MLNLP community is a well-known machine learning and natural language processing community both domestically and internationally, covering NLP master’s and doctoral students, university teachers, and enterprise researchers.Community Vision is to promote communication and progress between the academic and industrial sectors of natural language processing and machine learning, especially for beginners.Reprinted from | RUC AI BoxAuthor | Liu ZikangInstitution | Renmin University of China, Gaoling School of Artificial IntelligenceResearch Direction | Multimodal LearningThis article summarizes some commonly used lightweight methods for Transformers and introduces several mainstream lightweight Transformers in various fields.The article is also published simultaneously in the AI Box Zhihu column (search for AI Box column on Zhihu), and everyone is welcome to comment and discuss below the article in the Zhihu column!
0
Introduction
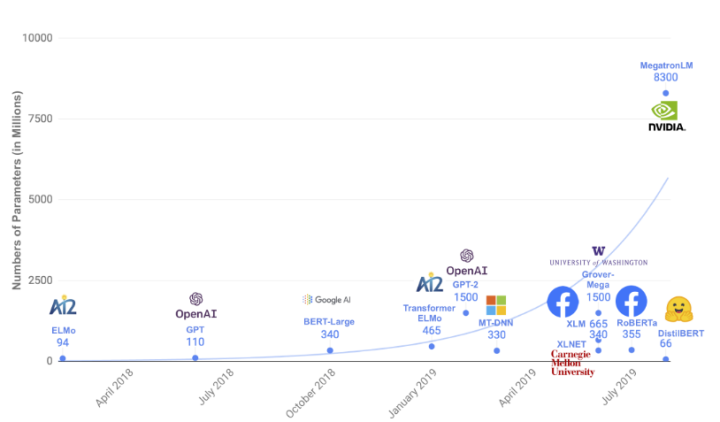
In recent years, Transformer models have been widely applied in various fields of artificial intelligence, becoming mainstream methods in computer vision, natural language processing, and multimodal fields. Although Transformers perform excellently on most tasks, their large number of parameters limits their application in real-world scenarios and poses challenges for related research, leading to the development of lightweight Transformers. The author first summarizes some commonly used lightweight methods for Transformers and introduces several mainstream lightweight Transformers across different fields. Criticism and suggestions are welcome for mutual communication.
Trend of Pre-trained Model Parameter Growth
1
Common Model Compression Methods in Transformers
Quantization: The basic idea of quantization is to use low-bit data types to replace the original high-bit data types while lightweighting the storage space and computational complexity of the data. Simple post-training quantization, which directly quantizes the parameters of the trained model, can lead to significant errors. Currently, quantization-aware training (QAT) is mainly used, which optimizes in full precision during training while simulating the low-precision inference process, effectively reducing the performance loss during quantization.
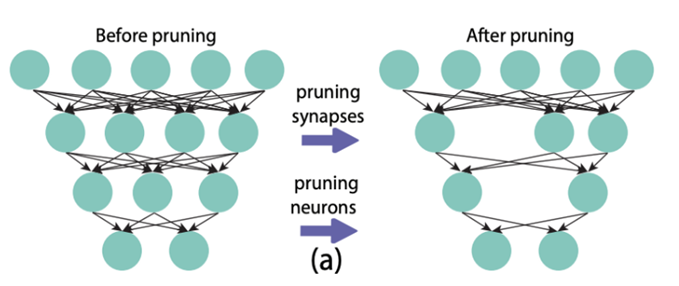
Pruning: The pruning method is based on the lottery ticket hypothesis, which states that only a small portion of parameters in the model play a core role, while most parameters are ineffective and can be removed. Pruning can be divided into unstructured pruning and structured pruning. Unstructured pruning identifies parameters in the parameter matrix that are close to zero or trending towards zero and sets these parameters to zero, making the parameter matrix sparse. Structured pruning reduces structured parts of the model, such as unnecessary attention heads in multi-head attention or unnecessary layers in multi-layer Transformers.
