final attention values are obtained. These attention values are multiplied by V to obtain the final matrix.After reviewing the calculation process of Attention, the scheme shown in Figure 5 becomes much easier to understand. It is still an encoder-decoder structure, where the upper part is the decoder and the lower part is the encoder (bidirectional RNN). The initial process is the same as the original version of RNN. First, the Encoder obtains the hidden state (h) of the input sequence X, and then the decoder can start working. From here, the work of the decoder begins to change due to the addition of Attention. When generating s_t and y_t, the decoder needs to first utilize s_{t-1} and the correlation of various hidden states to obtain attention (a). These attention values ultimately serve as weights for each h, performing a weighted sum to obtain the context vector (context), and then there is no significant change; y_t is generated based on s_{t-1}, y_{t-1}, and context.To better understand what Figure 5 is doing, we can relate the symbols in the figure to the three types of vectors we discussed earlier in the Attention:
During the query process, our goal is to determine the weight of h in the context matrix based on the correlation between h and s, so the topmost s_t is the query vector used for retrieval;
If you understand the previous point and the interpretation of the Attention mechanism, then h_t is easy to understand; it is the key and value vector mentioned earlier.
Although the Attention mechanism in LSTM is not as obvious, its internal Gate mechanism can also be considered a form of Attention to some extent, where the input gate decides which current information to input, and the forget gate decides which past information to forget. LSTM claims to solve the long-term dependency problem, but in reality, LSTM still needs to capture sequential information step by step, and its performance on long texts will gradually decline as the steps increase, making it difficult to retain all useful information.In summary, the Attention mechanism during the outsourcing phase focuses on weighting all hidden states of each step, concentrating attention on the more important hidden state information throughout the text.In addition to bringing performance improvements to the model, these Attention values can also be used for visualization, allowing us to observe which steps are important, but caution is needed to avoid overfitting, and it also increases computational load.Establishing Independence — Self-attentionWhen Attention started its own business, its excellent outsourcing solutions caught the attention of Transformer, which began to consider whether the core ideas of the Attention company could stand on their own. Without hesitation, Transformer expressed this idea to its distant relative Attention, and they quickly reached an agreement, after diligent research, they excitedly shouted their slogan—”Attention is all you need!” Thus, the Transformer company was born![The Ancestor of Revival] Transformer: Attention is Enough!Connecting Past and Future — Self-attentionWhat exactly did they do? In simple terms, they used an improved version of self-attention to bring attention from a supporting role to the main role. To prevent my paraphrasing from causing misunderstandings, I will first quote the original text introducing the attention mechanism of various components in the Transformer (for convenience, I slightly adjusted the order):
The encoder contains self-attention layers. In a self-attention layer, all of the keys, values and queries come from the same place, in this case, the output of the previous layer in the encoder. Each position in the encoder can attend to all positions in the previous layer of the encoder.
Similarly, self-attention layers in the decoder allow each position in the decoder to attend to all positions in the decoder up to and including that position. We need to prevent leftward information flow in the decoder to preserve the auto-regressive property. We implement this inside of scaled dot-product attention by masking out (setting to −∞) all values in the input of the softmax which correspond to illegal connections.
In “encoder-decoder attention” layers, the queries come from the previous decoder layer, and the memory keys and values come from the output of the encoder. This allows every position in the decoder to attend over all positions in the input sequence.
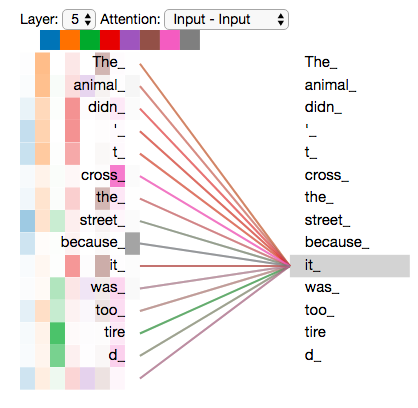
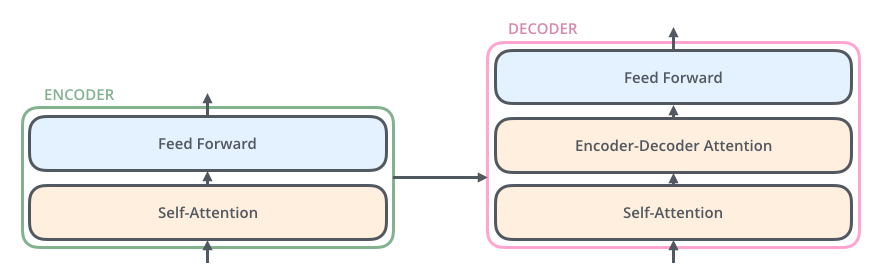
It can be seen that Transformer mainly utilizes two types of Attention—Self-attention and encoder-decoder attention. The Self-attention here is primarily aimed at eliminating external forces (LSTM, RNN, CNN, etc.), while the encoder-decoder attention continues the previous outsourcing solution (Figure 5), serving the same purpose of connecting the encoder and decoder.The Self Attention here, as the name implies, does not refer to the Attention mechanism between Target and Source, but rather the Attention mechanism occurring between elements within Source or within Target, which can also be understood as the attention calculation mechanism in the special case where Target=Source[12]..Let’s continue with the machine translation example. Suppose we want to translate from English (knowledge is powerful) to Chinese (知识就是力量). In the previous scheme without self-attention, Knowledge is powerful is first converted into hidden states, which serve as keys and values, while the query comes from s in the decoder. After introducing self-attention, the hidden states no longer need to be learned; the query directly comes from Knowledge is powerful, and the outcome of self-attention can be compared to the hidden state in RNN from Figure 5. In other words, self-attention accomplishes what RNN did solely through attention.
