
Source: Intelligent Learning and Thinking Distributed Laboratory
This article is about 6100 words long, and it is recommended to read it in 9 minutes.
This article analyzes the key points and main innovations behind the core paper of ChatGPT.
Origin
By inputting a few simple keywords, AI can help you generate a short story or even a professional paper. As a dialogue language model that knows both the heavens and the earth, the recently popular ChatGPT has shown powerful performance in tasks such as email writing, video scripting, text translation, and code writing, leading Elon Musk to claim that he feels the “danger” of AI.
The computational logic behind the recently popular ChatGPT comes from an algorithm called Transformer. It originated from a research paper published in 2017 titled “Attention is All You Need.” Originally focused on natural language processing, this paper has begun to be widely used in various fields of AI due to its excellent interpretability and computational performance, becoming one of the most popular AI algorithm models in recent years. Both this paper and the Transformer model represent a microcosm of today’s AI technological development.
This is also why I want to analyze the core points and main innovations of this article here.
However, I am not a professional in AI (mathematics, computer science); I am just organizing and sharing my learning experiences and thoughts, hoping to discuss with everyone. I welcome valuable feedback; my descriptions are not professional, and experts can skip them.
From the proposal of the Transformer to the birth of the large-scale pre-training model GPT (Generative Pre-Training), and then to the iteration of GPT2 marking OpenAI’s transition to a profit-making company, as well as the emergence of GPT3 and ChatGPT; looking at the industry, the Fourth Paradigm involves multiple important fields such as biomedicine and intelligent manufacturing, all of which have seen technologies based on Transformer implemented. In this wave, my thoughts are:
First, for a long time in the future in the field of intelligence, we will experience a rapid iteration of the cycle of “research, computing power, infrastructure, engineering, data, and solutions”; fluidity and innovation will not stabilize in the short term but will become stronger.
It is difficult for us to wait for technology to be packaged and all this knowledge to be shielded before refining products. The teams that win in the future will be those that can effectively “balance productization with research and engineering innovation.” What we generally understand as R&D is actually engineering, but the practical science nature of AI requires teams to better accept this “fluidity.” Therefore, for all practitioners or those interested in intelligence, understanding full-stack knowledge has become a necessity.
Second, through the discussion of this paper, we can more intuitively understand: what has happened on the research side, at what speed and rhythm it has occurred; which are milestones? They are like Messi emerging in the scientific world, leading us to discover the truth; which are micro-innovations? The direction may be clear, but there is still much space to expand; and which are more like alchemy? They are still exploring and may need a long time, or will always remain in this state.
Third, in the AI field, due to technical reasons, more papers are open source; on the one hand, this promotes more people to participate in improvements and iterations; on the other hand, it seamlessly connects research with engineering implementation, and a single paper can drive a wide range of value diffusion from core code to platforms to specific applications. A single paper can represent an entire field, a race track, or even directly drive significant improvements in business value and customer value.
Fourth, the development of AI technology spans many fields (perception, cognition; perception can be divided into images, voice, text, etc., and cognition can also be divided into many levels). Previously, there were significant differences in algorithm logic across these fields. The emergence of Transformer has somewhat promoted the convergence of various fields. Clearly introducing this paper may help grasp the overall picture. Moreover, ChatGPT is a phenomenal application that everyone can intuitively feel; the experience enhancement and update speed of such applications will only accelerate in the future. Understanding the logic behind it will help us grasp this trend.
Paper Introduction
Now, let’s get to the main topic and start introducing this paper, which will involve some technical details and formulas that may require careful reading. I believe that once you dive in, your understanding of AI will deepen significantly.
Overall Understanding
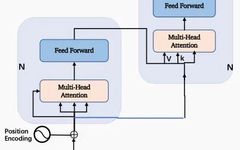
This paper is structured very concisely: it raises a question, analyzes the problem, provides a solution, and presents test data. Top journal articles emphasize brevity and conciseness, with descriptions, code, and results; the core of the paper is the following diagram, where the author team proposes the core algorithm structure of the Transformer:
The entire article is focused on explaining this diagram. Due to space limitations, we will focus on one main line: 1. What is the main problem the article aims to solve? 2. How is it solved? 3. Using the solution proposed in the article as a case to provoke overall thinking, we will simplify the content and mainly focus on the core parts.
