
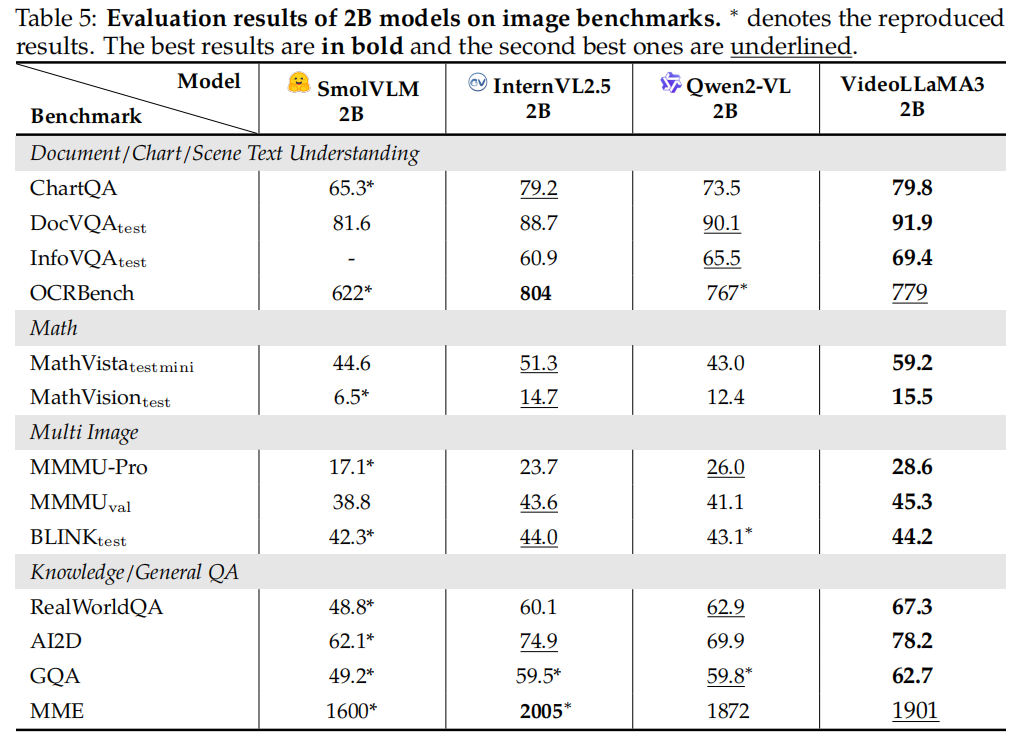
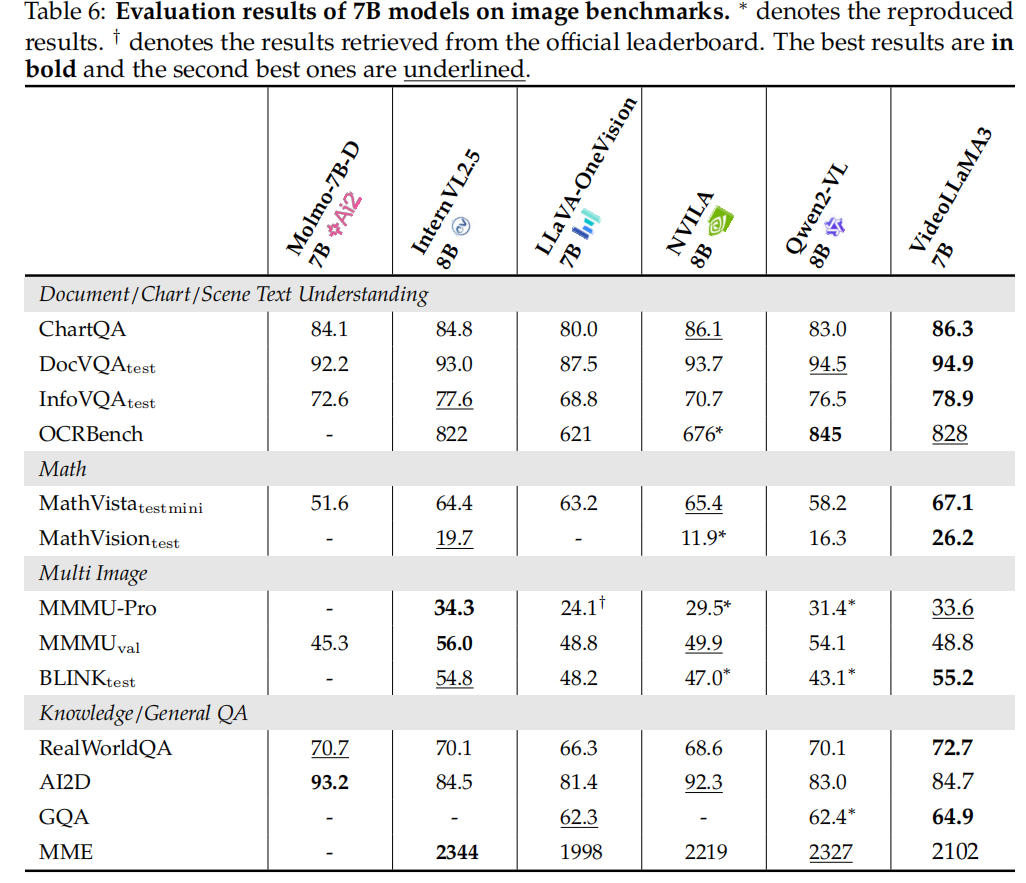
A more advanced multimodal foundation model for image and video understanding. The core design philosophy of VideoLLaMA3 is vision-centric:
-
Vision-centric training paradigm
-
Vision-centric framework design.
The key point of the vision-centric training paradigm is that high-quality image-text data is crucial for understanding both images and videos. Instead of preparing a large amount of