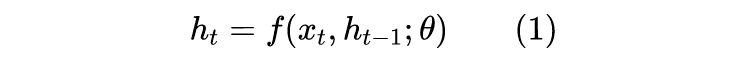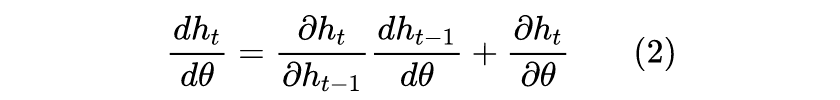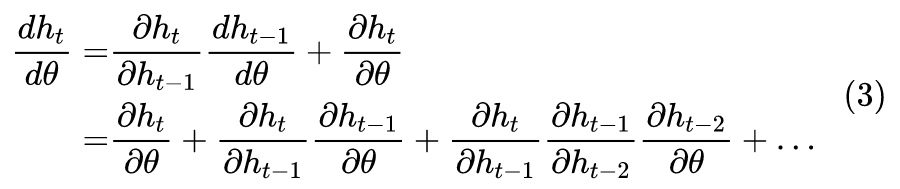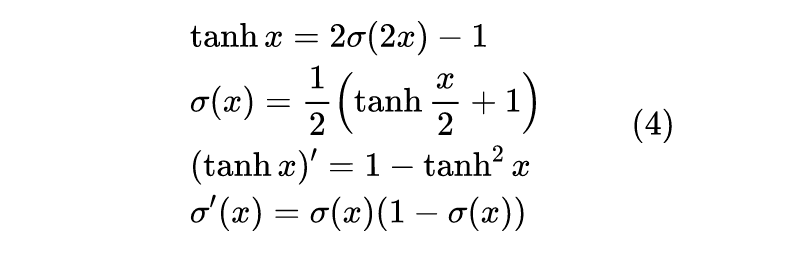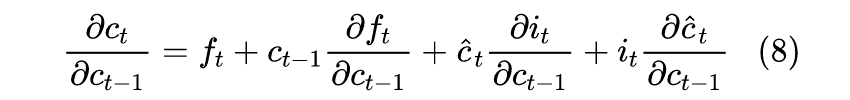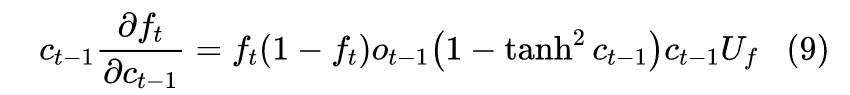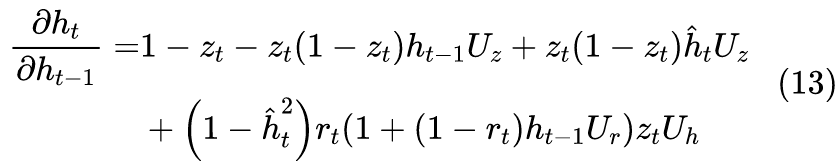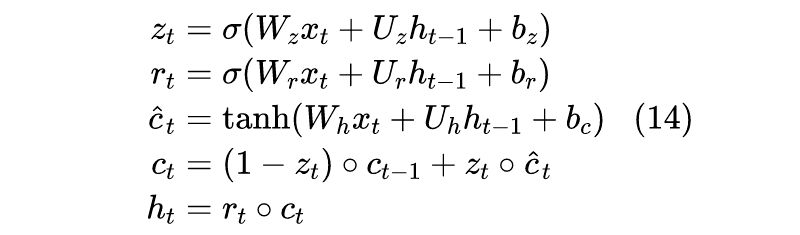Although Transformer models have conquered most fields in NLP, RNN models like LSTM and GRU still hold unique value in certain scenarios, making it worthwhile for us to study RNN models. The analysis of gradients in RNNs is an excellent example of thinking about model optimization, worthy of careful consideration. Notably, questions like “Why can LSTM solve the gradient vanishing/explosion problem?” remain popular interview topics today.