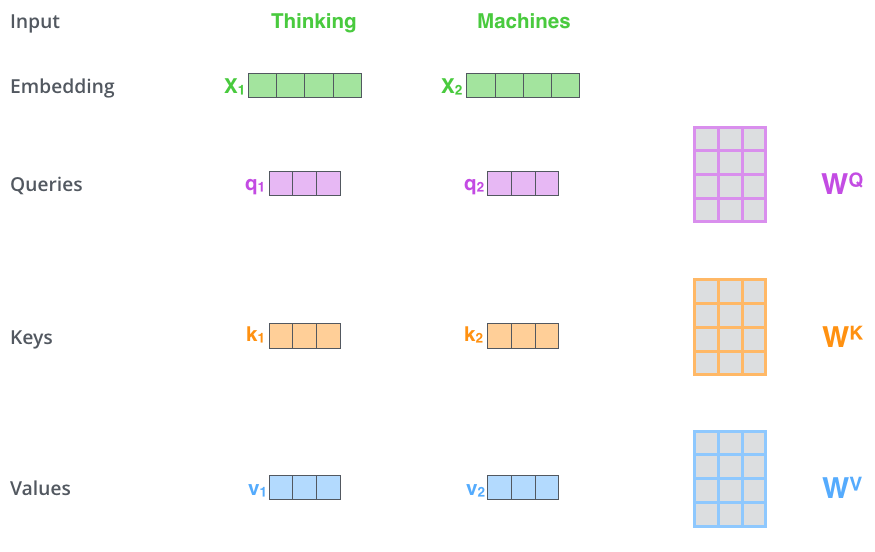
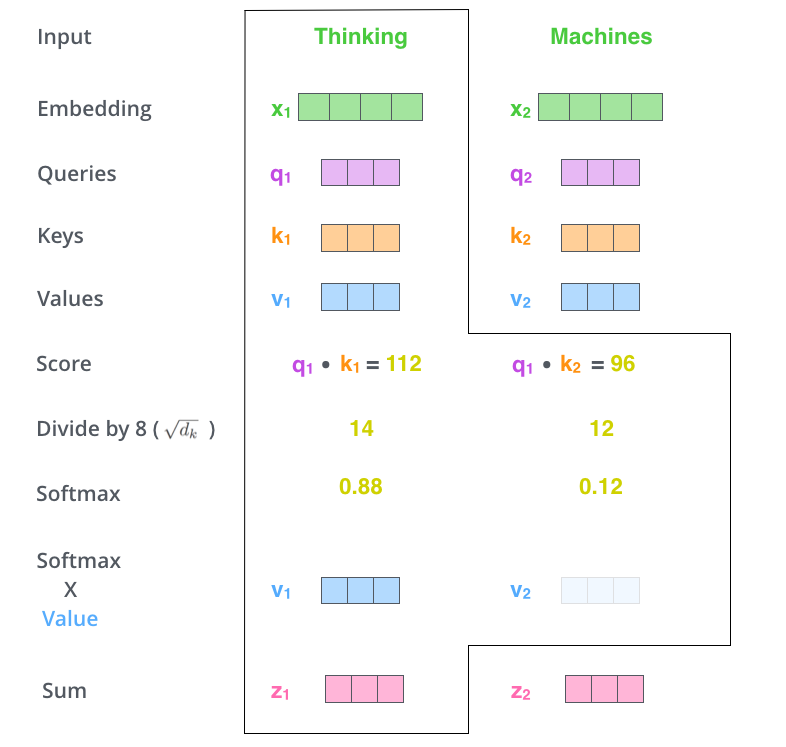
Figure 7: Visualization of self-attention (Image source: http://jalammar.github.io/illustrated-transformer/)Figure 7 visualizes the results of self-attention in a certain layer. The attention values are all relative to this sentence itself (including the word itself), and this figure vividly illustrates the meaning of self. At the same time, we can see that compared to traditional time series models, the advantages of self-attention are quite obvious—it can effectively focus on what needs to be noted, regardless of the length of the article. The fourth chapter of the original paper [4] details the benefits of discarding external forces (it cannot be just for the sake of establishing independence; there must be advantages to doing so), but the reasons are not closely related to the main line, so I won’t act as a porter here.In summary, the introduction of self-attention gave the Attention mechanism the same status as networks like CNN and RNN (they all established their own companies), but it can be seen that this approach has significant limitations, so the offspring of Transformer have hardly fully adopted Transformer; they have selectively retained parts.Details of Self-attention CalculationHowever, understanding self-attention is crucial for understanding the core differences between these sibling enterprises, so we will take the liberty of providing a specific calculation example (from several articles by Jalammar; if you already understand it, you can skip it): First, we multiply X_i by various W (trainable weight matrices) to obtain the query, key, and value matrices (as shown in Figure 8):
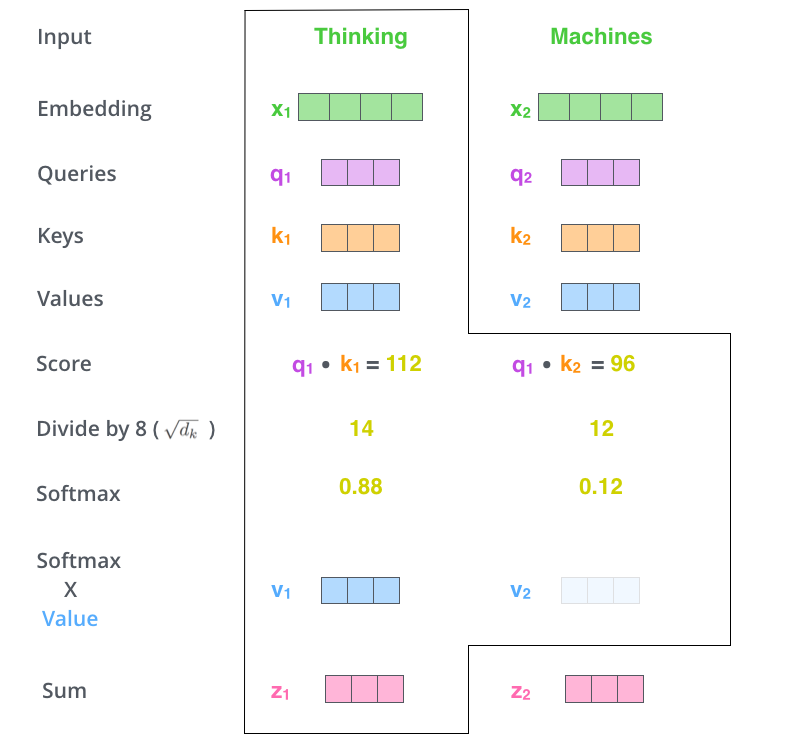
Figure 8: Original self-attention matrix (Image source: http://jalammar.github.io/illustrated-transformer/)Then, we follow the steps shown in Figure 9 to calculate the score, normalize (divide), and finally use softmax to obtain the attention score. This attention score is then used as the weight to compute the weighted sum of v1 and v2, yielding the output value of self-attention at this position (the word thinking).
