

Reprinted from | Xiaoyao’s Cute Selling House
Written by | Huang Yu
Source | Zhihu
In the field of NLP, transformer has successfully replaced RNNs (LSTM/GRU), and has also found applications in CV, such as object detection and image annotation, as well as in RL. This is a review paper published by Google in September 2020 on arXiv titled “Efficient Transformers: A Survey” that is worth reading.

The article mainly focuses on a class of X-former models, such as Reformer, Linformer, Performer, and Longformer, which improve the original Transformer to enhance its computational and memory efficiency.
Paper Title:
Efficient Transformers: A Survey
Paper Link:
https://arxiv.org/pdf/2009.06732
 Transformer Review
Transformer Review
self-attention is a key defining feature of the Transformer model. This mechanism can be viewed as an inductive bias similar to graphs, allowing all tokens in a sequence to be related through relevant pooling operations. A well-known issue with self-attention is its quadratic time and memory complexity, which hinders the scalability of models in many settings. Therefore, many variants have recently been proposed to address this issue, and we refer to these models as efficient Transformers.
Efficient self-attention models are crucial for long sequence modeling applications, as documents, images, and videos typically consist of a relatively large number of pixels or tokens. Thus, the efficiency of processing long sequences is vital for the widespread adoption of Transformers.
The figure shows a standard Transformer architecture:
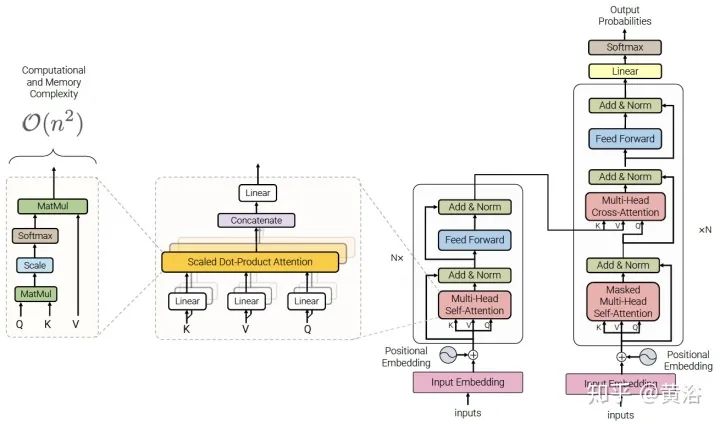
The Transformer is formed by stacking Transformer blocks on top of each other in a multi-layer architecture. The features of Transformer blocks include the multi-head self-attention mechanism, position-wise feed-forward networks, layer normalization (LN) modules, and residual connectors.
The input to the Transformer model is typically a tensor with shape BxN, where B is the batch size and N is the sequence length. This input first passes through an embedding layer that converts each one-hot token representation into a d-dimensional embedding vector, i.e., BxNxd. Then, the new tensor is added to positional encoding and processed through a multi-head self-attention module.
Positional encoding can be in the form of sine inputs or trainable embeddings. The input and output of the multi-head self-attention module are connected through residual connectors and layer normalization (LN) layers. The output of the multi-head self-attention module is then passed to two layers of feed-forward networks (FFN), similarly connected in a residual manner to the layer normalization (LN) module.
The residual connector with a layer normalization module is defined as follows:

The single head operation of Multi-Head Self-Attention is defined as:
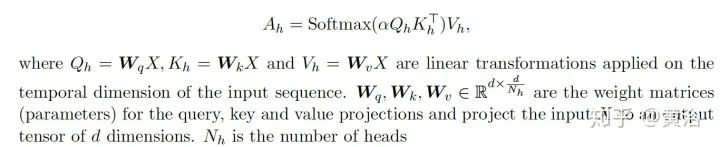


The attention matrix A = QK^T is primarily responsible for calibrating the scores between tokens in the sequence. This drives the self-attention’s self-calibration process, allowing tokens to learn clustering among each other. However, the computation of this matrix is an efficiency bottleneck.
