This article is adapted from Zhihu and has been authorized by the author for reprint. Please do not reprint it again. This is a fantastic article that provides a systematic summary of the attention mechanism and a detailed interpretation of the recently released frequency domain attention method FcaNet (related introduction has garnered significant attention on our Zhihu column CV Daily, with over 6000 reads, 127 likes, and 36 discussions). I strongly recommend everyone to bookmark and read it.
Original article: https://zhuanlan.zhihu.com/p/339215696
1. Paper Information
Title: FcaNet: Frequency Channel Attention Networks
Authors: Zequn Qin et al. (Zhejiang University, Li Xi Team)
Article: FcaNet: Frequency Channel Attention Networks
https://arxiv.org/abs/2012.11879
Source code: Not officially open-sourced yet, but there are third-party implementations available. After this article is published, CV Jun will add the URLs of the third-party implementations in the comments section of this article.
2. Introduction
From the perspective of the network structure itself, we can enhance the performance of convolutional neural networks from the following four dimensions: depth (ResNet), width (WideResNet), cardinality (ResNeXt), and attention (SENet). Generally, the deeper the network, the more abstract the features extracted; the wider the network, the richer the features; the larger the cardinality, the more unique roles each convolutional kernel can play; and attention is a method that can enhance important information while suppressing unimportant information, which is the focus of this article.
This article first reviews and summarizes the more representative attention mechanism methods so far, while interpreting FcaNet. The author approaches from the frequency domain perspective, compensating for the lack of feature information in existing channel attention methods by generalizing GAP to a more general representation form, namely the 2D Discrete Cosine Transform (DCT), by introducing more frequency components to fully utilize the information. For each feature channel map, we can essentially view it as different components corresponding to the input image on different convolutional kernels, similar to time-frequency changes, relative to performing a Fourier transform on the input signal (image) through convolution operations, thus decomposing the original input into signal components on different convolutional kernels.
3. Review of Previous Work
The attention mechanism, in essence, is a set of weight coefficients autonomously learned by the network, which emphasizes the regions of interest while suppressing irrelevant background regions in a “dynamic weighting” manner. In the field of computer vision, attention mechanisms can be roughly divided into two categories: strong attention and soft attention. Strong attention is a random prediction that emphasizes dynamic changes. Although the results are good, its non-differentiable nature limits its application. In contrast, soft attention is differentiable everywhere, meaning it can be obtained through neural network training based on gradient descent methods, thus its application is relatively widespread. Soft attention can be classified into three mainstream types based on different dimensions (such as channel, spatial, temporal, category, etc.): channel attention, spatial attention, and self-attention.
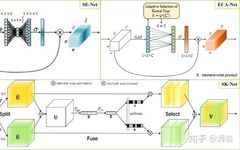
-
Channel Attention
Channel attention aims to model the correlation between different channels (feature maps) explicitly, automatically obtaining the importance of each feature channel through network learning, and finally assigning different weight coefficients to each channel to enhance important features while suppressing unimportant ones. Representative works in this area include SE-Net, which adaptively adjusts the feature responses between channels through feature recalibration. Additionally, the well-known SK-Net, inspired by both Inception-block and SE-block, considers multi-scale feature representation by introducing multiple convolutional kernel branches to learn feature map attention at different scales, allowing the network to focus more on important scale features. Another example is ECA-Net, which uses 1D sparse convolution operations to optimize the fully connected layer operations involved in the SE module, significantly reducing the number of parameters while maintaining considerable performance. To compress the number of parameters and improve computational efficiency, SE-Net adopts a “reduce-dimension-then-increase-dimension” strategy, using two multilayer perceptrons to learn the correlation between different channels, meaning that each feature map interacts with other feature maps, which is a dense connection. ECA-Net simplifies this connection method, allowing the current channel to only interact with its k neighborhood channels.