Figure 9: Calculation process of self-attention (Image source: http://jalammar.github.io/illustrated-transformer/)Figure 10: Details of self-attention matrix (Image source: http://jalammar.github.io/)Significant DifferencesHaving introduced so much, including the original text of the papers, one important purpose is to emphasize that the self-attention layers in the encoder and decoder are different! In the encoder, when performing self-attention, it can “attend to all positions,” whereas the decoder can only “attend to all positions in the decoder up to and including that position” (highlighting an important distinction between BERT and GPT). In simple terms, the decoder, like previous language models, can only see the preceding information, while the encoder can see the complete information (bidirectional information). Specific details will be elaborated when introducing BERT and GPT.[The New Wave Era] BERT & GPT & OthersIf you are observant enough, you may have noticed that the examples I mentioned earlier are almost all related to machine translation. This is because the encoder-decoder structure of Transformer brings significant limitations. If you want to perform text classification tasks, it becomes quite challenging to use Transformer, and it is difficult to pre-train this model and then fine-tune it on various downstream tasks. Therefore, the offspring of Transformer have brought us a surprising new wave era.Firstborn Transformer-decoder [6] – Language Models are Back!The firstborn of Transformer first discovered the redundant mechanisms in its father’s company, and launched its two main brands:
In Chinese, it translates to: “Our model sees further after laying off (the encoder), and can still pretrain, just like the good old days (Language Modelling)!”
