
This public account mainly focuses on cutting-edge AI technologies such as NLP, CV, LLM, RAG, and Agents, sharing practical industry cases and courses for free, helping you fully embrace AIGC.
1. Janus-Pro Can Perform 5 Tasks
1.1 Image Description

1.2 Location Recognition

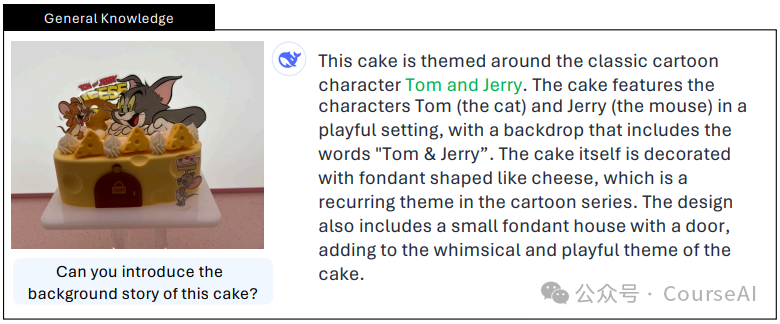
1.3 Background Inference
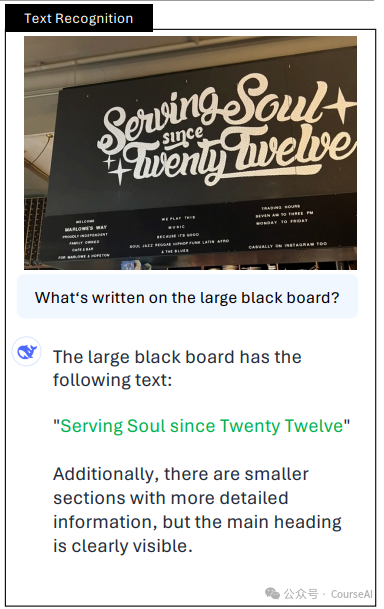
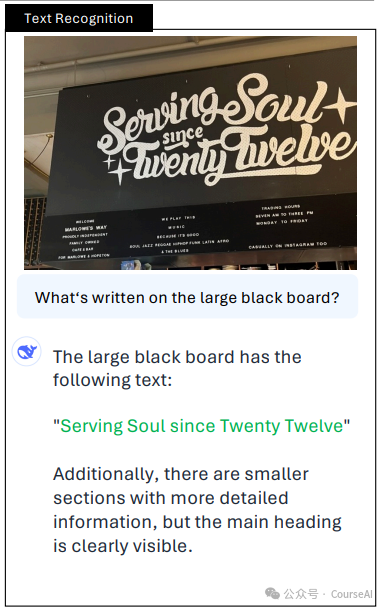
1.4 OCR Text Recognition
1.5 Text-Image Generation
2. Principles of Janus-Pro
-
Janus-Pro’s core design principle adopts an autoregressive framework, decoupling visual encoding to resolve conflicts between multimodal understanding and generation tasks. -
It converts raw inputs into features using independent encoding methods, which are then processed by a unified autoregressive transformer. -
For multimodal understanding tasks, it uses a SigLIP encoder to extract high-dimensional semantic features from images and flattens them into a one-dimensional sequence, mapping the image features into the input space of the language model through an understanding adapter. -
For visual generation tasks, it uses a VQ tokenizer to convert images into discrete IDs, flattens the ID sequence into one-dimensional, and maps the embeddings corresponding to each ID in the codebook into the input space of the language model through a generation adapter. -
These feature sequences are then concatenated to form a multimodal feature sequence, which is input into the language model for processing. -
For example, in multimodal understanding tasks, the model can accurately identify objects, scenes, and events in images and generate corresponding descriptions. -
In visual generation tasks, the model can generate high-quality images based on given text prompts. -
For example, given the prompt <span>A sunflower blooming in the sun with a bee on it</span>, Janus-Pro can generate an image showing the sunflower and the bee, with the bee’s wings glistening in the sunlight, rich in detail and aesthetic appeal.