video-text datasets, VideoLLaMA3 focuses on building large-scale and high-quality image-text datasets.
Divided into four training stages:
1) Vision-centric calibration stage, warming up the visual encoder and projector;
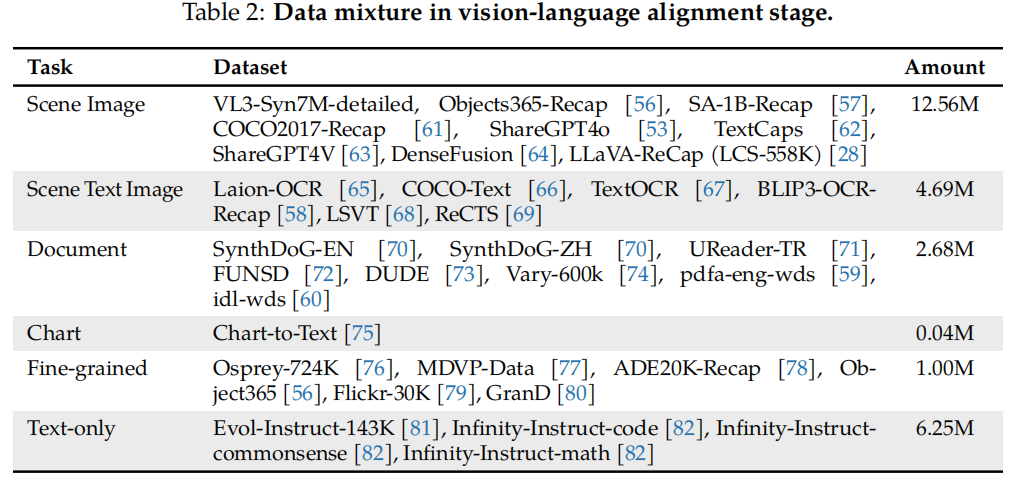
2) Vision-language pre-training stage, jointly tuning the visual encoder, projector, and LLM with a large-scale image-text dataset covering various types (including scene images, documents, charts) and pure text data.