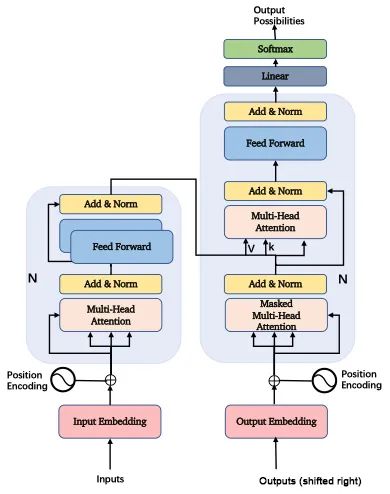
If you understand the content expressed in this diagram, you have basically grasped 85% of the content of this paper, which is also the most critical part.
“Attention is All You Need” was mainly written to consider NLP tasks and was completed by several researchers at Google. One background is that Google is also promoting its parallel computing chip and the AI TensorFlow development platform. The platform’s main features are parallel computing, and the algorithm in this paper also aims to maximize parallel computation. Let’s use a simple example to walk through this algorithm.
Core Content
The requirement is that we need to train a model to perform Chinese to English translation.
Background knowledge: This requirement needs to transpose “Translate: 我爱你 to I love you” into a y=f(x) problem, where x represents Chinese and y represents English. We need to train to obtain f(), and once training succeeds with f(), translation can be achieved. Everyone is competing to see whose training method is more accurate and efficient, and whose f() is more usable.
Previously, the main algorithm for natural language processing was called RNN (Recurrent Neural Network), which primarily operates by passing the result of each “character” to the next character. The algorithm’s drawback is that it requires a lot of serial computation, which is inefficient. Moreover, when encountering longer sentences, earlier information is likely to be diluted, resulting in inaccurate models, meaning that the effectiveness diminishes for longer sentences. This is the problem that this paper aims to solve, meaning this paper has a better method for training f(). Think about how ChatGPT can write papers and feel it.
In the Transformer, the authors propose calculating each character’s relevance to all words in the sentence, determining the more accurate meaning of that character in the sentence.(If you understand this sentence, you can actually skip the rest.)
At this point, we need to start delving into some technical details. Before we begin, it is necessary to familiarize ourselves with a core concept in the field of machine learning—”vector.” In the digital age, the smallest unit of mathematical operations is often natural numbers. But in the AI age, this smallest unit has become a vector. This is one of the most important differences between the digital age of computation and the intelligent age.
For example, in a bank, to determine a person’s credit limit, we use a vector to represent it:
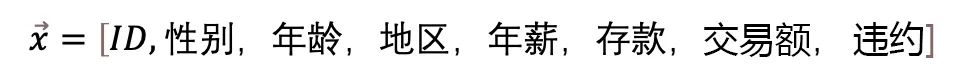
A vector is a collection of data and can also be imagined as a point in a very high-dimensional space. A specific credit limit vector is a point in an 8-feature high-dimensional space. Data in high-dimensional space will exhibit more mathematical properties, such as linear separability, making it easier for us to grasp more hidden rules.
The addition, subtraction, multiplication, and division of vectors are the main computational logic for computers during sample training. The Fourth Paradigm has always emphasized high-dimensionality, real-time, and self-learning, where high-dimensionality refers to elevating enterprise information to a very high-dimensional space, transforming it into vectors.
The main significance of the Transformer model is that it found an algorithm that progressively locates a word into a high-dimensional space in three steps, endowing that word with more optimal information than other algorithms.In many cases, this high-dimensional space has different meanings. Once the information endowed to this vector is more accurate and closer to the real situation, subsequent machine learning work can unfold easily. Let’s take the earlier credit limit vector as an example:
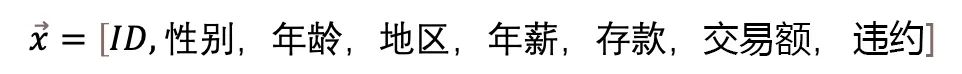

These two vectors exist in two different vector spaces, and the main difference is that the former has an additional vector feature: “annual salary.” Consider whether “annual salary” is a very important influencing factor when determining a person’s credit limit?