The layer operation of FFN is defined as:

Thus, the entire operation of the Transformer block is defined as:

Next, it is important to note the different usage modes of the Transformer module. The main usage modes of Transformers include: (1) Encoder (e.g., for classification), (2) Decoder (e.g., for language modeling), and (3) Encoder-Decoder (e.g., for machine translation).
In the encoder-decoder mode, there are typically multiple multi-head self-attention modules, including standard self-attention in the encoder and decoder, as well as encoder-decoder cross-attention that allows the decoder to utilize information from the encoder. This affects the design of the self-attention mechanism.
In the encoder mode, there are no constraints on the self-attention mechanism, which must be causal, meaning it only depends on the current and past tokens.
In the encoder-decoder setup, the encoder and encoder-decoder cross-attention can be non-causal, but the decoder’s self-attention must be causal. Designing an effective self-attention mechanism requires supporting causal relationships for AR (auto-regressive) decoding, which may be a universal limiting factor.
 Efficient Transformers
Efficient Transformers
The classification of Efficient Transformers is shown in the figure, with the corresponding methods published over the past two years (2018-2020) regarding time, complexity, and category shown in the table:
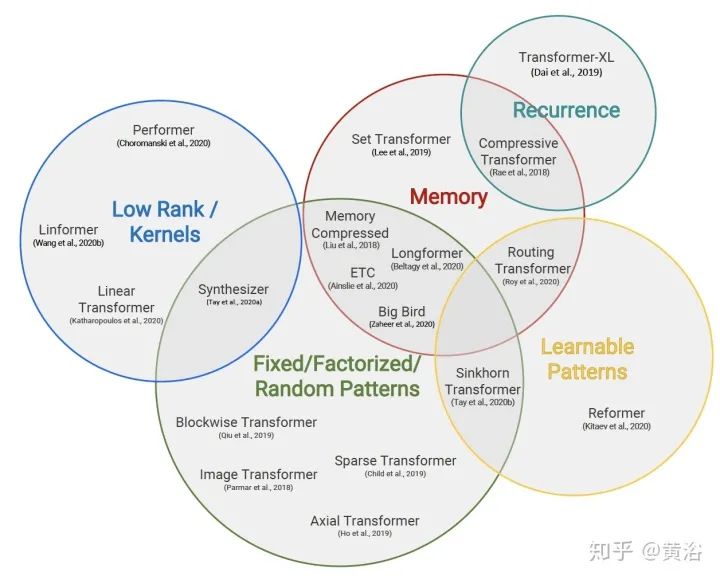
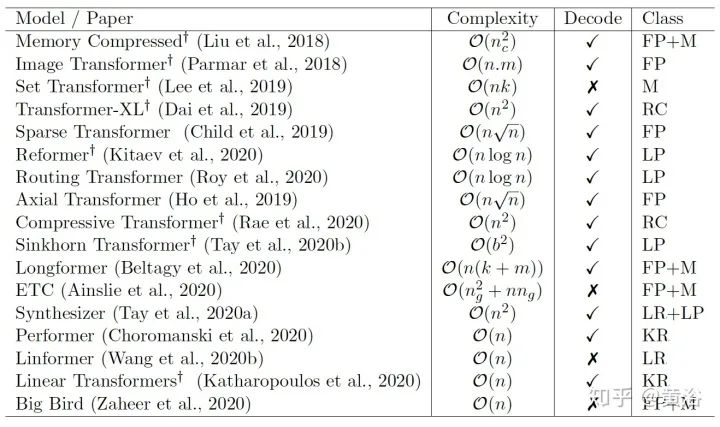
Note: FP = Fixed Patterns/Combinations of Fixed Patterns, M = Memory, LP = Learnable Pattern, LR = Low Rank, KR = Kernel, RC = Recurrence.
Except for segment-based recurrence, most models aim to approximate the quadratic level overhead of the attention matrix. Each method applies the concept of sparsity to the original dense attention mechanism.