-
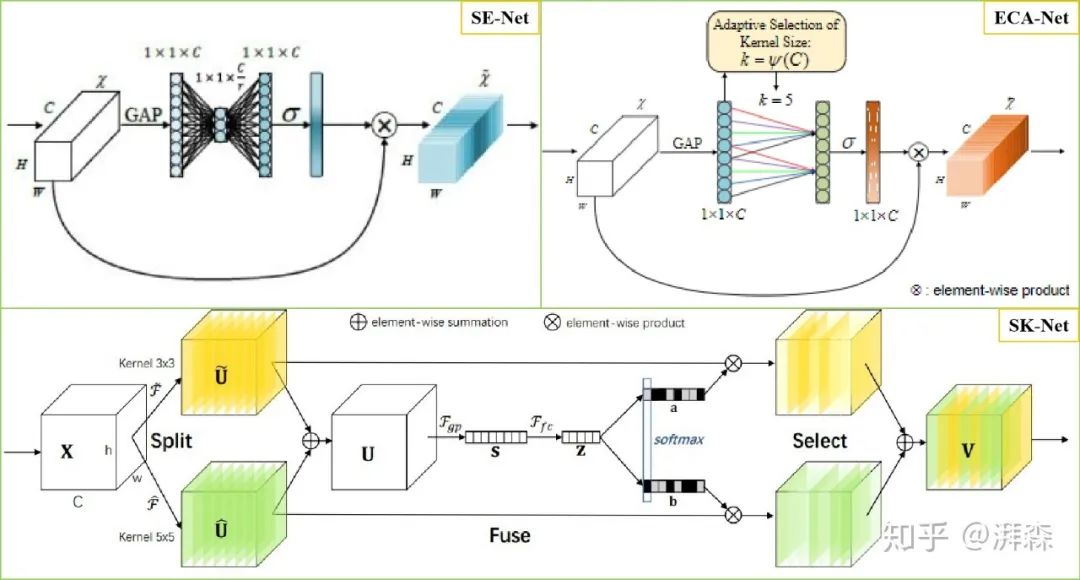
Spatial Attention
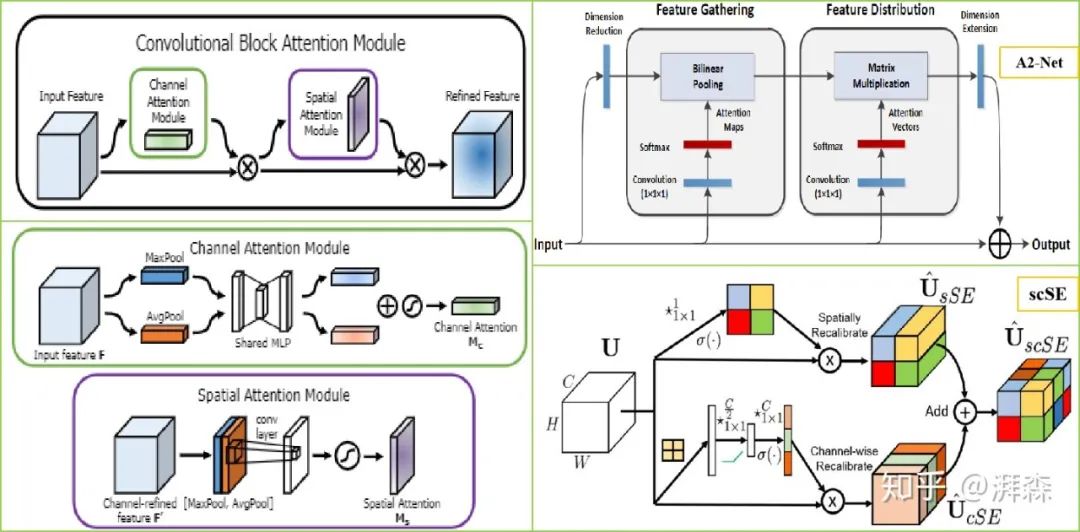
Spatial attention aims to enhance the feature representation of key regions, essentially transforming the spatial information from the original image through a spatial transformation module into another space while retaining key information, generating weight masks for each position and outputting weighted results, thus enhancing specific target regions of interest while weakening irrelevant background regions. Notable works in this area include CBAM, which connects a spatial attention module (SAM) based on the original channel attention. SAM performs global average pooling and global max pooling operations based on channels to produce two feature maps representing different information, which are merged and then fused through a large receptive field convolution of size 7×7, finally generating a weight map that is added back to the original input feature map through a Sigmoid operation, thereby enhancing the target region. Overall, for spatial attention, since each channel’s features are treated equally, it neglects the information interaction between channels; while channel attention directly processes the information within a channel globally, it easily overlooks the information interaction within the spatial domain. The author ultimately verifies through experiments that the channel-first and spatial-later approach performs better than the spatial-first and channel-later or parallel channel-space approaches. Furthermore, similar improved modules include the Double Attention module proposed by A2-Net and the variant attention module scSE inspired by SE-Net.
