Click on the above“Beginner Learning Vision” to choose to add a Star or “Top”
Important content delivered first
Source | Zhihu Author | Huang PiaoLink | https://zhuanlan.zhihu.com/p/113443895This article is for academic exchange only. If there is any infringement, please contact for deletion. IntroductionRecently, I came across several interesting articles and referred to some related discussions. Here, I want to explore the invariance and equivalence of translation and scale in CNNs, as well as the principles of CNNs in predicting the relative and absolute positions and depth of objects. This content is crucial for certain tasks, such as object detection, segmentation, depth estimation, classification/recognition, and confidence map prediction in single-object tracking.
1 Does CNN Have Invariance and Equivalence of Translation and Scale?
1.1 Definitions of Invariance and Equivalence
Before introducing Convolutional Neural Networks (CNN), our understanding of invariance and equivalence may come from traditional image processing algorithms, such as invariance to translation, rotation, illumination, and scale. For example, HOG (Histogram of Oriented Gradients) has some invariance to translation and rotation due to the existence of <span>cells</span>, and also has some invariance to illumination due to local contrast normalization. Similarly, SIFT (Scale-Invariant Feature Transform) has invariance to all four points mentioned above, including scale invariance due to the scale pyramid. Our understanding of invariance here is that when the same object undergoes translation, rotation, illumination changes, scale transformations, or even deformation, its properties should remain consistent. Below we provide specific definitions of invariance and equivalence.The definition of invariance is as mentioned above, so its form is: As for equivalence, it means that after transforming the input, the output also undergoes the corresponding transformation: However, if we only consider the invariance and equivalence of the output concerning the input, it can be difficult to understand, as we often imagine the mapping at the feature level, such as:We might consider the influence of the feature level on the output less, but it does exist. For example, the translation and scale transformations of an object in an image must enable the network to maintain relevant transformation equivalence to capture the position and shape changes of the object. In tasks like image classification, object recognition, and person re-identification, the network must exhibit relevant transformation invariance. These two points represent a classic contradiction in the field of object detection and person retrieval, which currently lacks a particularly good solution. More often, different tasks are executed in stages to prevent feature sharing. For instance, in classic two-stage object detection tasks, the first stage involves coarse detection and foreground-background classification, while the second stage focuses on refinement and specific category classification, with a certain emphasis. Most person retrieval algorithms follow the strategy of detecting first and then recognizing. In addition to the issues of invariance and equivalence, there are also intra-class variation problems. For example, different individuals belong to the pedestrian category for detection but are recognized as different persons, which poses challenges for feature extraction.
1.2 Execution Process of CNN
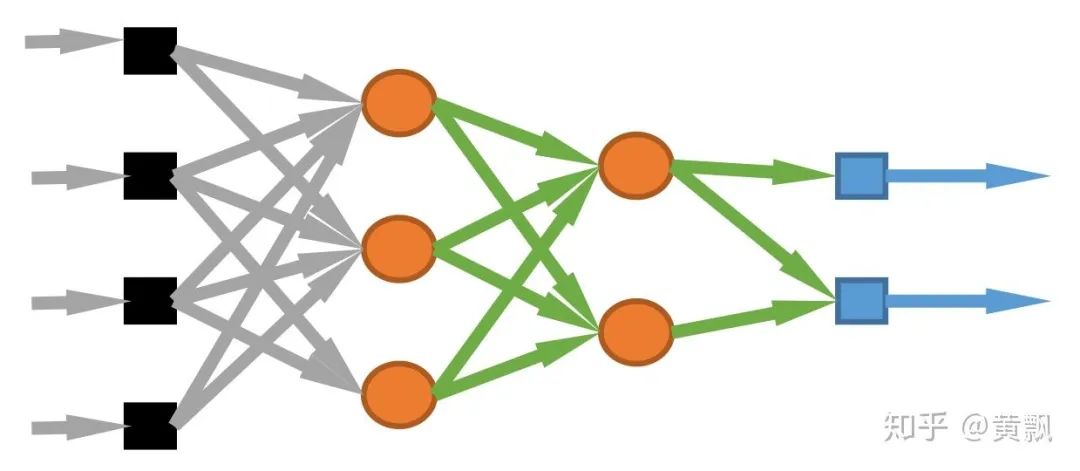
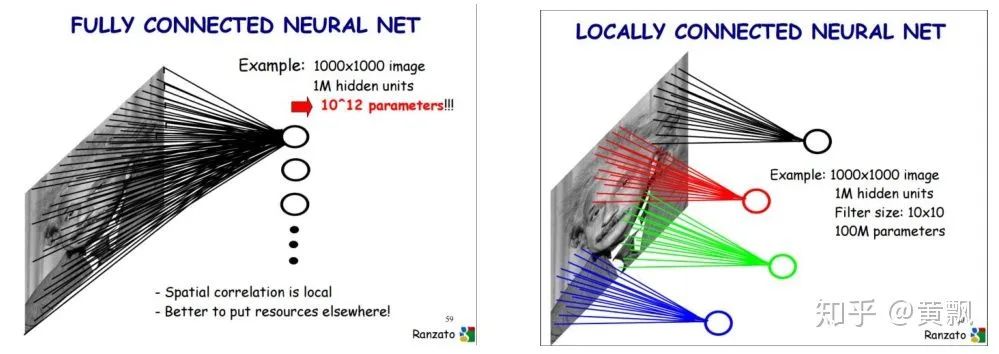
I remember when I first encountered deep learning a few years ago, there were claims about invariance and equivalence in fully connected networks and the local connection form of CNN. In fully connected networks, each node in the next layer connects to every node in the previous layer:Therefore, regardless of whether the input undergoes translation, scale, or any other transformation, as long as its properties remain unchanged, the fully connected network can capture the invariance. For convolutional neural networks, we know two key features: local connections and weight sharing.Due to local connections, fully connected parameters are too numerous, leading to overfitting, and in the image domain, more attention is paid to local detail information, making local connection methods effective. Weight sharing also reduces parameters and is similar to filters in image processing. Our early understanding of its invariance was more of a macro perception; that due to the convolution kernel’s shifting filter, the relative positions of features from the previous layer to the next layer remain macro-invariant until the final output, similar to the effect of fully connected layers, thus achieving invariance.