Unstructured Pruning
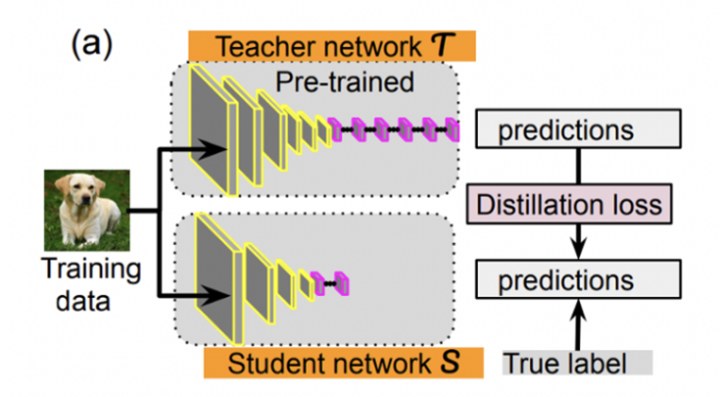
Knowledge Distillation: Knowledge distillation typically occurs between a large teacher model and a small student model. The student model is trained using the “soft label distribution” output by the teacher model on supervised data. This learning of “soft labels” can effectively overcome label bias in supervised data, bringing good knowledge transfer capability.
Parameter Sharing: Sharing parameters between identical parts of the model.
2
Lightweight Transformers in Pre-trained Language Models
Transformers were first widely applied in the field of natural language, and their powerful capabilities have led to rapid development in the pre-training field, bringing innovation to related areas. However, as the scale of pre-trained models continues to grow, the cost of training and deploying a pre-trained model also increases, giving rise to the research direction of lightweight pre-trained language models. Since the mainstream architecture of pre-trained language models, represented by BERT, is still Transformers, the lightweighting of Transformers has become an important topic in the current NLP field. Below are some classic lightweight works on pre-trained language models compiled by the author for reference.
Q8BERT: Quantized 8Bit BERT
https://arxiv.org/pdf/1910.06188.pdf
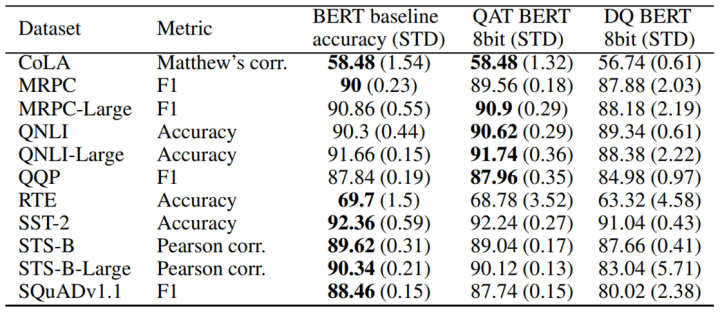
Q8BERT is a simple application of quantization methods on BERT. In addition to using the basic quantization-aware training method, Q8BERT also uses exponential moving average to smooth the QAT training process. Ultimately, after compressing nearly 4 times the number of parameters and achieving 4 times the inference speed, Q8BERT achieved results close to BERT on the GLUE and SQUAD datasets, proving the effectiveness of quantization methods on BERT.
Q8BERT’s Performance on Downstream Tasks
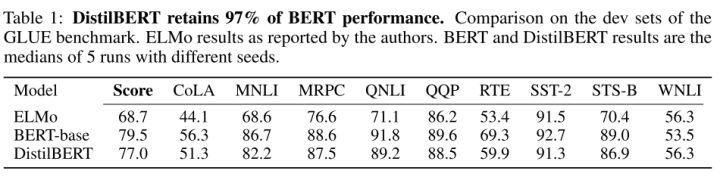
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
https://arxiv.org/pdf/1910.01108.pdf
DistilBERT is a smaller version of the BERT model released by Hugging Face, which only uses soft labels for distillation at the output layer, reducing the number of BERT layers to half while achieving good results on various downstream tasks.
On GLUE, DistilBERT used only 60% of the parameters while retaining 97% of the performance
TinyBERT: Distilling BERT for Natural Language Understanding
https://arxiv.org/pdf/1909.10351.pdf
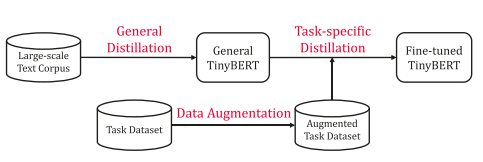
Similar to DistilBERT, TinyBERT is also an application of knowledge distillation on BERT compression. Unlike DistilBERT, which only uses knowledge distillation during the pre-training phase, TinyBERT employs a two-stage knowledge distillation approach during both the pre-training and fine-tuning phases, allowing the small model to learn general and task-related semantic knowledge.