-
Self-Attention
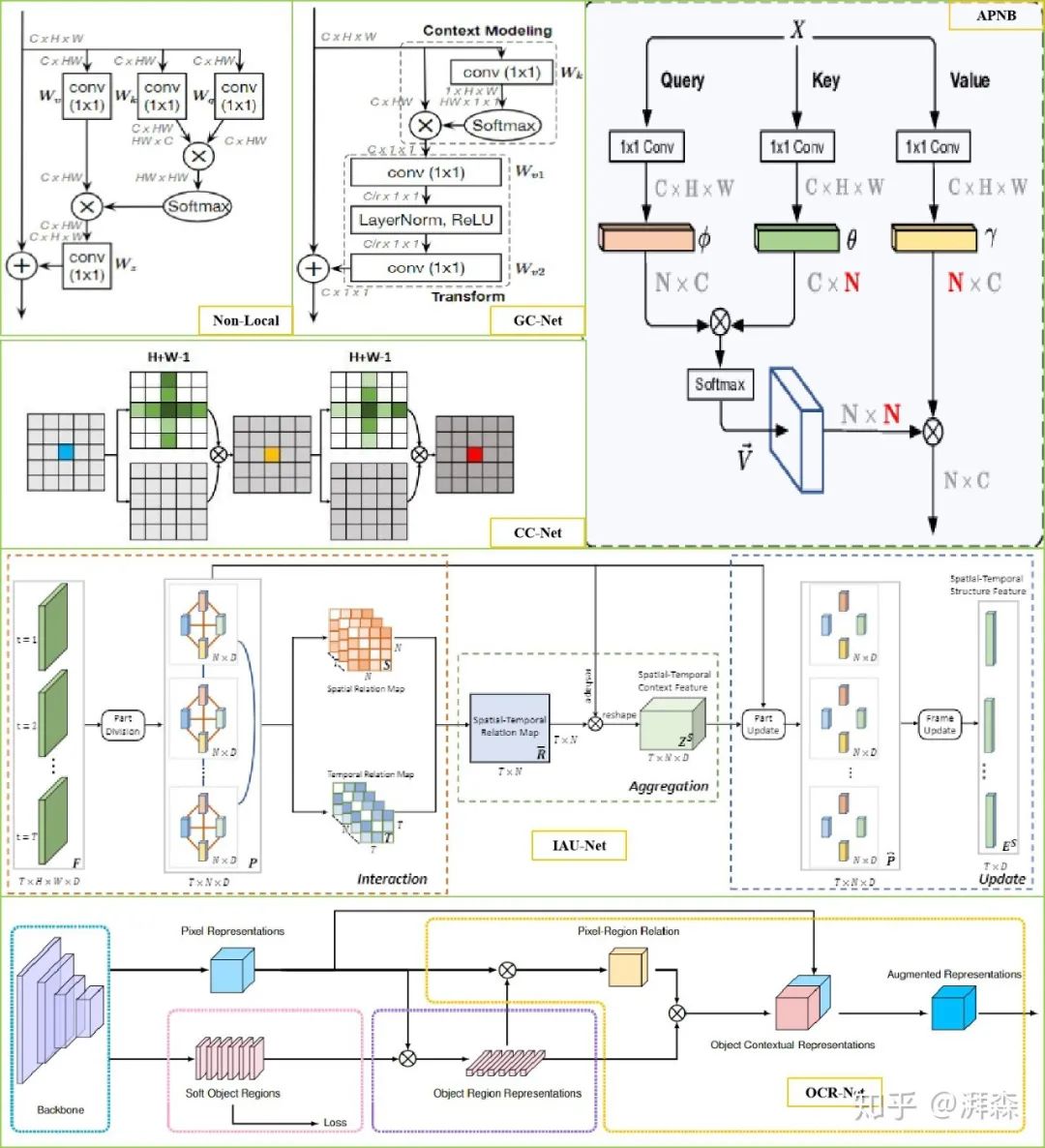
Self-attention is a variant of the attention mechanism aimed at reducing dependence on external information, maximizing the use of inherent information within the features for attention interaction. It first appeared in the Transformer architecture proposed by Google. Later, Kaiming He and others applied it to the CV field and proposed the Non-Local module, which effectively captures long-range feature dependencies by modeling global context through the Self-Attention mechanism. The general self-attention process involves mapping the original feature map into three vector branches: Query, Key, and Value. First, the correlation weight matrix coefficients of Q and K are calculated; secondly, the weight matrix is normalized through soft operations; finally, the weight coefficients are added to V to achieve modeling of global context information. Since the introduction of the NL-block, many improvements based on it have emerged. For instance, the dual attention mechanism proposed by DANet applies the NL concept to both spatial and channel domains, treating spatial pixel points and channel features as queries for context modeling. On the other hand, although NL utilizes 1×1 convolution operations to compress the dimensionality of feature maps, this pixel-to-pixel modeling approach based on global points undoubtedly incurs a huge computational cost. Therefore, many works are also dedicated to addressing this issue, such as CCNet, which develops and utilizes two cross attention modules to equivalently replace the pixel-to-pixel modeling based on global points; the Asymmetric Pyramid Non-local Block (APNB) reduces computational complexity by modeling point-to-area; GC-Net combines the SE mechanism and proposes a simplified spatial