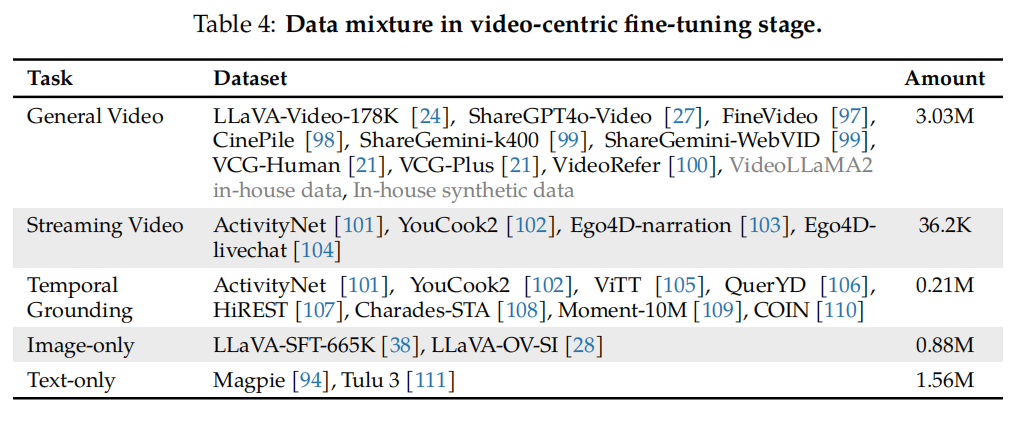
3) Multi-task fine-tuning stage, incorporating image-text SFT data into downstream tasks and video-text data to lay the foundation for video understanding.
4) Video-centric fine-tuning, further enhancing the model’s video understanding capabilities.
In framework design, to better capture fine-grained details in images, a pre-trained visual encoder encodes images of different sizes into a corresponding number of visual tokens, rather than a fixed number of tokens. For video input, the number of visual tokens is reduced based on similarity, making the representation of the video more precise and compact. (This is interesting; with fewer tokens, some information will be lost to a certain extent, but the effect is better??)
Contributions:
-
Proposed a vision-centric training paradigm. Improved video understanding capabilities through large-scale image understanding pre-training.
-
Proposed two vision-centric framework designs to better represent images and videos with the visual encoder.
-
Framework
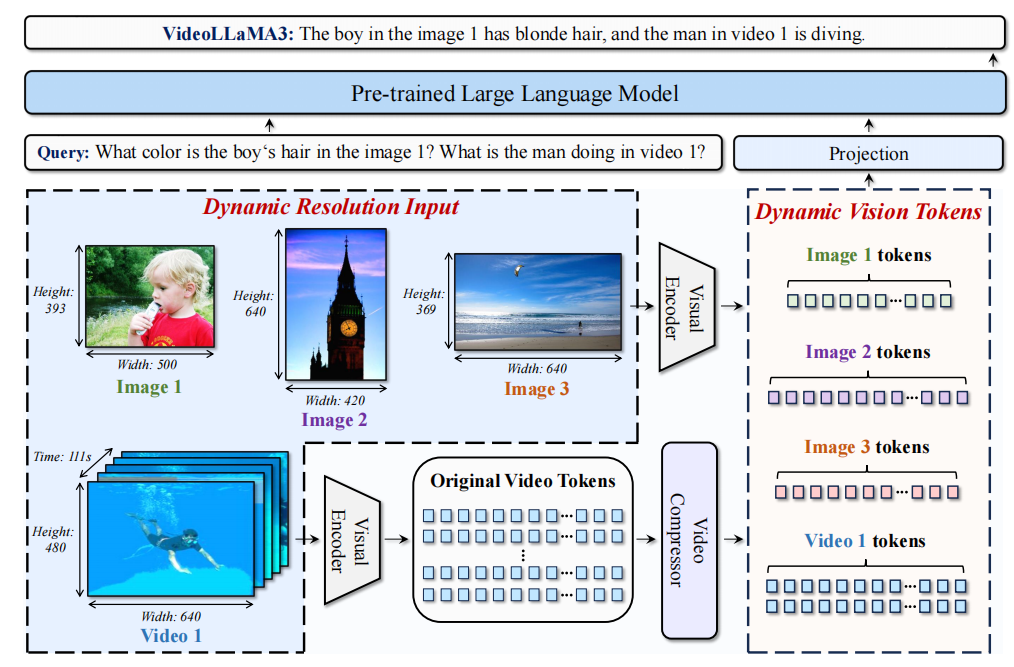
-
Training Stages
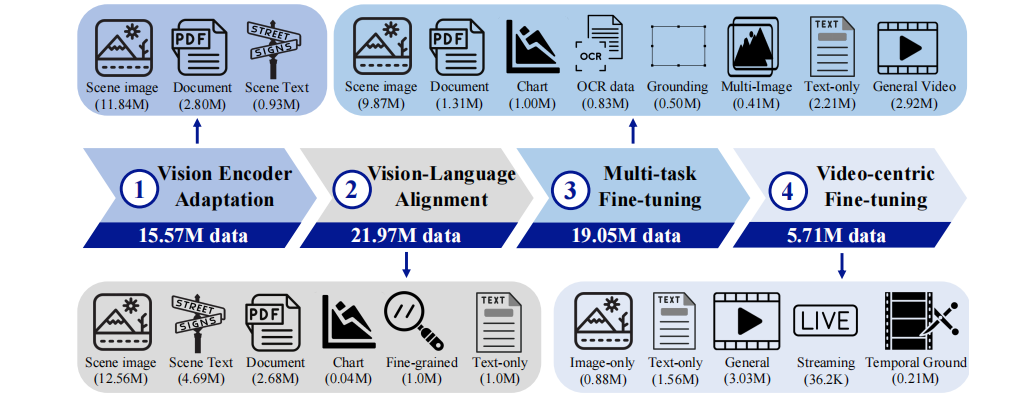
