 Big Data Digest Production
Big Data Digest Production
Source:Github
Publisher:yuanxiaosc
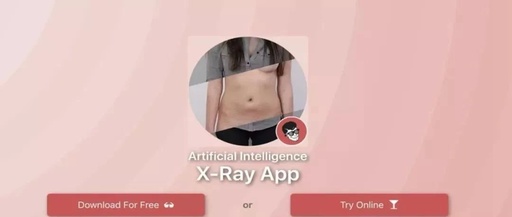
Last week, another AI niche application DeepNude surfaced, allowing users to “strip” women’s clothing with one click, going viral worldwide.
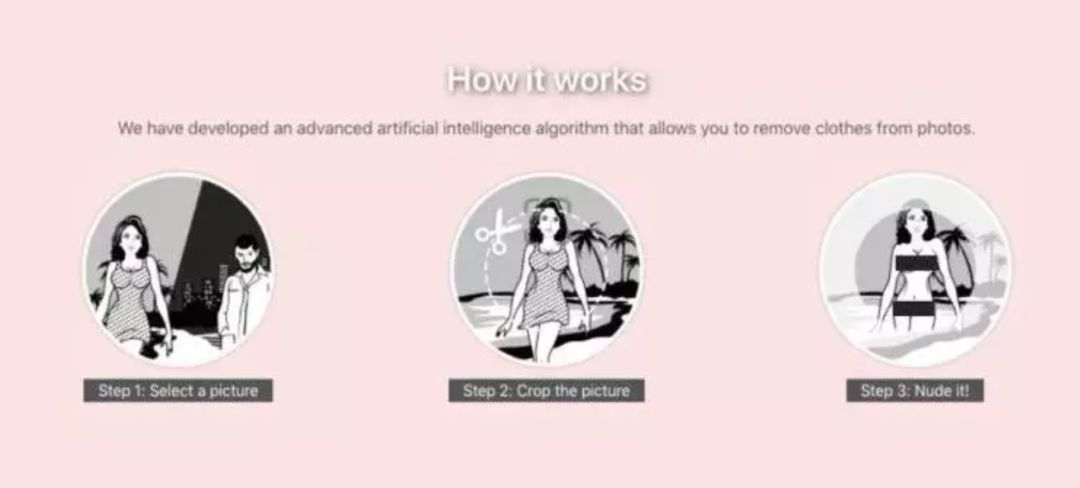
The application is also very easy to use; just provide a photo, and it can automatically “strip” clothing using neural network technology. Although the underlying principle is complex, using it is effortless, as users need no technical knowledge, just one click to obtain results.
According to the publisher, the development team is quite small, and the related technology is evidently still immature. Most photos (especially low-resolution ones) processed by DeepNude show artificial traces; when inputting cartoon character photos, the resulting images are completely distorted, and most images with low resolution produce some visual artifacts.
Of course, the target “images” are various women; the tech media Motherboard, which exposed this application early on, reported that they tested dozens of photos and found that inputting images from the Sports Illustrated Swimsuit issue produced the most realistic naked photos.

Images tested by overseas media Motherboard
This application immediately sparked various condemnations in the community, stating it is a counterexample of AI usage.
Even Andrew Ng spoke out against this project.
Under a wave of criticism, the application was quickly taken offline, but the aftershocks remain.
In particular, discussions about the technologies behind this application are ongoing.
This week, a GitHub project titled “Research on Image Generation and Restoration Technologies and Papers Used in DeepNude” rose to the weekly hot list, gaining many stars.
The project founder evidently has a deep understanding of the technology behind this project, proposing a series of technical frameworks needed for its generation, as well as which technologies may achieve better results.Here, we reprint this, hoping that all geeks can satisfy their technical curiosity while also using their technical power correctly.
Below is the original content and source link:
https://github.com/yuanxiaosc/DeepNude-an-Image-to-Image-technology
Next, I will open-source some neural network models for image/text/random-to-image, for learning and communication purposes, and I welcome you to share your technical solutions.