attention module to replace the original spatial downsampling process. In addition, we can further optimize it from the perspective of area-to-area modeling. Besides optimizing from spatial and channel dimensions, we can also improve from temporal and category perspectives, with works such as IAU-Net and OCR-Net.
Attention Mechanism Review in CNN
-
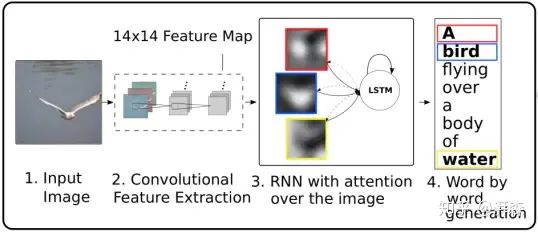
Inspired by the attention mechanism in machine translation, Bengio et al. published an article at ICML in 2015 that first applied the attention mechanism to the field of large image description (Image Caption), proposing both hard attention and soft attention mechanisms, and visually expressing the role of the Attention mechanism, paving the way for the subsequent development of attention mechanisms in the field of computer vision.
-
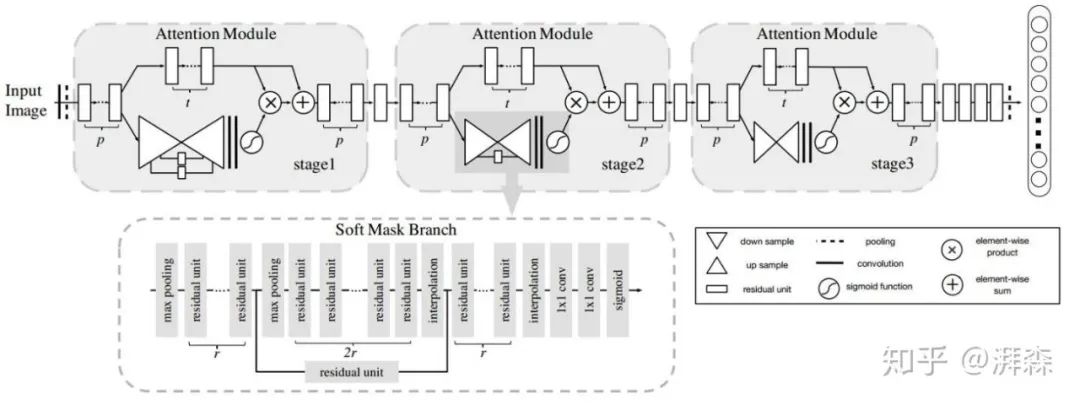
SenseTime and CUHK published an article at CVPR in 2017 proposing a residual attention network that utilizes downsampling and upsampling spatial attention mechanisms. Prior to this, most attention models were applied to image segmentation and saliency detection tasks, focusing on concentrating attention on certain areas of interest or salient regions. The authors utilized this model in conventional classification networks by introducing a side branch, which also consists of a series of convolution and pooling operations to gradually extract high-level semantic features and enlarge the network’s receptive field, ultimately upsampling this branch back to the original resolution as a feature activation map to overlay back onto the original input. Unfortunately, the improvement effect of this method seems not very significant, and the introduction of a large number of additional parameters leads to a very high computational cost.
