
Click the above “Beginner’s Guide to Vision” and choose to add “Star” or “Pin“
Important insights delivered at the first moment
Important insights delivered at the first momentScan the QR code below to join the cutting-edge academic paper exchange group!Get the latest top conference/journal paper idea interpretations and PDF interpretations!And materials from beginner to advanced in CV, and the most cutting-edge applications!


1. Paper Information
 1Paper Title::SwiftFormer: Efficient Additive Attention for Transformer-based Real-time Mobile Vision ApplicationsChinese Title: SwiftFormer:针对基于Transformer的实时移动视觉应用的高效加性注意力Paper Link:https://openaccess.thecvf.com/content/ICCV2023/papers/Shaker_SwiftFormer_Efficient_Additive_Attention_for_Transformer-based_Real-time_Mobile_Vision_Applications_ICCV_2023_paper.pdfOfficial GitHub:https://github.com/Amshaker/SwiftFormerAffiliated Institutions:Mohammed Bin Zayed University of AI, University of California Merced, Yonsei University, Google Research Center, Linköping UniversityKeywords:SwiftFormer, Transformer, Self-attention, Mobile Vision Applications, Real-time Performance, Hybrid Design
1Paper Title::SwiftFormer: Efficient Additive Attention for Transformer-based Real-time Mobile Vision ApplicationsChinese Title: SwiftFormer:针对基于Transformer的实时移动视觉应用的高效加性注意力Paper Link:https://openaccess.thecvf.com/content/ICCV2023/papers/Shaker_SwiftFormer_Efficient_Additive_Attention_for_Transformer-based_Real-time_Mobile_Vision_Applications_ICCV_2023_paper.pdfOfficial GitHub:https://github.com/Amshaker/SwiftFormerAffiliated Institutions:Mohammed Bin Zayed University of AI, University of California Merced, Yonsei University, Google Research Center, Linköping UniversityKeywords:SwiftFormer, Transformer, Self-attention, Mobile Vision Applications, Real-time Performance, Hybrid Design
2. Paper Summary

Highlight
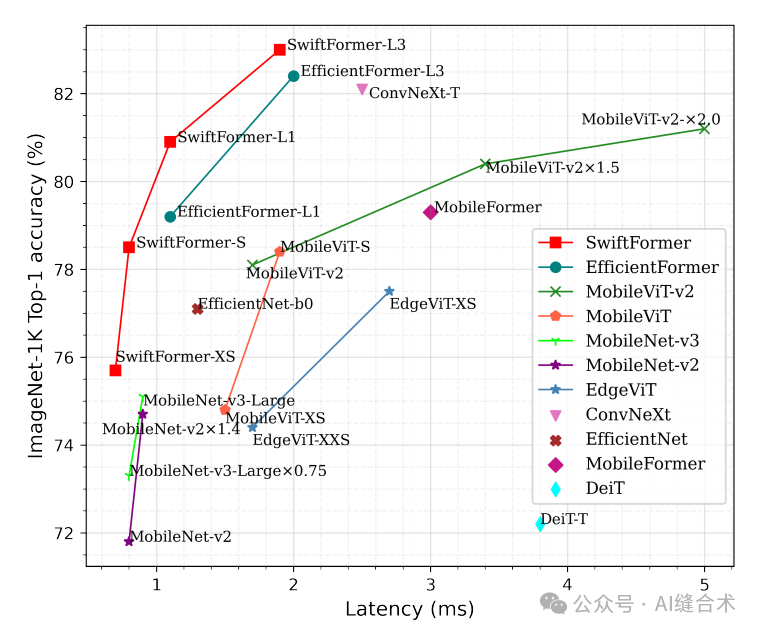 Figure 1: Comparison of delay and accuracy. Compared to the recent EfficientFormer-L1, our SwiftFormer-L1 achieves an absolute improvement of 1.7% in top-1 accuracy at the same delay without any neural architecture search.
Figure 1: Comparison of delay and accuracy. Compared to the recent EfficientFormer-L1, our SwiftFormer-L1 achieves an absolute improvement of 1.7% in top-1 accuracy at the same delay without any neural architecture search. Figure 4: Example of object detection and instance segmentation on the COCO 2017 validation set. The SwiftFormer-L1 model can accurately detect and segment instances in the image. Figure 5: Qualitative example of semantic segmentation on the ADE20K validation set. Top image: real masks. Bottom image: semantic segmentation results. Our model can accurately segment various indoor and outdoor scenes.
