
Click the “Deep Learning Column” above to select the “Star” public account
Heavy content delivered immediately
From: Open Source Frontline (ID: OpenSourceTop)
Compiled from:
https://github.com/yuanxiaosc/DeepNude-an-Image-to-Image-technology, programmers, etc.
Some time ago, a programmer developed an application called DeepNude. “Is Technology Innocent? The AI Nudification App was taken down just hours after launch”
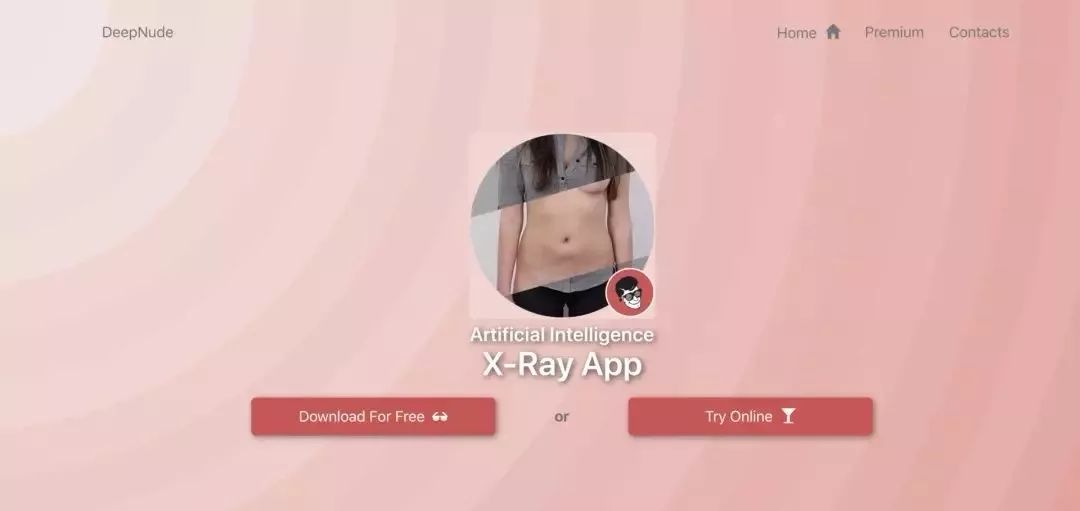
The app is very simple to use: open the software → convert → generate photos. From the generated results provided online, the effect is indeed realistic, as shown below:

Currently, this program has been taken down, but I found a project related to the image generation and image restoration technology used by DeepNude on GitHub, created by yuanxiaosc.
This repository contains the pix2pixHD algorithm (proposed by NVIDIA) used by DeepNude. More importantly, it includes the general Image-to-Image theory and practical research behind DeepNude.
Image-to-Image Demo
This section provides a trial Image-to-Image Demo: transforming black and white sketches into colorful cats, shoes, handbags. The DeepNude software mainly uses Image-to-Image technology, which theoretically can convert any input image into any desired image.
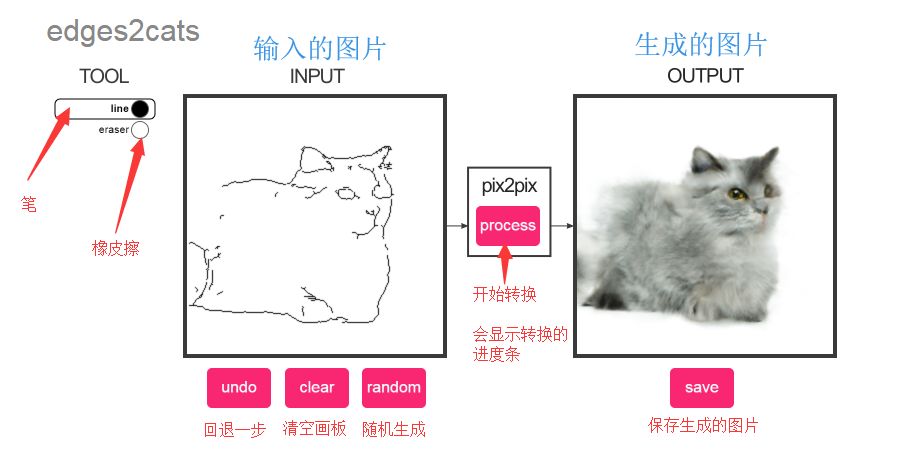
In the left box, draw a simple sketch of a cat according to your imagination, then click the process button to output a model-generated cat.
Experience link: https://affinelayer.com/pixsrv/
DeepNude’s Technology Stack

