
As the Spring Festival approaches, DeepSeek is once again making strides by launching the multimodal open-source large model—Janus Pro. Although its performance is not as stunning as the previous R1, it still attracts attention due to its comprehensive architectural optimizations and open-source features.
This article provides an in-depth interpretation of the technical innovations and experimental results of Janus Pro from DeepThink.
For those who wish to read the original technical report, please click on the 【Read Original】 link at the end of the article.
1. Research Background and Motivation
-
Problem Identification: Traditional multimodal unified models use a single visual encoder to handle understanding and generation tasks, leading to representation conflicts that affect performance (e.g., unstable generation quality, poor performance on short prompts). -
Limitations of Existing Work: -
Data Limitations: Low quality and noisy training data (e.g., insufficient aesthetic quality of real data). -
Model Capacity Limitations: Janus only verifies a 1B parameter scale, which cannot fully exploit multimodal potential. -
Inefficient Training Strategies: Staged training (e.g., Stage II relies on ImageNet data) leads to computational redundancy. -
Research Goals: To enhance the synergy of multimodal understanding and generation by optimizing training strategies, expanding data scale (multimodal understanding + visual generation), and increasing model parameters (1B→7B).
2. Methods and Technical Innovations
-
Architecture Design: 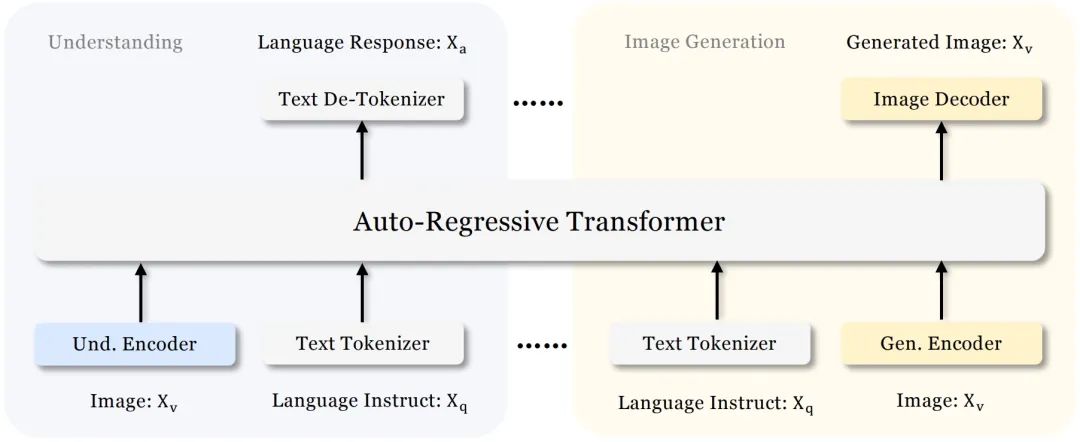
-
Understanding Task: Use SigLIP to extract high-dimensional semantic features and map them to the LLM input space via an MLP adapter. -
Generation Task: Use a VQ tokenizer to discretize images and map them to the LLM via another MLP adapter. -
Visual Encoding Decoupling: -
Unified Autoregressive Framework: The multimodal feature sequence (understanding + generation) inputs the LLM, sharing parameters but predicting tasks separately (using the LLM head for understanding and an independent head for generation). -
Training Strategy Optimization: -
Stage I Extension: Fix the LLM parameters to fully train the adapter and image head, enhancing ImageNet category generation capability. -
Stage II Focus: Abandon ImageNet data and directly train dense text-image data to improve efficiency. -
Stage III Data Ratio Adjustment: Adjust the multimodal: pure text: generated data ratio from 7:3:10 to 5:1:4 to balance generation and understanding performance. -
Data Expansion: -
Multimodal Understanding: Added 90M samples (covering charts, document understanding, and Chinese dialogue data). -
Visual Generation: Introduced 72M synthetic aesthetic data (e.g., Midjourney prompts), mixing real and synthetic data in a 1:1 ratio to enhance generation stability and quality. -
Model Expansion: -
Parameter scale expanded from 1B (24 LLM layers) to 7B (30 layers), validating the positive correlation between model size and performance (7B converges faster and shows significant performance improvement).
