Follow the official WeChat account “ML_NLP“
Set as “Starred“, delivering heavy content to you first!

Engineers in the OCR field must have heard of the PaddleOCR project,
whose main recommended PP-OCR algorithm has been widely used by developers in China and abroad,
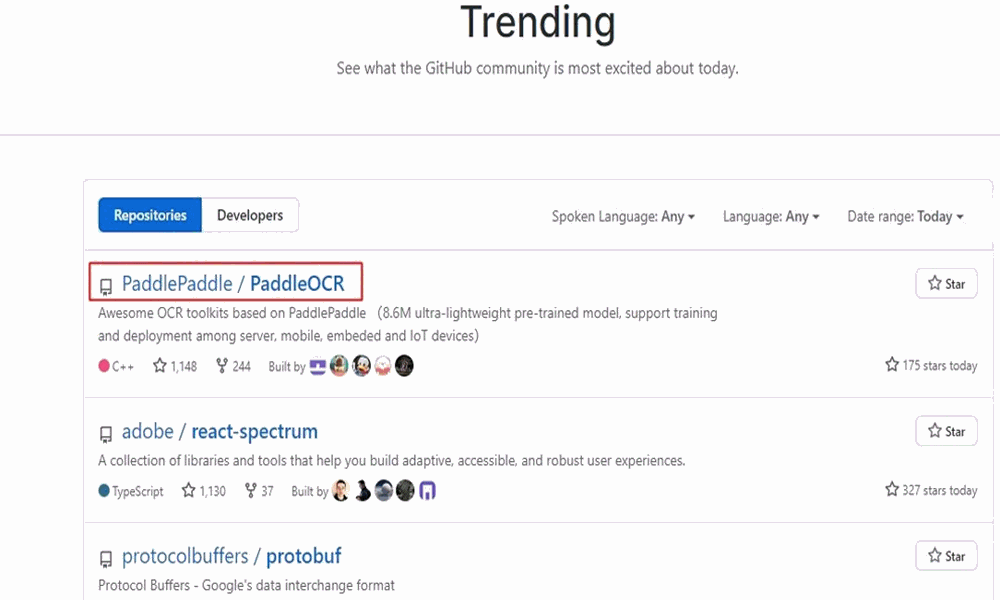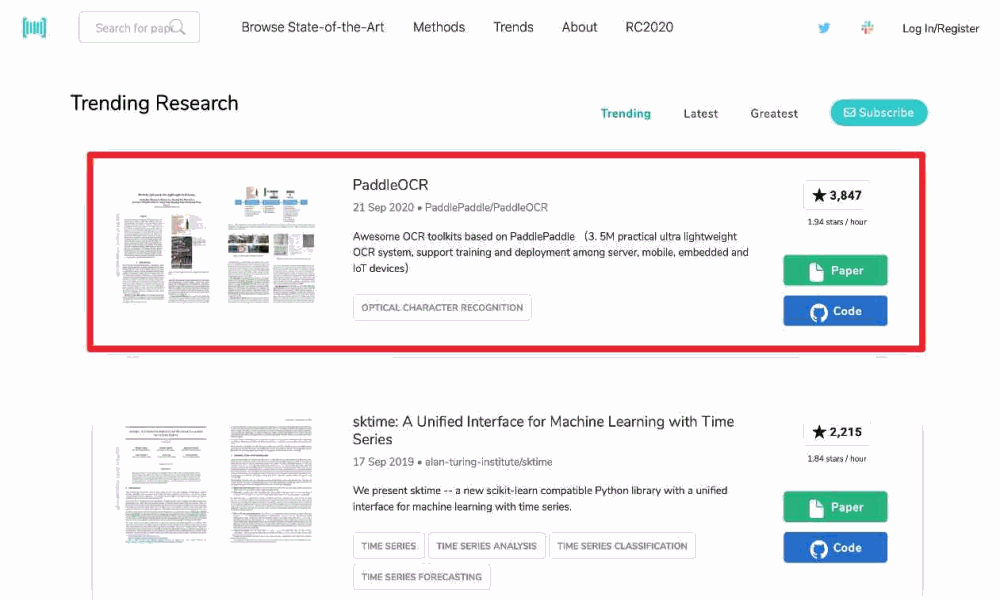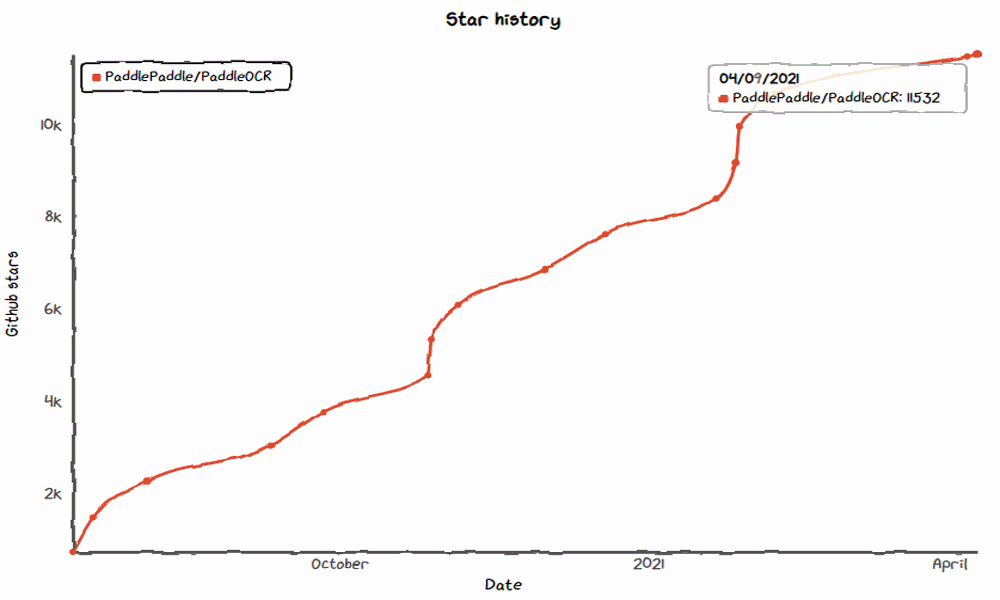
In just half a year,the total number of stars has exceeded 15k,
frequently topping GitHub Trending and Paperswithcode daily and monthly lists,
rated asone of the Top 20 active projects on GitHub in China in the “GitHub 2020 Digital Insight Report”,
calling it the hottest repo in the OCR field is absolutely justified.