-
Python + PyQt
-
pytorch
-
Deep Computer Vision
Image-to-Image Theoretical Research
This section elaborates on the artificial intelligence/deep learning theories related to DeepNude (especially in computer vision) research,
1. Pix2Pix
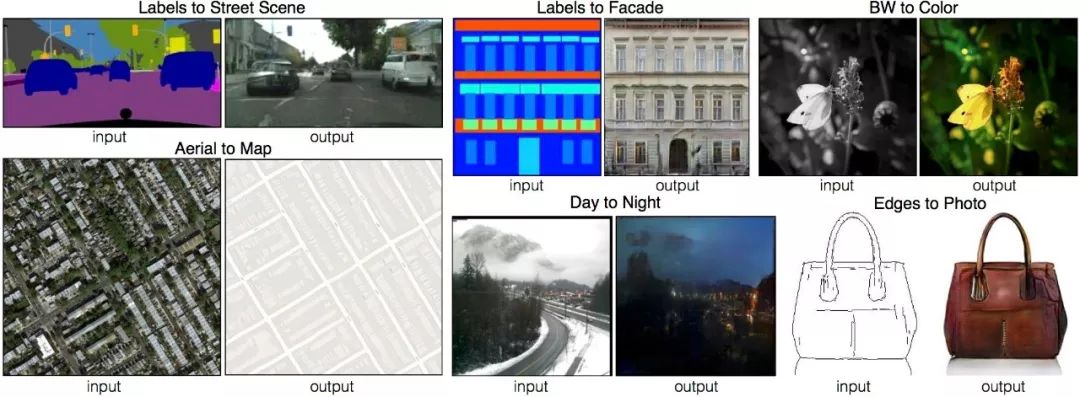
Pix2Pix is a general solution for image-to-image translation problems using conditional adversarial networks proposed by researchers at UC Berkeley. (GitHub link: https://github.com/phillipi/pix2pix)
2. Pix2PixHD


Obtaining high-resolution images from semantic maps. A semantic map is a colored image where different color blocks represent different types of objects, such as pedestrians, cars, traffic signs, buildings, etc. Pix2PixHD takes a semantic map as input and generates a high-resolution realistic image from it. Previous technologies mostly generated rough low-resolution images that did not look realistic. This research generates images of 2k by 1k resolution, which is very close to full HD photos. (GitHub link: https://github.com/NVIDIA/pix2pixHD)
3. CycleGAN

CycleGAN uses a cycle consistency loss function for training without paired data. In other words, it can translate from one domain to another without a one-to-one mapping between source and target domains. This opens up the possibility of performing many interesting tasks, such as photo enhancement, image colorization, style transfer, etc. You only need source and target datasets.
Using the CycleGAN neural network model to achieve four major functions: photo style transfer, photo effect enhancement, seasonal transformation of landscapes in photos, and object transformation.
4. Image Inpainting