Figure 4: Example of object detection and instance segmentation on the COCO 2017 validation set. The SwiftFormer-L1 model can accurately detect and segment instances in the image. Figure 5: Qualitative example of semantic segmentation on the ADE20K validation set. Top image: real masks. Bottom image: semantic segmentation results. Our model can accurately segment various indoor and outdoor scenes.
Research Background:
- Self-attention Mechanism in Visual Applications: The self-attention mechanism has become the default choice for capturing global context in various visual applications. However, its quadratic computational complexity with respect to image resolution limits its use in real-time applications, especially when deployed on resource-constrained mobile devices.
- Proposal of Hybrid Methods: To combine the advantages of convolution and self-attention, hybrid methods have been proposed to achieve better speed-accuracy trade-offs. However, the expensive matrix multiplication operations in self-attention remain a bottleneck.
- Need for Efficiency Improvements: Developing more efficient and flexible models that combine the advantages of CNNs and Transformers is particularly important for platforms with limited computational resources, such as mobile devices.
Contributions of this Paper:
- Efficient Additive Attention: A new efficient additive attention mechanism is proposed that effectively replaces quadratic matrix multiplication operations with linear element-wise multiplication. This significantly reduces the computational complexity of the model without sacrificing any accuracy.
- SwiftFormer Architecture: Based on EfficientFormer, SwiftFormer is proposed by introducing 4D MetaBlocks and 3D MetaBlocks, used for learning local representations and encoding global context, respectively. Utilizing the proposed efficient additive attention, a series of models named “SwiftFormer” are constructed, achieving state-of-the-art performance in both accuracy and mobile inference speed. The small version achieves 78.5% top-1 accuracy on ImageNet-1K on an iPhone 14 with only 0.8 ms of latency, being more accurate and twice as fast as MobileViT-v2.
- Overall Conclusion: SwiftFormer significantly enhances the performance of Transformer models in mobile vision applications by introducing an efficient additive attention mechanism and a consistent hybrid design. SwiftFormer not only achieves new state-of-the-art levels in accuracy but also significantly improves inference speed on mobile devices, providing new possibilities for real-time mobile vision applications.
 3. Method
3. Method 1
1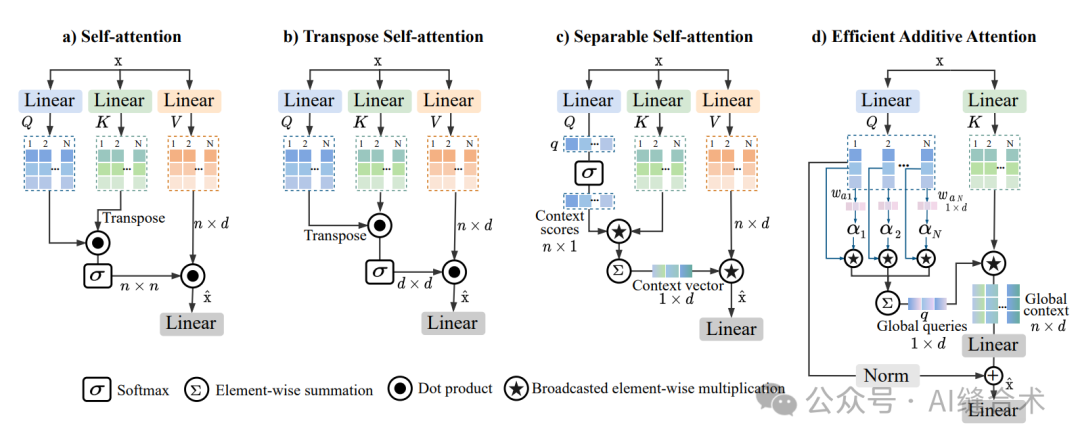 (a) is the typical self-attention used in ViTs. (b) is the transposed self-attention used in EdgeNeXt, where the self-attention operation is applied on the channel feature dimension (d×d) rather than the spatial dimension (n×n). (c) is the separable self-attention of MobileViT-v2, which computes the context vector from the interaction of Q and K matrices using element-wise operations. The context vector is then multiplied by the V matrix to produce the final output. (d) is the efficient additive self-attention we propose. Here, the query matrix is multiplied by learnable weights and pooled to produce a global query. The matrix K is then element-wise multiplied by the broadcasted global query to obtain the global context representation.