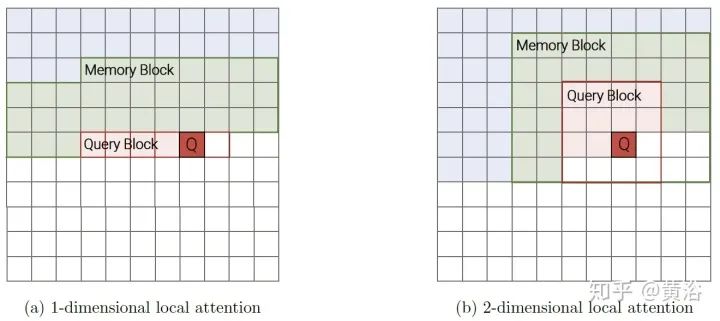
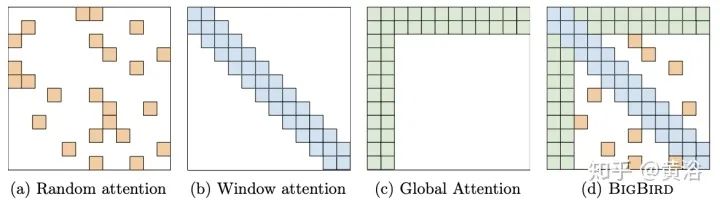
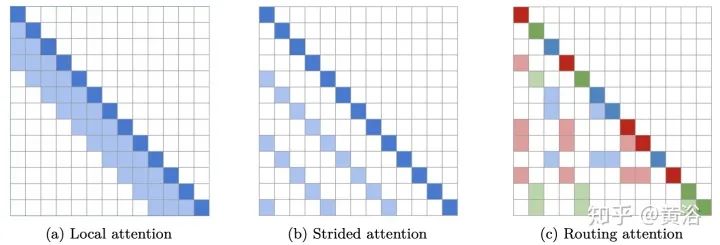
Fixed patterns (FP): The earliest improvement to self-attention limited the receptive field to fixed, predefined patterns (e.g., local windows and fixed stride block patterns) to simplify the attention matrix.
-
Blockwise Patterns: The simplest practical example of this technique is the blockwise (or chunking) paradigm, which divides the input sequence into fixed blocks, considering local receptive fields. Examples include chunk-wise and/or local attention. Dividing the input sequence into blocks can reduce complexity from N^2 to B^2 (block size), where B << N, significantly reducing overhead. These blockwise or chunking methods can serve as the foundation for many more complex models. -
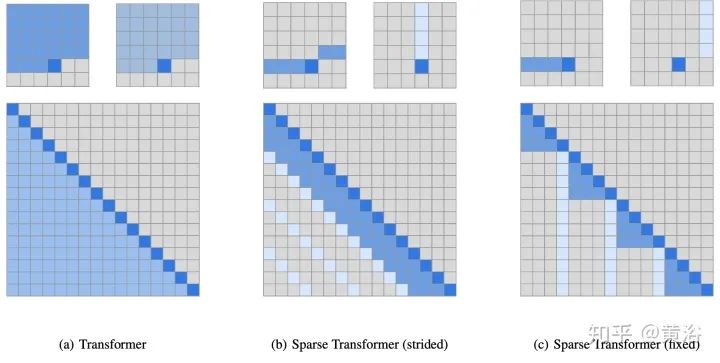
Strided patterns: Another method involves participating only at fixed intervals. Models like Sparse Transformer and/or Longformer adopt a “strided” or “dilated” window. -
Compressed Patterns: Another offensive line that down-samples sequence length using some merging operations, making it a form of fixed patterns. For example, Compressed Attention effectively reduces sequence length using strided convolutions.
Combination of Patterns (CP): The key point is to improve coverage by combining two or more different access patterns. For example, Sparse Transformer allocates half of its heads to patterns that combine strided and local attention. Similarly, Axial Transformer applies a series of self-attention calculations along a single axis of the input tensor when given a high-dimensional tensor as input. Essentially, pattern combinations reduce memory complexity in the same way as fixed patterns. However, the difference is that multi-pattern aggregation and combination improve the overall coverage of the self-attention mechanism.