Image-to-Image Demo
Image-to-Image Demo
The DeepNude software mainly uses the Image Inpainting for Irregular Holes Using Partial Convolutions proposed Image-to-Image technology, which has many other applications, such as converting black and white sketches into colorful images. You can click the link below to try the Image-to-Image technology in your browser.
https://affinelayer.com/pixsrv/
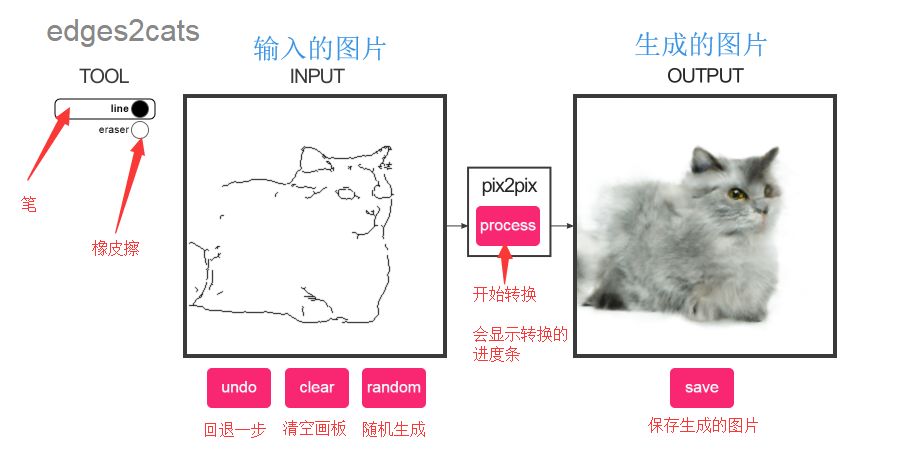
In the left box, draw a simple sketch of a cat as you imagine it, and then click the pix2pix button to output a model-generated cat.
Deep Computer Vision in DeepNude
Deep Computer Vision in DeepNude
Image Inpainting
-
Paper: NVIDIA 2018 paper Image Inpainting for Irregular Holes Using Partial Convolutions and Partial Convolution based Padding.
-
Code: Paper code partialconv.

Effect
In the Image_Inpainting(NVIDIA_2018).mp4 video, on the left side of the operation interface, simply use the tool to paint over unwanted content in the image, even if the shape is very irregular, NVIDIA’s model can “restore” the image, filling the erased areas with very realistic visuals. It can be said to be one-click photo editing, and “without any traces of editing”.This research comes from the team of Guilin Liu and others at Nvidia, who released a deep learning method that can edit images or reconstruct damaged images, even if the image has holes or lost pixels.This is currently the state-of-the-art method in 2018.
Pix2Pix (need for paired train data)
Pix2Pix (need for paired train data)
DeepNude mainly uses this Pix2Pix technology.
-
Paper: Berkeley 2017 paper Image-to-Image Translation with Conditional Adversarial Networks.
-
Homepage: Image-to-Image Translation with Conditional Adversarial Nets
-
Code: code pix2pix
-
Run in Google Colab: pix2pix.ipynb
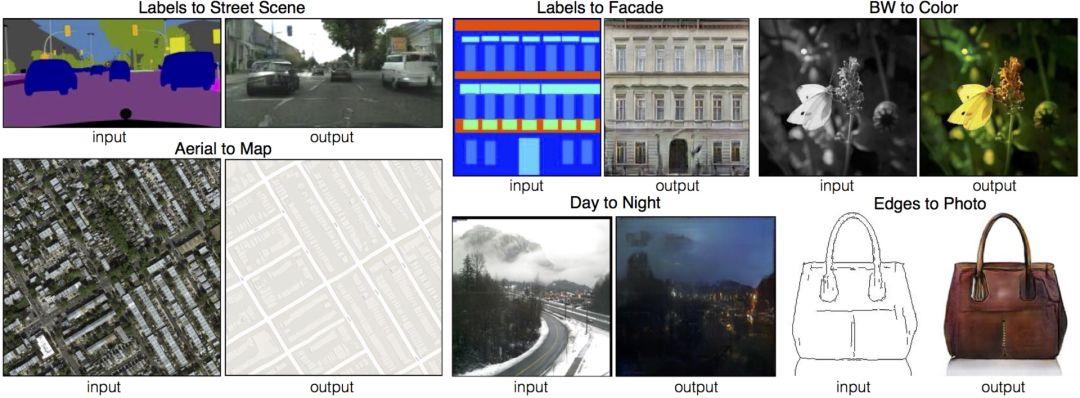
Image-to-Image Translation with Conditional Adversarial Networks is a general solution for image-to-image translation problems proposed by Berkeley University using conditional adversarial networks.
CycleGAN (without the need for paired train data)
CycleGAN (without the need for paired train data)
-
Paper: Berkeley 2017 paper Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
-
Code: code CycleGAN
-
Run in Google Colab: cyclegan.ipynb

Effect
CycleGAN uses a cycle-consistent loss function for training, without the need for paired data. In other words, it can convert from one domain to another without one-to-one mapping between the source and target domains.This opens up the possibility of performing many interesting tasks, such as photo enhancement, image coloring, style transfer, etc.You only need source and target datasets.
