Introduction
It is an open-source RAG (Retrieval-Augmented Generation) engine built on deep document understanding. It mainly provides a streamlined RAG workflow for enterprises and individuals of various sizes, leveraging large language models (LLMs) to handle users’ diverse complex format data, offering reliable Q&A and well-founded citations.
Its main features include:
1. Deep Document Understanding: Capable of extracting insights from various complex formats of unstructured data.
2. Template-Based Text Slicing: Provides various text templates for intelligent and controllable text processing.
3. Reducing Hallucination: Visualization of the text slicing process supports manual adjustments, ensuring that answers provide key citation snapshots and support traceability.
4. Compatible with Various Heterogeneous Data Sources: Supports a wide range of file types including Word documents, PPT, Excel spreadsheets, txt files, images, PDFs, photocopies, structured data, web pages, etc.
5. Worry-Free, Automated RAG Workflow: Optimizes the RAG workflow, supporting various ecosystems from personal applications to large enterprises, providing easy-to-use APIs for integration into various enterprise systems.
Its launch aims to address the current issues encountered in implementing RAG (Retrieval-Augmented Generation), such as multi-route recall capabilities of databases and data processing problems. By providing dedicated databases and tools, it intends to make RAG easier for more enterprises and individuals to use and unlock more application scenarios.
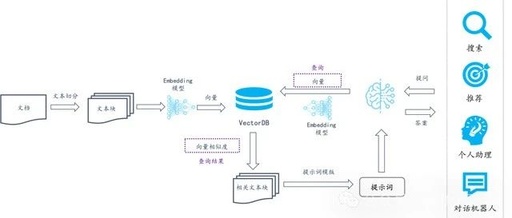
For a long time, RAG has been synonymous with knowledge bases in the industry. The aforementioned application architecture has not only sparked interest in vector databases but also in middleware represented by LangChain and LlamaIndex, which are responsible for handling the workflows behind the various arrows in the diagram above. Specifically, it includes:
1. Splitting the user’s documents and then calling an embedding model to generate vectors from the split documents.
2. Writing the generated vectors along with the original documents into the vector database.
3. During queries, generating vectors from the user’s questions using the same embedding model, then querying the vector database to return the Top K results.
4. Compiling the texts corresponding to the Top K results into prompts for the large model to summarize and complete the content.
Thus, the core components of the entire architecture are two:
1. Vector Database: Responsible for querying and recalling user documents based on vectors.
2. Middleware: Responsible for document slicing and converting them into suitable vectors.
The use of vectors is because they can provide semantic recall; users just need to ask questions, and the most relevant answers can be returned based on similarity without considering whether the question actually matched any keywords in the document. Even without matches, answers can still be returned based on semantic similarity. The reason for needing to slice user documents is that the semantics represented by vectors can be ambiguous; not only can an article be represented as a vector, but a single word can also be represented as a vector, which makes it difficult to control the granularity of the text blocks corresponding to vectors: if the granularity is too coarse, using one vector to represent a large paragraph makes it hard to represent the details of the text; if the granularity is too fine, a large paragraph will correspond to many vectors, with each vector representing only a few words’ semantics, making it impossible to find semantically matching vectors simply based on similarity. Therefore, documents need to be sliced in a “proper” way, which is the core work of middleware like LangChain and LlamaIndex.
So, how is “proper” defined? Typically, some simple strategies are employed: for example, first splitting the document into different paragraphs based on whitespace between words, which represent a relatively suitable granularity. Then, titles (which usually need to be judged by certain rules) are often merged with these paragraphs so that the paragraphs containing only local text can also reflect the semantics of the entire article or certain sections.
As a result, with such components, a RAG system can be quickly built. However, since this application architecture became popular in April 2023, it has faced a debate: “It is better to fine-tune user data into large models to answer questions directly without the entire retrieval-based architecture of RAG.” This debate has accompanied the entire year of 2023. Until today, the voices of this debate have gradually faded. Because, evidently, in terms of real-time performance and cost, using RAG is far superior to fine-tuning LLMs. Proponents of fine-tuning prioritize answer quality, but more evaluations have found that the gap between the two is not significant, leading to the conclusion that both need to be used in conjunction. Moreover, this so-called combined usage scheme, with the rapid iteration of open-source LLMs, has led to very few actually adopting fine-tuning.