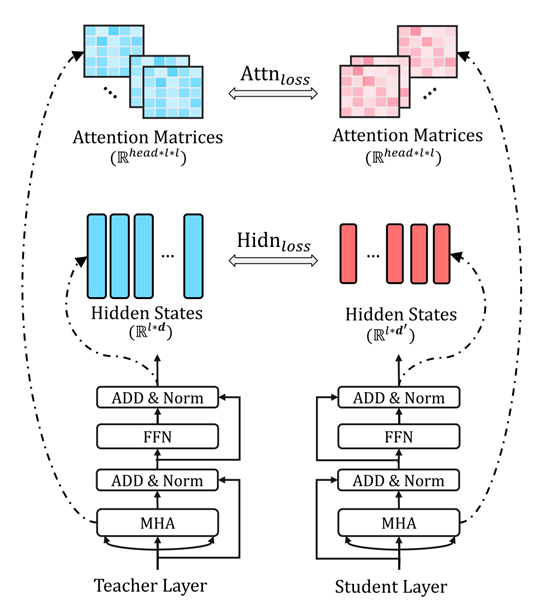
TinyBERT Distillation StrategyAt the same time, TinyBERT adopts a more fine-grained knowledge distillation method, distilling knowledge from the output of the embedding layer, the hidden layers in each Transformer layer, and the soft labels of the entire model, achieving a more precise knowledge transfer effect.
More Fine-grained Distillation MethodUltimately, TinyBERT distilled the BERT model into a 4-layer model with a smaller hidden layer dimension, achieving results comparable to those of DistilBERT with a higher parameter count.
ALBERT: A LITE BERT FOR SELF-SUPERVISED LEARNING OF LANGUAGE REPRESENTATIONS
https://arxiv.org/pdf/1909.11942.pdf
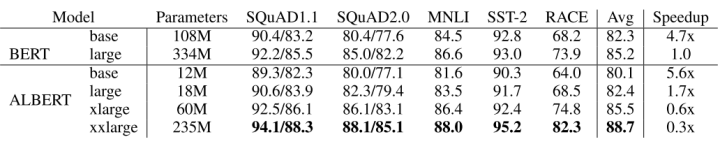
ALBERT is a work by Google presented at ICLR 2020. It first employs the method of vocabulary matrix factorization; since BERT uses a very large vocabulary, the embedding layer of the vocabulary contains a large number of parameters. ALBERT reduces this parameter count through factorized embedding parameterization. Specifically, for a vocabulary containing V words, if the hidden layer size E of the vocabulary matches the hidden layer size H of the model, the number of parameters in the embedding layer is V × E. Considering that V is generally large, the total parameter count of the embedding also becomes large. To reduce the parameter count, unlike directly mapping one-hot word vectors to H-dimensional space, ALBERT first maps word vectors to a smaller E-dimensional space and then to H-dimensional space, reducing the parameter count from O(V × H) to O(V × E + E × H), thus achieving compression of the embedding layer.In addition, ALBERT also performs cross-layer parameter compression within the Transformer, achieving sufficient parameter compression through complete parameter sharing across Transformer layers. Under low parameter conditions, ALBERT achieves results similar to BERT-base while ensuring a deeper model with a larger hidden layer dimension, leading to better performance on downstream tasks.
ALBERT’s Parameter Count and Downstream Task Performance
3
Lightweight Transformers in Computer Vision
Although the application of Transformers in the field of computer vision has been slightly slower than in NLP, the emergence of Vision Transformers has made Transformers a mainstream model in visual tasks. Later pre-training methods based on MAE and BEiT further solidified the position of Transformers in the computer vision field. Similar to the natural language understanding field, Transformers in computer vision also face the problem of excessive parameters and deployment difficulties, thus requiring lightweight Transformers to efficiently perform downstream tasks. Below are several lightweight works in the field of computer vision compiled by the author for reference.
Training data-efficient image transformers & distillation through attention
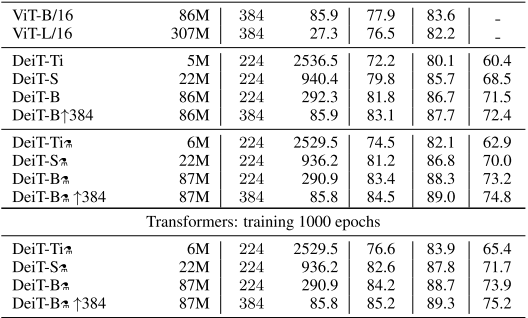
DeiT is a work by Facebook in 2021, with the core method being knowledge distillation applied to compress visual Transformers. DeiT employs two distillation methods to achieve knowledge transfer from the teacher model to the student model:
Soft Distillation: Knowledge distillation through the soft labels output by the teacher model.
