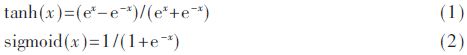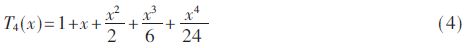Predicting the parameters of Insulated Gate Bipolar Transistors (IGBTs) can effectively avoid economic losses and safety issues caused by their failures. By analyzing the parameters of IGBTs, a System on Chip (SoC) hardware system for IGBT parameter prediction based on LSTM networks is designed. This system uses an ARM processor as the main controller to manage the invocation of various sub-modules and data transmission. The FPGA optimizes the matrix-vector multiplication algorithm to enhance the internal data computation speed of the LSTM network and employs polynomial approximation methods to reduce the resources consumed by the activation function. Experimental results show that the average prediction accuracy of the system is 92.6%, and the computation speed is 3.74 times faster than that of a CPU, while also featuring low power consumption.
Chinese Citation Format: Li Yuanbo, Yang Yuan, Zhang Xiaotao. Design of IGBT parameter prediction hardware system based on LSTM network[J]. Application of Electronic Technique, 2019, 45(10):33-36.English Citation Format: Li Yuanbo, Yang Yuan, Zhang Xiaotao. Design of IGBT parameter prediction hardware system based on LSTM network[J]. Application of Electronic Technique, 2019, 45(10):33-36.
0 Introduction
Today, with the rapid development of computer computing power and the continuous maturity of the integrated circuit industry, machine learning has become one of the hottest research fields[1]. In machine learning models, artificial neural networks are widely used across various domains due to their high prediction accuracy. For learning and predicting time series data, Recurrent Neural Networks (RNNs)[2] and their various improved models have gradually become a commonly used method[3-4]. However, most hardware platforms that currently apply RNNs are implemented through large server CPUs[5-6] or microcontrollers[7], which cannot meet the requirements for efficiency, portability, and low power consumption in some harsh application scenarios. In recent years, SoCs integrating ARM processors and FPGAs have become a new development direction for embedded systems. SoCs retain the advantages of FPGAs in terms of easy customization and fast parallel computation, while inheriting the high speed and low power consumption advantages of ARM processors, achieving functional complementarity[8]. Therefore, SoC systems can be used for hardware acceleration and low power design of RNN networks.This paper addresses the issue of the high failure rate and uncertain lifespan of Insulated Gate Bipolar Transistors (IGBTs)[9], which are widely used in the field of power electronics, by utilizing RNN networks to predict the state parameters of IGBTs and implementing the network model on the SoC platform, thereby designing a hardware SoC system for RNN networks that meets the high speed, low power, and portability requirements of the IGBT parameter prediction system without significant loss in accuracy.
1 IGBT Parameter Analysis
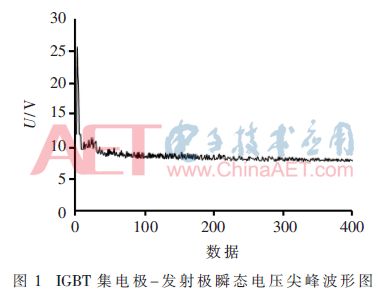
Before training the RNN network, it is necessary to analyze the state parameters of the IGBT. This paper studies the accelerated aging experiments conducted by NASA’s PCoE research center on IGBTs[10]. The experiment uses a single IGBT to load a Pulse Width Modulation (PWM) signal until a locking effect occurs, leading to the IGBT’s damage. The experimental temperature is 330 °C, the duty cycle is 40%, the gate voltage is 10 V, the protection temperature is 345 °C, and the switching frequency is 10 kHz.The experiment includes 418 sets of transient data. Each set contains one hundred thousand collector-emitter voltage data points. The interval for each data point is 1 ns, and the time scale for each set of transient data is 0.1 ms. It was found that the waveforms of gate voltage and current during turn-on and turn-off show almost no change over time. The collector-emitter voltage characteristics change little when turned on, but during turn-off, the transient voltage spikes of the collector-emitter exhibit a strong negative time correlation, as shown in Figure 1. Based on this, this paper analyzes the correlation between the transient voltage spike value of the collector-emitter and historical data at a certain moment, thus using the transient voltage spike value of the collector-emitter for training and prediction.