(a) is the typical self-attention used in ViTs. (b) is the transposed self-attention used in EdgeNeXt, where the self-attention operation is applied on the channel feature dimension (d×d) rather than the spatial dimension (n×n). (c) is the separable self-attention of MobileViT-v2, which computes the context vector from the interaction of Q and K matrices using element-wise operations. The context vector is then multiplied by the V matrix to produce the final output. (d) is the efficient additive self-attention we propose. Here, the query matrix is multiplied by learnable weights and pooled to produce a global query. The matrix K is then element-wise multiplied by the broadcasted global query to obtain the global context representation.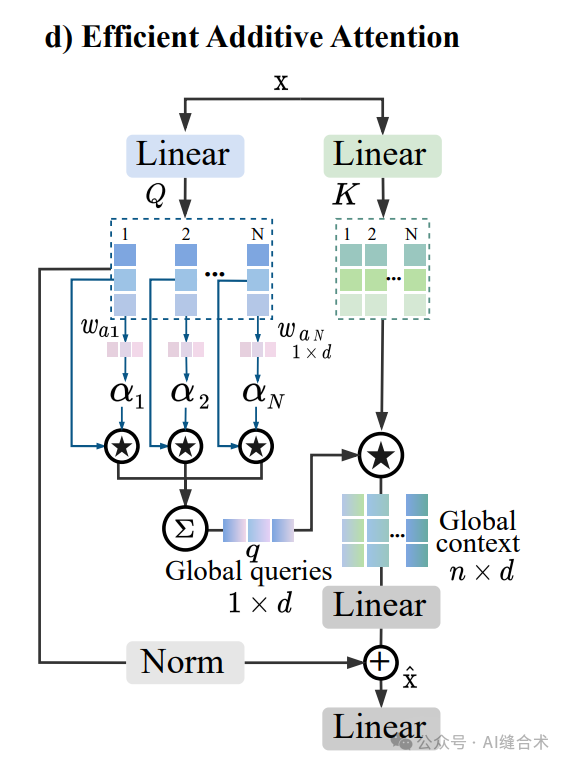 Figure d: Efficient additive self-attention.
Figure d: Efficient additive self-attention.
Efficient Additive Attention avoids expensive matrix multiplication operations, reducing computational complexity from quadratic to linear, allowing the self-attention mechanism to be used at all network stages without significantly increasing computational burden. This makes Efficient Additive Attention particularly suitable for real-time visual applications on resource-constrained mobile devices. Implementation process:
1. Input Embedding: The input feature matrix x is transformed into query (Query) and key (Key) matrices Q and K using two matrices Wq and Wk, where Q,K∈Rn×d, Wq,Wk∈Rd×d, n is the length of the tokens, and d is the dimension of the embedding vector.
2. Global Query Vector: The query matrix Q is multiplied by a learnable parameter vector wa to learn the attention weights of the queries, producing a global attention query vector α. This process can be represented as α=Q·wa/√d.
3. Pooling Operation: The query matrix Q is pooled based on the learned attention weights to obtain a single global query vector q.
4. Key-Global Query Interaction: The global query vector q and the key matrix K interact using element-wise multiplication to form a global context representation. This process can be represented as x=Q+T(K*q), where T represents a linear transformation.
5. Output Representation: The final output representation is the sum of the query matrix Q and the global context representation learned through linear transformation.