1.3 Potential Issues and Improvements in CNNs
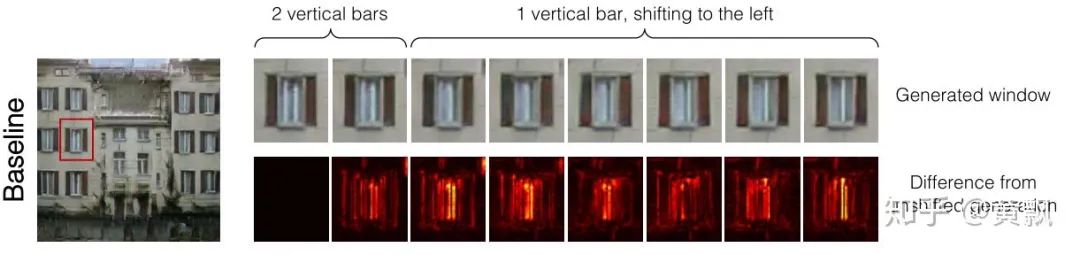
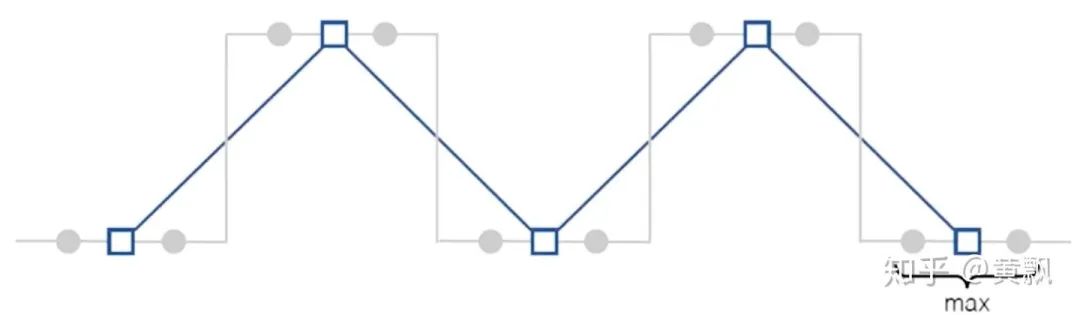
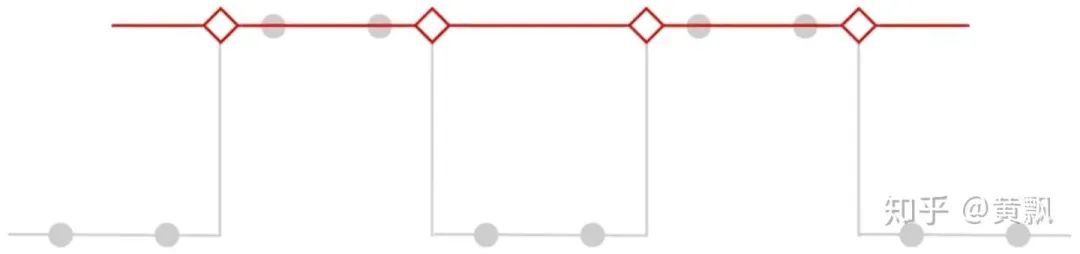
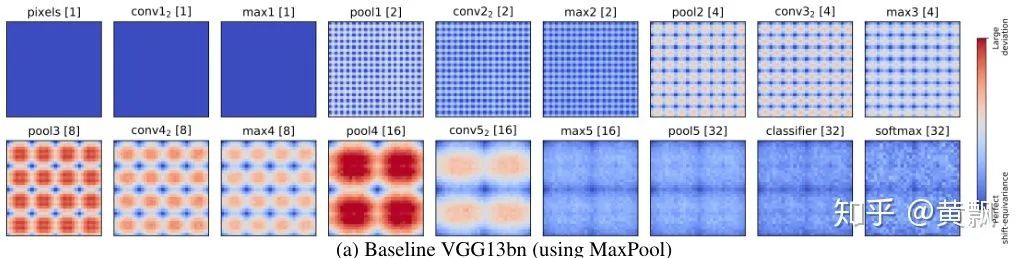
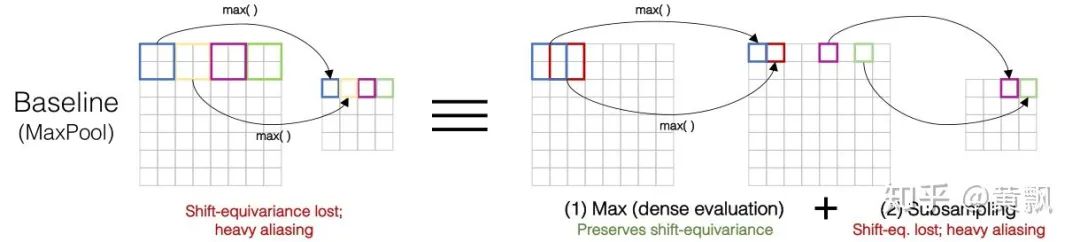
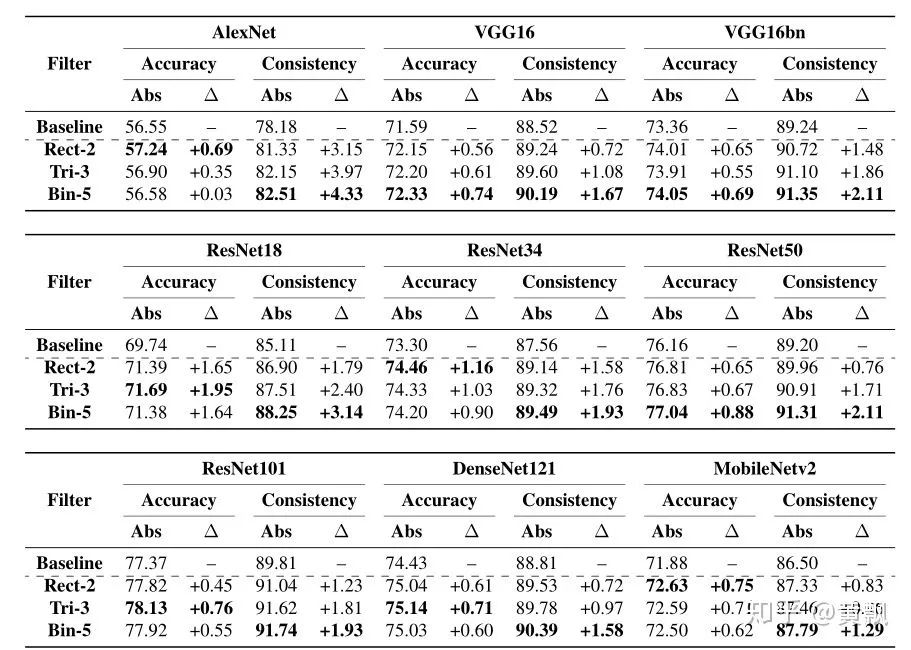
Because of the aforementioned macro-invariance, inputs undergo multiple convolutions and pooling, resulting in the accumulation of micro/detail changes, thus losing this invariance. Next, I will introduce two papers on this topic.The first is an ICML 2019 paper titled “Making Convolutional Networks Shift-Invariant Again”, which mainly discusses the impact of downsampling in CNNs on translation invariance:The above image shows the feature maps of a window with translation amounts from 0 to 7, and we can clearly see fluctuations in the feature maps. Correspondingly, the upper part uses images generated by pix2pix, and we can see that as the translation amount increases, the vertical line in the window changes from two lines to one. This indicates that traditional CNNs do not possess translation invariance.Firstly, the authors conducted a small experiment using max pooling on a one-dimensional vector [0011001100] to obtain the vector [01010]:Next, if the input is shifted one unit to the right, the vector becomes [111111]:Clearly, both translation equivalence and invariance are lost. The authors conducted further experiments using cosine distance to characterize translation equivalence, testing the VGG network on the Cifar dataset:Where deeper colors indicate greater differences, it can be seen that each max pooling operation increases feature differences. However, the authors separated the max and pool operations to distinguish the effects of taking the maximum value and downsampling:It is clear that downsampling has a greater impact on translation equivalence, and operations involving downsampling in CNNs include pooling (max pooling and average pooling) and strided convolution. The authors proposed a method called Anti_aliasing, which involves anti-aliasing techniques from traditional signal processing. In general, anti-aliasing techniques either increase the sampling frequency, which is not suitable for image processing tasks that often require downsampling, or use image blurring techniques. According to Nyquist sampling theory, this is done by lowering the original signal’s frequency to allow for reconstruction, as shown in the following image. The two images at the bottom show the results of downsampling the original image, with the blurred original image still showing some contours, while the unprocessed original image appears more chaotic.The authors adopted the blurring method and proposed three different blur kernels:
Rectangle-2: [1, 1], similar to mean pooling and nearest neighbor interpolation;
Triangle-2: [1, 2, 1], similar to bilinear interpolation;
Binomial-5: [1, 4, 6, 4, 1], used in Laplacian pyramids.
Each kernel needs to be normalized by dividing by the sum of all elements in the kernel and then added to the downsampling process, i.e., using the blur kernel for convolution filtering before downsampling:The results are quite impressive:Code and models can be found at:https://richzhang.github.io/antialiased-cnns orhttps://github.com/adobe/antialiased-cnnsThe second paper is from the same year published in JMLR titled “Why do deep convolutional networks generalize so poorly to small image transformations?” The authors first provided several examples representing the impact of translation, scale, and slight image differences on the classification confidence of the network:The authors believe that CNNs overlook the sampling theorem, which was previously verified by Simoncelli et al. in the paper Shiftable multiscale transforms, where they stated:We cannot simply hope for translation invariance in the system based on convolutions and secondary sampling; the translation of input signals does not imply a simple translation of transformation coefficients unless the translation is a multiple of each secondary sampling factor.In our existing network frameworks, the deeper the network, the more downsampling occurs, and thus more problems arise. The authors then made several points:
If is a feature obtained through convolution that satisfies translation invariance, then the global pooling operation also satisfies translation invariance;
For the feature extractor and downsampling factor , if the translation of the input can be reflected in the output through linear interpolation:According to the Shannon-Nyquist theorem, satisfies shiftability, ensuring that the sampling frequency is at least twice the highest signal frequency.
Next, the authors made some attempts to improve these issues:
Anti-aliasing, which is the method we just introduced;
Data augmentation, which is currently used in many image tasks, where we typically employ techniques such as random cropping, multi-scale, and color jittering for data augmentation, which indeed helps the network learn some invariance;
Reducing downsampling, meaning relying solely on convolution to reduce the input scale, which is only applicable to small images due to high computational costs.