Hard-label Distillation: Knowledge distillation through the actual labels predicted by the teacher model, aimed at correcting potential label biases in the supervised data.
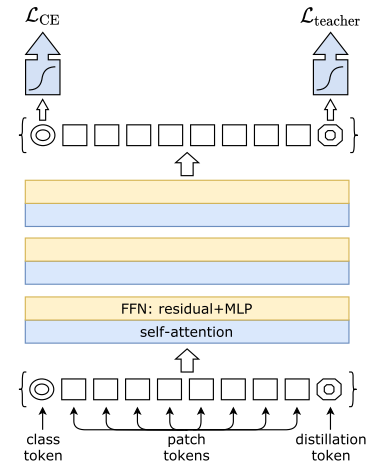
DeiT introduces the concept of a Distillation token during the distillation process, serving a purpose similar to the Class token, but while the Class token is used for training on the original data using cross-entropy, the Distillation token is used to simulate the soft distribution output of the teacher model or to train using the hard labels predicted by the teacher model.
Distillation TokenThrough the distillation process on the teacher model, DeiT achieves better results than ViT with a smaller parameter scale and faster inference speed.
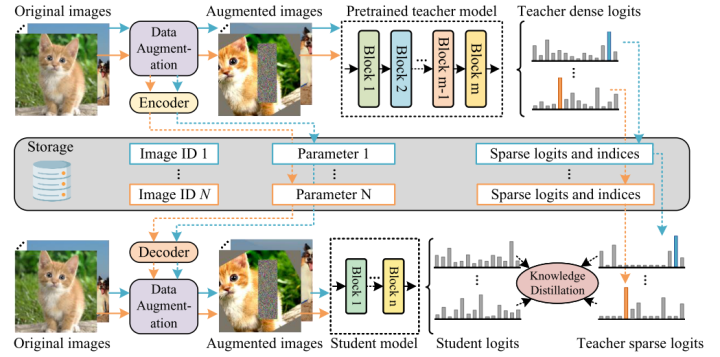
TinyViT: Fast Pretraining Distillation for Small Vision Transformers
TinyViT is a work by Microsoft in 2022, with the core still being knowledge distillation, but with some optimizations in engineering implementation, allowing small models to acquire knowledge from large models under larger data scales through knowledge distillation. The knowledge distillation method employed by DeiT is quite expensive, as both the teacher and student models occupy GPU memory simultaneously during the distillation process, limiting the increase in batch size and the training speed of the student model. Additionally, the transfer of soft labels from the teacher model output to the student model output also incurs significant computational resource costs.To address this issue, TinyViT proposes a method for pre-generating soft labels, decoupling the generation of soft labels from the training process of the student model. First, soft labels are generated and pre-stored, and then the pre-stored soft labels are used to train the student model. Given that the pre-stored soft label vectors incur significant storage overhead, considering that most of these vectors are sparse (because for a trained teacher model, given an image, only a small number of categories will have a probability of being the correct label), the authors adopt a strategy of storing sparse labels, only keeping the top-k probable labels and their corresponding probabilities. When training the student model, these sparse labels are restored to a complete probability distribution for knowledge distillation. The entire pipeline is illustrated below:
TinyViT’s Distillation ProcessUnder the same model scale, TinyViT improves the speed and data volume of knowledge distillation, achieving enhancements in classification tasks.
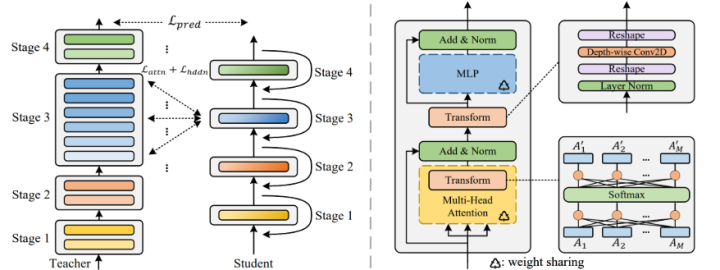
MiniViT: Compressing Vision Transformers with Weight Multiplexing
MiniViT is a work by Microsoft presented at CVPR 2022, adopting a weight multiplexing method to compress model parameters. Unlike ALBERT, the authors found that simply reusing weights can lead to the homogenization of the l2 norm of gradients across layers and reduce the correlation of output features in the last few layers. To solve this problem, MiniViT employs Weight Transformation and Weight Distillation methods. Weight Transformation involves inserting small, adapter-like structures between each layer to ensure that the output of each layer does not homogenize due to identical parameter counts. Weight Distillation uses a teacher model to guide the output of MiniViT to enhance model performance. The overall pipeline is illustrated below:
As a general compression method, the authors tested it on DeiT and Swin-Transformer. With fewer parameters, the Mini version of the model achieved comparable or even better results on the ImageNet dataset.