It can be seen that the firstborn is a ruthless boss. He discovered that he only needs to use part of the Transformer to achieve his desired language modeling, so he retained only the decoder, because the work of the decoder in the Transformer is to predict the next word based on the previous words (which is the same as the language modeling task). However, as previously mentioned (Figure 11), the Transformer not only proposed the self-attention mechanism but also retained the past encoder-decoder attention. Now that the encoder has been removed, the encoder-decoder attention layer is also gone.
Figure 11: Details of the encoder-decoder structure of Transformer (Image source: http://jalammar.github.io/)If you carefully read the previous sentence and then look at Figure 11 and remove the encoder-decoder attention layer accordingly, you will find that the structures of the encoder and decoder are identical! Then why do I still mention that BERT and GPT use different Transformers? First, let’s look at the description of the transformer decoder in Figure 12:
Figure 12: Details of the transformer decoder (Image source: [6])This means that originally, the decoder in Transformer was supposed to receive the information processed by the encoder from the input (m) and then obtain the final output (y). Moreover, when generating the subsequent y, it must consider the previously generated y. Therefore, after removing the encoder, the decoder must do more work, as its input now combines m and y, with
gamma separating the input and output (the ruthless boss indeed). Of course, doing this also means higher pay (the input sequence length increased from 512 to 1024).Based on the characteristics of regression language models, Transformer-decoder earned an excellent reputation for itself, which attracted the attention of its younger brother—GPT-1.Second Son GPT-1 – NLP Can Also Achieve Transfer LearningGPT-1 saw an opportunity in the success of his older brother Transformer-decoder and unearthed a more essential business opportunity—using pre-trained models for downstream tasks. Based on this idea, he launched his own brand:
We demonstrate that large gains on these tasks (downstream tasks) can be realized by generative pre-training of a language model on a diverse corpus of unlabeled text, followed by discriminative fine-tuning on each specific task.
This brand’s Generative Pre-Training (GPT) essentially does what the elder brother Transformer-decoder does, but there are indeed many troubles during fine-tuning. Therefore, the GPT-1 company thoughtfully made many flexible adjustments based on this and provided various solutions:
we make use of task-aware input transformations during fine-tuning to achieve effective transfer while requiring minimal changes to the model architecture.
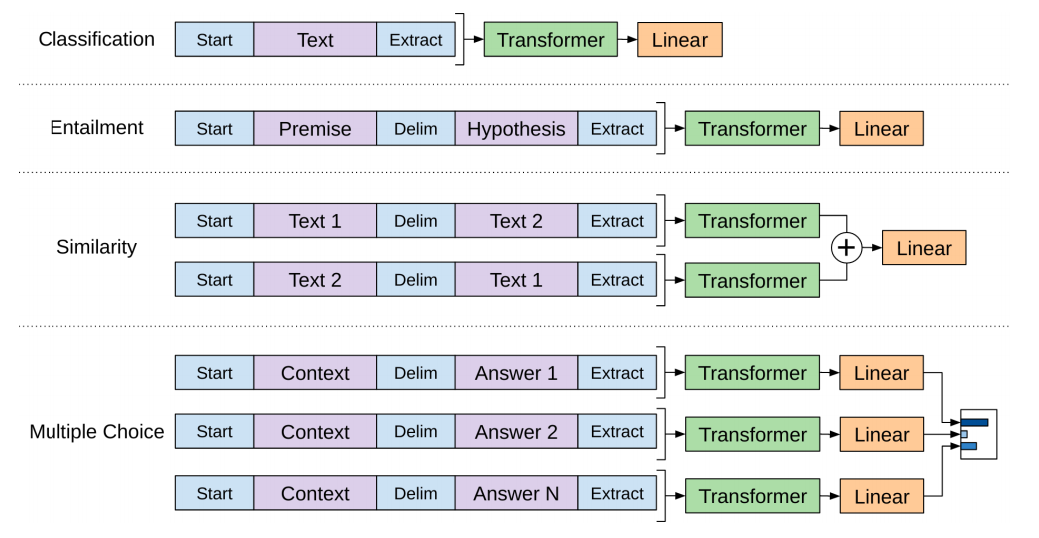
The specific workflow of GPT-1 is shown in Figure 13:
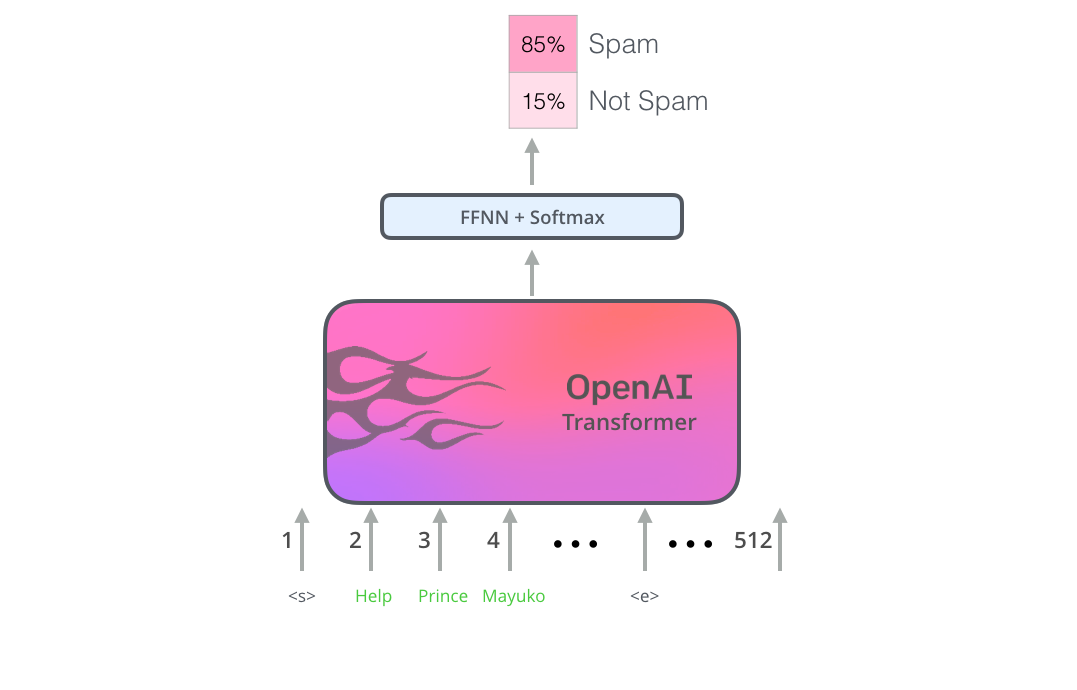