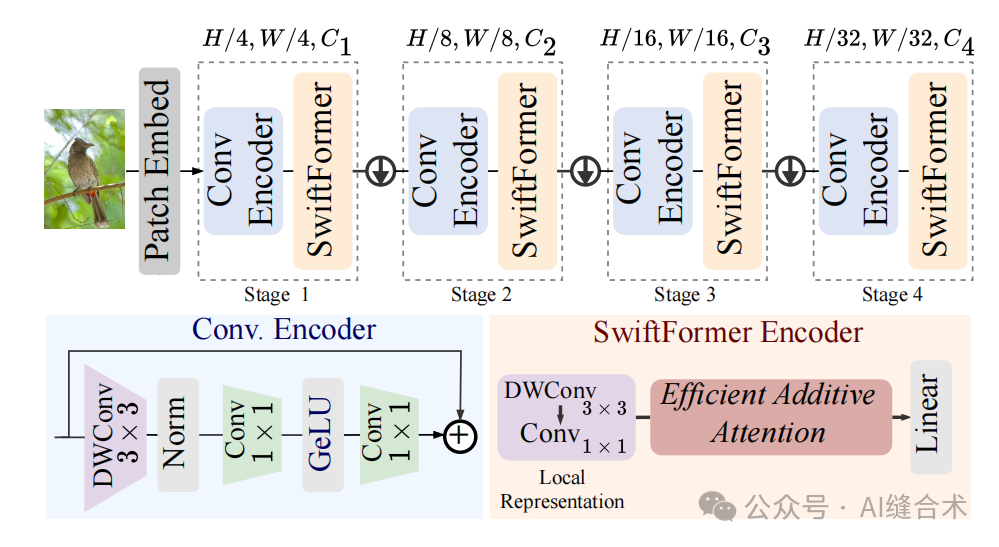
Figure 3: Top row: Overview of our proposed architecture. The input image is sent to the patch embedding layer, followed by four different scales of hierarchical stages {1/4,1/8,1/16,1/32}. Each stage is consistent and consists of convolution encoder blocks followed by SwiftFormer encoders. Between two consecutive stages, we add down-sampling layers to reduce spatial dimensions by half and increase feature dimensions. Bottom row: We show the designs of the convolution encoder (left) and SwiftFormer encoder (right). The convolution encoder is designed to learn effective local representations and consists of 3×3 depthwise separable convolutions followed by two pointwise convolutions for channel mixing. The SwiftFormer encoder is designed to learn rich local-global representations. It starts with local convolution layers to extract local features, followed by the efficient additive attention module (see Figure 2 (d)) and linear layers.
4. Experimental Analysis 1. ImageNet-1K: Experiments for image classification tasks. The experimental results show that the SwiftFormer model achieves excellent performance on the ImageNet-1K dataset, with the SwiftFormer-L1 model achieving a latency of 1.1 milliseconds and a Top-1 accuracy of 80.9% on the iPhone 14. Additionally, other variants of SwiftFormer also achieve superior performance on ImageNet-1K compared to models like MobileViT-v2 and EfficientFormer.
1. ImageNet-1K: Experiments for image classification tasks. The experimental results show that the SwiftFormer model achieves excellent performance on the ImageNet-1K dataset, with the SwiftFormer-L1 model achieving a latency of 1.1 milliseconds and a Top-1 accuracy of 80.9% on the iPhone 14. Additionally, other variants of SwiftFormer also achieve superior performance on ImageNet-1K compared to models like MobileViT-v2 and EfficientFormer.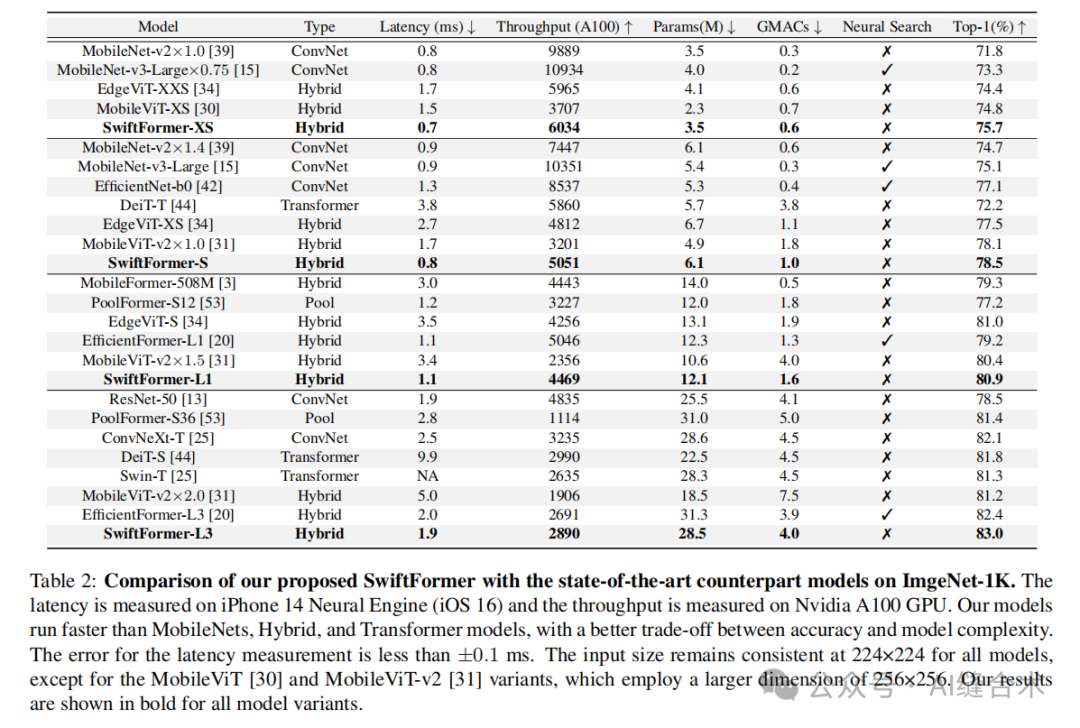 2. MS-COCO 2017: Experiments for object detection and instance segmentation tasks. The SwiftFormer-L1 model achieved 41.2 AP box and 38.1 AP mask performance on the MS-COCO 2017 dataset, surpassing models like EfficientFormer-L1.