-
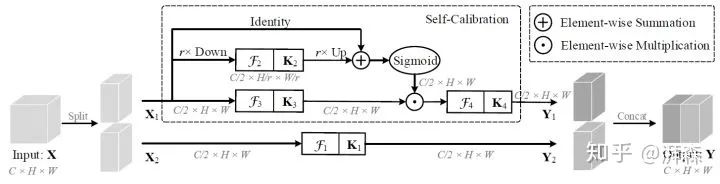
This is an article published by Cheng Mingming’s team at Nankai University at CVPR 2020, and this method of first downsampling to expand the receptive field and then upsampling back to act as an attention map is somewhat repetitive of the above paper’s idea, just migrating it from the network branch to the convolution branch. However, those familiar with Professor Cheng’s work can find that most of their work is very simple and efficient, and they advocate open-source strongly, which is admirable. Interested readers can directly visit the official website’s Publications.
-
This article is a work published by Hu’s group after SE-Net at NIPS in 2018, which proposes a more general form of SE, namely GE, from the perspective of context, using Gather and Excite, and utilizes spatial attention to better mine the contextual information between features. The Gather operation is used to extract features from local spatial locations, while the Excite operation is used to scale them back to the original size. It is a model similar to the Encoder-Decoder model, which can improve network performance with very few parameters and computational costs, but its popularity and influence seem to be far less than SE.
-
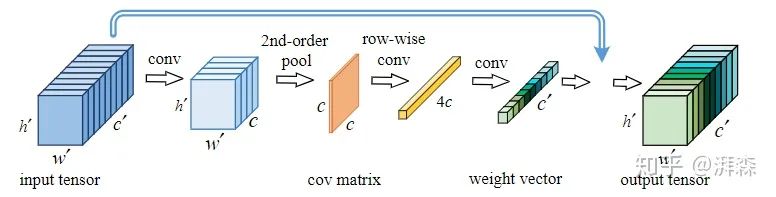
GSoP-Net is an article published at CVPR 2019, where the authors believe that the main goal of CNNs is to represent the complex boundaries of thousands of categories in high-dimensional space, and learning high-order representations is crucial for enhancing nonlinear modeling capabilities. However, traditional first-order networks clearly cannot effectively represent this, so the authors introduce global second-order pooling modules from the bottom up to capture long-distance statistical information by modeling the correlation of overall image information, fully utilizing the contextual information of the image. Unlike the 2D GAP operations advocated by SE and others, GSoP calculates the relationship between channels by introducing covariance. Specifically, after nonlinear transformation using convolution and pooling, this covariance matrix can be used to scale the tensor along the channel dimension and also along the spatial dimension. Overall, applying GSoP can fully utilize the second-order statistics in the image to efficiently capture global contextual information.