The above example is still quite simple, as it only adds one feature value. In the Transformer, it is much more complex, as it needs to combine multiple vector information through matrix addition, subtraction, multiplication, and division to endow a vector with new meanings.
Now that we understand the importance of vectors, let’s return to the three steps of the Transformer, which are: 1. Encoding (Embedding); 2. Positioning (Positional encoding); 3. Self-Attention Mechanism (Self-Attention), which is indeed very famous.
For example, let’s translate the sentence “Smart John is singing” into Chinese.
First, we need to vectorize each word in the sentence.
We first look at the word “John”; we need to convert the arrangement of the letters in “John” into a 512-dimensional vector for John, so that the computer can begin to recognize it. This indicates that John is a point in this 512-dimensional space; this is the first step: Encoding (Embedding).
Next, in the second step, Positioning (Positional encoding). Using the following formula (this is the innovation of this paper):
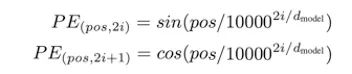
Fine-tuning a new high-dimensional space generates a new vector:

We need not worry too much about this formula; its core significance is that in this new vector, each position originally represented by 0 and 1 is replaced by sin and cos, allowing this new vector to not only represent the meaning of the word John but also to convey John’s positional information in the sentence “Smart John is singing.”
If you don’t understand, you can ignore it; just remember that the second step is used to add positional information to the vector expressing the word “John.” John is no longer an isolated word but a word within a specific sentence, although we still don’t know what the meanings of the other words in the sentence are.
If the computer understands what John is in the first step, in the second step, it understands “* John**”.
Finally, in the third step, the Self-Attention Mechanism uses an Attention (Q, K, V) algorithm to place John into a new space of information, which we denote as:
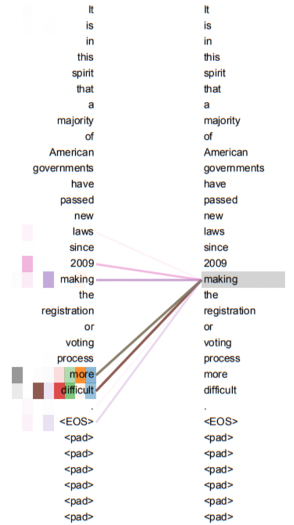
In this new vector, it not only contains the meaning of John, the positional information of John in the sentence, but also the relationship and value information between John and every other word in the sentence. We can understand that John as a word is general, but Smart John is much more specific, and singing Smart John is even closer. Moreover, the Attention (Q, K, V) algorithm does not compute based on a single word’s surroundings but calculates the word’s relationship with every other word in the sentence, adjusting its position in space through this computation.
This method can be advantageous in very long sentences, and crucially, it breaks through the barriers of sequential order. Previously, the division between image and NLP algorithms was largely due to the obvious sequential features of NLP, where each word has a clear sequential relationship with the next. However, the Transformer algorithm breaks this constraint; it pays more attention to the value weight of a word in relation to every other word in the sentence. This is the main reason why the Transformer can be applied everywhere.
Computational Process
If you are not interested, you can skip this part and directly go to the insights and gains section.
The specific computational process can be illustrated using the translation of the sentence “我爱你” to “I love you” (this sentence is simpler). First, vectorize and absorb the positional information of the sentence to obtain an initial vector set for the sentence.
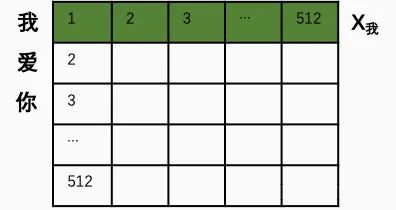
Since the length of each sample sentence varies, each sentence will be represented as a 512*512 matrix. If the length is insufficient, it is replaced with 0. Thus, during training, regardless of how long the sentence is, it can be represented by a matrix of the same scale. Of course, 512 is a hyperparameter that can be adjusted before training.