Recently, the original team of PaddleOCR has made some empirical improvements to PP-OCR, constructing a new OCR system called PP-OCRv2.
★ From the perspective of algorithm improvement, there are mainly five aspects of enhancement:
-
Detection model optimization: adopting the CML collaborative mutual learning knowledge distillation strategy;
-
Detection model optimization: CopyPaste data augmentation strategy;
-
Recognition model optimization: LCNet lightweight backbone network;
-
Recognition model optimization: UDML improved knowledge distillation strategy;
-
Recognition model optimization: Enhanced CTC loss function improvement.
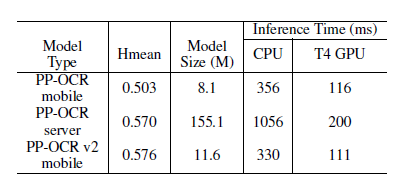
★ In terms of performance, there are mainly three improvements:
-
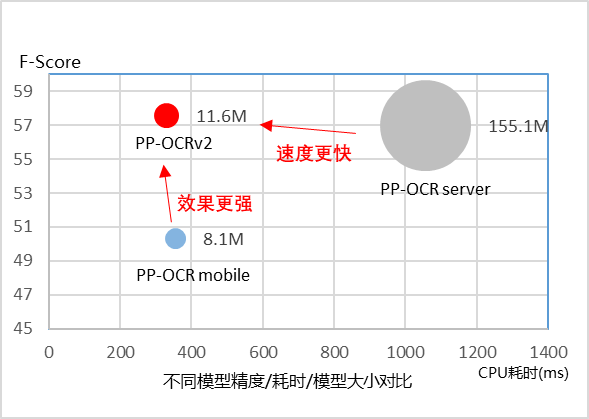
In model performance, it has improved by over 7% compared to the mobile version of PP-OCR;
-
In speed, it has improved by over 220% compared to the server version of PP-OCR;
-
In model size, with a total size of 11.6M, it can be easily deployed on both server and mobile.
Note: In consideration of new users who are just getting to know PaddleOCR, the second and third parts will provide some background introduction, while experienced users can skip directly to the fourth part.
2. Review of PaddleOCR’s Historical Performance
In June 2020, an 8.6M ultra-light model was released,topping the GitHub Trending daily chart.
In August 2020, the open-source CVPR 2020 top conference algorithm topped the GitHub trending list again!
In October 2020, the PP-OCR algorithm was released, open-sourcing a 3.5M ultra-light model, and topped thePaperswithcode trending list!
In January 2021, the Style-Text text synthesis algorithm and PPOCRLabel data annotation tool were released, with star numbers exceeding 10000+, and it was rated asone of the Top 20 active projects on GitHub in China.
In April 2021, the open-source AAAI top conference paper PGNet end-to-end recognition algorithm was released, with stars exceeding 13k.
In August 2021, the open-source layout analysis and table recognition algorithm PP-Structure was released, with stars exceeding 15k.
In September 2021, the PP-OCRv2 algorithm was released, with further upgrades in performance and speed.