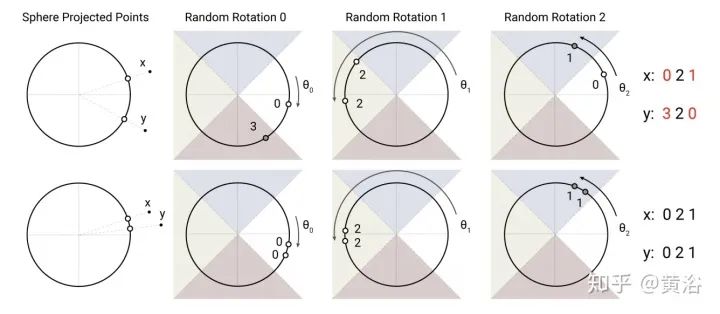
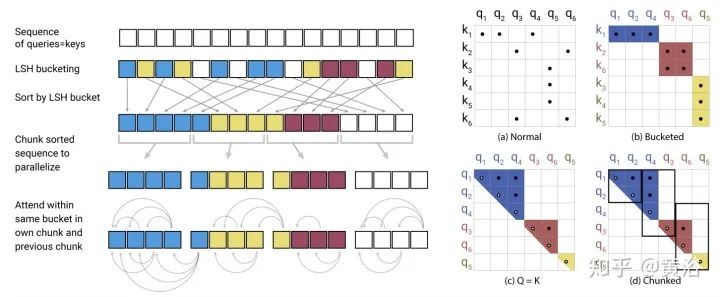
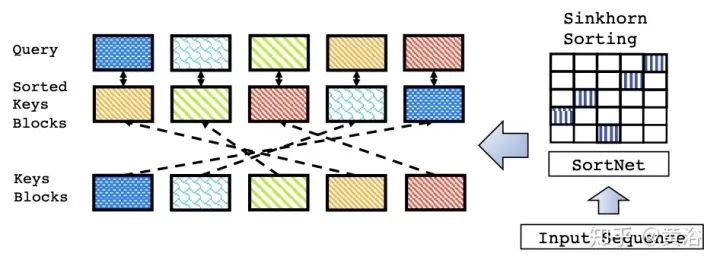
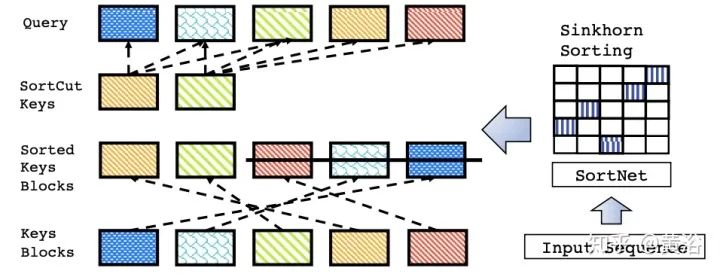
Learnable Patterns (LP): An extension of predetermined FP patterns that can be learned. Unsurprisingly, models using learnable patterns aim to learn access patterns in a data-driven manner. The key to LP is determining token relevance, assigning tokens to buckets or clusters. Notably, Reformer introduces a hash-based similarity measure that effectively clusters tokens into chunks. Similarly, Routing Transformer employs online k-means clustering on tokens. Meanwhile, Sinkhorn sorting networks expose the sparsity of attention weights by learning to sort blocks of the input sequence. In all these models, the similarity function is trained end-to-end with other parts of the network. The key point of LP remains to leverage fixed patterns (chunked patterns). However, such methods learn to sort/clustering input tokens, maintaining the efficiency advantages of FP methods while achieving a better global view of the sequence.