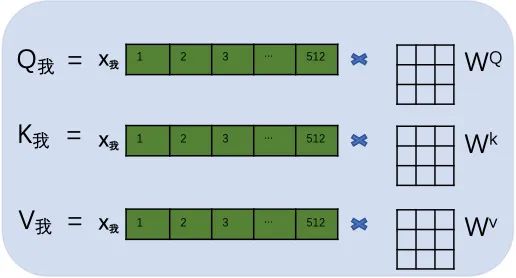
Next, the initial vector of each character is multiplied by three randomly initialized matrices WQ, Wk, and Wv to obtain three quantities Qx, Kx, and Vx. The following diagram illustrates this using the character “我”.
Then, calculate the attention value for each word; for example, the attention value for the character “我” is obtained by multiplying the Q我 of the character “我” by the K values of the other words in the sentence. The mathematical meaning of multiplying two matrices is to measure the similarity between the two matrices. Then, through a SoftMax transformation (don’t worry about how to compute it), the weight of “我” with each word is calculated, and the sum of all weights must equal 1. Finally, multiply each weight by the corresponding V value. The sum of all products yields the attention value.
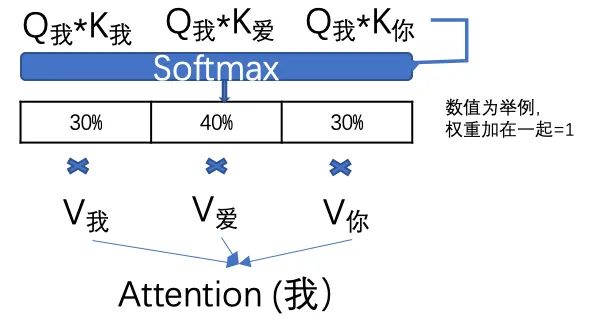
This attention value is the successful acquisition of the relevance information of each word in the sentence, in addition to the inherent information and positional information of the character “我”.
You may notice that in the calculation logic of all attention coefficients, only the initial matrices WQ, Wk, and Wv for each character are unknown (these three matrices are shared by all characters). Thus, we can simplify this Transformer into an equation concerning input, output, and the W matrix: where X is the input text information, and Y is the translation information.
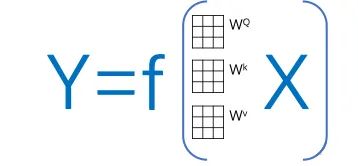
It is necessary to introduce some basic knowledge of machine learning here: The Transformer algorithm is essentially a feedforward neural network model. Its computational logic does not concern complex hidden layers; it assumes Y=f(x)=wx (the goal is still to calculate an f()). A random w0 is initially set to compute the cost function of y=w0x, and then w0 is changed to w1 to compute the cost function of y=w1x, and so forth, calculating numerous w (not infinitely, it will converge), and then comparing which w has the smallest cost function is the f() we have trained. In the Transformer, these three initial matrices are that w0.
Returning to the Transformer, after computing Attention, each word is placed into a new high-dimensional space based on semantic relationships, which is the Self-Attention (自注意力机制).
However, in the Transformer, it does not just input a single space; rather, it inputs multiple high-dimensional spaces, known as the multi-head attention mechanism.
The article does not provide clearer theoretical support for why it is multi-head.
The main reason is that it performs very well during training.This is also a characteristic of AI research papers; they often discover certain directions based on high research literacy and sensitivity, and through testing, they prove effective, but they may not provide perfect theoretical support. This often leaves space for subsequent researchers to improve upon.
It has been proven that how to enhance the efficiency of Attention (Q, K, V) is the fastest evolving part of the Transformer field. Subsequently, the Bert algorithm proposed a pre-training mechanism that became mainstream, which will be further introduced later.
Of course, in retrospect, we can understand that this method places the logical relationships within the sentence into different high-dimensional spaces for training, intending to capture more information. This part allows for a deeper understanding of how researchers apply space.
In addition to the above content, there are some technical points such as the Mask mechanism, layer norm, and neural network activation function saturation control, which will not be introduced one by one due to space limitations and because they belong to technical details.
If everyone understands the multi-head self-attention mechanism, you have basically grasped 85% of the important content of this paper and have a more intuitive understanding of the rapidly expanding impact of the Transformer model.