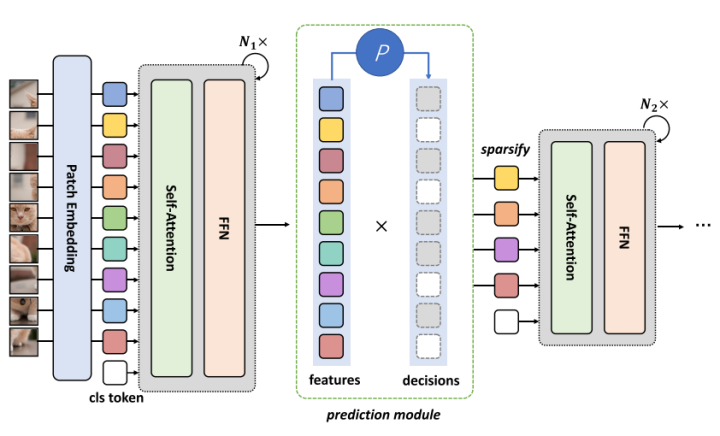
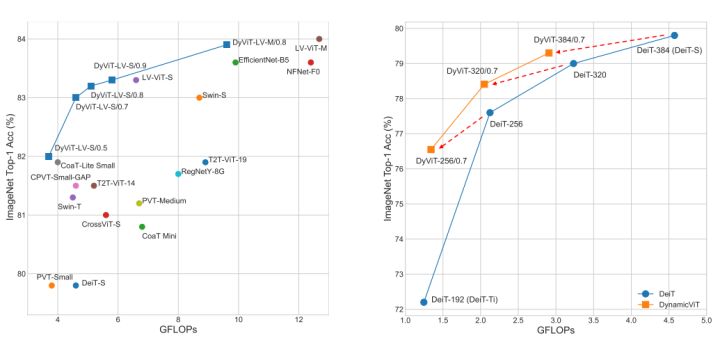
DynamicViT: Efficient Vision Transformers with Dynamic Token Sparsification
This paper is a work by Tsinghua University presented at NeurIPS 2021, which draws on the idea of pruning in model compression but sparsifies the input tokens of the Transformer at each layer. The basic assumption of token sparsification is that for a given image, there are certain redundant parts that have little impact on the model’s prediction results, and reducing these parts can significantly increase the model’s inference speed.The specific approach of DynamicViT is to add a lightweight prediction module between each layer to predict which tokens can be discarded. After prediction, a binary decision mask is used to complete the token discard process. At the same time, the authors modified the training objective function to ensure that the number of discarded tokens at each layer is limited.
DynamicViT’s Sparsification ModuleUltimately, under the aforementioned sparsification strategy, DynamicViT achieves significant acceleration based on the original ViT, balancing model performance and inference speed effectively.
4
Lightweight Transformers in Multimodal Learning
Multimodal models often reference the designs of both visual and language models, thus using Transformers as their mainstream architecture. However, lightweight work in multimodal settings is relatively scarce, and the author has compiled several representative lightweight works in multimodal learning for reference.
