By Jiao Fa from Aofeisi Quantum Bit Report | WeChat Official Account QbitAI
This tutorial is written for beginners in machine learning and will introduce what a Recurrent Neural Network (RNN) is.
Recurrent Neural Networks are specifically designed to handle sequences. Due to their effectiveness in processing text, they are often used in Natural Language Processing (NLP) tasks.
As mentioned before, the author is Victor Zhou.
What is the Use of RNN?
Traditional neural networks, as well as CNNs, have a problem: they only work with a predetermined size.
In simpler terms, they take fixed-size inputs and produce fixed-size outputs.
For example, in the CNN example mentioned earlier, a 4×4 image is input, resulting in a 2×2 output image.
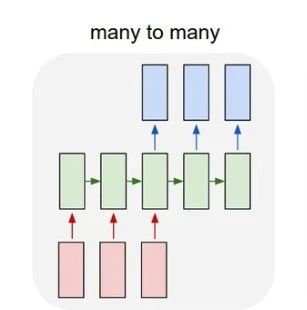
But RNNs? They focus on processing text, where the length of inputs and outputs can vary, such as one-to-one, one-to-many, many-to-one, or many-to-many.
Look at this diagram, and you should understand.
Here, the input is red, the RNN itself is green, and the output is blue.
This ability to process sequences is very useful, leading to a rich variety of applications for RNNs.
For example, machine translation.
As you may have seen, services like Google Translate, Baidu Translate, and the recently popular DeepL Translator all perform “many-to-many” translations.
The original text sequence is fed into the RNN, and then the RNN generates the translated text as output.
Another example is sentiment analysis.
This typically uses “many-to-one” RNNs. You input the text you want to analyze into the RNN, which then produces a single output classification.
For instance: analyzing whether a review is positive or negative.
The output could be: This is a positive review.
How to Implement RNN?
Let’s consider a “many-to-many” RNN, where the input is x0, x1, x2… xn, and the output is y0, y1, y2… yn. Each xi, yi is a vector with arbitrary dimensions.
The RNN works by iteratively updating a hidden state h, which can be a vector of arbitrary dimensions.
For any given ht:
1. It is calculated from the corresponding input xt and the previous hidden layer ht-1. 2. The output yt is derived from ht.
This way, the output from the previous step is carried over to the next hidden layer, training together. Doesn’t this feel like a cycle?
Each step uses the same weights, and typically, a standard RNN only requires 3 sets of weights to perform its calculations.
Additionally, two biases are also needed.
Thus, these 3 weights and 2 biases complete the entire RNN calculation.
Putting them together, the equation is as follows.
Note that here, the weights are matrices, while other variables are vectors!
The first equation here uses the hyperbolic tangent as the activation function, but using the sigmoid function mentioned earlier is also acceptable.
Is the Text Affirmative or Negative?
Next, let’s try to execute an RNN from scratch.
For a simple sentiment analysis example, we will determine whether a given text string expresses an affirmative or negative sentiment.
For instance, using these datasets.
From this table, we can see that we will use a “many-to-one” RNN type.
Each input x will be a vector representing a word in the text.
The output y will be a vector containing two numbers, one representing positive and the other representing negative, then applying Softmax to convert these values into probabilities, ultimately determining positive or negative.
Preprocessing
First, we need to do some preprocessing—converting the dataset into a usable format. Since RNNs cannot yet recognize words, we need to build a vocabulary of all the words and assign them numbers.
In the vocabulary, if there are 18 words, that means each word is an x, making the input an 18-dimensional vector.
Training the RNN
Next, we will begin with the 3 weights and 2 biases required for the original RNN.
This is the formula we saw earlier.
Like training a CNN, training an RNN first requires a loss function.
We will use cross-entropy loss combined with Softmax:
(where c represents a text label, e.g., correct)
For example, if a positive text test shows a 90% probability of being positive, then its loss function is:
After calculating the loss function, we need to use gradient descent training to minimize the loss.
Next, we involve multivariable calculus, with the calculation thinking being similar to before, just with different specific formulas. For details, click the link below.
After training, don’t forget to conduct a test!
Well, that’s all for today’s introduction to RNNs.
Links
https://victorzhou.com/blog/intro-to-rnns/
The author is a signed author of NetEase News · NetEase Account “Each Has Its Attitude”
— End —
Huawei MindSpore Evangelist Recruitment
Help Beginners Become Experts
Say goodbye to technical idolization, respect every developer.
Grow rapidly together in the open-source community and build an open-source ecosystem!
Scan the QR code below to sign up!


Quantum BitQbitAI · Signed Author on Toutiao
Tracking new trends in AI technology and products
If you like it, click “Looking”!