-
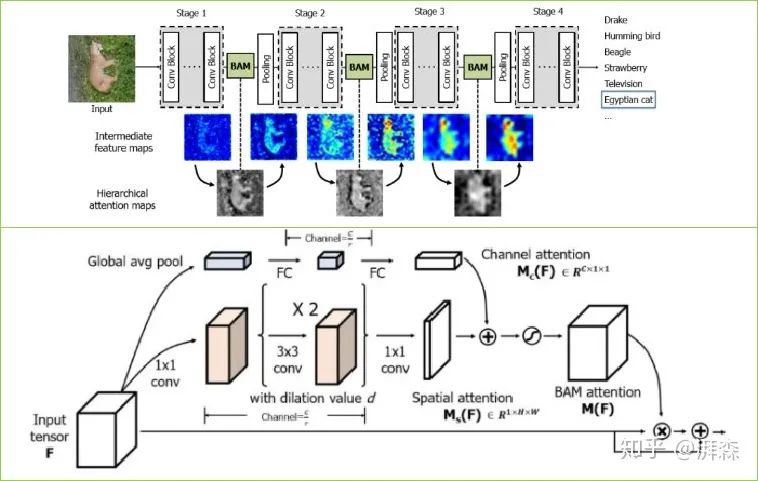
BAM is an article published at BMVC 2018, created by the same team as CBAM, where the authors propose a simple yet effective attention model that can be integrated into any forward-propagation convolutional neural network, while obtaining attention maps through two separate paths: spatial and channel. Interestingly, the authors place it in the middle of each stage of the backbone network, and through visualizing the intermediate process maps, we can clearly see that BAM forms a hierarchical attention mechanism, suppressing background features and allowing the model to focus more on foreground features, thereby enhancing high-level semantics. BAM combines two attention branches through concatenation, while CBAM is a parallel form. Similar dual attention modes include DA-Net and scSE attention, which interested readers can check out.
-
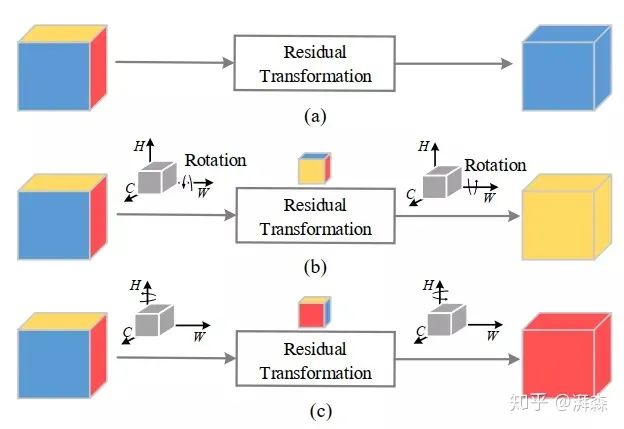
This is a recent work proposed by an Indian researcher, who approaches from the perspective of dimensional interaction, proposing a triplet attention mechanism. Traditional attention methods calculate a weight coefficient through GAP operations and then uniformly scale the original input feature map using this coefficient. However, it has been repeatedly mentioned that GAP decomposes the input tensor on a two-dimensional spatial level, condensing it into a coefficient, which inevitably leads to a large loss of spatial detail information. Moreover, simply operating on the channel can easily overlook some key information in the spatial domain. Although later BAM and CBAM alleviated the dependency relationship between channels and spatial dimensions, essentially, these two are still independent, merely concatenated or parallelized. Therefore, the Indian researcher advocates the need for information interaction between different dimensions. For example, if there are three dimensions, HWC, they should interact pairwise. However, personally, I feel this work is somewhat redundant; arbitrary dimensional interactions can sometimes disrupt the spatial consistency of information, leading to more harm than good. This work is less practical than GC-Net, which simplifies Non-local by directly combining SE operations, making it straightforward, efficient, and easy to understand.