2 CNNs in Predicting Position and Depth Information
2.1 How CNNs Obtain Object Position Information
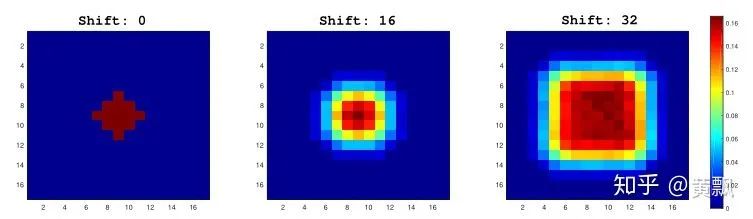
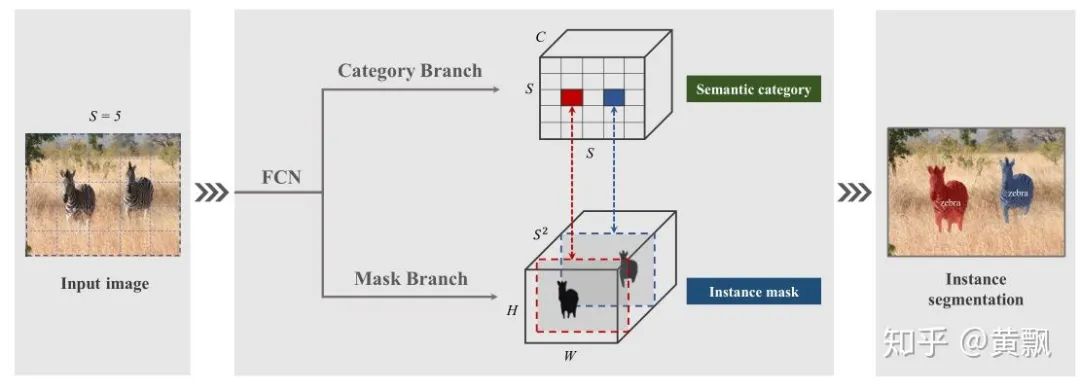
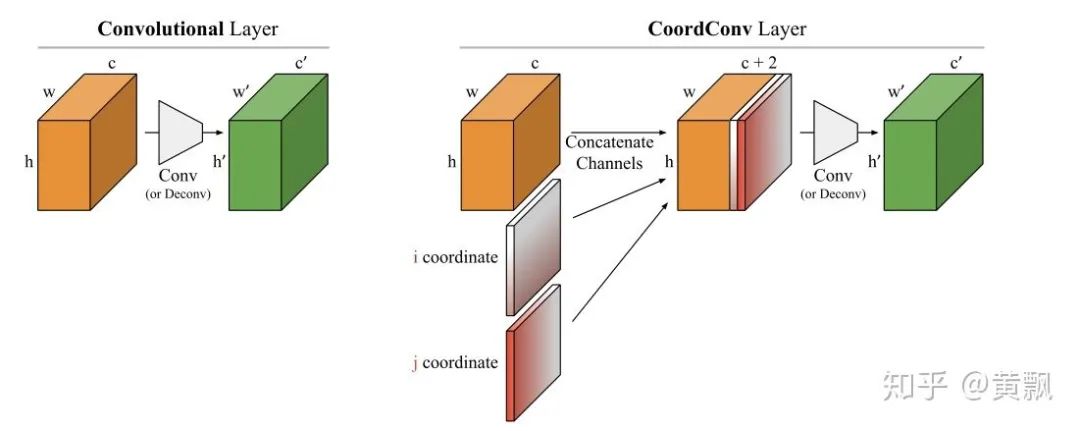
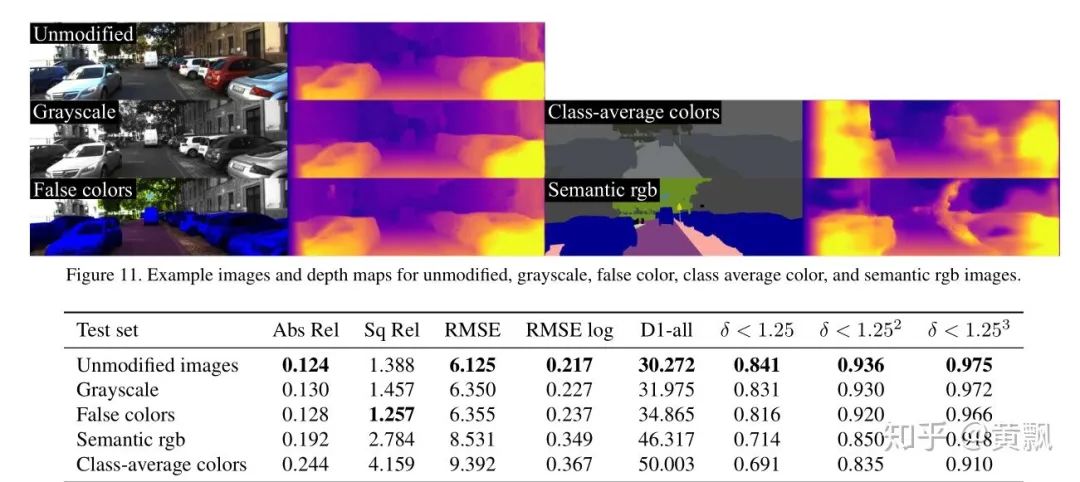
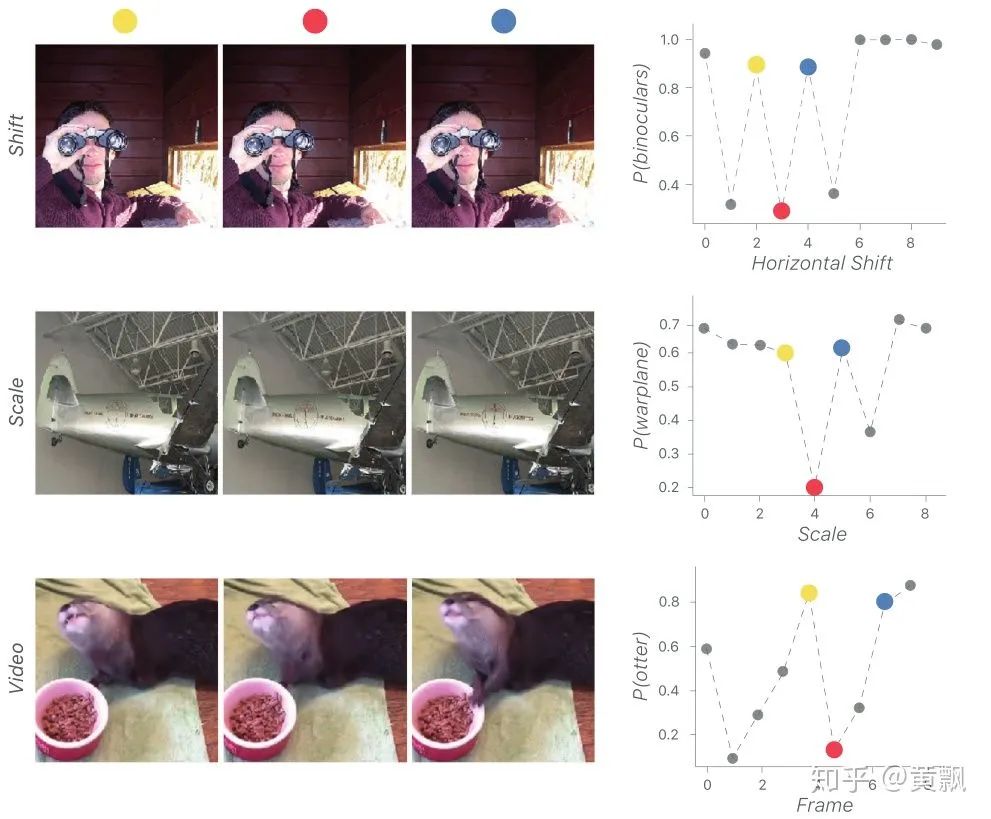
When I first encountered neural networks and deep learning-related tasks, my impression was that these algorithms essentially perform classification tasks, such as image segmentation, which classifies foreground and background as well as specific categories, and recognition tasks distinguish between classes and instances. The image segmentation task utilizes some equivalence from CNNs, so how does the position regression of objects in object detection tasks obtain its information? We know that searching for object positions in single-object tracking tasks involves confidence maps:However, the confidence map is essentially derived from searching regions, which can be approximated as a recognition process of multiple sub-regions. Therefore, the object localization in single-object tracking can also be understood through classification, but object detection cannot be easily understood this way.Next, let’s consider a question: what information do the networks we design actually contain? Image features, network structure (kernel size, padding). From the previous chapter, we know that the network can learn a certain equivalence:Thus, through continuous training, the network can estimate the scale of the target based on the corresponding feature values and area sizes in the final feature output, combined with a certain multiple (downsampling size). However, regarding the position of the target, our human perception of the target’s position is based on a coordinate system, i.e., the distance from the target to the edge of the image. But how does the network understand this information? The article “How much Position Information Do Convolutional Neural Networks Encode?” provides an answer.The authors first conducted a series of experiments:For different input images, various mask perturbations were applied, with H, V, and G representing horizontal, vertical, and Gaussian distributions, respectively, generating multiple ground truths. We might be familiar with Gaussian distributions centered around the target in single-object tracking. The results showed:GT represents the ground truth generated by the three distributions, and PosENet is the network proposed by the authors without padding. We can see that PosENet did not obtain position distribution information but maintained equivalence. In contrast, VGG and ResNet with padding predicted position distributions. This indicates the role of padding in position prediction and supplements the content from the previous chapter, showing that padding also