3. Overview of PaddleOCR’s Open Source Capabilities
★ General Text Detection and Recognition Performance: Supports fast detection and recognition of OCR text in general scenarios

★ Style-Text Text Synthesis Tool Performance: Compared to traditional data synthesis algorithms, Style-Text can achieve image style transfer in special backgrounds, requiring only a few target scene images to synthesize a large amount of data, as shown below:
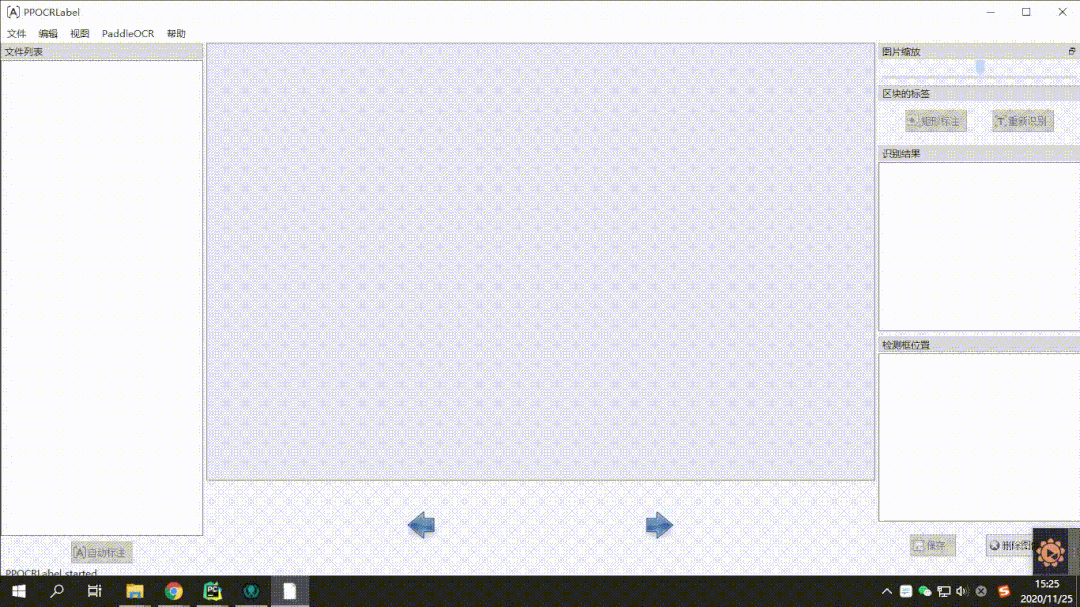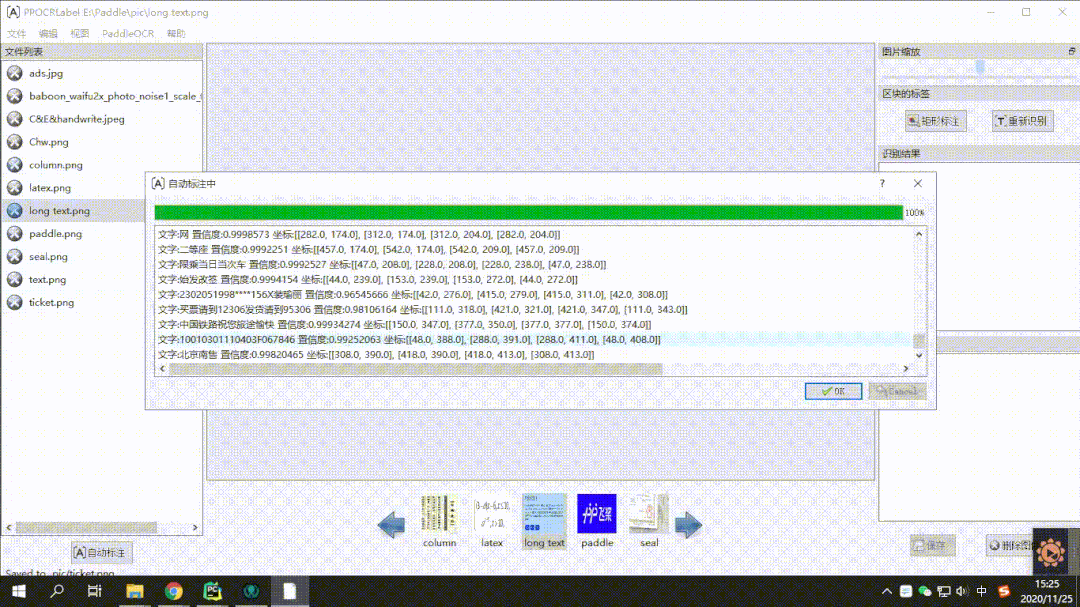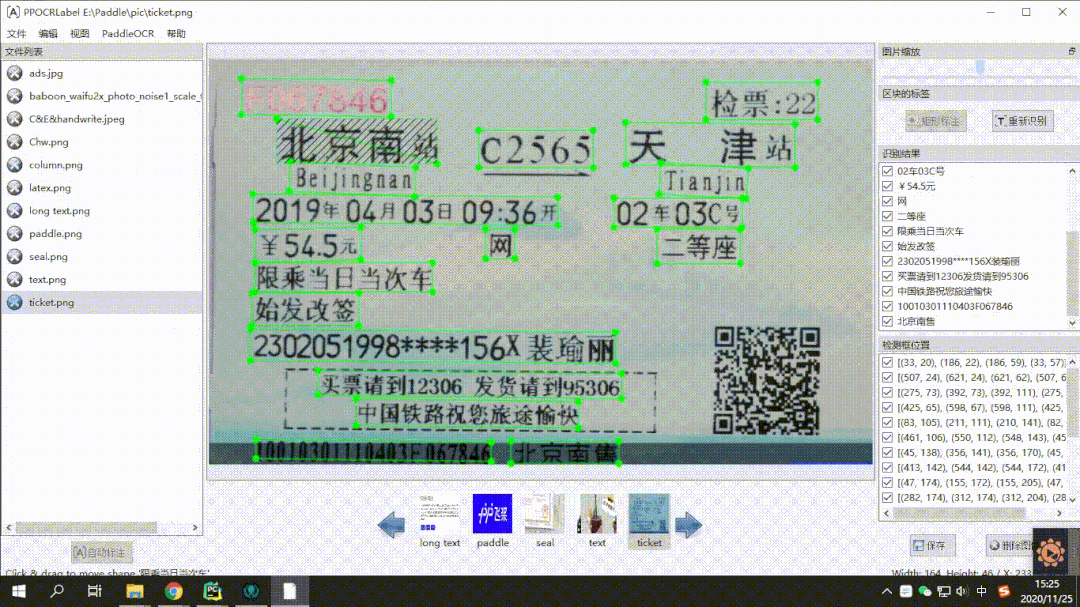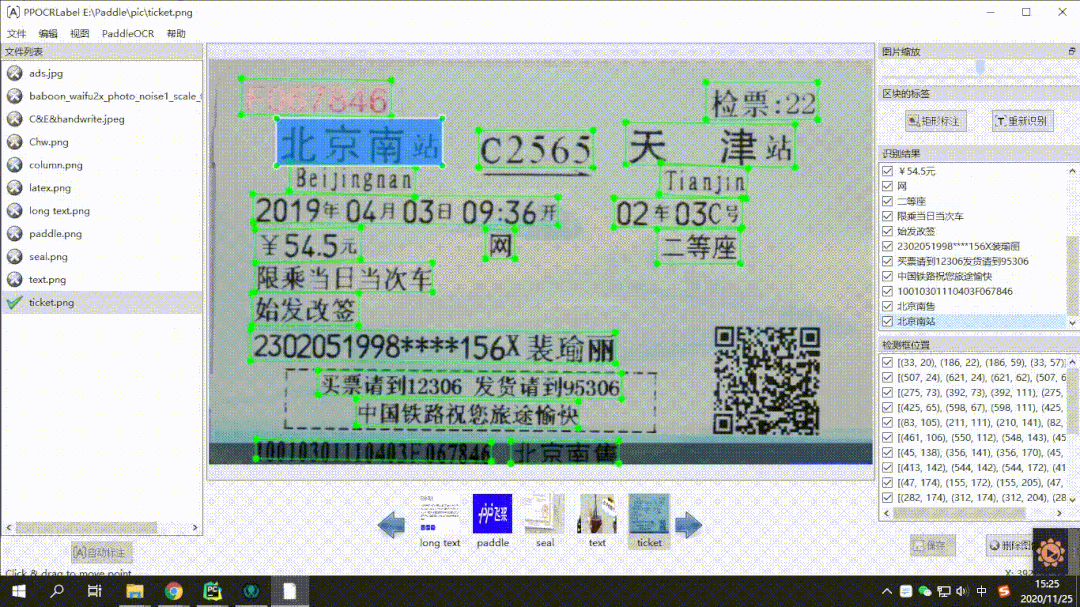