Insights and Gains
From the perspective of theoretical scientific progress:
- The Transformer breaks the logic of sequential computation, quickly goes mainstream, and begins to integrate multiple previously independent AI fields on a technical level. Looking deeper, one important reason why the Transformer can break through sequentiality is that the parallel computing power model provides the possibility of cost-effectiveness for more complex computations. Further improvements in computing power will inevitably lead to integration in various subfields of AI, and more foundational infrastructure-level models and algorithms will continue to be introduced. The division of labor in AI in the fields of image, NLP, and cognition will gradually become blurred.
- AI research indeed has some experimental nature. Besides the core ideas, many solutions to technical points are already clear, but there is still significant room for improvement. It can be anticipated that micro-innovations surrounding the Transformer will continue to accelerate and prosper.
-
“Attention is All You Need” is famous in the industry, but if you look closely, you will find that much of its content is also borrowed from existing ideas; for example, the most important Attention (Q, K, V) where Query, Key, and Value are standard methodologies for Internet recommendation systems; the entire Transformer algorithm is also a large neural network that has iteratively developed step by step based on predecessors, but this iteration speed is obviously accelerating.
From the perspectives of theory, algorithms, architecture, and engineering:
The AI algorithm research field is undergoing a growth flywheel of algorithms, open-source code, engineering, and computing power.
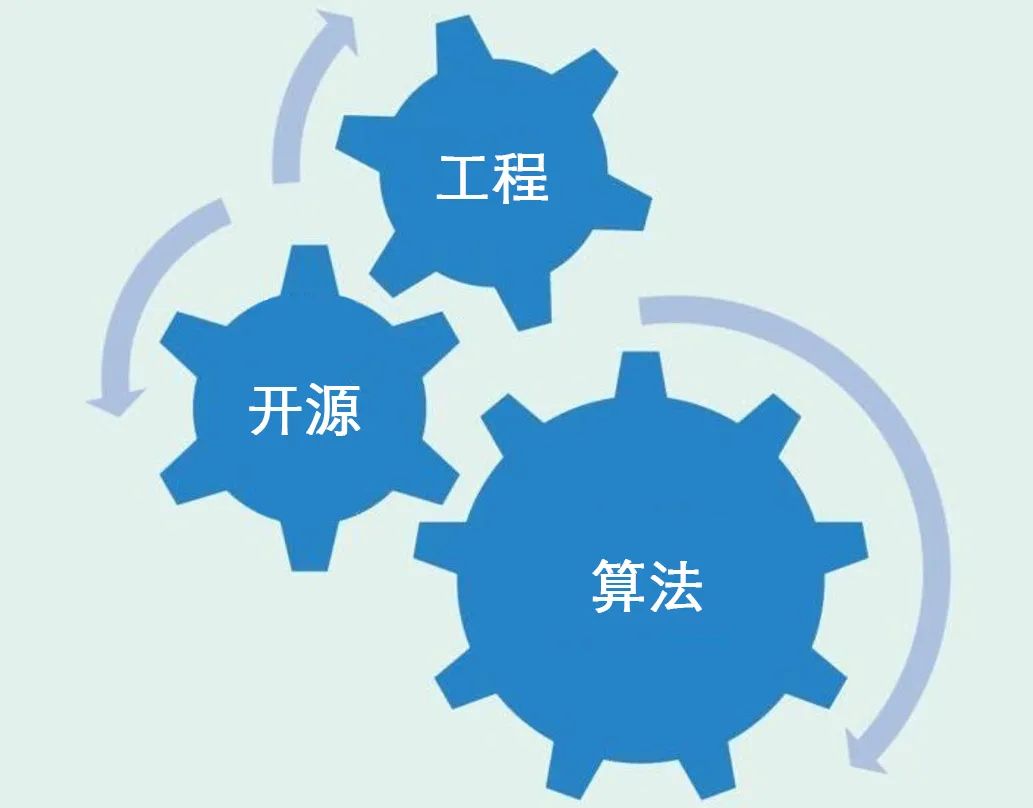
The following diagram shows the proportion of open-source papers in top journals, which has been growing at an accelerated rate in recent years. The research process and engineering process are increasingly intersecting. The open-source community and open-source culture themselves are also driving the rapid development of algorithms and engineering.