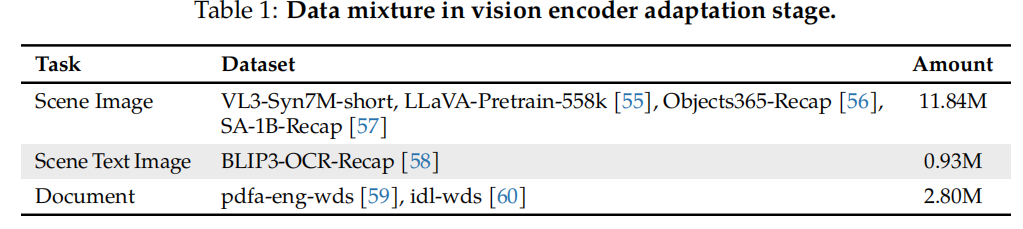



import torch
from transformers import AutoModelForCausalLM, AutoProcessor
device = "cuda:0"
model_path = "DAMO-NLP-SG/VideoLLaMA3-7B"
model = AutoModelForCausalLM.from_pretrained( model_path, trust_remote_code=True, device_map={"": device}, torch_dtype=torch.bfloat16, attn_implementation="flash_attention_2",)
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
conversation = [ {"role": "system", "content": "You are a helpful assistant."}, { "role": "user", "content": [ {"type": "video", "video": {"video_path": "./assets/cat_and_chicken.mp4", "fps": 1, "max_frames": 128}}, {"type": "text", "text": "What is the cat doing?"}, ] },]
inputs = processor( conversation=conversation, add_system_prompt=True, add_generation_prompt=True, return_tensors="pt")
inputs = {k: v.to(device) if isinstance(v, torch.Tensor) else v for k, v in inputs.items()}
if "pixel_values" in inputs: inputs["pixel_values"] = inputs["pixel_values"].to(torch.bfloat16)
output_ids = model.generate(**inputs, max_new_tokens=128)
response = processor.batch_decode(output_ids, skip_special_tokens=True)[0].strip()
print(response)