2 LSTM Network Model Hardware Design and Implementation
2.1 LSTM Network Model
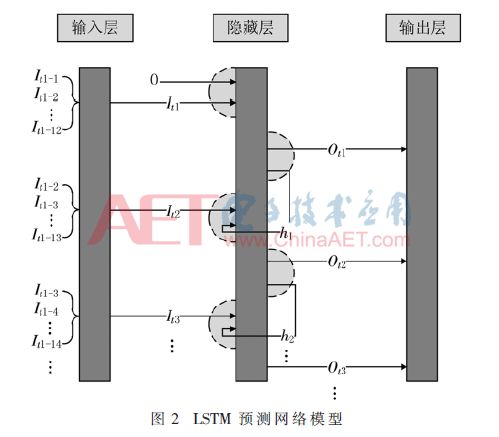
The network model in the system adopts a Long Short-Term Memory (LSTM) model[11], which is an improvement over the standard RNN model. It adds memory cells and is controlled by three gates: the input gate, forget gate, and output gate. LSTM is more suitable for time series prediction compared to ordinary RNN models. Based on the characteristics of the transient voltage spike data of IGBTs, this paper makes certain improvements to the input and output of the LSTM network, as shown in Figure 2. Here, It1 is the model input, composed of 12 true values of the collector-emitter transient voltage spikes It1-1~It1-12. Similarly, It2 and It3 correspond to true values It1-2~It1-13 and It1-3~It1-14, respectively. The model output Ot1 corresponds to the predicted value associated with the true value It13, and similarly Ot2 and Ot3 correspond to the true values It14 and It15. h1 and h2 are the neuron state values at times t1 and t2. Therefore, both the input and output of this network model are continuous time series.
2.2 Overall Hardware Architecture
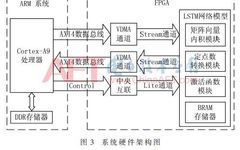
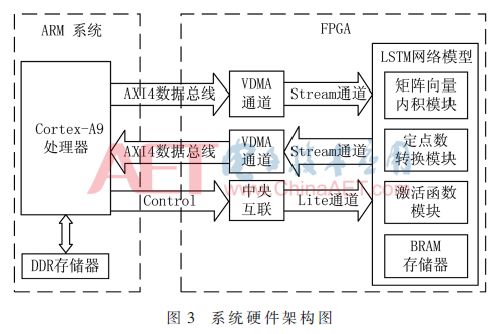
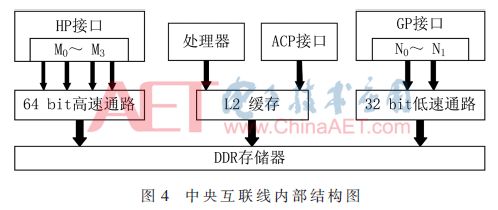
This paper uses the Xilinx Zynq-7000 SoC platform, which integrates a dual-core ARM Cortex-A9 processor system with FPGA, allowing both to operate independently while achieving high-speed broadband data communication via a high-performance bidirectional Advanced eXtensible Interface (AXI) bus. Figure 3 illustrates the entire system’s hardware architecture, where the ARM processor serves as the system’s main controller, managing all hardware sub-modules. Data is transmitted through the AXI bus[12], with the Lite channel used for control signal transmission, and the Stream channel responsible for computing data transmission. AXI4 is the data bus between the DDR memory and FPGA, while the FPGA is mainly responsible for various data computations within the LSTM network. The FPGA first reads the required data from DDR memory in parallel through two VDMA modules. This includes the network weights of the LSTM and input vectors, which are processed through dot products, fixed-point conversions, activation functions, etc., before outputting the result vector via VDMA. According to the computation logic of the LSTM network, this design also requires BRAM to store the state and output values of each LSTM cell for use by other modules.
The FPGA side accesses DDR memory through the system bus GP, HP, and ACP interfaces in the central interconnect line, with the internal structure shown in Figure 4. The four HP interfaces connect to the DDR memory via a 64-bit high bandwidth data path, while the two GP interfaces connect via a 32-bit low-speed path. The processor and ACP interface must first go through L2 cache before connecting to DDR memory to enhance data transfer speed.