2. MS-COCO 2017: Experiments for object detection and instance segmentation tasks. The SwiftFormer-L1 model achieved 41.2 AP box and 38.1 AP mask performance on the MS-COCO 2017 dataset, surpassing models like EfficientFormer-L1.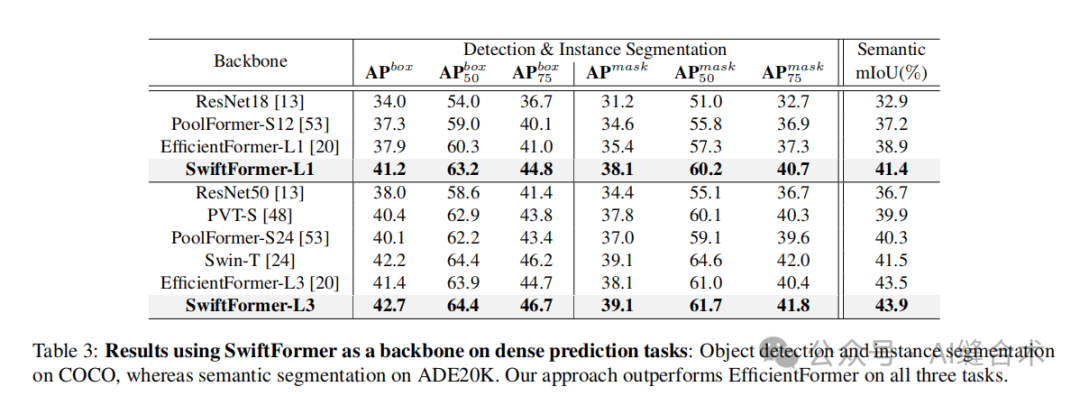 3. ADE 20K: Experiments for semantic segmentation tasks. The SwiftFormer-L1 model achieved a mean intersection over union (mIoU) score of 41.4% on the ADE 20K dataset, also surpassing models like EfficientFormer-L1.
3. ADE 20K: Experiments for semantic segmentation tasks. The SwiftFormer-L1 model achieved a mean intersection over union (mIoU) score of 41.4% on the ADE 20K dataset, also surpassing models like EfficientFormer-L1.
5. Code
 1
1 Tips:For all the code mentioned in the tweets,If the formatting of the code you copied in WeChat is messy, please copy the link to this tweet, open it in any browser, and then copy the corresponding code to run successfully in your development environment! Or go to the official GitHub repository to find the corresponding code to copy!
Tips:For all the code mentioned in the tweets,If the formatting of the code you copied in WeChat is messy, please copy the link to this tweet, open it in any browser, and then copy the corresponding code to run successfully in your development environment! Or go to the official GitHub repository to find the corresponding code to copy!
import torch
from torch import nn
import einops
# Paper Title: SwiftFormer: Efficient Additive Attention for Transformer-based Real-time Mobile Vision Applications
# Chinese Title: SwiftFormer:针对基于Transformer的实时移动视觉应用的高效加性注意力
# Paper Link: https://openaccess.thecvf.com/content/ICCV2023/papers/Shaker_SwiftFormer_Efficient_Additive_Attention_for_Transformer-based_Real-time_Mobile_Vision_Applications_ICCV_2023_paper.pdf
# Official GitHub: https://github.com/Amshaker/SwiftFormer
# Affiliated Institutions: Mohammed Bin Zayed University of AI, University of California Merced, Yonsei University, Google Research Center, Linköping University
# Keywords: SwiftFormer, Transformer, Self-attention, Mobile Vision Applications, Real-time Performance, Hybrid Design
# WeChat Official Account: AI Stitching Technology
class EfficientAdditiveAttnetion(nn.Module):
"""
Efficient Additive Attention module for SwiftFormer.