3. Experimental Design and Evaluation
-
Benchmark Testing: -
Multimodal Understanding: MMBench (79.2), GQA (62.0), MMMU (41.0), MM-Vet (50.0). -
Visual Generation: GenEval (0.80), DPG-Bench (84.19). -
Comparison Results: 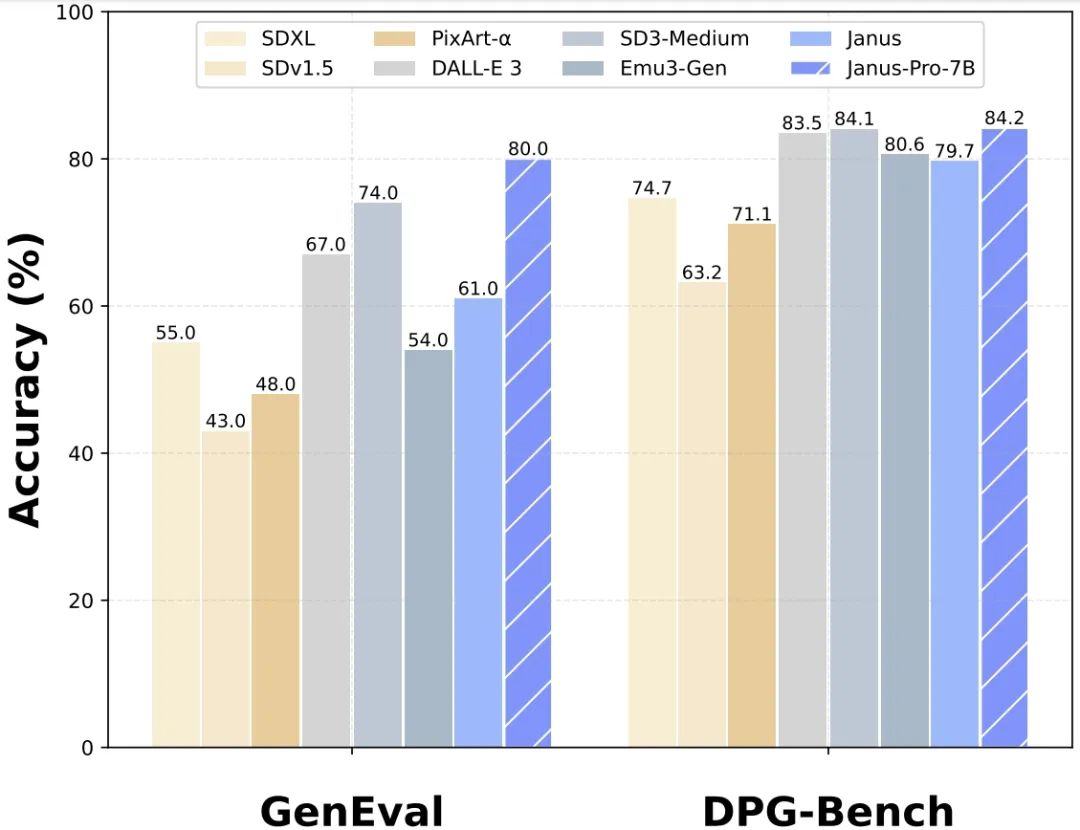
-
Multimodal Understanding: Surpassing LLaVA-v1.5 (7B), Qwen-VL-Chat (7B), TokenFlow-XL (13B). -
Visual Generation: Better than DALL-E 3 (0.67), Stable Diffusion 3 Medium (0.74). -
Key Results: -
Quantitative Metrics: Janus-Pro-7B improved by 9.8 points in MMBench compared to Janus (69.4→79.2), and improved by 19% in GenEval (0.61→0.80). -
Qualitative Analysis: Generated images at a resolution of 384×384 with rich details (e.g., rock textures, lighting effects), semantically aligned with dense prompts (e.g., “crystal ball in a desert sunset”).
4. Advantages and Limitations
-
Advantages: -
Task Decoupling: Independent visual encoding alleviates conflicts in multitasking, enhancing both understanding and generation performance. -
Data-Driven: Synthetic data significantly improves the aesthetic quality of generation (e.g., reduces noise-induced blurriness). -
Scalability: The 7B model validates the compatibility of methods with parameter scale (e.g., improved convergence speed). -
Limitations: -
Resolution Limitations: Input images at 384×384 affect fine-grained tasks like OCR. -
Insufficient Generation Detail: Low resolution and tokenizer reconstruction loss lead to blurriness in small areas (e.g., faces).
5. Potential Impact and Applications
-
Academic Value: -
Validates the effectiveness of visual encoding decoupling in multimodal unified models, providing design references for future research (e.g., video generation). -
Proposes a mixed training paradigm of synthetic and real data, enhancing generation controllability. -
Application Scenarios: -
Creative Content Generation: Supports complex instruction-driven image generation (e.g., advertising, art design). -
Multimodal Dialogue Systems: Combines understanding (Q&A) and generation (scene description) capabilities in an end-to-end manner.
6. Future Research Directions
-
Technical Improvements: -
Upgrade input resolution (e.g., 768×768) to enhance fine-grained understanding. -
Introduce diffusion models to replace VQ tokenizers, reducing reconstruction loss (e.g., potential space design of SD3). -
Exploration of Expansion: -
Verification of models with hundreds of billions of parameters to explore larger scale potential. -
Cross-modal task generalization (e.g., 3D generation, video generation).
Summary
Janus-Pro achieves a breakthrough in the synergy of multimodal understanding and generation tasks through decoupling visual encoding, data and model expansion, and training strategy optimization, although there is still room for improvement in resolution and detail generation. This work provides important references for the architectural design and data optimization of multimodal models.
Finally, most of the above content comes from DeepSeek’s DeepThink. For specific acquisition methods, refer to the video below:
Thank you for reading. If this article has been helpful to you, please like, share, or follow!