
1. Why Introduce LightRAG?
Retrieval-Augmented Generation (RAG) enhances large language models (LLMs) by integrating external knowledge sources, allowing LLMs to generate more accurate and contextually relevant responses, significantly improving utility in practical applications.
-
• By adapting to domain-specific knowledge, RAG systems ensure that the information provided is not only relevant but also meets user needs.
-
• Provides a means to access up-to-date information, which is crucial in rapidly evolving fields.
-
• Chunking plays a critical role in facilitating retrieval-augmented generation. By breaking down large external text corpora into smaller, more manageable segments, the accuracy of information retrieval is improved. This allows for more targeted similarity searches, ensuring that the retrieved content is directly related to the user’s query.
However, existing RAG systems have key limitations that hinder their performance:
-
• First, many methods rely on simple data structures, limiting their ability to understand and retrieve information based on complex relationships between entities.
-
• Second, these systems often lack the necessary contextual awareness, failing to maintain coherence across different entities and their interrelations, which can lead to responses that may not comprehensively address user queries.
-
• For example, when a user asks, “How does the growth of electric vehicles affect urban air quality and public transportation facilities?” existing RAG methods may retrieve documents about electric vehicles, air pollution, and public transportation challenges separately, but struggle to integrate this information into a coherent response.
They may fail to explain how the popularity of electric vehicles improves air quality, which in turn affects public transportation planning.
To address these limitations, the authors propose to incorporate graph structures (knowledge graphs) into text indexing and relevant information retrieval. Graphs effectively represent interdependencies between different entities, allowing for a more nuanced understanding of relationships. The integration of graph-based knowledge structures helps synthesize information from multiple sources into coherent and contextually rich responses.
Thus, the authors introduce LightRAG: a RAG system seamlessly integrating a graph-based text indexing paradigm with a dual-layer retrieval framework.
2. LightRAG Architecture
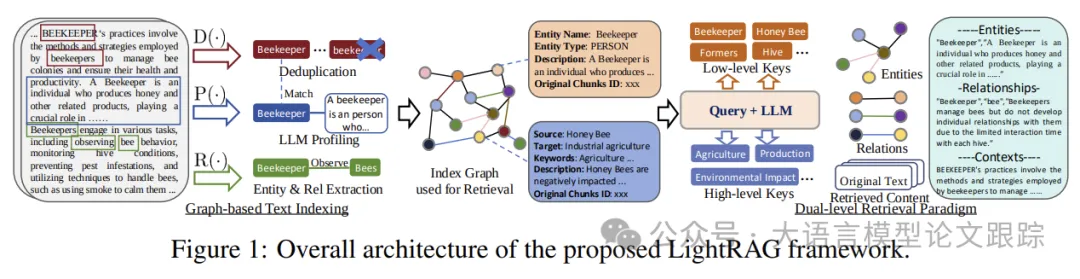
The diagram above illustrates the architecture of LightRAG, divided into two main parts:
-
• Part One: Graph-based indexing phase. Using large language models to extract entities and relationships from each text chunk.
-
• Part Two: Graph-based retrieval phase. First, using large language models (LLMs) to generate relevant keywords.
-
• Similar to current retrieval-augmented generation (RAG) systems, the retrieval mechanism of LightRAG relies on vector-based search.
-
• Unlike traditional RAG which retrieves chunks, LightRAG focuses on retrieving entities and relationships.
-
• Compared to the community-based traversal methods used in GraphRAG, LightRAG significantly reduces retrieval overhead.
2.1 Graph-Based Text Indexing
Graph-Enhanced Entity and Relationship Extraction: LightRAG enhances the retrieval system by segmenting documents into smaller, more manageable parts. This allows for quick identification and access to relevant information without analyzing the entire document. Large language models (LLMs) are utilized to identify and extract various entities (e.g., names, dates, places, and events) and their relationships, creating a knowledge graph.

-
• Extracting Entities and Relationships: Utilizing LLMs to identify entities (nodes) and their relationships (edges) in textual data. For example, extracting entities such as “cardiologist” and “heart disease” and relationships like “cardiologist diagnoses heart disease” from the text “The cardiologist assesses symptoms to identify potential heart problems.” To improve efficiency, the original text is segmented into multiple chunks before entity and relationship extraction. The above image shows the prompts used to construct the knowledge graph.
-
• LLM Generates Key-Value Pairs: LLMs generate text key-value pairs (K, V) for each entity node and edge. Each index key is a word or phrase that enables efficient retrieval, while the corresponding value is a text paragraph summarizing relevant segments from external data to assist in text generation. Entities use their names as unique index keys, while relationships may have multiple index keys derived from LLM enhancement, including global themes from connecting entities.
-
• Graph Deduplication: Identifying and merging identical entities and relationships from different segments of the original text. This process minimizes the size of the graph, reducing overhead associated with graph operations, resulting in more efficient data processing.