2.3 Optimization of Matrix-Vector Multiplication Algorithm
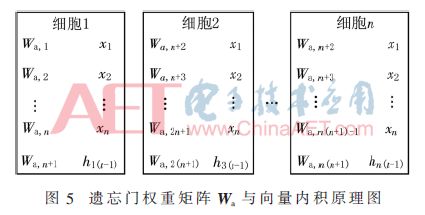
In the entire SoC system, matrix-vector multiplication is the core computation part. To enhance the computation speed of the system, this paper optimizes the algorithm. Figure 5 illustrates the principle of the weight matrix wa of the forget gate and the vector’s inner product. The number of cell units is n, and at time t, the input vector of each cell unit is Xt(Xt={x1, x2, …, xm}) and the output vector from the previous time step ht-1. Since the multiplication of different vectors with their corresponding matrices is independent, this paper merges Xt and ht-1 into a long vector before computing with the weight matrix W. The inner product process for the weight matrices Wi and Wo is the same as that for Wa.
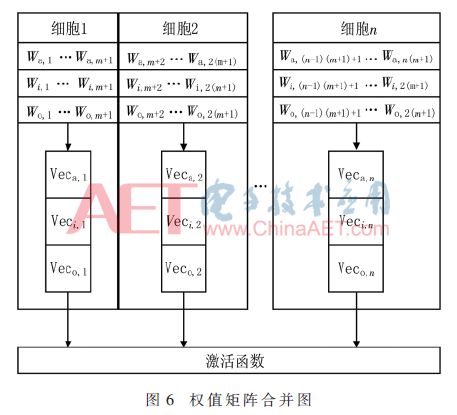
Similarly, the three weight matrices Wa, Wi, and Wo can also be merged into one matrix. As shown in Figure 6, due to the presence of the three gates in the LSTM model, the result of the matrix-vector multiplication will be split into three vectors Veca, Veci, and Veco, which will participate in the subsequent activation function operations at the three input terminals of the LSTM network.
2.4 Implementation of Activation Functions
The activation function serves to introduce non-linear factors into the neural network. In the LSTM unit, the activation function used at the input terminal is tanh, represented mathematically as shown in equation (1); the other activation function is sigmoid, represented as shown in equation (2). Additionally, when processing output values, the cell state also passes through the tanh activation.
From the above equations, it can be seen that these operations involve the exponential operation of e, i.e., ex. However, directly calling the IP core for the ex function in FPGA consumes a large amount of computational resources. Using polynomial approximation methods can reduce the computational load while maintaining a small error that does not affect the prediction results of the neural network. The Taylor expansion of ex at x=0 is as follows:
This paper adopts n=4 for the approximation, where the polynomial approximation of the function is expressed as follows:
3 System Testing and Results
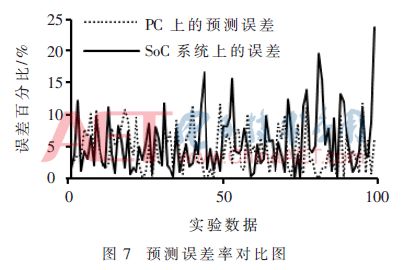
This paper uses the Xilinx Vivado platform for hardware development and testing, utilizing the Zynq-7000 series development board for validation, with the chip model xc7z020clg400-2, where the main frequency of the ARM Cortex-A9 processor is 667 MHz, and the FPGA’s operating frequency is 100 MHz, with 220 DSP48E resources. Additionally, this development board is compact and lightweight, making it easy to deploy and carry. The PC platform utilizes an Intel Core i5-8400 processor with a main frequency of 2.8 GHz and 8 GB of memory. For comparison, both experimental platforms use the same LSTM neural network structure and testing data for simulation validation.The experimental results are shown in Figure 7, which captures the error rates of 100 typical continuous data points from all prediction results. It can be observed that there are certain differences in error rates between the PC platform and the Zynq-7020 development board, with the maximum reaching about 20%. After calculations, the final average prediction accuracy on the PC is 96%, while on the SoC system, it is 92.6%. The reason for this difference is that the FPGA uses fixed-point numbers, and the conversion between floating-point and fixed-point numbers introduces truncation errors, leading to some discrepancies in the computation results. Although the average prediction accuracy on the SoC system is lower than that on the PC, it can meet basic application requirements in practical use.