In the demonstration video, simply use a tool to paint over unwanted content in the image, even if the shape is irregular, NVIDIA’s model can “restore” the image, filling in the erased area with very realistic visuals. It’s like a one-click photo editing, and “without any traces of Photoshop.” This research comes from the team of Guilin Liu and others at NVIDIA, who released a deep learning method that can edit images or reconstruct damaged images, even if the image has holes or lost pixels. This is currently the 2018 state-of-the-art method.
In fact, it may not be necessary to use Image-to-Image. We can use GANs to generate images directly from random values or from text:
1. Obj-GAN
A new AI technology called Obj-GAN developed by Microsoft Research AI can understand natural language descriptions, draw sketches, synthesize images, and refine details based on sketch frameworks and individual words provided in the text. In other words, this network can generate images of the same scene based on descriptions of everyday scenes.
Effect
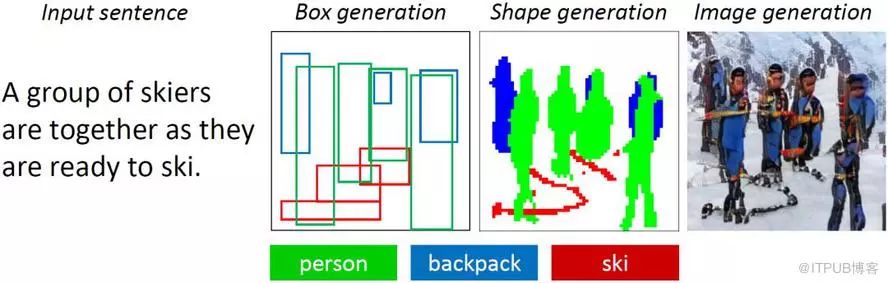
Model
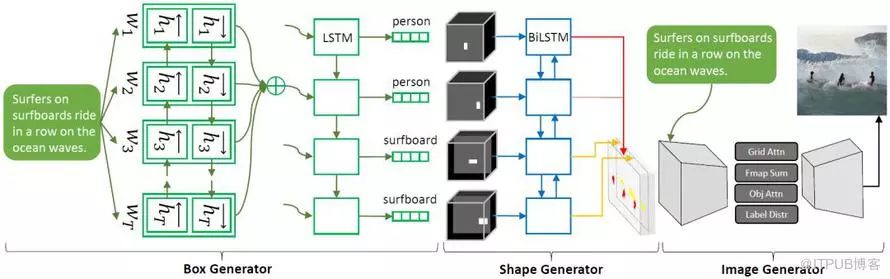
2. StoryGAN
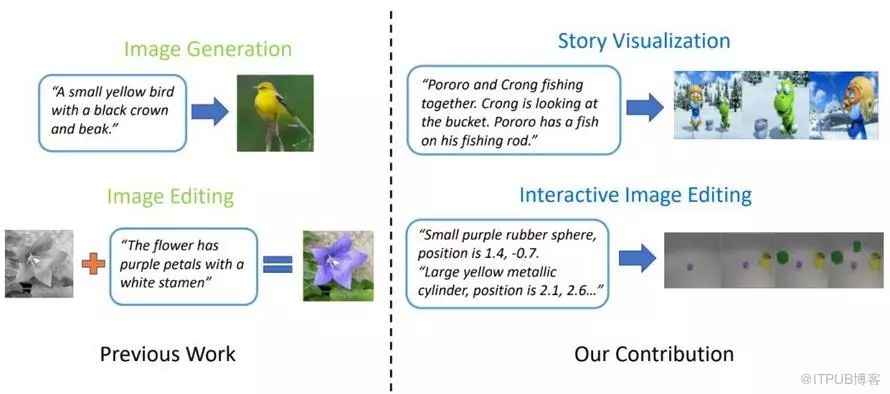
Microsoft’s new research proposes a new type of GAN—ObjGAN, which can generate complex scenes based on text descriptions. They also proposed another GAN that can draw stories—StoryGAN, which outputs comic strips based on the input text of a story.
The current best text-to-image generation model can generate realistic bird images based on single-sentence descriptions. However, text-to-image generators can do much more than just generate a single image from one sentence. Given a multi-sentence paragraph, it can generate a series of images, each corresponding to a sentence, visualizing the entire story completely.
Effect
Currently, the most used Image-to-Image technology should be beauty apps, so why not develop a more intelligent beauty camera?
Technology is innocent, but don’t entertain yourself to death. It’s important to understand what can and cannot be done. I hope everyone can use these technologies for good.

👆 Scan the QR code above to follow