3. Model Architecture
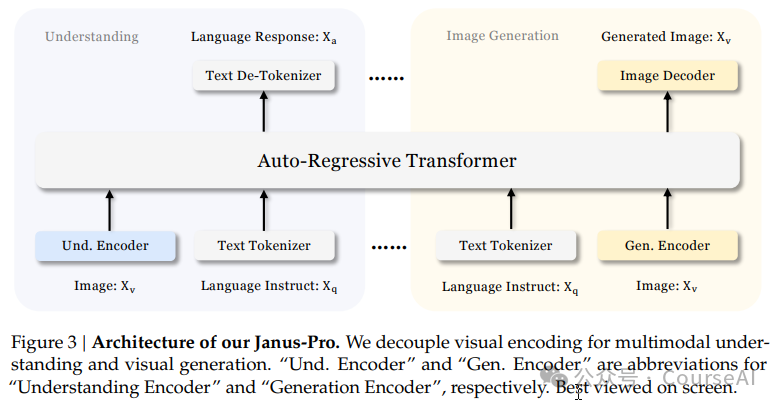
-
Janus-Pro is a unified MLLM for understanding and generation, decoupling visual encoding for multimodal understanding and generation. -
Janus-Pro is built on DeepSeek-LLM-1.5b-base/DeepSeek-LLM-7b-base. -
For multimodal understanding, it uses SigLIP-Large-Patch16-384 as the visual encoder, supporting 384 x 384 image input, with a codebook size of 16384 and an image downsampling factor of 16. -
Both understanding and generation adapters are two-layer MLPs. -
For image generation, Janus-Pro uses the tokenizer here, with a downsampling rate of 16.
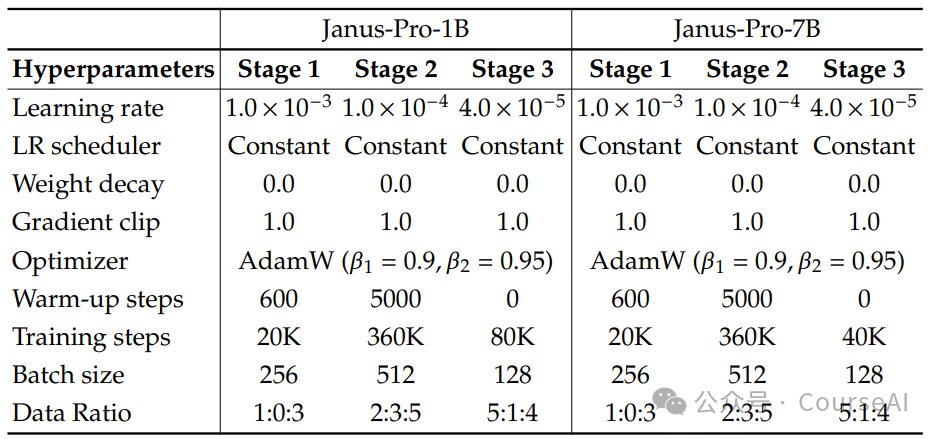
4. Training Techniques
The training process of Janus-Pro is divided into three stages.
-
In the first stage, the main focus is on training the adapters and the image head. -
By increasing the number of training steps, the model can effectively model pixel dependencies using the ImageNet dataset while keeping the language model parameters fixed, generating reasonable images. -
In the second stage, pre-training from text to image. -
Janus-Pro removed the ImageNet data and added about 90 million samples, including image caption datasets (such as YFCC) and data for table, chart, and document understanding (such as Docmatix), using regular text-to-image data for training to improve training efficiency. -
In the third stage, supervised fine-tuning. -
Janus-Pro adjusted the proportion of different types of data, changing the ratio of multimodal data, pure text data, and text-to-image data from 7:3:10 to 5:1:4, thereby enhancing multimodal understanding performance while maintaining strong visual generation capabilities. -
In multimodal understanding data, the long edge of the image is adjusted to 384 pixels, with the short edge filled with background color to 384 pixels. -
In visual generation data, the short edge of the image is adjusted to 384 pixels, with the long edge cropped to 384 pixels. -
Training efficiency is improved through sequence packing techniques, mixing all data types in a specified ratio within a single training step.
https://github.com/deepseek-ai/Janus
https://hf-mirror.com/deepseek-ai/Janus-Pro-7B
https://bgithub.xyz/deepseek-i/Janus/blob/main/janus_pro_tech_report.pdf