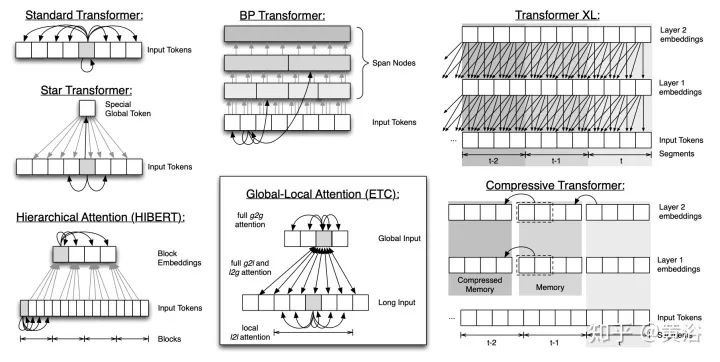
Memory: Another standout method that utilizes a side memory module, allowing access to multiple tokens at once. The general form is a global memory that can access the entire sequence. Global tokens serve as a form of memory, learning to aggregate from the tokens of the input sequence. This was first introduced in the Set Transformers with the inducing points method. These parameters are often interpreted as “memory” and serve as temporary contextual information for future processing. This can be viewed as a form of parameter attention. Global memory is also used in ETC and Longformer. With a limited amount of memory (or inducing points), a pooling operation similar to the input sequence is employed to compress the data, which is a technique that can be used when designing effective self-attention modules.
Low-Rank methods: Another emerging technique that leverages low-rank approximations of the self-attention matrix to improve efficiency. The key point is to assume the low-rank structure of the NxN matrix. Linformer is a classic example of this technique, projecting the length dimensions of keys and values into lower-dimensional representations (N -> k). It is evident that since the NxN matrix is now decomposed into Nxk, this method improves the storage complexity of self-attention.
Kernels: Another recently popular method to improve the efficiency of Transformers by viewing the attention mechanism through kernelization. The use of kernels allows the self-attention mechanism to undergo clever mathematical rewriting, avoiding the explicit computation of the NxN matrix. Since kernels are an approximate form of the attention matrix, they can also be viewed as a form of low-rank methods.
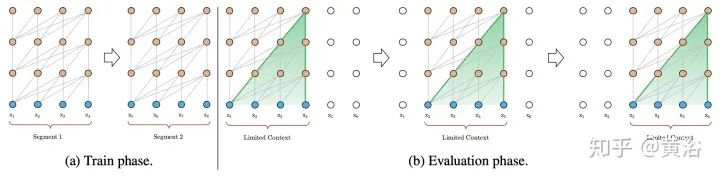
Recurrence: A direct extension of blockwise methods is to recursively connect these blocks. Transformer-XL proposed a segment-level recursive mechanism that connects multiple segments and blocks. In some sense, these models can be seen as FP models.
 Memory and Computational Complexity Analysis
Memory and Computational Complexity Analysis
This review analyzes the memory and computational complexity of the following 17 methods:
1. Memory Compressed Transformer: “Generating Wikipedia by summarizing long sequences” as shown in the figure
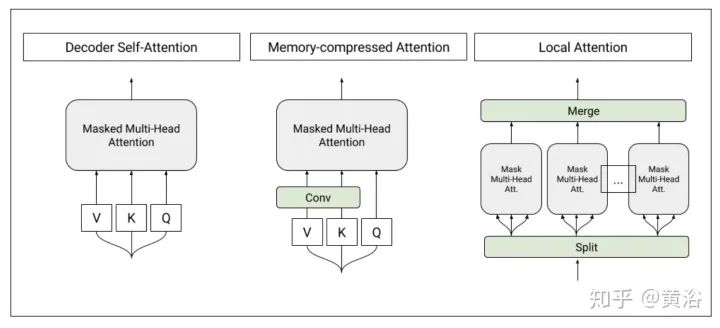
2. Image Transformer: “Image Transformer” as shown in the figure