impacts translation invariance and equivalence.However, this may be difficult to understand. I conducted a small test, but it may not be exactly how it was done; it merely helps my understanding:The above shows the convolution results of two different position “targets.” It can be seen that little position reflection can be obtained from the output results. If padding is added:Firstly, we can see that with zero-padding added, the output for the target edges relative to the center has decreased. Secondly, the farther the target is from the image edge, the more zeros appear in the feature mapping. Therefore, I guess that during training, the network corresponds padding with this relative relationship. If there is no padding, the farther the target is from the edge, the more zeros would appear, but the issue lies in the inability to compare this with the special distribution caused by padding, where edge values are small and center values are large. Of course, the above is just my personal understanding to help deepen my impression. Some also say that adding padding affects the translation equivalence of CNNs, allowing them to learn position information, but this is not easy to explain.Regarding padding issues, a single-object tracking algorithm, SiamRPN++, also discussed this at CVPR 2019. Its starting point was why Siamese networks cannot scale to larger networks, which is due to padding affecting translation equivalence, causing the target position distribution to shift. Therefore, the authors introduced random perturbations to the target center to help the network overcome its own bias:Some studies have also explored how CNNs can incorporate absolute position information. A well-known example is the current popular SOLO single-stage instance segmentation algorithm. The premise of SOLO is simple; we know that semantic segmentation only needs to segment different categories of objects, while instance segmentation requires distinguishing individuals of the same category. However, it is evident that as long as the positions and shapes of objects differ, they can be distinguished. Therefore, SOLO incorporates position and shape (simplified by size) information. Specifically, it uniformly divides the input system’s image into an S x S grid, and if the object’s center falls into a grid cell, that grid cell is responsible for predicting the semantic category and segmenting that object instance.In particular, the SOLO algorithm employs the CoordConv strategy (code: github.com/uber-researc), which incorporates the coordinate information of each feature area, allowing the network to explicitly learn the absolute position information of features. SOLO achieved a 3.6 AP improvement with this strategy, demonstrating that only one layer providing this information is sufficient for stable enhancement.