★ Semi-Automatic Annotation Tool PPOCRLabel: Through the built-in high-quality PP-OCR Chinese and English ultra-lightweight pre-trained model, it can achieve efficient annotation of OCR data. Running on a CPU machine is also completely fine. The usage is very simple, and the annotation efficiency is guaranteed to improve by 60%-80%, as shown in the demonstration below:
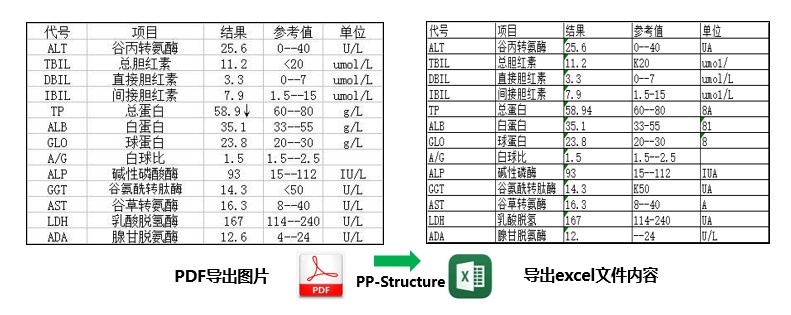
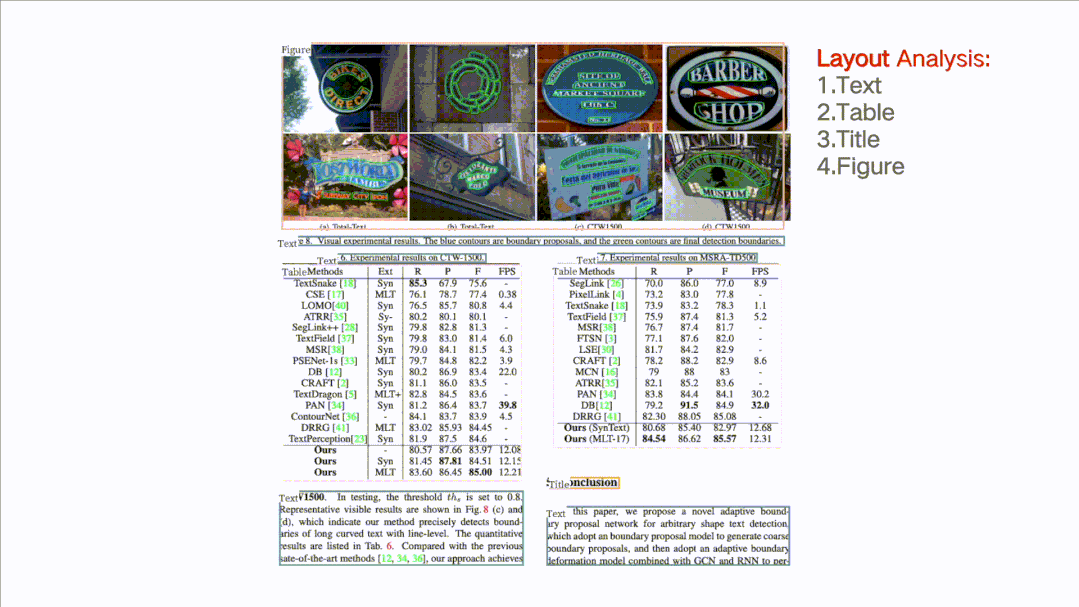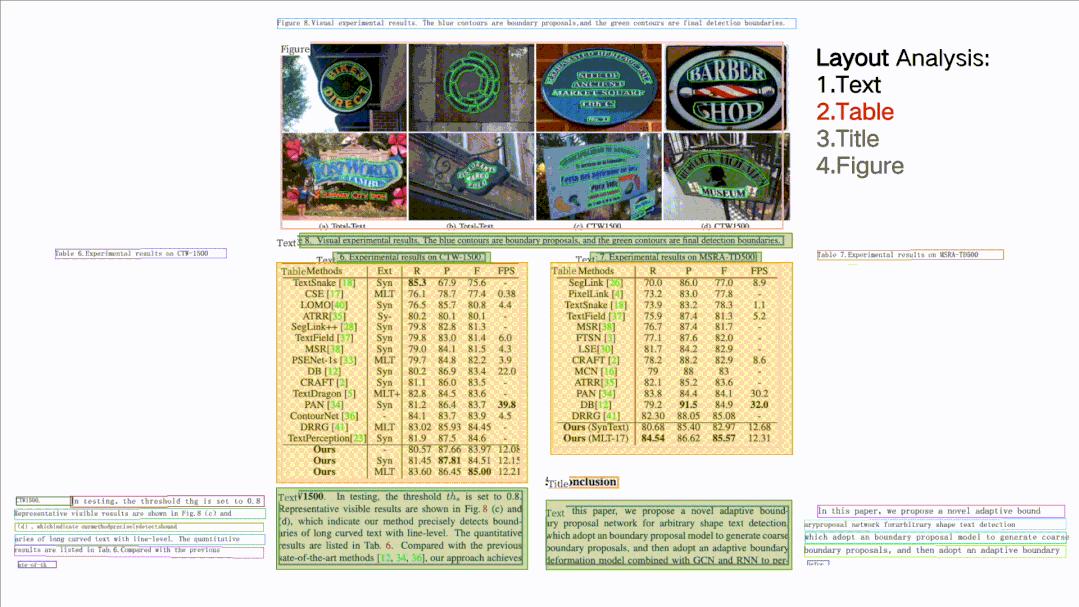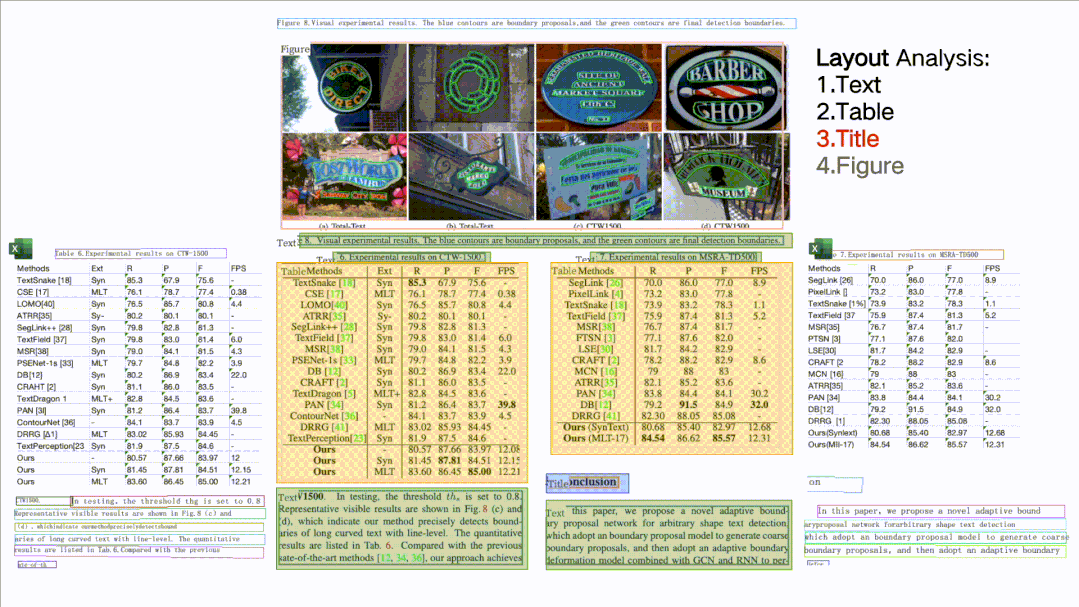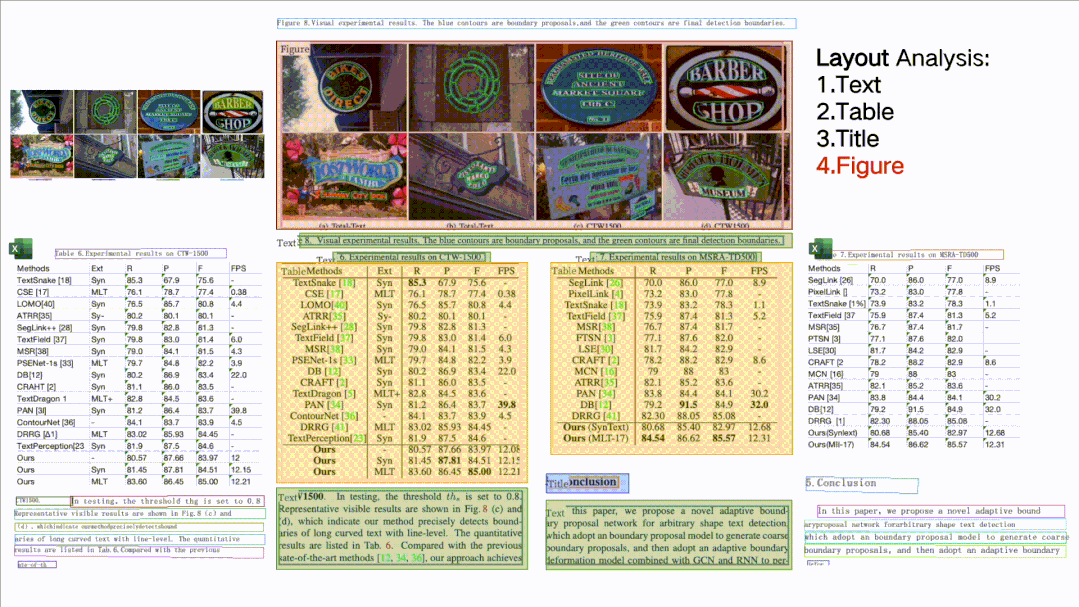
★ Document Structure Analysis + Table Extraction PP-Structure: Can classify text, tables, images, titles, and list areas in document images, and can also use table recognition technology to completely extract table structure information, allowing table images to be converted into editable Excel files.