This design has several advantages:
-
• First, a global understanding of information. The constructed graph structure can extract global information from multi-hop subgraphs, enhancing LightRAG’s ability to handle complex queries spanning multiple document chunks.
-
• Second, enhanced retrieval performance. The key-value data structure derived from the graph is optimized for fast and accurate retrieval. It provides a superior alternative to the less accurate embedding matching methods and inefficient chunk traversal techniques commonly used in existing methods.
Incremental Updates to Knowledge Base*
The rapid update method for the incremental knowledge base has two key objectives:
-
• Seamless integration of new data. By applying a consistent method to new information, the incremental update module allows LightRAG to integrate new external databases without disrupting the existing graph structure. This maintains the integrity of established connections, ensuring that historical data remains accessible while enriching the graph without conflicts or redundancies.
-
• Reducing computational overhead. By eliminating the need to rebuild the entire index graph, this approach reduces computational overhead and facilitates the rapid absorption of new data.
2.2 Dual-Layer Retrieval Paradigm
LightRAG generates query keys across both micro and macro dimensions, allowing for the retrieval of relevant information within specific document chunks and complex dependencies.
-
• Micro Queries (Specific Queries): Focused on specific details, referencing particular entities in the graph, requiring precise retrieval of information related to specific nodes or edges. For example, a specific query might be, “Who wrote ‘Pride and Prejudice’?”
-
• Abstract Queries: Abstract queries are more conceptual, covering broader themes, summaries, or overall topics not directly related to specific entities. An example of an abstract query is, “How does artificial intelligence impact modern education?”
To accommodate different query types, LightRAG employs two different retrieval strategies in the dual-layer retrieval paradigm. This ensures that both specific and abstract queries are effectively handled, allowing the system to provide relevant responses based on user needs.
-
• Low-Level Retrieval: Focused on retrieving specific entities and their associated attributes or relationships. This level of query is detail-oriented, extracting precise information about specific nodes or edges in the graph.
-
• High-Level Retrieval: Addresses broader topics and overall themes. Aggregates information across multiple related entities and relationships, providing insights into higher-level concepts and summaries rather than specific details.
Retrieval Combining Graph and Vector Search
By combining graph structures with vector representations, the retrieval algorithm can effectively utilize local and global keywords, streamlining the search process and enhancing the relevance of results.
-
• 1.Query Keyword Extraction. For a given query, LightRAG first extracts local query keywords and global query keywords.
-
• 2.Keyword Matching. Using a vector database, local query keywords are matched with candidate entities, and global query keywords are matched with relationships linked to global keys.
-
• 3.Incorporating High-Order Relatedness. To enhance the high-order relatedness of queries, LightRAG retrieves not only graph elements but also extends to neighboring nodes within the local subgraphs of these elements.
This dual-layer retrieval paradigm not only facilitates the efficient retrieval of relevant entities and relationships through keyword matching but also enhances the comprehensiveness of results by integrating relevant structural information from the constructed knowledge graph.
2.3 Answer Generation
Utilization of Retrieved Information: Using the retrieved information, LLMs generate answers based on the collected data. The collected data includes descriptions of relevant entities and relationships, including names, entity and relationship descriptions, and excerpts from the original text.
Context Integration and Answer Generation: Unifying the query with this multi-source text, LLM generates information-rich answers tailored to user needs, ensuring alignment with the intent of the query. This approach simplifies the answer generation process by integrating both context and queries into the LLM model (the image below shows the prompts).
3. Effectiveness Evaluation
-
• RQ1: What advantages does LightRAG have in generation performance compared to existing RAG baseline methods?
-
• RQ2: How does dual-layer retrieval and graph-based indexing enhance the generation quality of LightRAG?
-
• RQ3: What unique advantages does LightRAG demonstrate in various scenario cases?
-
• RQ4: What are the costs of LightRAG and how does it adapt to data changes?