2.2 How CNNs Predict Object Depth Information
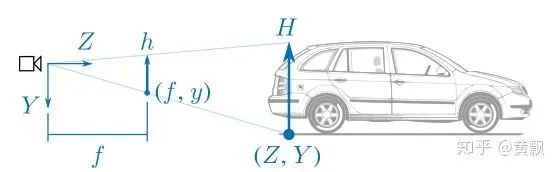
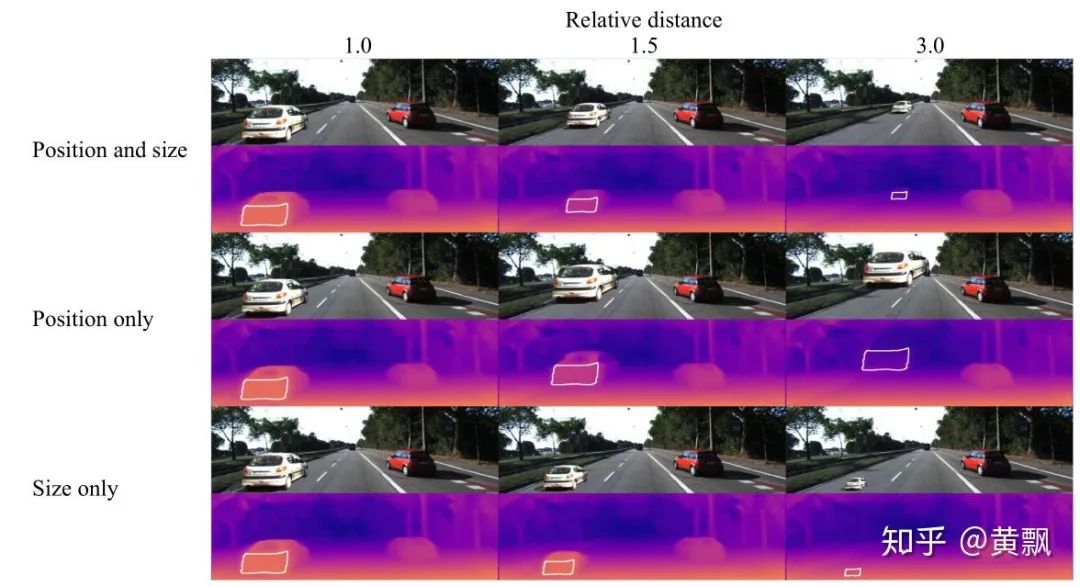
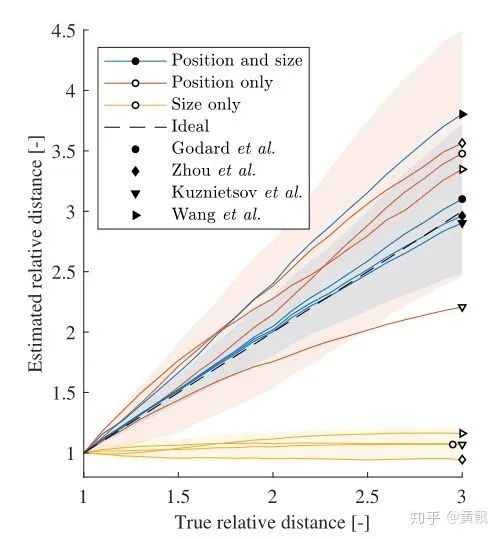
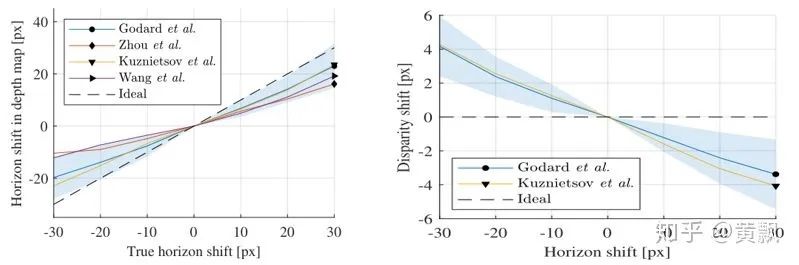
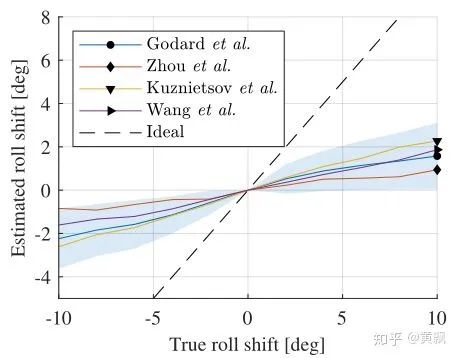
Depth estimation is a similar issue, but the difference is that the image does not contain depth information. So how does the network obtain depth information? The article “How Do Neural Networks See Depth in Single Images?” provides an answer. Teacher Naiyan Wang has discussed this article in his blog, so I will summarize it here.We can see that the absolute depth of an object is greatly related to the camera pose. So how do CNNs learn this geometrically prior absolute information? The authors conducted three sets of experiments:In the above image, the authors varied both the target position and size simultaneously, only changed position, and only changed size. From the qualitative results above, it seems there are no issues, but below are the quantitative results:It can be found that scale has no impact on depth information prediction, meaning that CNN networks estimate depth based on the vertical coordinates of the target. Thus, the network is actually overfitting the training set, learning some fixed scene depth and relative position relationships.The authors also discussed the impact of camera motion on depth prediction. Since depth relates to the vertical coordinates of the target, the pitch angle should have a significant impact:It can be seen that pitch indeed has a significant impact, while the effect of roll is relatively small:Finally, the authors discussed the impact of color and texture on depth estimation:It can be seen that merely changing the color and texture of the target also decreases depth estimation performance, which shows how much the CNN network ‘takes shortcuts’ during training. I wonder if turning the above experiments into data augmentation methods would make the depth estimation network ineffective or stronger.