★ Core Capabilities Can All Be Custom Trained, Unified Development Experience
Dynamic and static graphs are two commonly used modes in deep learning frameworks. In dynamic graph mode, the coding and running methods align with Python programmers’ habits, making it easy to debug, but in terms of performance, Python execution has a larger overhead compared to C++. In contrast, static graphs have performance advantages in deployment. Static graph programs can be compiled and executed, allowing the pre-built neural network to be executed independently of Python and re-parsed in C++, and overall network structure can also be optimized.
PaddleOCR relies on the unified capabilities of the PaddlePaddle core framework, supporting users to write network code using dynamic graphs. During prediction deployment, PaddlePaddle analyzes user code and automatically converts it into static graph network structures, balancing the advantages of dynamic graph usability and static graph deployment performance.
Github: https://github.com/PaddlePaddle/PaddleOCR
So what surprises does the recent update in September 2021 bring to PaddleOCR?
4. In-depth Analysis of Five Key Technologies in PP-OCRv2:
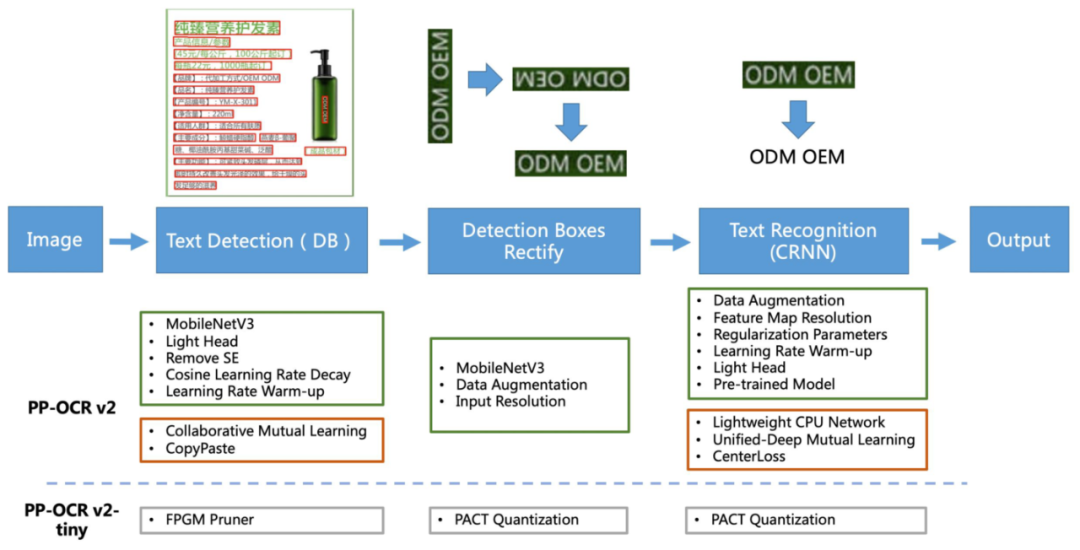
The newly upgraded PP-OCRv2 version maintains the same pipeline framework as PP-OCR, as shown in the diagram below.