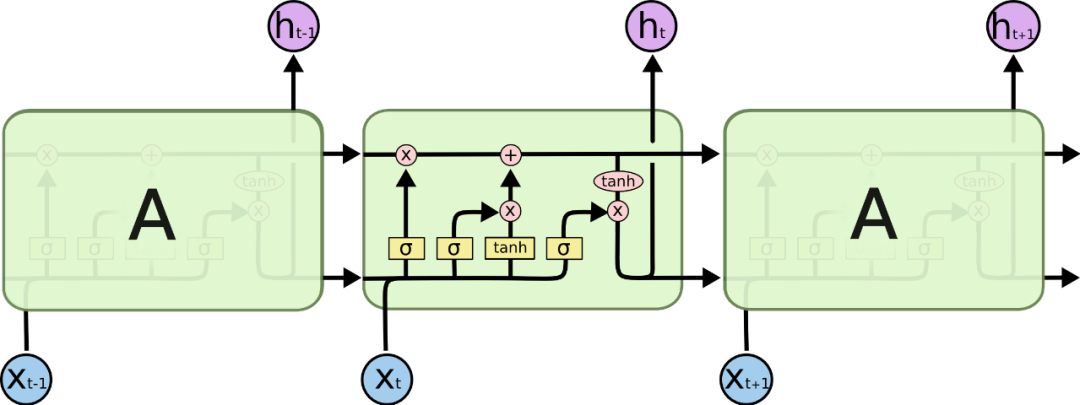
▲Classic LSTM
Many netizens have already answered such questions, but I found some articles (including several answers on Zhihu, columns, and classic English blogs) that did not provide satisfactory answers: some derivation notations are chaotic, and some explanations lack emphasis, making the overall understanding unclear and inconsistent. Therefore, I also attempt to provide my understanding for everyone’s reference.
RNN and Its Gradients
The unified definition of RNN is:
Where y_t is the output at each step, determined by the current input x_t and the output from the previous time step h_{t-1}, and W are the trainable parameters. When performing the most basic analysis, we can assume that y_t, x_t, and h_{t-1} are one-dimensional, which allows us to gain the most intuitive understanding, and the results still hold reference value for high-dimensional cases. The reason to consider gradients is that our mainstream optimizers are still gradient descent and its variants, thus we need our defined model to have a relatively reasonable gradient. We can derive:
It can be seen that the gradient of RNN is also an RNN, where the gradient at the current time step g_t is a function of the gradient from the previous time step g_{t-1} and the current operation gradient g_t. From the above equation, we can see that the phenomenon of gradient vanishing or explosion is almost inevitable:When W is less than 1, it means that the historical gradient information is decaying, thus after many steps, the gradient will inevitably vanish (like ); when W is greater than 1, it means that the historical gradient information is gradually enhancing, thus after many steps, the gradient will inevitably explode (like ). It is impossible for it to always be around 1, right? Of course, there may be some moments when it is greater than 1 and some moments when it is less than 1, eventually stabilizing around 1, but this probability is very small and requires a very sophisticated model design.Thus, after many steps, gradient vanishing or explosion is almost unavoidable; we can only alleviate this problem for a limited number of steps.
Vanishing or Explosion?
At this point, we have not clarified a question: what is the gradient vanishing/explosion of RNN? Gradient explosion is easy to understand; it means that the gradient values diverge, even becoming NaN; but does gradient vanishing mean that the gradient becomes zero? Not necessarily, as we mentioned, gradient vanishing occurs when W is always less than 1, and the historical gradients continuously decay, but it does not mean that the total gradient is zero. Specifically, if we iterate indefinitely, we have:
It is evident that as long as W is not zero, the probability of the total gradient being zero is very low; however, if we continue iterating, then the sparsity in front of this term is the product of the previous t-1 terms, and if their absolute values are all less than 1, the result will approach 0. In this case, there is almost no information containing the initial gradient.This is the meaning of gradient vanishing in RNN: the longer the distance from the current time step, the less significant the gradient signal that is fed back, potentially leading to complete ineffectiveness, which means that RNN loses its ability to capture long-distance semantics.In simple terms, if your optimization process is unrelated to long-distance feedback, how can you ensure that the learned model can effectively capture long distances?
A Few Mathematical Formulas
The above text is a general analysis, and next we will analyze RNN specifically. However, before that, we need to review a few mathematical formulas that we will frequently use in the subsequent derivations:
Where σ is the sigmoid function. These formulas essentially state that: σ and σ’ are essentially equivalent, and their derivatives can be expressed in terms of themselves.
Simple RNN Analysis
First up is the relatively primitive simple RNN (sometimes we directly refer to it as SimpleRNN), whose formula is:
Where W, U, b are the parameters to be optimized. At this point, a natural question arises: why use the activation function tanh instead of the more popular ReLU? This is a good question, and we will answer it shortly.From the above discussion, we already know that gradient vanishing or explosion mainly depends on W, so we calculate:
Since we cannot determine the range of U, W may be less than 1 or greater than 1, indicating the risk of gradient vanishing/explosion. Interestingly, if |U| is large, then W will be close to 1 or -1, which will reduce the risk. In fact, it can be strictly proven that if W is fixed, then W as a function of U is bounded, meaning that no matter what U equals, it does not exceed a fixed constant.Thus, we can answer why the activation function is tanh, because using tanh keeps the corresponding gradient W bounded; although this bound may not be 1, a bounded quantity is always more likely to be less than 1 than an unbounded quantity, thus reducing the risk of gradient explosion. In contrast, if ReLU is used, its derivative is always 1 in the positive half-axis, making it unbounded and increasing the risk of gradient explosion.Therefore, the main purpose of RNN using tanh instead of ReLU is to mitigate the risk of gradient explosion. Of course, this mitigation is relative; using tanh still carries the possibility of explosion. In fact, the fundamental method to handle gradient explosion is parameter clipping or gradient clipping, which means that I artificially clip U to [-1,1], thus ensuring that the gradient does not explode, right?Of course, some readers may ask, since clipping can solve the problem, can we use ReLU? Indeed, with a good initialization method and parameter/gradient clipping scheme, the ReLU version of RNN can also be trained well, but we still prefer to use tanh because it is bounded, so clipping does not need to be too aggressive, allowing for better model fitting.