Updated on 2020.3.18
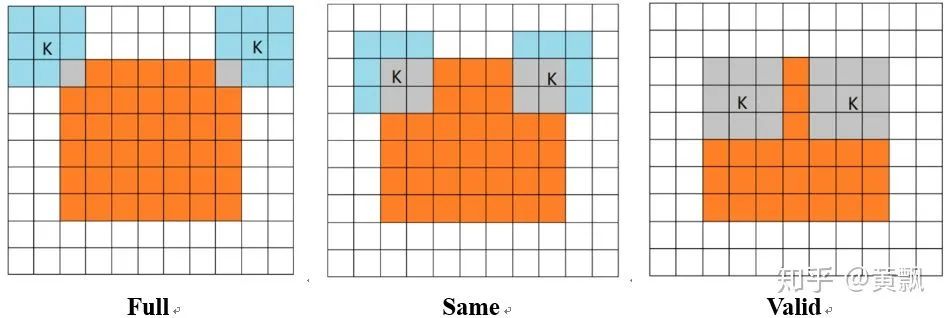
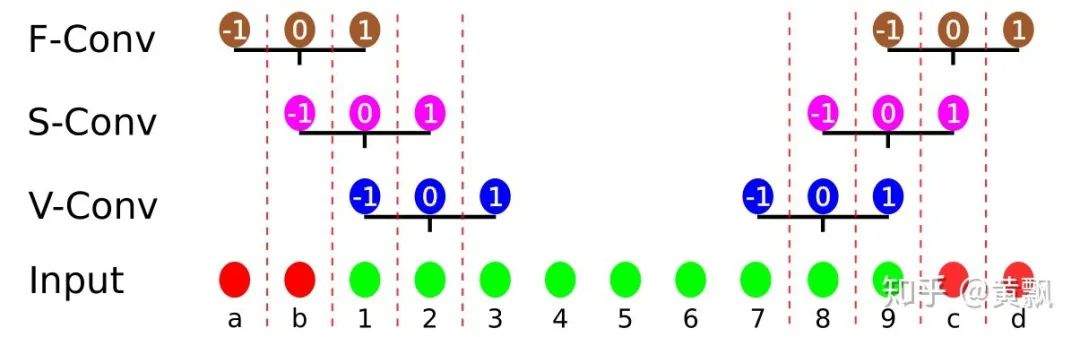
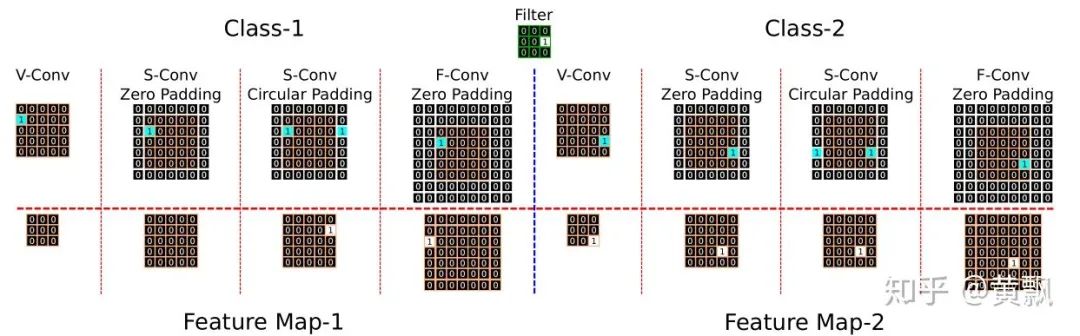
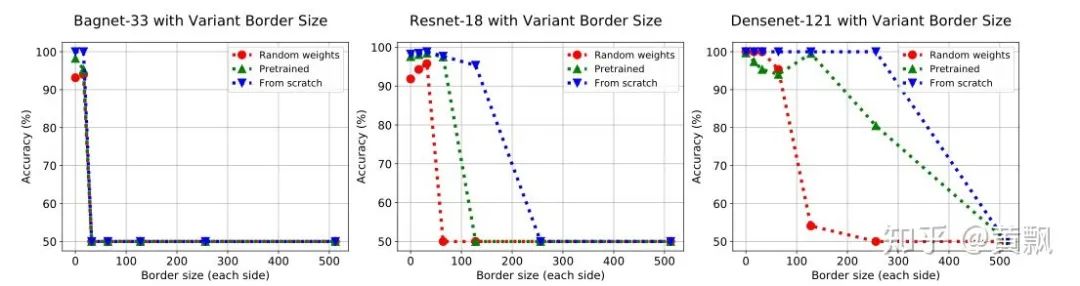
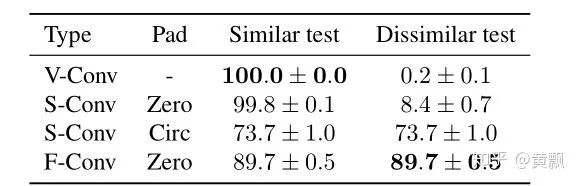
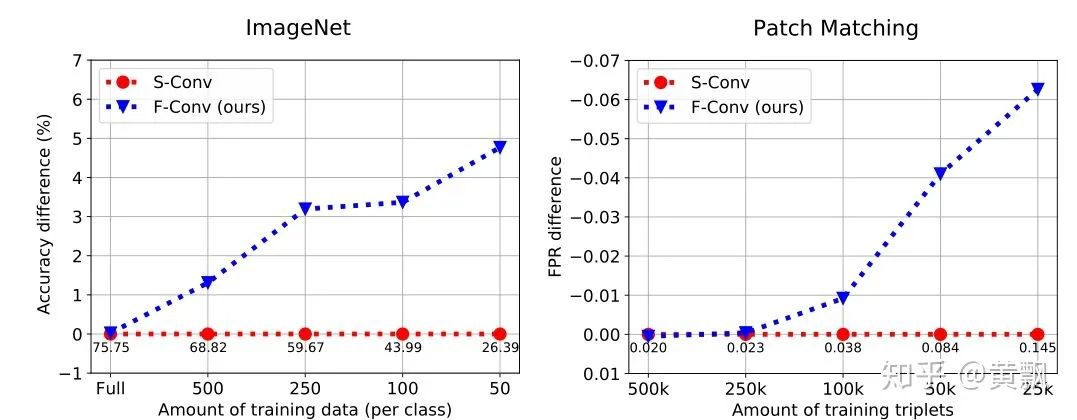
Yesterday, I happened to see a CVPR 2020 paper titled “On Translation Invariance in CNNs: Convolutional Layers can Exploit Absolute Spatial Location”, which also mentioned the issues of translation invariance and absolute position encoding in CNNs, focusing on the boundary issues in CNNs.The authors first used three convolution methods as examples: full/same/valid, each differing in padding size. I won’t elaborate further, just provide a schematic:In these images, the red areas indicate padding, and the green areas represent boundary regions. Clearly, the <span>valid</span> mode’s convolution kernel’s far-right <span>1</span> can never act upon the green area’s <span>1</span>, and the <span>same</span> mode’s convolution kernel’s far-right <span>1</span> can never act upon the green area’s <span>1</span>. The authors provided an example illustrating the differences between zero-padding and circular-padding:It can be seen that in Class-1, the first two examples did not detect <span>1</span>. The <span>valid</span> and <span>same+zero-padding</span> modes are sensitive to the absolute position of the convolution area. Subsequently, the authors analyzed how many times each position was convolved:This leads to the question of how far from the image boundary a fixed pixel can be detected. The authors conducted experiments by adding black borders of varying sizes around the images:Interestingly, after adding black borders, the classification accuracy dropped significantly, although different training strategies and different backbones exhibited varying resistance to interference.To quantitatively analyze the differences in handling boundaries among various convolution strategies, a classification dataset was created, with special points distributed at the boundaries:The results showed significant differences:It can be seen that, as observed previously, the first two strategies had poor generalization capabilities, while the Circular padding and full convolution modes performed the best. Subsequently, to reduce the impact of boundaries, the authors employed the blur pooling + Tri3 convolution kernel mentioned earlier regarding convolution translation invariance. They compared the robustness of S-conv + circular padding and F-conv strategies against different diagonal translations of images:The results showed that the Full conv mode performed better. Subsequent experiments also indicated that it helps reduce overfitting risk, being more effective for small datasets.The code will be open-sourced soon: github.com/oskyhn/CNNs-Without-Borders
Good news!
Beginner Learning Vision knowledge circle is now open to the public👇👇👇
Download 1: OpenCV-Contrib Extension Module Chinese Version Tutorial