3.1 RQ1: What advantages does LightRAG have in generation performance compared to existing RAG baseline methods?
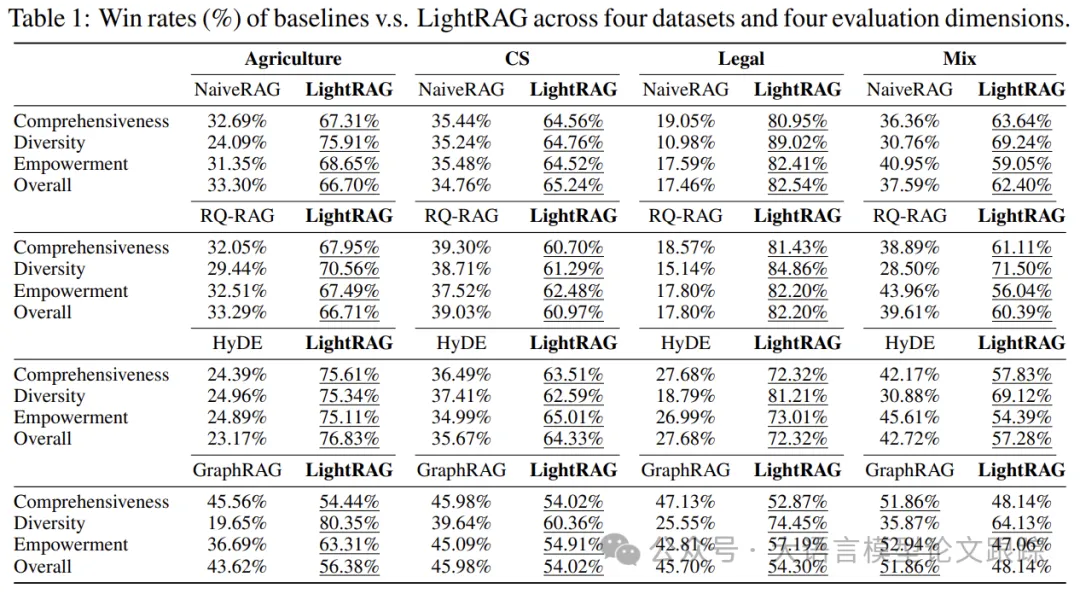
Advantages of Graph-Enhanced RAG Systems in Handling Large-Scale Corpora: When faced with the need for a significant number of tokens and complex queries, LightRAG and other graph-based RAG systems consistently outperform pure block-based retrieval methods like NaiveRAG, HyDE, and RQRAG. This performance difference is particularly pronounced as the dataset size increases. For instance, in the largest legal dataset, baseline methods have a win rate of only about 20%, while LightRAG clearly dominates. This trend highlights the advantages of graph-enhanced RAG systems in capturing complex semantic dependencies within large-scale corpora, aiding in a more comprehensive understanding of knowledge and improving generalization performance.
LightRAG’s Advantage in Enhancing Response Diversity: Compared to various baseline methods, LightRAG stands out in diversity (whether the answers provide diverse perspectives) metrics, especially in large legal datasets. This advantage stems from LightRAG’s dual-layer retrieval model, which comprehensively retrieves information from both low-level and high-level dimensions. This method effectively leverages graph-based text indexing, consistently maintaining the complete context of queries.
LightRAG Surpasses GraphRAG: Although both LightRAG and GraphRAG employ graph-based retrieval mechanisms, LightRAG consistently outperforms GraphRAG, particularly in handling large datasets and complex linguistic environments. In agricultural, computer science, and legal datasets containing millions of tokens, LightRAG demonstrates a clear advantage, significantly surpassing GraphRAG, highlighting its ability to comprehensively understand information in diverse environments.
3.2 RQ2: How does dual-layer retrieval and graph-based indexing enhance the generation quality of LightRAG?
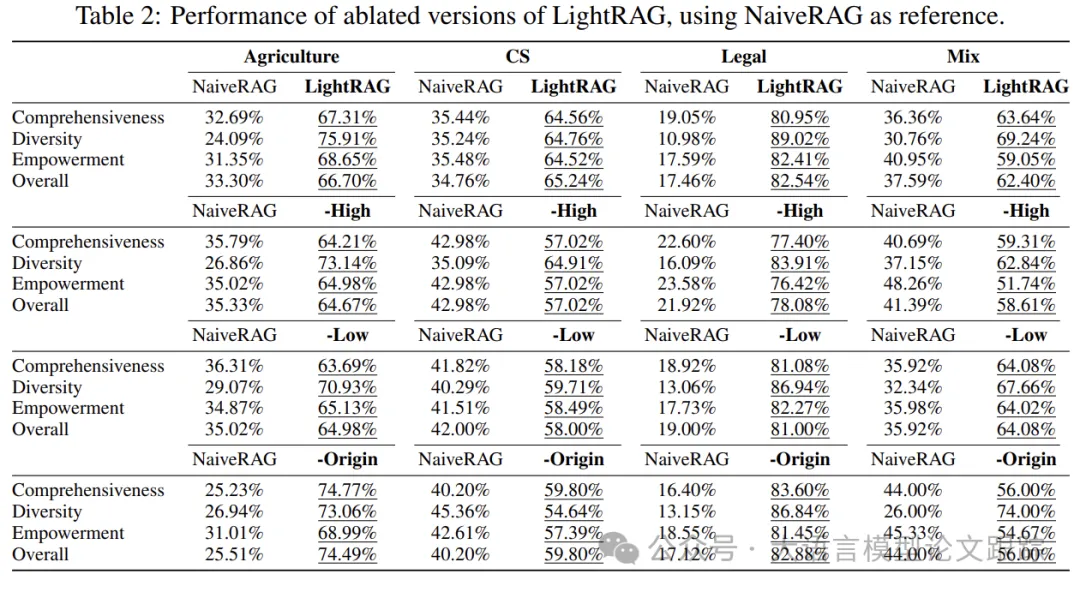
-
• Low-Level Retrieval Only: Removing high-level retrieval leads to significant performance declines across nearly all datasets and evaluation metrics. This is primarily because it overly emphasizes specific information, focusing on entities and their direct associations. While this approach can delve deeply into directly related entities, it struggles to collect complex query information that requires comprehensive insights.