Figure 13: How to use GPT (OpenAI Transformer) for Finetuning (Image source: http://jalammar.github.io/)Figure 14 shows the finetuning scheme provided by GPT-1, which corresponds to the input transformation for different tasks. These solutions are very clever and have achieved many successes, making it widely applied. However, the popularity of GPT-1 did not reach the height of BERT because at that time, GPT-1 lacked sufficient business acumen and media promotion, thus being showcased as a “negative example” when its brother BERT opened its business. Of course, at that time, the GPT family’s ambition was not great, and its powerful few-shot learning strength had not yet been demonstrated (which GPT-2 began to do, detailed later).
Figure 14: How to perform Finetuning (Image source: http://jalammar.github.io/)Youngest Son BERT – The Encoder Can Also Support Half the SkyWhile the GPT company was thriving, the youngest son BERT was also growing quietly. Uncle ELMo loved this little son of his brother so much that he often brought him to the company to play and would tell him about their business. Thus, the concept of “bidirectional information is important” was deeply imprinted in little BERT’s mind. When he grew up and saw his brother GPT’s company’s promotional slogan, he thought, isn’t that just a language model? No, bidirectional information is not obtained; it needs to change! However, he did not want to directly enter Uncle ELMo’s company, and his father Transformer had directly abandoned one of the core technologies of Uncle’s company—LSTM, so bidirectional information could not be directly applied in Transformer (looking at the working mechanisms of LSTM and the decoder based on self-attention, it can be found that the decoder cannot obtain reverse information like LSTM).After deep contemplation, he suddenly realized that his father’s Encoder was the best choice! His brothers used the Decoder for language modeling, so why not use the Encoder? Moreover, he could obtain bidirectional information (Masked Language Model, MLM). The basic idea of MLM is that the self-attention mechanism is not supposed to mainly focus on itself (similar to looking in the mirror), so I will cover your face and let you guess your appearance based on the looks of your siblings (the information from the front and back), and once you can guess it accurately, you can go out to work.But little BERT was still too naive. Since his brother chose the decoder, there must be a reason. For example, a very practical issue is that since BERT uses the Encoder, the input is a masked sentence. How can he handle the “two-sentence problem” (e.g., given two sentences, determine whether they express the same meaning)? After careful consideration, BERT decided to learn the characteristics of his brothers’ language models and added the Next Sentence Prediction task during pre-training—given sentence A, you must guess whether sentence B is the next sentence after A, thus learning the relationship between sentences. At this point, the BERT company could officially open for business. The specific business and workflow are shown in Figure 15:
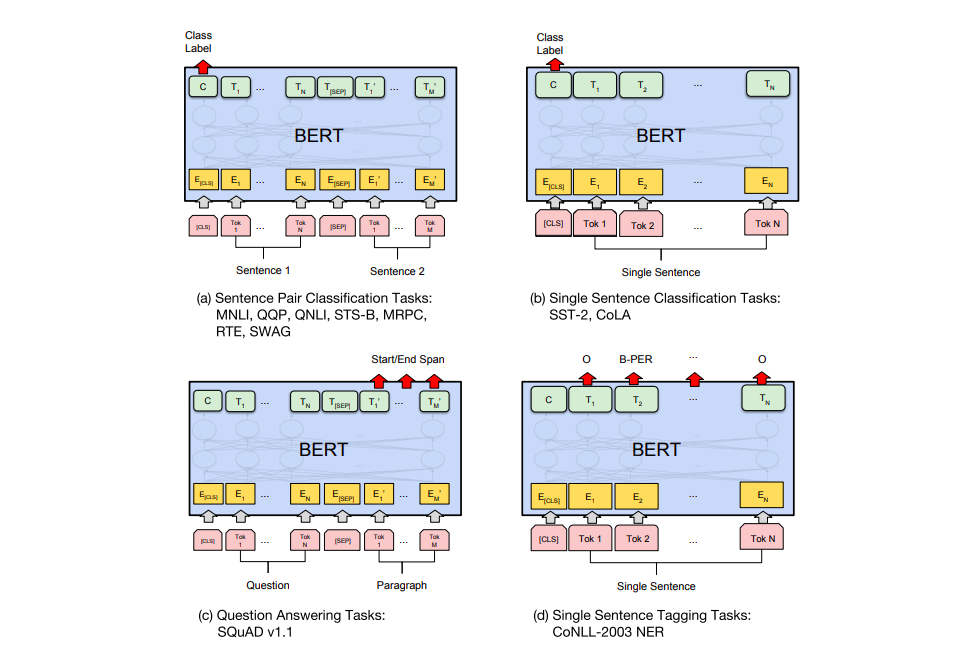