Input: tensor in shape [B, N, D]
Output: tensor in shape [B, N, D]
"""
def __init__(self, in_dims=512, token_dim=256, num_heads=2):
super().__init__()
self.to_query = nn.Linear(in_dims, token_dim * num_heads)
self.to_key = nn.Linear(in_dims, token_dim * num_heads)
self.w_g = nn.Parameter(torch.randn(token_dim * num_heads, 1))
self.scale_factor = token_dim ** -0.5
self.Proj = nn.Linear(token_dim * num_heads, token_dim * num_heads)
self.final = nn.Linear(token_dim * num_heads, token_dim)
def forward(self, x):
query = self.to_query(x)
key = self.to_key(x)
query = torch.nn.functional.normalize(query, dim=-1) #BxNxD
key = torch.nn.functional.normalize(key, dim=-1) #BxNxD
query_weight = query @ self.w_g # BxNx1 (BxNxD @ Dx1)
A = query_weight * self.scale_factor # BxNx1
A = torch.nn.functional.normalize(A, dim=1) # BxNx1
G = torch.sum(A * query, dim=1) # BxD
G = einops.repeat(
G, "b d -> b repeat d", repeat=key.shape[1]
) # BxNxD
out = self.Proj(G * key) + query #BxNxD
out = self.final(out) # BxNxD
return out
if __name__ == "__main__":
# Test input tensor
batch_size = 4
num_tokens = 64
in_dims = 512
input_tensor = torch.randn(batch_size, num_tokens, in_dims)
# Efficient Additive Attention parameters
token_dim = 256
num_heads = 2
# Initialize Efficient Additive Attention module
attention_module = EfficientAdditiveAttnetion(
in_dims=in_dims,
token_dim=token_dim,
num_heads=num_heads
)
# Move to GPU (if available)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
attention_module.to(device)
input_tensor = input_tensor.to(device)
# Forward pass
output = attention_module(input_tensor)
# Output result
print(f"Input tensor shape: {input_tensor.shape}")
print(f"Output tensor shape: {output.shape}")<span>Run Result</span>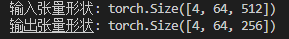
Convenient Download
https://github.com/AIFengheshu/Plug-play-modules/blob/main/(ICCV%202023)%20EfficientAdditiveAttnetion.py(
Download 1: OpenCV-Contrib Extension Module Chinese Tutorial
Reply "OpenCV Extension Module Chinese Tutorial" in the background of the "Beginner's Guide to Vision" public account to download the first Chinese version of the OpenCV extension module tutorial on the internet, covering installation of extension modules, SFM algorithms, stereo vision, object tracking, biological vision, super-resolution processing, and more than twenty chapters of content.
Download 2: Python Vision Practical Project 52 Lectures
Reply "Python Vision Practical Project" in the background of the "Beginner's Guide to Vision" public account to download 31 visual practical projects including image segmentation, mask detection, lane line detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, face recognition, etc., to help quickly learn computer vision.
Download 3: OpenCV Practical Project 20 Lectures
Reply "OpenCV Practical Project 20 Lectures" in the background of the "Beginner's Guide to Vision" public account to download 20 practical projects based on OpenCV implementation, achieving advanced OpenCV learning.
Discussion Group
Welcome to join the public account reader group to communicate with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (will gradually be subdivided in the future). Please scan the WeChat ID below to join the group, note: "Nickname + School/Company + Research Direction", for example: "Zhang San + Shanghai Jiao Tong University + Visual SLAM". Please follow the format for notes, otherwise, it will not be approved. After successful addition, you will be invited to join related WeChat groups based on research direction. Please do not send advertisements in the group, otherwise, you will be removed from the group. Thank you for your understanding~