3. Set Transformer: “Set transformer: A framework for attention-based permutation-invariant neural networks” as shown in the figure

4. Sparse Transformer: “Generating long sequences with sparse transformers” as shown in the figure
5. Axial Transformer: “Axial attention in multidimensional transformers.” as shown in the figure
6. Longformer: “Longformer: The long-document transformer” as shown in the figure
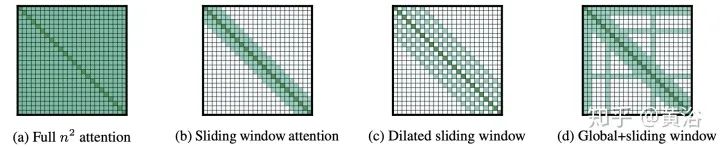
7. Extended Transformer Construction (ETC): “ETC: Encoding long and structured data in transformers” as shown in the figure
8. BigBird: “Big Bird: Transformers for Longer Sequences” as shown in the figure
9. Routing Transformer: “Efficient content-based sparse attention with routing transformers” as shown in the figure
10. Reformer: “Reformer: The efficient transformer” as shown in the figure
11. Sparse Sinkhorn Transformer: “Sparse sinkhorn attention” as shown in the figure
12. Linformer: “Hat: Hardware-aware transformers for efficient natural language processing” as shown in the figure
13. Linear Transformer: “Transformers are RNNs: Fast autoregressive transformers with linear attention” as shown in the figure is its algorithm pseudo-code

14. Performer: “Masked language modeling for proteins via linearly scalable long-context transformers” as shown in the figure is the algorithm pseudo-code for Fast Attention via Orthogonal Random Features (FAVOR)

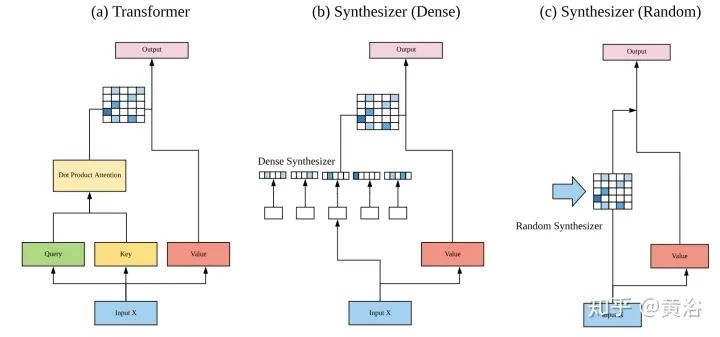
15. Synthesizer: “Synthesizer: Rethinking self-attention in transformer models.” as shown in the figure
16. Transformer-XL: “Transformer-xl: Attentive language models beyond a fixed-length context” as shown in the figure
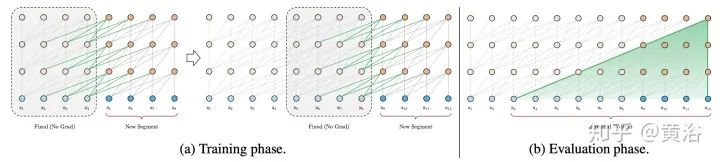
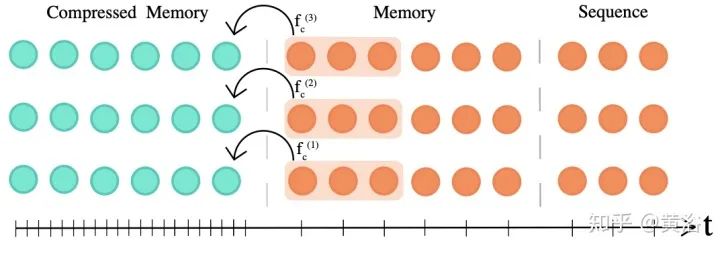
17. Compressive Transformers: “Compressive transformers for long-range sequence modelling” as shown in the figure
 Evaluation Benchmarks
Evaluation Benchmarks
Despite the field’s busy efforts to use new Transformer models, there is almost no simple way to compare these models. Many research papers choose their own benchmarks to showcase the capabilities of the proposed models. Coupled with different hyperparameter settings (e.g., model size and configuration), it can be difficult to accurately identify the reasons for performance improvements. Moreover, some papers compare them with pre-training, making it even harder to distinguish the relative performance of these different models. Which basic efficient Transformer block to consider remains a mystery.