Figure 15: BERT’s business (Image source: [10])Finally, it is important to mention the difference between Encoder and Decoder. Essentially, it is the difference between autoregressive models (Auto regression) and autoencoder models (Auto Encoder). They are not in a better or worse relationship but rather a trade-off relationship. BERT chose the Encoder, which brought a significant problem. The Encoder does not possess the autoregressive characteristics of the Decoder (Auto Regressive), and the autoregressive characteristic allows the model to have a clear probabilistic basis. This distinction became particularly evident when XLNet (one of the less important offspring, which will be mentioned later) was introduced, as XLNet belongs to the autoregressive model while BERT belongs to the autoencoder model. To better understand the differences between AR and AE models, let’s take a look at the objective functions of BERT and XLNet:This is XLNet (AR):
This is BERT (AE):
The specific meanings of these two formulas will not be detailed here; those interested can refer to the original papers. The reason I present these two objective functions is to emphasize the difference between the “=” of XLNet and the “≈” of BERT. This “≈” comes at the cost of abandoning autoregressive characteristics. As for the specific principles, it is due to the fact that the tokens being predicted in the input are masked, so BERT cannot use the product rule to model joint probabilities like autoregressive language modeling. It can only assume that the masked tokens are independent, and this “≈” arises from this assumption. Moreover, because the real data during model fine-tuning lacks the artificial symbols like [MASK] used during BERT’s pre-training, the differences between pre-training and fine-tuning may arise. Autoregressive models do not need to introduce such noise into the input, so they do not encounter this issue.The reason why his brothers chose AR models is that AR models perform better in generative tasks, as generative tasks are generally unidirectional and forward, and GPT’s brand explicitly states that their main work is Generative Pre-training. Thus, the distinction between AR and AE, specifically choosing between encoder and decoder, is fundamentally a trade-off; the most suitable one is the best.[Rumors] The Bastards of TransformerThe bastards, due to their lack of attention, tend to work extra hard to follow their father’s guidance, diligently improving their father’s shortcomings. One of the bastards of Transformer, transformer XL[17] (XL means extra long), performs exceptionally well (mainly because his son XLNet[16] is outstanding), allowing transformer to return to its AR nature and enabling Transformer to handle longer sequences. As previously mentioned, AR models have their advantages. However, to achieve greater victories, they must find a better way to solve the bidirectional context problem than the Masked LM method.However, he never managed to complete this task in his lifetime, and his son XLNet made up for his regrets by solving the bidirectional context problem. The general solution is shown in
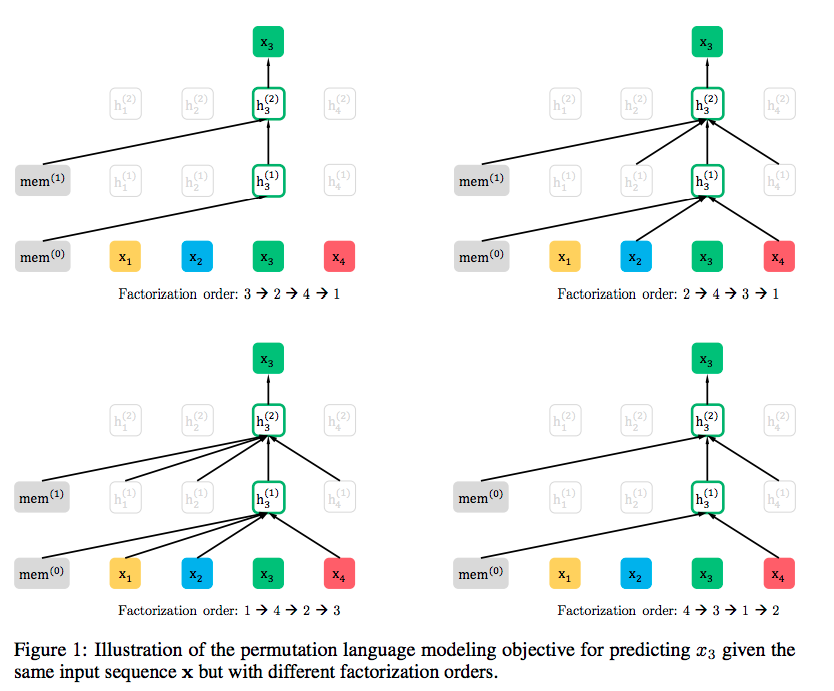