Future
Future
We may not need Image-to-Image. We can use GANs to generate images directly from random values or from text.
Obj-GAN
Obj-GAN
The new AI technology Obj-GAN developed by Microsoft Research AI can understand natural language descriptions, sketch, synthesize images, and then refine details based on the sketch framework and individual words provided in the text. In other words, this network can generate images of the same scene based on textual descriptions describing everyday scenarios.

Effect
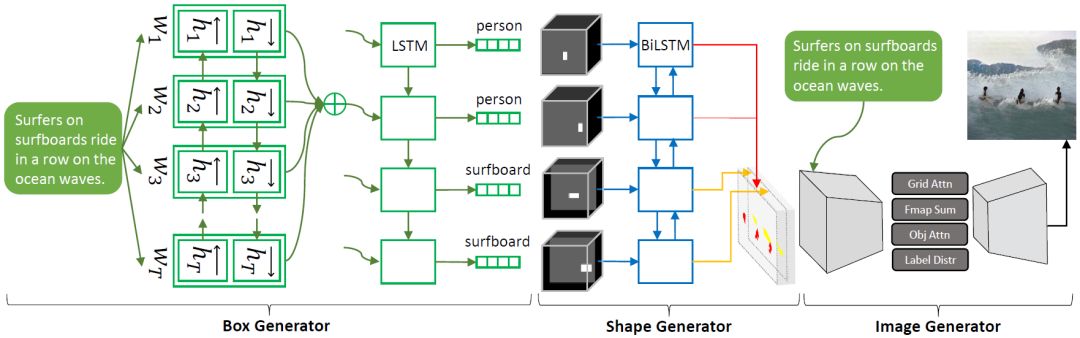
Model
StoryGAN
StoryGAN
Advanced magic pen: just one sentence, one story, can generate a picture
Microsoft’s new research proposes a new type of GAN—ObjGAN, which can generate complex scenes based on textual descriptions. They also proposed another GAN that can draw stories—StoryGAN, which can output “comic strips” based on the text of a story.
The current best text-to-image generation model can generate realistic bird images based on single-sentence descriptions. However, text-to-image generators go far beyond generating a single image from a single sentence. Given a multi-sentence paragraph, it can generate a series of images, each corresponding to a sentence, visualizing the entire story completely.
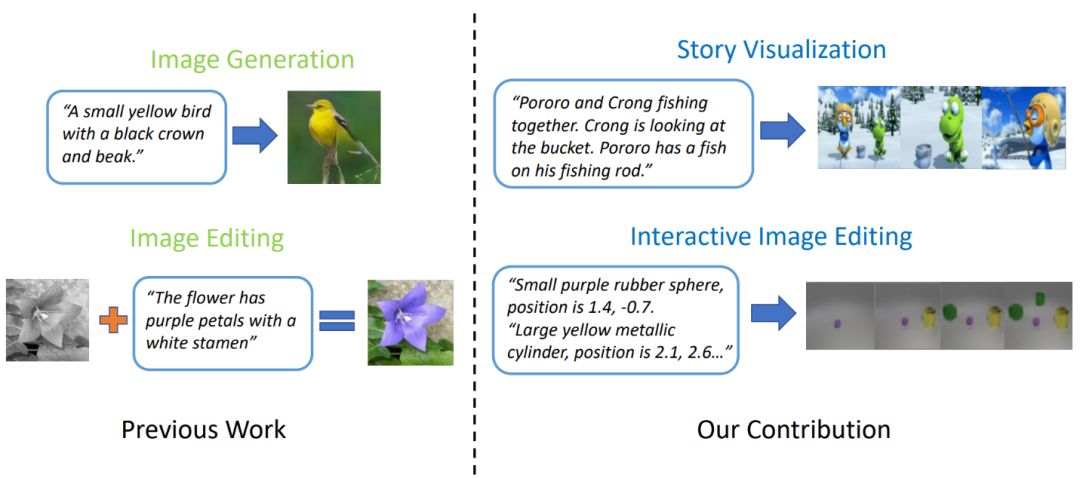
Effect
The most commonly used Image-to-Image technology today should be beauty apps, so why not develop a more intelligent beauty camera?
Intern/Full-time Editor Reporter Recruitment
Join us and experience every detail of a professional tech media reporting, growing with a group of the best people around the world in the most promising industry. Located at Tsinghua East Gate in Beijing, reply “Recruitment” on the Big Data Digest homepage dialogue page for details. Please send your resume directly to [email protected]