In terms of optimization strategies, in-depth optimizations have been made from five angles (as shown in the red box in the above image), including:
-
Detection model optimization: adopting CML knowledge distillation strategy
-
Detection model optimization: CopyPaste data augmentation strategy
-
Recognition model optimization: LCNet lightweight backbone network
-
Recognition model optimization: UDML knowledge distillation strategy
-
Recognition model optimization: Enhanced CTC loss improvement
Let’s elaborate on the details:
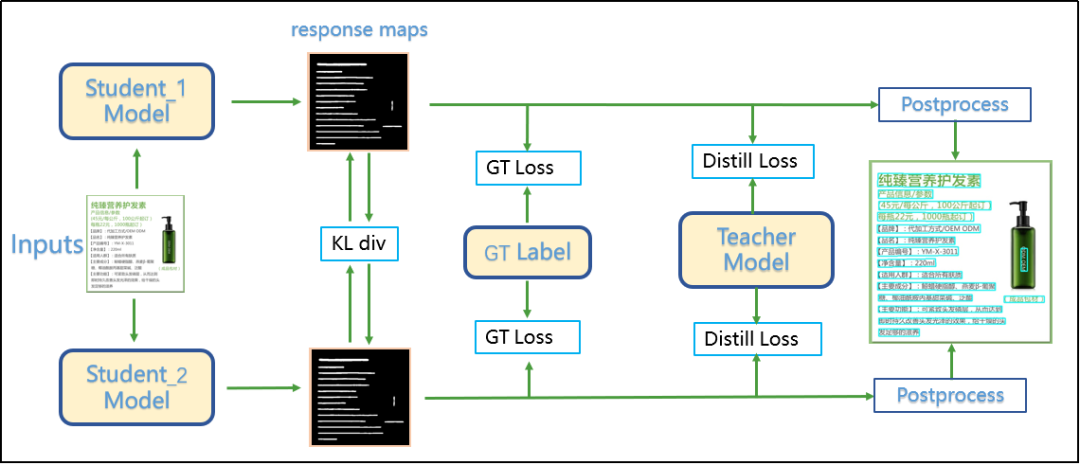
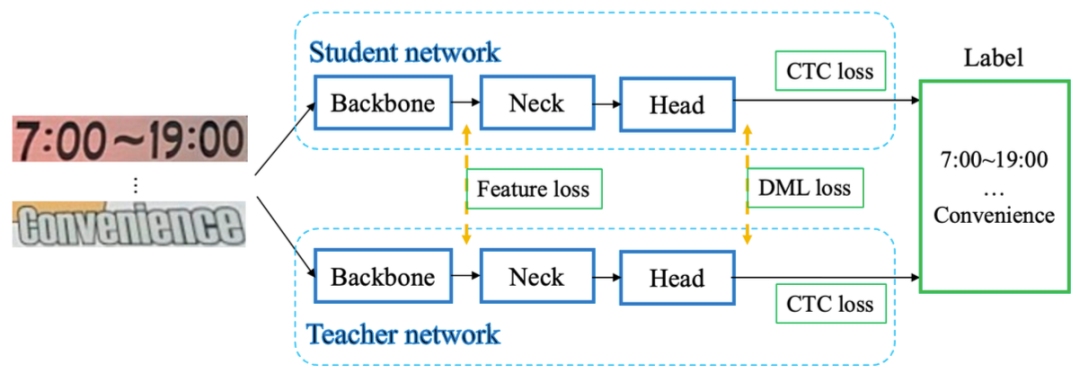
★ Detection Model Optimization: adopting the CML (Collaborative Mutual Learning) knowledge distillation strategy.
As shown in the above image, the core idea of CML combines ① traditional Teacher guiding Student standard distillation and ② Students networks directly learning from each other. This allows Students networks to learn from each other while being guided by the Teacher network. Correspondingly, three key loss functions are carefully designed: GT Loss, DML Loss, and Distill Loss, which have had a good improvement effect on the Student MobileNetV3 under the condition of the Teacher network Backbone being ResNet18.