Reply "Extension Module Chinese Tutorial" in the "Beginner Learning Vision" WeChat public account to download the first OpenCV extension module tutorial in Chinese, covering installation, SFM algorithms, stereo vision, object tracking, biological vision, super-resolution processing, and more than twenty chapters of content.
Download 2: Python Vision Practical Projects 52 Lectures
Reply "Python Vision Practical Projects" in the "Beginner Learning Vision" WeChat public account to download 31 practical vision projects, including image segmentation, mask detection, lane line detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, face recognition, etc., to help quickly learn computer vision.
Download 3: OpenCV Practical Projects 20 Lectures
Reply "OpenCV Practical Projects 20 Lectures" in the "Beginner Learning Vision" WeChat public account to download 20 practical projects based on OpenCV for advanced learning of OpenCV.
Community Group
Welcome to join the reader group of the public account to exchange with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (which will gradually be subdivided in the future). Please scan the WeChat number below to join the group, noting: "Nickname + School/Company + Research Direction", for example: "Zhang San + Shanghai Jiao Tong University + Vision SLAM". Please follow the format when noting, otherwise, it will not be approved. After successful addition, you will be invited to the relevant WeChat group based on your research direction. Please do not send advertisements in the group, otherwise, you will be removed. Thank you for your understanding~


 As for equivalence, it means that after transforming the input, the output also undergoes the corresponding transformation:
As for equivalence, it means that after transforming the input, the output also undergoes the corresponding transformation: However, if we only consider the invariance and equivalence of the output concerning the input, it can be difficult to understand, as we often imagine the mapping at the feature level, such as:
However, if we only consider the invariance and equivalence of the output concerning the input, it can be difficult to understand, as we often imagine the mapping at the feature level, such as: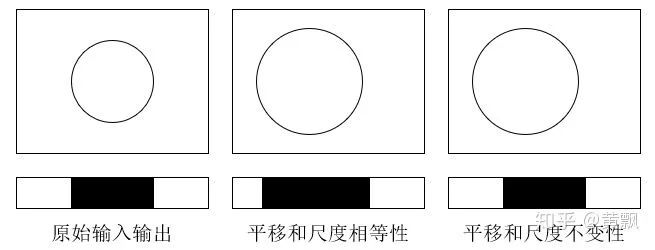



 is a feature obtained through convolution that satisfies translation invariance, then the global pooling operation
is a feature obtained through convolution that satisfies translation invariance, then the global pooling operation  also satisfies translation invariance;
also satisfies translation invariance; and downsampling factor
and downsampling factor  , if the translation of the input can be reflected in the output through linear interpolation:
, if the translation of the input can be reflected in the output through linear interpolation: According to the Shannon-Nyquist theorem,
According to the Shannon-Nyquist theorem,  satisfies shiftability, ensuring that the sampling frequency is at least twice the highest signal frequency.
satisfies shiftability, ensuring that the sampling frequency is at least twice the highest signal frequency.