MiniVLM: A Smaller and Faster Vision-Language Model
https://arxiv.org/pdf/2012.06946.pdf
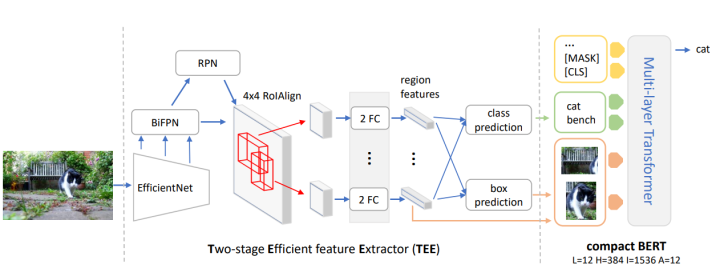
MiniVLM is a lightweighting effort by Microsoft on the Oscar model. The lightweighting of MiniVLM is based on an observational hypothesis: that in most multimodal tasks, the visual part of the multimodal model does not require particularly strong object detection information, and the object detector often becomes a bottleneck for the model. Therefore, using a less precise object detector can effectively compress the model’s parameter count and speed up inference while minimizing performance loss.To achieve this effect, MiniVLM employs a lightweight object detector based on EfficientNet and Bi-FPN. Additionally, to further compress the model, MiniVLM also compresses the multimodal Transformer part, replacing the original BERT structure with a more lightweight MiniLM, as shown below:
Lightweight Object DetectorUltimately, within an acceptable range of accuracy loss, compared to the original OSCAR model, MiniVLM greatly improves inference speed:
MiniVLM’s Acceleration Effect and Downstream Task Performance
Compressing Visual-linguistic Model via Knowledge Distillation
https://arxiv.org/pdf/2104.02096
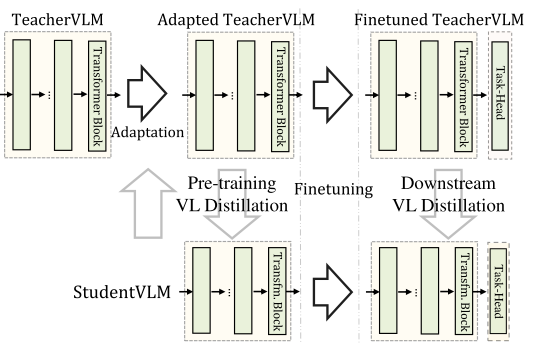
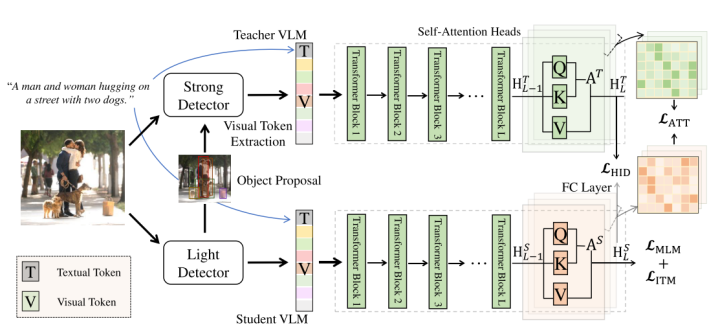
DistilVLM is a continuation of MiniVLM’s work. Unlike before, while replacing the object detector and Transformer architecture, DistilVLM also employs knowledge distillation to maintain the model’s performance. The distillation strategy of DistilVLM is similar to that of TinyBERT, which also involves two-stage distillation during the pre-training and fine-tuning phases:
DistilVLM’s Distillation StrategyDue to the use of different object detectors, the detected target areas differ, making subsequent knowledge distillation ineffective. To resolve this issue, DistilVLM employs visual token alignment, ensuring that both the teacher and student models use the same object detector, aligning the detection areas of the two models and ensuring the effectiveness of subsequent knowledge distillation.
Visual AlignmentUltimately, under the same parameters and inference speed as MiniVLM, DistilVLM achieves notable performance improvements.
References
[1] Q8BERT: Quantized 8Bit BERT
[2] DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
[3] TinyBERT: Distilling BERT for Natural Language Understanding
[4] ALBERT: A LITE BERT FOR SELF-SUPERVISED LEARNING OF LANGUAGE REPRESENTATIONS
[5] Training data-efficient image transformers & distillation through attention
[6] TinyViT: Fast Pretraining Distillation for Small Vision Transformers
[7] MiniViT: Compressing Vision Transformers with Weight Multiplexing
[8] DynamicViT: Efficient Vision Transformers with Dynamic Token Sparsification
[9] MiniVLM: A Smaller and Faster Vision-Language Model
[10] Compressing Visual-linguistic Model via Knowledge DistillationTechnical Community Invitation
△ Long press to add the assistant
Scan the QR code to add the assistant on WeChat
Please note: Name-School/Company-Research Direction(e.g., Xiao Zhang-Harbin Institute of Technology-Dialogue System)to apply for joining the Natural Language Processing/Pytorch and other technical community groups
About Us
MLNLP Community is a grassroots academic community jointly built by scholars in machine learning and natural language processing from both domestic and international backgrounds, and has developed into a well-known community for machine learning and natural language processing, aiming to promote progress among practitioners in academia, industry, and enthusiasts.The community can provide an open communication platform for related practitioners’ further studies, employment, and research. Everyone is welcome to follow and join us.