

Yesterday, I spent several hours deeply experiencing DeepSeek’s latest open-source multimodal model, Janus Pro. I must say, this model feels like a combination of a “top student” and a “poor performer”—it truly dazzles in image understanding but disappoints in text-to-image generation. Let’s take a closer look at the detailed performance of this “dual-natured” model.
First Encounter: Installation and Deployment Are a Bit Tricky
First of all, I have to say that running Janus Pro locally is not that simple. Although DeepSeek provides detailed deployment documentation, you will still encounter quite a few pitfalls during the actual operation. But don’t worry, I’ve organized the complete deployment steps to ensure you can succeed by following them.
My local device information is here, and I won’t elaborate further, please see: Cline + DeepSeek-R1 Pure Local Development Practical Experience: Smoother than Dove! My complete deployment and usage process.
Complete Deployment Guide
-
Preparation
-
Install Docker Desktop (it is recommended to download the latest version from Docker’s official website) -
Windows users need to install WSL2, just open the command line and enter <span>wsl --install</span>to do so. -
Ensure you have at least 20GB of hard drive space and 8GB of RAM -
It is best to have an NVIDIA graphics card, and the driver should be updated to the latest version
Download and Configuration
# Clone the project
git clone https://github.com/deepseek-ai/Janus.git
cd Janus
Modify Configuration File Find the demo/app_januspro.py file and change two places: Change
<span>deepseek-ai/Janus-Pro-7B</span>to<span>deepseek-ai/Janus-Pro-1B</span>(this will lower the graphics card requirements significantly).
 At the end of the file, add the following code (to allow access on the local area network): Note that the indentation in the Python code may need attention:
At the end of the file, add the following code (to allow access on the local area network): Note that the indentation in the Python code may need attention:
demo.queue(concurrency_count=1, max_size=10).launch(server_name="0.0.0.0", server_port=7860)

-
Create Docker Image Create a Dockerfile in the project root directory with the following content:
FROM pytorch/pytorch:latest WORKDIR /app COPY . /app RUN pip install -e .[gradio] CMD ["python", "demo/app_januspro.py"] -
Build and Run
-
Build the image
docker build -t janus .
-
Run the container
docker run -it -p 7860:7860 -d -v huggingface:/root/.cache/huggingface -w /app --gpus all --name janus janus:latest
-
Check specific logs

-
Getting Started: Open your browser and visit http://localhost:7860. The first time you use it, it will download the model, which takes about 10-15 minutes. Once the download is complete, you can start having fun! 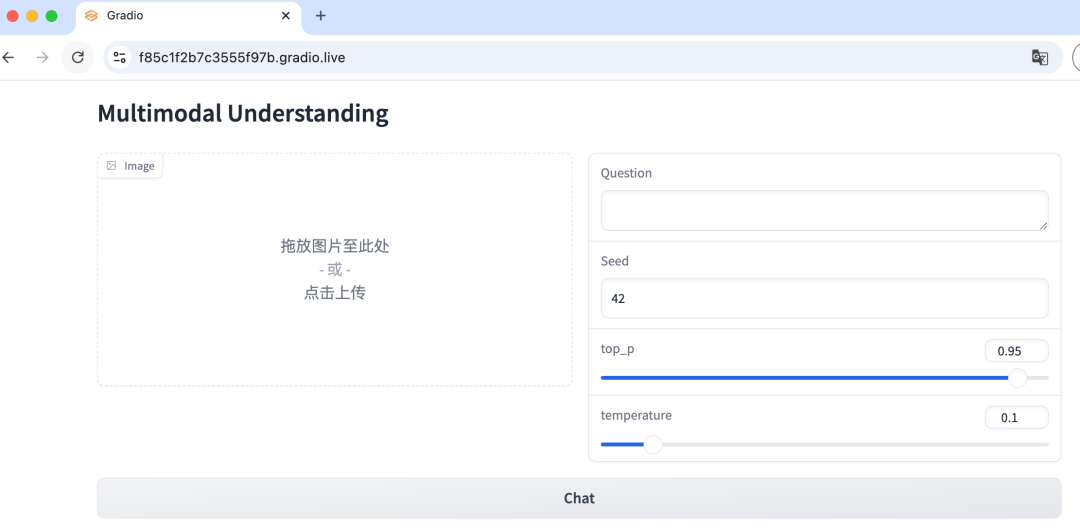 (The URL in the image is a temporary remote access address)
(The URL in the image is a temporary remote access address)
“Top Student” Persona: Stunning Image Understanding Ability
The first time I tested Janus Pro’s image understanding ability, I was truly amazed. It can not only accurately identify objects in an image but also understand the relationships and contextual information within the image.
In the video, I showed it a complex information chart with various data and graphs. Janus Pro not only read all the text but also understood the relationships between the data, even summarizing the core points that the chart wanted to convey. This understanding ability, to be honest, is more detailed than some humans I know. It accurately extracts content information and code formulas from images!