Main Features
🍭 “Quality In, Quality Out”
-
Based on deep document understanding, capable of extracting insights from various complex formats of unstructured data.
-
Truly completing needle-in-a-haystack testing quickly in an unlimited context (token) scenario.
🍱 Template-Based Text Slicing
-
Not just intelligent, but importantly controllable and explainable.
-
Various text templates are available.
🌱 Well-Founded, Minimizing Hallucination
-
Visualization of the text slicing process supports manual adjustments.
-
Well-founded: Answers provide key citation snapshots and support traceability.
🍔 Compatible with Various Heterogeneous Data Sources
-
Supports a rich variety of file types, including Word documents, PPT, Excel spreadsheets, txt files, images, PDFs, photocopies, structured data, web pages, etc.
🛀 Worry-Free, Automated RAG Workflow
-
Comprehensively optimized RAG workflow supports various ecosystems from personal applications to large enterprises.
-
Large language models (LLMs) and vector models are both configurable.
-
Based on multi-route recall and fusion reordering.
-
Provides easy-to-use APIs that can be easily integrated into various enterprise systems.
Supported File Types
It supports various types of structured data processing. Specifically, it can handle files in formats including but not limited to:
– Word documents
– PPT
– Excel spreadsheets
– txt files
– Images
– PDFs
– Photocopies
– Structured data
– Web pages, etc.
Through its deep document understanding capabilities, it can extract insights from these complex formats of unstructured data, thereby providing reliable Q&A services. This makes it an effective tool for handling various complex format data for enterprises and individuals.
How to Ensure Content Originality
It does not directly detect or ensure content originality, but it can help improve content originality in the content creation process through the following ways:
1. Information Retrieval and Citation: It can assist you in retrieving relevant information and providing accurate citations. This helps you clearly distinguish between original materials and cited content during creation, avoiding unintentional plagiarism.