Figure 16: The bidirectional context solution proposed by XLNet (Image source: [16])Initially, the AR model was only able to work unidirectionally. So, they shuffled the input to find all permutations and performed factorization based on these permutations. Of course, this requires a huge amount of computation. XLNet also thought of a good way to solve it, but I won’t elaborate here; you can check the original paper to see how it was solved. However, XLNet did indeed cause quite a stir at that time, marking a significant victory for the bastards.[Modern] GPT-2 & 3 – Bigger is BetterFinally, back to the present, GPT-2 and GPT-3. By this point, there is not much technical detail to discuss about GPT-2 and GPT-3. They realized that their ancestors had ushered in an era where BERT broke records in various tasks within the natural language processing field. Shortly after the paper describing the model was released, the team also open-sourced the model’s code and provided pre-trained models that had been trained on a large number of datasets. This was an important development, as it allowed anyone building machine learning models involving language processing to leverage this powerful functionality as a readily available component, thereby saving time, effort, knowledge, and resources from training language processing models (as shown in Figure 17).
Figure 17: The New Era (Image source: http://jalammar.github.io/)Returning to GPT, before introducing what GPT-1’s descendants have done (mainly expanding the model), let’s first look at the titles of GPT-2 and GPT-3 papers:
Language models are unsupervised multitask learners. (GPT-2)
Language Models are Few-Shot Learners. (GPT-3)
Upon seeing these titles, the first impression is probably “a direct lineage.” In fact, the descendants of GPT have done just that, aiming to achieve zero-shot learning and eliminate the fine-tuning mechanism! This is why GPT-3 became popular and gave people the feeling of experience. By the time of GPT-2, they began to take a creative step—removing the fine-tuning layer and instead of defining what tasks the model should perform, the model would automatically identify what tasks it needed to perform. This is akin to a well-read person being able to answer any type of question effortlessly; GPT-2 is such a well-read model [18]. Other features mainly include expanding the company scale (increasing data size, adding parameters, increasing vocabulary, and extending context size from 512 to 1024 tokens). Additionally, it made adjustments to the transformer, placing layer normalization before each sub-block and adding another layer normalization after the last Self-attention.In summary, the differences between GPT-2 and GPT-1 are as indicated by GPT-2’s name; it aims to transform the language model into an unsupervised multitask learner. [19] A concise comparison is provided for reference:
Data Quality: GPT-2 is higher, having been filtered.
Data Breadth: GPT-2 is broader, containing web data and data from various fields.
Data Quantity: GPT-2 is larger, WebText, 8 million webpages.
Model Size: GPT-2 is larger, with 1.5 billion parameters.
Structural Changes: Minimal changes.
Two-Stage vs. One-Step: GPT-1 is a two-stage model, pre-training through language models, then fine-tuning for different task parameters. GPT-2 directly solves the problem in one step by introducing special characters.