★ Detection Model Optimization: CopyPaste data augmentation strategy
Data augmentation is one of the important means to improve the model’s generalization ability, and CopyPaste is a novel data augmentation technique that has been validated in object detection and instance segmentation tasks. By using CopyPaste, text instances can be synthesized to balance the ratio of positive and negative samples in training images. Compared to traditional image rotation, random flipping, and random cropping, this method achieves better results.
CopyPaste’s main steps include: ① randomly selecting two training images, ② randomly scaling, ③ randomly flipping horizontally, ④ randomly selecting a target subset from one image, and ⑤ pasting it at a random position in the other image. This greatly enhances sample richness and increases the model’s robustness to environmental variations.
After the optimizations in the above two detection directions, the experimental results of the PP-OCRv2 detection part are as follows:
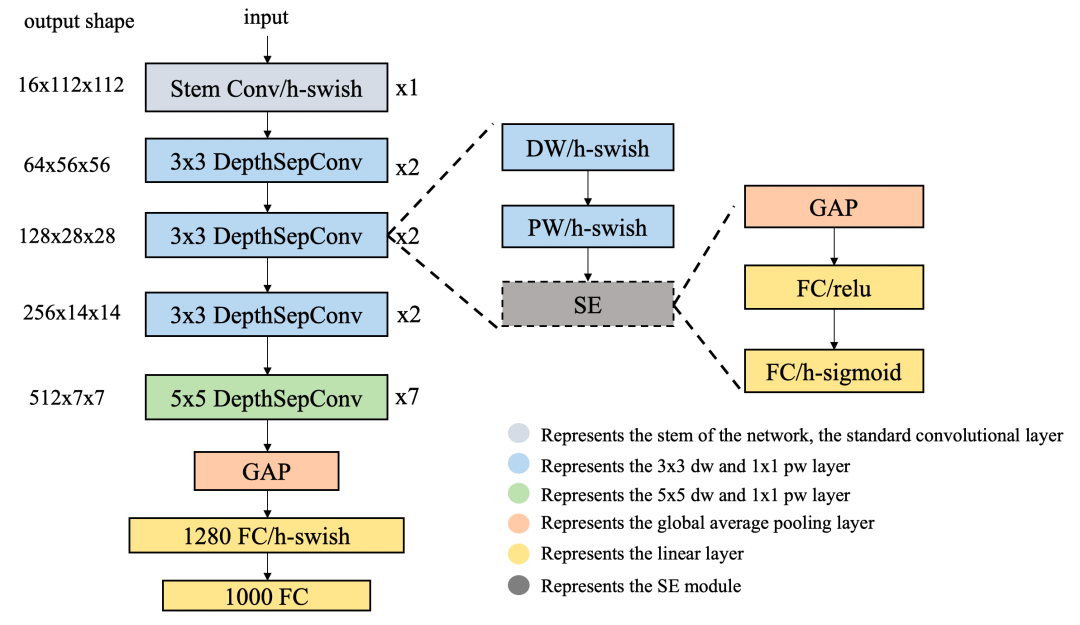
★ Recognition Model Optimization: LCNet lightweight backbone network
Here, the development team of PP-OCRv2 proposed a new backbone network LCNet based on improvements to MobileNetV1, with the main changes including:
① All relu in the network replaced with h-swish except for the SE module, leading to a 1%-2% accuracy improvement
② The kernel size of DW in the fifth stage changes to 5×5, improving accuracy by 0.5%-1%
③ The last two DepthSepConv blocks in the fifth stage added SE modules, improving accuracy by 0.5%-1%
④ Adding a 1280-dimensional FC layer after GAP to enhance feature representation capability, improving accuracy by 2%-3%
★ Recognition Model Optimization: UDML knowledge distillation strategy
Based on standard DML knowledge distillation, a supervision mechanism for Feature Map has been introduced, adding Feature Loss, increasing iteration counts, and adding an additional FC network in the Head part, ultimately speeding up the distillation process while enhancing performance.
★ Recognition Model Optimization: Enhanced CTC loss improvement
Considering that Chinese OCR tasks often face the challenge of similar characters leading to misrecognition, the idea of Metric Learning has been referenced to introduce Center Loss, further increasing inter-class distances, as shown in the formula in the above image.
After the optimizations in the three recognition directions above, the experimental results of the PP-OCRv2 recognition part are as follows:
After the five directions of optimization, PP-OCRv2 has comprehensively surpassed PP-OCR with only a slight increase in model size, achieving excellent results.
5. Conscientious Production of Chinese and English Documentation Tutorials
With the upgrade of PP-OCRv2, the project documentation of PaddleOCR has also been fully upgraded, with clearer structure and richer content,
No need to say much, just visit GitHub, star it and experience it yourself:
https://github.com/PaddlePaddle/PaddleOCR
On September 8th, from 20:15 to 21:30, a senior R&D engineer from Baidu will provide a detailed analysis of the greatly improved speed and accuracy of PaddleOCR. Everyone is welcome to scan the code to sign up for the live class and join the technical exchange group~


Official website: https://www.paddlepaddle.org.cn
PaddleOCR project address:
GitHub: https://github.com/PaddlePaddle/PaddleOCR
Gitee: https://gitee.com/paddlepaddle/PaddleOCR