2. Content Paraphrasing and Integration: By using the retrieved information, you can help paraphrase or integrate this information in your own words and perspectives, thus enhancing content originality.
3. Diversification of Sources: It supports retrieving information from multiple data sources, which can help you obtain a broader range of materials, reducing reliance on a single source and creating more diverse content.
4. Improving Work Efficiency: It can automate and simplify the information retrieval and organization process, allowing you more time and energy to focus on creation and reducing non-original behaviors such as copy-pasting due to time constraints.
5. Content Review and Proofreading: While it does not directly check for originality, the information and citations it provides can help you check for missing citations or areas that need further rewriting during later reviews and proofreading.
Ultimately, ensuring content originality still requires the creator’s own efforts, such as in-depth analysis of materials, critical thinking, and expressing in their own words and viewpoints. It can serve as an auxiliary tool to help you handle information more efficiently during the creation process, but it cannot replace the originality and creativity of the creator themselves. If you need to check content originality, you may need to use specialized plagiarism detection tools or services.
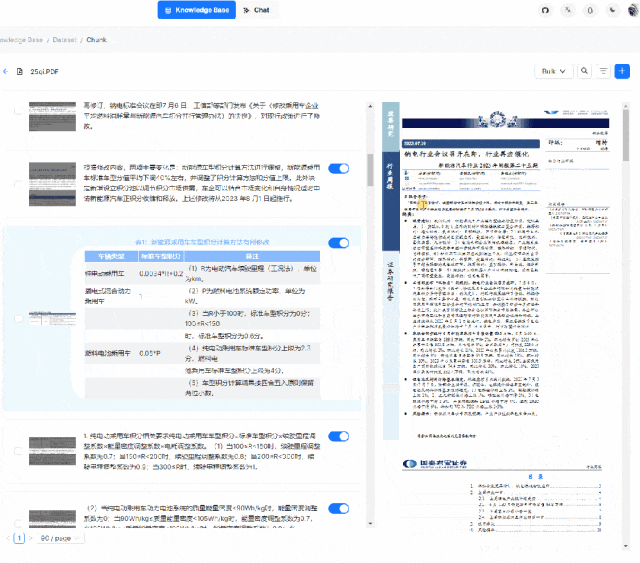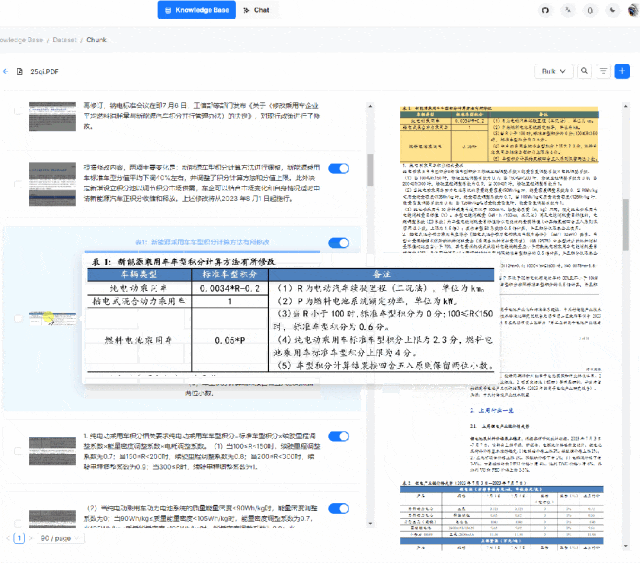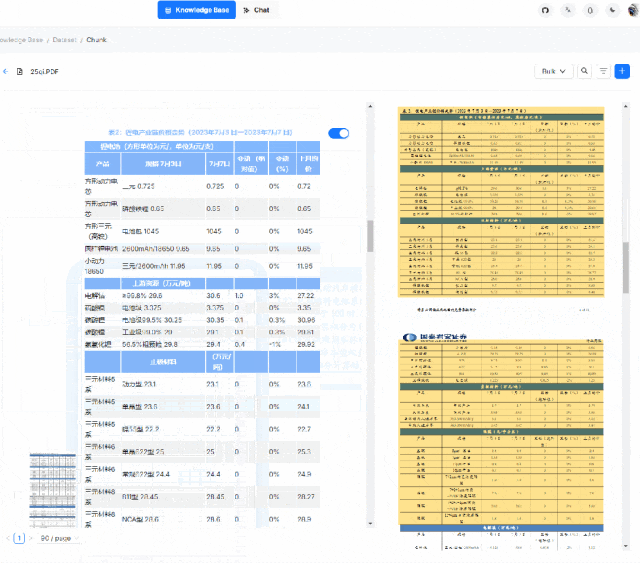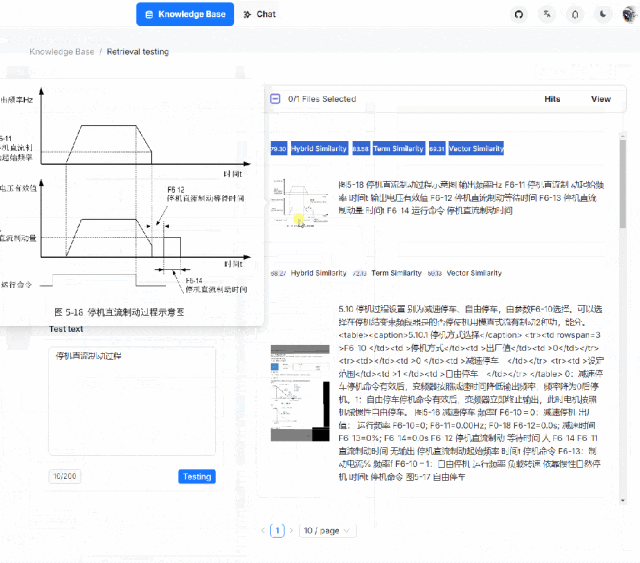
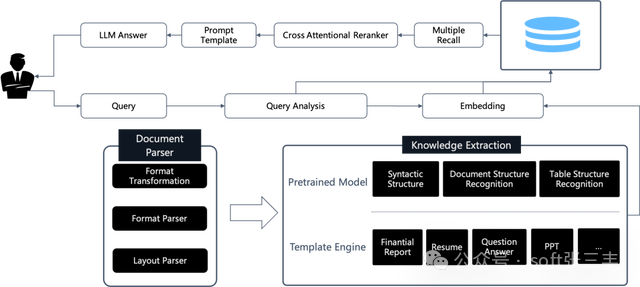
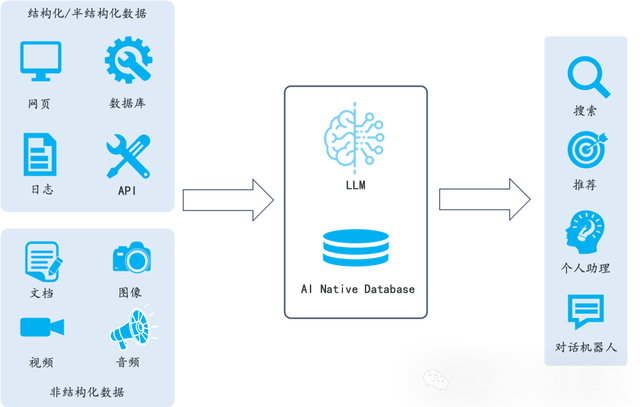
System Architecture
Its system architecture is designed to provide an efficient, flexible, and scalable platform for handling and enhancing Retrieval-Augmented Generation (RAG) tasks. The system includes the following key components:
1. Data Input Interface: This is where the system receives various format data, including structured and unstructured data such as text files, PDFs, images, web pages, etc.