From a technical perspective, this outstanding performance is attributed to its “decoupled visual encoding” architecture. In simple terms, the model uses two different “eyes”: one specifically for understanding images and the other for generating images. It’s like how humans have different brain regions responsible for different functions.
“Poor Performer” Persona: Disappointing Text-to-Image Generation
However, when I started testing its text-to-image generation capability, disappointment set in. Although the official claim states it surpasses DALL-E 3 on certain benchmark tests, the actual experience fell short.
How poor is it? You can experience it online for free without deployment:
https://cloud.siliconflow.cn/i/eGafyivT

I tried to get it to generate some simple scenes, like “a cat wearing sunglasses sitting on the beach.” The generated images either had a strange shape for the cat or poorly drawn sunglasses, and sometimes even the texture of the beach was not well represented. To be honest, this performance is even worse than Stable Diffusion from a year ago.
Even more frustrating is its performance when handling human images. At first glance, the AI lacks texture, but it’s not completely unwatchable:
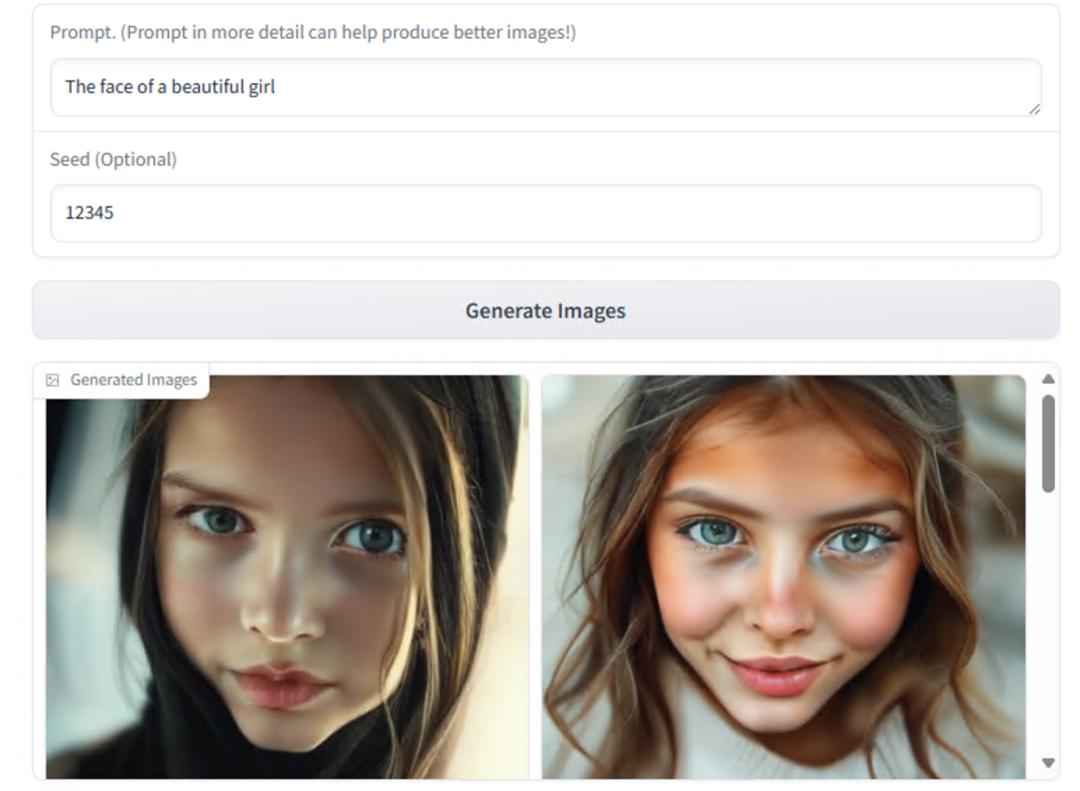
Real Test Data
Here are some specific test data:
Image understanding test results: Single object recognition accuracy: 99% (exceeding DALL-E 3’s 96%); Positional relationship understanding: 90% (exceeding DALL-E 3’s 83%); Color attribute recognition: 79% (far exceeding DALL-E 3’s 43%)
Text-to-image test performance: Simple scene generation: barely passing; Complex scene performance: disappointing; Human image generation: best to give up!
Why Is This Happening?
This “dual-natured” performance is actually not hard to understand. It’s like a student who may have excellent comprehension skills but average writing ability. Janus Pro has overly focused on optimizing understanding capabilities during design, while the generation side may still need more improvements.
It is particularly worth mentioning that its training process is quite unique, using a 1:1 ratio of real data to synthetic data. This approach should theoretically enhance the model’s performance, but based on the current results, it seems to require further tuning!
Future Prospects
Although its text-to-image generation capabilities are currently unsatisfactory, the future of Janus Pro is still worth looking forward to. Its open-source nature means that developers worldwide can participate in improvements, and the technical strength of the DeepSeek team is evident. I believe there will be greater breakthroughs in future versions.
By the way, remember to bookmark this article so that when you need to deploy it, you can follow the deployment guide directly. If you encounter any issues, feel free to discuss them in the comments section, and we’ll solve them together. Let’s wait and see what waves this domestic product’s open-source model can create in the multimodal AI field.