The hardware resource utilization on the system is shown in Table 1. It can be seen that the DSP utilization of the accelerator architecture is relatively high, as a large number of multiplications and divisions are used in the activation function. However, considering the timing requirements for layout and routing, it is generally not advisable to have an excessively high resource occupancy rate, as this may lead to timing convergence issues due to long routing. Meanwhile, the utilization rates of LUTRAM and BRAM are relatively low, providing ample space for future calculations that require more data.
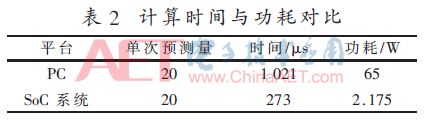
Table 2 compares the computation time and power consumption of achieving the same structure and data on both platforms. The data shows that when the amount of prediction data is 20, the running time on the PC is 1,021 μs, while on the Zynq-7000 development board, it is 273 μs, which accelerates 3.74 times compared to the PC. Meanwhile, the power consumption on the PC reaches 65 W, while on the Zynq-7020 platform, it is only 2.175 W, which is only 3.3% of the former, meeting the application requirements for embedded mobile terminals.
4 Conclusion
This paper first analyzes the failure causes of the IGBT power module based on experiments, identifies the failure parameters, selects the LSTM model from RNN networks, and makes improvements to it. Finally, a SoC hardware system is designed based on this LSTM model. An ARM processor is used as the main controller of the system, and the matrix-vector multiplication is optimized within the FPGA to improve data computation efficiency. The activation function is defined using power series approximation, and a complete system is built using the AXI bus. Through validation and comparison on the Zynq-7020 development board, the designed SoC hardware system achieves an average prediction accuracy of 92.6%, operates at a speed 3.74 times that of the PC, and has a power consumption of only 3.3% of the PC platform. This presents a broad development prospect for low-power design and provides a new method for predicting the parameters of IGBT power modules.
References
[1] ALPAYDIN E. Introduction to machine learning[M]. Boston: MIT Press, 2004.
[2] GRAVES A. Generating sequences with recurrent neural networks[J]. arXiv preprint arXiv: 1308.0850, 2013.
[3] Zheng Yi, Li Feng, Zhang Li, et al. Human posture detection method based on long short-term memory network[J]. Computer Applications, 2018, 38(6): 1568-1574.
[4] Li Jie, Lin Yongfeng. Time series prediction based on multi-time scale RNN[J]. Computer Applications and Software, 2018, 35(7): 33-37, 62.
[5] Zhang Guoxing, Li Yadong, Zhang Lei, et al. Taxi trip destination prediction method based on SDZ-RNN[J]. Computer Engineering and Applications, 2018, 54(6): 143-149.
[6] Li Yakun, Pan Qing, WANG E X. Chinese word segmentation and punctuation prediction based on improved multi-layer BLSTM[J]. Computer Applications, 2018, 38(5): 1278-1282, 1314.
[7] Liu Yanping, Li Jie, Jin Fei. Research and implementation of pulse wave blood pressure monitor based on RNN[J]. Application of Electronic Technique, 2018, 44(6): 76-79, 84.
[8] WANG B, SANIIE J. Ultrasonic signal acquisition and processing platform based on Zynq SoC[C]. 2016 IEEE International Conference on Electro Information Technology (EIT). IEEE, 2016: 448-451.
[9] BAILEY C, LU H, TILFORD T. Predicting the reliability of power electronic modules[C]. 2007 8th International Conference on Electronic Packaging Technology. IEEE, 2007: 1-5.
[10] CHEN Q, ZHU X, LING Z, et al. Enhanced LSTM for natural language inference[J]. arXiv preprint arXiv:1609.06038, 2016.
[11] HOCHREITER S, SCHMIDHUBER J. Long short-term memory[J]. Neural Computation, 1997, 9(8): 1735-1780.
[12] MAKNI M, BAKLOUTI M, NIAR S, et al. Performance exploration of AMBA AXI4 bus protocols for wireless sensor networks[C]. 2017 IEEE/ACS 14th International Conference on Computer Systems and Applications (AICCSA). IEEE, 2017: 1163-1169.
Author Information:
Li Yuanbo, Yang Yuan, Zhang Xiaotao
(Department of Electronic Engineering, Xi’an University of Technology, Xi’an 710048, Shaanxi, China)
This content is original to the AET website and is prohibited from reproduction without authorization.