2. Data Processing Module: This module is responsible for extracting information from the input data and performing necessary preprocessing, such as text extraction, image recognition, format conversion, etc.
3. Information Retrieval Engine: This component is the core of the system, using deep learning models and large language models (LLMs) to understand and retrieve relevant information. This may include using vector databases and similarity search techniques to quickly find the most relevant data segments to the queries.
4. Generation Engine: Based on the retrieved information, the generation engine uses natural language processing (NLP) techniques to generate new text content. This may include answering questions, writing summaries, generating reports, etc.
5. User Interface and API: The user interface allows users to interact with the system, submit queries, view results, etc. The API allows developers to integrate it into other applications.
6. Visualization Tools: To improve transparency and interpretability, it may include visualization tools that allow users to view and adjust the text slicing process.
7. Database and Storage: The system needs a place to store and manage large amounts of data, including raw data, processed data, and generated outputs.
8. Security and Compliance Module: Ensures the system’s data security and compliance with relevant laws and regulations.
9. Monitoring and Logging: These components are used to track the system’s performance and record operational history for troubleshooting and performance optimization.
Trial Product
Open Source Address
infiniflow/ragflowAuthor Introduction:
Zhang Feng, original author of practical microservice architecture, with over 10 years of software development and architecture design experience. He is a software engineer passionate about exploring new technologies and models, with in-depth research in microservice architecture, container technology, and automated deployment. Throughout his career, he has worked in several well-known companies, serving as a technical team leader, leading the team to achieve a series of high-concurrency, high-availability microservice architecture projects.
Teacher Zhang Feng has rich practical experience in the field of microservice architecture, and his work “Practical Microservice Architecture” introduces the design concepts, technology stack choices, project practices, and other key aspects of microservice architecture in an accessible manner, receiving high praise from readers. In addition, he is active in the technical community, sharing his insights and experiences to help more developers grasp the essence of microservice architecture.
You Might Like:
[Open Source] A high-performance, scalable distributed process orchestration service from Weibo, featuring core capabilities: high performance with support for tens of millions of tasks execution, execution latency below 100ms.
[Open Source] Messaging platform (8K stars), useful for graduation projects, campus recruitment, and observing how messages are pushed in production environments.
[Open Source] A visual drag-and-drop editing page generation tool based on Vue. Enhances front-end development efficiency and can be integrated into mobile projects to generate UI interfaces directly through defined JSON.
[Open Source] This project is an extremely simple workflow with minimal design, a small amount of code, and only 6 tables, allowing the complete design to be viewed within an hour. Convenient to use.
[Open Source] A system that can be used with one-click deployment, supporting direct import of various document formats such as Word, PPT, Excel, PDF, images, etc., enabling Q&A similar to ChatGPT.
Add WeChat to join relevant discussion groups,
Note “Microservices” to join the group for discussion
Note “Low Start” to join the low start group for discussion
Note “AI” to join the big data and data governance group for discussion
Note “Digital” to join the IoT and digital twin group for discussion
Note “Security” to join the security-related group for discussion
Note “Automation” to join the automation and operations group for discussion
Note “Trial” to apply for product trial

Follow the public account soft Zhang Sanfeng