-
• High-Level Retrieval Only: LightRAG with only low-level retrieval prioritizes acquiring broader content by utilizing relationships between entities rather than focusing on specific entities. This method has significant advantages in comprehensiveness, allowing for the collection of broader and more diverse information. However, it may fall short in deeply exploring specific entities, potentially limiting its ability to provide detailed insights. Therefore, this high-level retrieval-only approach may perform poorly in tasks requiring precise, detailed answers.
-
• Hybrid Mode: While retrieving broader relationships, it also deeply explores specific entities. This dual-level approach ensures both breadth of retrieval and depth of analysis, providing a comprehensive perspective of the data. Thus, LightRAG achieves balanced performance across multiple dimensions.
-
• Semantic Graph Performs Well in RAG: Not using the original text (-Origin) during retrieval does not exhibit significant performance declines across all four datasets. In some cases, this variant even shows improvement (e.g., in agriculture and hybrid aspects). The primary reason may be the effective extraction of key information during the graph-based indexing process, which provides sufficient context for answering queries. Additionally, original texts often contain irrelevant information that may introduce noise into responses.
3.3 RQ3: What unique advantages does LightRAG demonstrate in various scenario cases?


-
• Comprehensiveness: Excels in precise entity and relationship extraction as well as LLM analysis.
-
• Diversity and Empowerment: LightRAG not only provides more diverse information but also offers more empowering content. This is primarily due to LightRAG’s layered retrieval paradigm, which combines in-depth exploration of relevant entities through low-level retrieval and broader exploration through high-level retrieval to enhance empowerment and improve answer diversity.
3.4 RQ4: What are the costs of LightRAG and how does it adapt to data changes?
We compare the costs of our LightRAG with the best-performing baseline GraphRAG from two key perspectives.
-
• First, examining the number of tokens and API calls during the indexing and retrieval processes.
-
• Second, relating these metrics to handling data changes in dynamic environments.
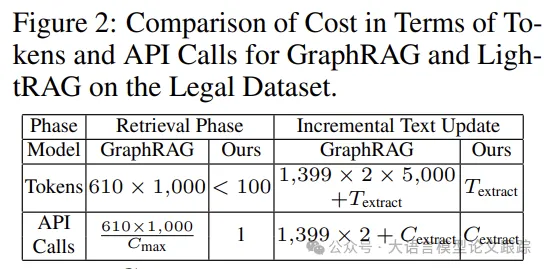
3.4.1 Retrieval Phase
GraphRAG generated 1,399 communities, with 610 secondary communities actively used for retrieval. Each community reports an average of 1,000 tokens, leading to a total token consumption of 610,000 tokens (610 communities × 1,000 tokens per community).
Additionally, GraphRAG requires traversing each community separately, resulting in hundreds of API calls, significantly increasing retrieval overhead. In contrast, LightRAG only requires fewer than 100 tokens for keyword generation and retrieval, with the entire process needing only one API call. This efficiency is achieved through LightRAG’s retrieval mechanism, which seamlessly integrates graphical structures and vectorized representations for information retrieval, eliminating the need to pre-process large amounts of information.
3.4.2 Incremental Data Update Phase
Both schemes exhibit similar overhead in entity and relationship extraction.
However, GraphRAG demonstrates significant inefficiency in managing newly added data. When introducing a new dataset of the same size as the legal dataset, GraphRAG must dismantle its existing community structure to incorporate new entities and relationships, then completely regenerate.
This process incurs a high token cost, with each community reporting approximately 5,000 tokens. Given that there are 1,399 communities, GraphRAG would need about 1,399 × 2 × 5,000 tokens to rebuild the original and new community reports – an excessively high cost that highlights its inefficiency.
In contrast, LightRAG seamlessly integrates newly extracted entities and relationships into the existing graph without requiring complete reconstruction. This approach results in significantly lower overhead during incremental updates, demonstrating its superior efficiency and cost-effectiveness.
Source | Overview of Large Prediction Model Papers
For reference links, click the bottom left corner to read the original text. For academic sharing only, please delete immediately if there is any infringement.
Editor / Garvey
Review / Fan Ruiqiang
Recheck / Fan Ruiqiang
Click below
Follow us