On one hand, there are various models focused on generative modeling, demonstrating the proposed Transformer units’ capabilities in sequence AR (auto-regressive) modeling. For this purpose, Sparse Transformers, Adaptive Transformers, Routing Transformers, and Reformers mainly focus on generative modeling tasks. These benchmarks typically involve language modeling and/or pixel-wise image generation on datasets such as Wikitext, enwik8, and/or ImageNet/CIFAR. Meanwhile, segment-based recurrence models (e.g., Transformer-XL and Compressive Transformers) also focus on large-range language modeling tasks, such as PG-19.
On the other hand, some models primarily focus on **encoding (encoding only)** tasks, such as question answering, reading comprehension, and/or selections from the GLUE benchmark. For example, the ETC model only experiments on question answering benchmarks like NaturalQuestions or TriviaQA. Conversely, Linformer focuses on a subset of the GLUE benchmark. This decomposition is very natural and intuitive, as models like ETC and Linformer cannot be used in an AR (auto-regressive) way, i.e., they cannot be used for decoding. This exacerbates the difficulty of comparing these encoder models with others.
Some models aim to balance both aspects. Longformer attempts to balance this by running benchmarks on both generative modeling and encoder tasks. Sinkhorn Transformer compares generative modeling tasks and encoding-only tasks.
Additionally, it is worth noting that while the **machine translation (MT)** task of Seq2Seq is one of the popular problems for Transformer models, these efficient Transformer models have not been extensively evaluated for MT. This may be because the sequence length in MT is insufficient to justify the use of these models.
Although generative modeling, **GLUE (General Language Understanding Evaluation)**, and/or question answering seem to be common evaluation benchmarks for these applications, there are still some benchmarks available for a small number of papers to evaluate separately. First, the Performer model evaluates masked language modeling and has been positively compared with other efficient Transformer models. Furthermore, the Linear Transformer also evaluates speech recognition, which is relatively rare.
 Efficiency Comparison
Efficiency Comparison
Additionally, the paper concludes by analyzing and comparing these methods for improving efficiency, focusing on several aspects:
-
Weight Sharing -
Quantization / Mixed Precision -
Knowledge Distillation (KD) -
Neural Architecture Search (NAS) -
Task Adapters This will not be elaborated here; interested friends can refer to the original paper.
Download 1: Four-piece Set Reply "Four-piece set" in the background of the Machine Learning Algorithms and Natural Language Processing public account to obtain the learning set for TensorFlow, Pytorch, Machine Learning, and Deep Learning! Download 2: Repository Address Sharing Reply "Code" in the background of the Machine Learning Algorithms and Natural Language Processing public account to obtain 195 NAACL + 295 ACL2019 papers with open-source code. The open-source address is as follows: https://github.com/yizhen20133868/NLP-Conferences-Code Heavy! The Machine Learning Algorithms and Natural Language Processing exchange group has been officially established! There are many resources in the group, and everyone is welcome to join the group for learning! Additional welfare resources! Deep Learning and Neural Networks, Official Chinese Tutorials for Pytorch, Data Analysis with Python, Machine Learning Study Notes, Official Chinese Documentation for Pandas, Effective Java (Chinese version), and other 20 welfare resources. How to obtain: After entering the group, click on the group announcement to get the download link. Note: Please modify the remarks to [School/Company + Name + Direction] when adding. For example - Harbin Institute of Technology + Zhang San + Dialogue System. The account owner and WeChat merchants please consciously avoid the way. Thank you! Recommended Reading: 12 Golden Rules for Solving the NER Problem in the Industry Three Steps to Master the Core of Machine Learning: Matrix Derivation Distillation Techniques in Neural Networks, Starting from Softmax