By the time of GPT-3, if you look at the paper, you’ll find that GPT-3 resembles a thick technical report, explaining how GPT-3 achieves few-shot and even zero-shot learning. The core details here no longer need special mention; its size and financial strength are its most significant characteristics (the entire English Wikipedia, about 6 million entries, accounts for only 0.6% of its training data). If given the chance, I hope everyone can try this model themselves and experience the charm brought by GPT-3.ConclusionAfter reading this article, you may find that all technologies do not arise from nothing; they progress bit by bit. Sorting out the “group members” of a model from its origins not only allows for a deeper understanding of the field but also provides a more profound understanding of each technology within that model.At the same time, in practical applications, the latest model is not always the best. One must also consider whether the model size is suitable and whether the model performs excellently on specific tasks, etc. With a broader understanding of the entire NLP field, you will be better equipped to make choices rather than simply responding with, “Oh, I only know BERT” when asked why you chose BERT.References[1] Mikolov, Tomas; et al. (2013). “Efficient Estimation of Word Representations in Vector Space”. arXiv (https://en.wikipedia.org/wiki/ArXiv_(identifier)):1301.3781 (https://arxiv.org/abs/1301.3781) [cs.CL (https://arxiv.org/archive/cs.CL)]. [2]Mikolov, Tomas (2013). “Distributed representations of words and phrases and their compositionality”. Advances in neural information processing systems.[3] Matthew E. Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, & Luke Zettlemoyer. (2018). Deep contextualized word representations.[4] Ashish Vaswani and Noam Shazeer and Niki Parmar and Jakob Uszkoreit and Llion Jones and Aidan N. Gomez and Lukasz Kaiser and Illia Polosukhin (2017). Attention Is All You NeedCoRR, abs/1706.03762.[5] Zihang Dai and Zhilin Yang and Yiming Yang and Jaime G. Carbonell and Quoc V. Le and Ruslan Salakhutdinov (2019). Transformer-XL: Attentive Language Models Beyond a Fixed-Length ContextCoRR, abs/1901.02860.[6] P. J. Liu, M. Saleh, E. Pot, B. Goodrich, R. Sepassi, L. Kaiser, and N. Shazeer. Generating wikipedia by summarizing long sequences. ICLR, 2018.[7] Radford, A., Narasimhan, K., Salimans, T., & Sutskever, I. (2018). Improving language understanding by generative pre-training.[8] Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language models are unsupervised multitask learners. OpenAI Blog, 1(8), 9.[9] Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, & Dario Amodei. (2020). Language Models are Few-Shot Learners.[10]Jacob Devlin and Ming-Wei Chang and Kenton Lee and Kristina Toutanova (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language UnderstandingCoRR, abs/1810.04805.[11]Zhilin Yang and Zihang Dai and Yiming Yang and Jaime G. Carbonell and Ruslan Salakhutdinov and Quoc V. Le (2019). XLNet: Generalized Autoregressive Pretraining for Language UnderstandingCoRR, abs/1906.08237.[12] Attention mechanism and self-attention (transformer). Accessed at: https://blog.csdn.net/Enjoy_endless/article/details/88679989[13] Detailed explanation of Attention mechanism (I) – Attention in Seq2Seq. Accessed at: https://zhuanlan.zhihu.com/p/47063917[14] Understanding Attention (Essence, 3 Major Advantages, 5 Major Types). Accessed at: https://medium.com/@pkqiang49/%E4%B8%80%E6%96%87%E7%9C%8B%E6%87%82-attention-%E6%9C%AC%E8%B4%A8%E5%8E%9F%E7%90%86-3%E5%A4%A7%E4%BC%98%E7%82%B9-5%E5%A4%A7%E7%B1%BB%E5%9E%8B-e4fbe4b6d030[15]The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning). Accessed at: http://jalammar.github.io/illustrated-bert/[16] Yang, Zhilin, et al. “Xlnet: Generalized autoregressive pretraining for language understanding.” Advances in neural information processing systems. 2019.[17] Dai, Zihang, et al. “Transformer-xl: Attentive language models beyond a fixed-length context.” arXiv preprint arXiv:1901.02860 (2019).[18] NLP – GPT Comparison with GPT-2. Accessed at: https://zhuanlan.zhihu.com/p/96791725[19] Deep Learning: Cutting-edge Technology – GPT 1 & 2. Accessed at: http://www.bdpt.net/cn/2019/10/08/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%EF%BC%9A%E5%89%8D%E6%B2%BF%E6%8A%80%E6%9C%AF-gpt-1-2/Analyst Introduction:The author of this article is Wang Zijia, currently pursuing a master’s degree in artificial intelligence at Imperial College London. His main research direction is NLP recommendations, and he enjoys cutting-edge technologies and quirky ideas, aiming to be a researcher who does not follow the conventional path!
About the Synced Global Analyst Network
The Synced Global Analyst Network is a global knowledge-sharing network for artificial intelligence initiated by Machine Heart. Over the past four years, hundreds of AI professionals from around the world have shared their research ideas, engineering experiences, and industry insights through online sharing, column interpretation, knowledge base construction, report publishing, evaluations, and project consulting, while gaining personal growth, experience accumulation, and career development.
Interested in joining the Synced Global Analyst Network? ClickRead the Original to submit an application.