Click the card below to follow “Machine Vision and Deep Learning”
Visual/image heavy content delivered first!
In many enterprise applications, Optical Character Recognition (OCR) is a fundamental technology. In this article, we will delve into Surya-OCR, a recently popular solution. Text detection and extraction are crucial in various business use cases. For example:
In manufacturing, extracting invoice details from documents is essential.
The insurance industry uses OCR technology to automate the digitization of claims, while healthcare applications utilize OCR to extract medication information from clinical records.
Surya is a document OCR toolkit that features:
-
OCR supporting over 90 languages, benchmarked to outperform cloud services
-
Line-level text detection for any language
-
Layout analysis (detection of tables, images, headings, etc.)
-
It is suitable for a range of documents (for more details, see usage and benchmarks).
https://github.com/VikParuchuri/surya
Before installing Surya, ensure that two prerequisites are met:
-
Python version 3.9 or higher is required.
-
PyTorch must be installed on the system.
If you are using an older version of Python, you can update it using the following command:
To install the latest version of torch, visit the following page and generate the command according to your environment – https://pytorch.org/get-started/locally/
In short, if you are using a CPU machine, simply run:
If it’s a GPU machine, ensure to install torch with cuda:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
Next, install Surya-OCR:
Surya supports multiple languages. To perform text detection, let’s select an image from a Wikipedia page.

The image consists of two columns and also includes header and footer annotations. Text detection can be accomplished in three consecutive steps.
【1】Load the image – use the PIL library to load the png file
from PIL import Image
image = Image.open("test.png")
print(image)
from surya.model.segformer import load_model, load_processor
model, processor = load_model(), load_processor()
The first time you run this command, the model will be downloaded from HuggingFace. For subsequent runs, the model will be cached and loaded quickly.
【3】Perform text detection — use the surya batch_inference component
from surya.detection import batch_inference
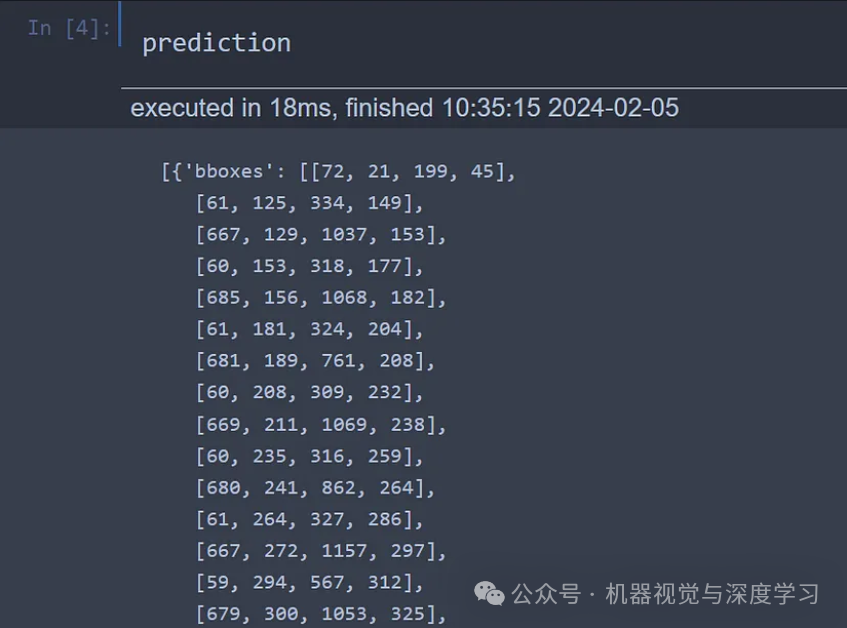
prediction = batch_inference([image], model, processor)
print(prediction)
The Python interface prints the coordinates of the bounding box for the detected text:
You can use the following commands to view the heatmap and affinity map:
prediction[0]["affinity_map"]
Text detection can also be performed via the command line:
surya_detect DATA_PATH --images
DATA_PATH can be an image, pdf, or image/pdf folder
–images will save the page images and detected text lines (optional)
–max specify the maximum number of pages to process if you do not want to process everything
–results_dir specify the directory to save results instead of the default directory

Surya detected almost 99% of the body text. The footer was covered. However, it could not detect the header correctly.
Surya runs seamlessly in both CPU and GPU environments. In GPU environments, Surya automatically detects the GPU and utilizes it without any additional setup.
The Surya team is currently focused on developing multiple features, including text extraction, heading detection, and table extraction.
https://github.com/VikParuchuri/surya?tab=readme-ov-file#surya
After release, we can compare the results with EasyOCR or PaddleOCR to evaluate its performance.
The code can be accessed via the following link:
https://github.com/srinathmkce/TheAIGuy/blob/main/ComputerVision/OCR/Surya-OCR.ipynb