Results of LSTM
Of course, while clipping can work, it is ultimately a last resort, and clipping can only solve the gradient explosion problem, not the gradient vanishing problem. If we can resolve this issue through model design, that would be best. The legendary LSTM is such a design; is this true? We will analyze it shortly.
The update formula for LSTM is relatively complex, which is:We can calculate as we did above, but it is easier to analyze g than h, so we will proceed in this direction.Similarly, we will first only consider the one-dimensional case; at this point, based on the derivative formula, we have:
The first term on the right, which we refer to as the “forget gate”, will generally be the dominant term, while the other three terms are secondary. Since g is between 0 and 1, it indicates that the risk of gradient explosion will be very small. As for whether it will vanish, it depends on whether g is close to 1.Coincidentally, we have a rather self-consistent conclusion: if our task relies heavily on historical information, then g will be close to 1, meaning that historical gradient information is also less likely to vanish; if g is close to 0, it indicates that our task does not rely on historical information, and thus gradient vanishing is not an issue.So, the key now is whether the conclusion that “the other three terms are secondary” holds. The latter three terms are of the form “one term multiplied by another term’s partial derivative”, and the terms being differentiated are either g or σ activations. As mentioned when reviewing the mathematical formulas, g and σ are essentially equivalent, so the latter three terms are similar; analyzing one of them is equivalent to analyzing the other two. For example, in the second term, substituting g yields:
Note that g is between 0 and 1, and it can also be proven that g is between -1 and 1. Thus, g acts similarly to a gate, unlike LSTM, where it theoretically could diverge. Understanding this, we can now differentiate:
In fact, the result is similar to LSTM; the dominant term should be g, but the remaining terms have one less gate than those corresponding to LSTM, so their magnitudes might be larger. Overall, it feels like GRU might be less stable compared to LSTM and more dependent on good initialization methods.In light of the above analysis, I personally believe that if we adopt GRU’s idea while needing to simplify LSTM and maintain LSTM’s friendliness to gradients, a better approach would be to place g at the end:
Of course, this requires caching an additional variable, which brings extra memory consumption.Article Summary OverviewThis article discussed the gradient vanishing/explosion problem in RNNs, primarily analyzing the gradient flow of RNN, LSTM, and GRU models based on the boundedness of gradient functions and the number of gates, to determine the risk of gradient vanishing/explosion. This article is a self-contained work; if there are any errors or omissions, I hope readers can forgive and correct them.
Download 1: Four-piece Set
Reply "Four-piece Set" in the backend of the Machine Learning Algorithms and Natural Language Processing public account to obtain the learning materials for TensorFlow, Pytorch, Machine Learning, and Deep Learning!
Download 2: Repository Address Sharing
Reply "Code" in the backend of the Machine Learning Algorithms and Natural Language Processing public account to obtain 195 NAACL + 295 ACL2019 papers with open-source code. The open-source address is as follows: https://github.com/yizhen20133868/NLP-Conferences-Code
Heavyweight! The Machine Learning Algorithms and Natural Language Processing exchange group has been officially established! There are plenty of resources in the group; everyone is welcome to join and learn!
Extra gifts! Resources on Deep Learning and Neural Networks, official Chinese tutorials for Pytorch, data analysis using Python, machine learning notes, official Chinese documentation for pandas, effective java (Chinese version), and 20 other welfare resources.
How to obtain: After entering the group, click on the group announcement to get the download link. Please modify your remarks when adding as [School/Company + Name + Direction]. For example —— Harbin Institute of Technology + Zhang San + Dialogue System. The account owner and WeChat merchants please consciously avoid this. Thank you!
Recommended Reading:
12 Golden Rules for Solving NER Problems in Industry
Three Steps to Master the Core of Machine Learning: Matrix Derivatives
Distillation Techniques in Neural Networks, Starting with Softmax


 ▲Classic LSTM
▲Classic LSTM