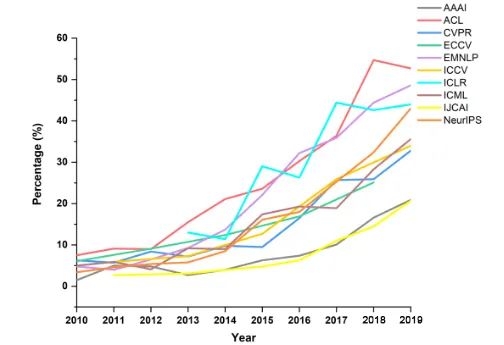
With more people participating and more people from various fields getting involved, the entry barrier is gradually lowered with the decreasing cost of computing power, AI infrastructure, and code, and knowledge sharing through open-source. The boundaries between research and engineering are also becoming blurred, akin to the rules of football; as the number of football players increases, the probability of genius players like Messi emerging will also increase.
From the perspective of data and subsequent solution development:
The success of ChatGPT is greatly attributed to extensive data training; however, besides simple dialogue interactions or translations, there is still a severe lack of sample data for lengthy answers or even paper-level responses (the sample data required for algorithm training needs clarity in X and Y).
Moreover, the Transformer algorithm requires a larger data volume compared to other algorithms because it needs to randomly generate three matrices in the initial stage and optimize them step by step. Besides the Transformer, another important phenomenon-level technology is Bert, which is a simplified Transformer. Bert does not translate from A to B; instead, it randomly masks some words or sentences in X to optimize predictions for the masked parts. This approach has made Bert the best partner for pre-training Transformers.
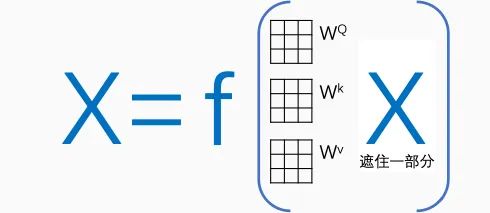
If pre-training is conducted through Bert, it is equivalent to adding prior knowledge to the matrix (the previous training logic did not provide any hints to the machine, while the latter provided basic knowledge), improving the accuracy of the initial matrices during formal training, which greatly enhances the subsequent computational efficiency of the Transformer and its data volume requirements.
In reality, for example, if I want to train a national library’s books, previously I would need information about each book and explanations for them, or the corresponding English books for Chinese ones. But now we can train content in bulk without needing to label it; later, we just need to fine-tune the sample data using the Transformer. This gives ChatGPT a significant advancement space, and it can be anticipated that more such large models will quickly emerge like mushrooms after rain.
Since the Transformer is a more advanced deep learning algorithm with high data requirements, it has also spurred algorithms for quickly generating large data from small data, such as GAN adversarial networks. This is a core technology in the AIGC field. Solving the issue of insufficient data volume not only involves more efficient abstraction of small data information but also introduces methods for supplementing small data into large data, and these methods are maturing rapidly.
We find that there are many hyperparameters in machine learning algorithms, such as the number of heads needed for the multi-head mechanism in the Transformer, whether the text turns into a vector of 512 or more, learning rates, etc., all of which need to be set before training. Due to the long training time and complex parameters, exploring more optimal computational outcomes requires a very long time of trial and error.
This has led to the emergence of AutoML; the Fourth Paradigm has been researching this field for many years, taking the Transformer as an example, and many routes for automated machine learning are pursued; for instance, Bayesian computation (finding better parameter configuration probabilities); reinforcement learning approaches (greedy algorithms quickly approaching the optimal in uncertain environments); and seeking entirely new training networks (using combinations of Transformer, RNN, MLP, etc.) and so forth.
Research and development emphasizes parameterization, while industrial development emphasizes automation; these two may seem unified, but in practical operations, they often represent considerable painful contradictions. This is also an important area for balancing productization and the fluidity of research mentioned at the beginning.
Editor: Huang Jiyan
Proofreader: Lin Yilin