-
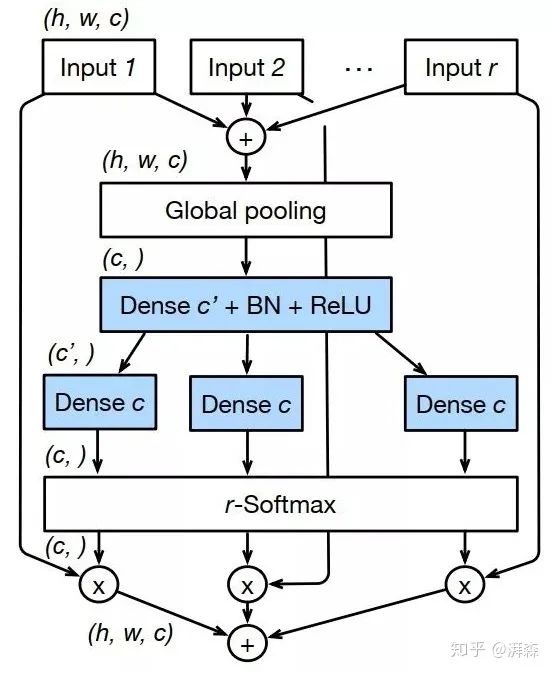
ResNeSt, touted as the enhanced version of ResNet, is an article proposed by Dr. Zhang Hang from the Li Mu team (Zhihu ID: ), where the author integrates the concept of attention into multi-branch convolution structures from the cardinality dimension to solve the issues of limited receptive fields in traditional CNNs and cross-channel information interaction. Unfortunately, it was rejected by ECCV 2020. ResNeSt maintains the “Split-Transform-Merge” structure, bearing some resemblance to SK (Zhihu ID: ), synthesizing ideas from SENet, SKNet, and ResNeXt. The results presented by ResNeSt are indeed stunning, topping the ADE20K and MS-COCO datasets, outperforming other manual network architectures without additional computational overhead, and the code is not very complicated. Although many have questioned that the performance improvement is largely related to numerous tricks and that there were some issues with the initial code implementation, it does not hinder us from learning its ideas. After all, research is different from development; engineering emphasizes “talk is cheap, show me your code,” while research emphasizes “code is weak, show me your idea.”
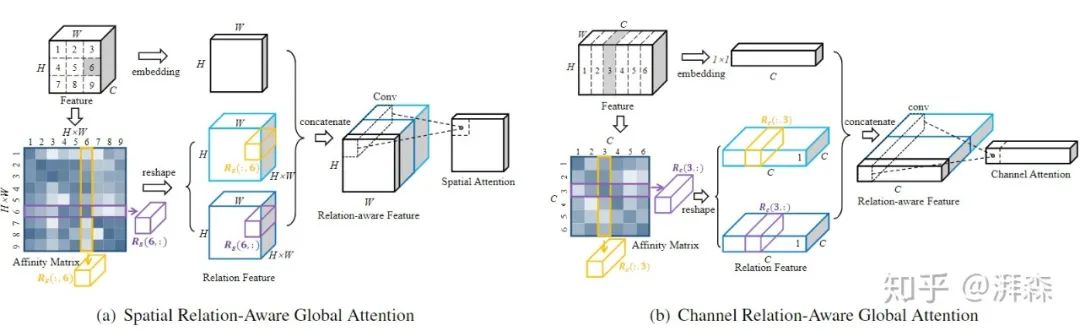
-
Relation-Aware Global Attention is a method proposed by the University of Science and Technology of China & Microsoft Research Asia at CVPR 2020 for the pedestrian re-identification task. The viewpoint advocated by this paper is that to intuitively judge whether a feature node is important, one should understand the characteristics of the global range, so that the relationship information needed for decision-making can be obtained, thereby better exploring the global relationships of each feature node and learning attention more effectively.
4. Paper Interpretation
4.1 Motivation
Generally speaking, due to limited computational resource expenditure, methods like channel attention that obtain weight functions through network learning require the calculation of scalars for each channel, and the global average pooling operation, due to its ease of use and efficiency, is undoubtedly the best choice. Nevertheless, there is a potential problem that GAP cannot capture rich input pattern information well, thus lacking feature diversity when dealing with different inputs. Consequently, a natural question arises: Is the mean information sufficient to represent the different feature channels in channel attention? The author analyzes this from three perspectives:
-
Firstly, from the perspective of feature channels themselves, different feature degrees represent different information, and the GAP operation, i.e., the “average” operation, greatly suppresses this diversity of features;
-
Secondly, from the frequency perspective, GAP is equivalent to the lowest frequency component of the Discrete Cosine Transform (DCT). Therefore, if only GAP is used, it clearly ignores many other useful frequency components;
-
Finally, supporting the argument with the viewpoint proposed in the CBAM paper, using only GAP is insufficient to express the rich information inherent in the features.
4.2 Contributions
-
Proved that GAP is a special case of DCT. Based on this, generalized GAP to the frequency domain and proposed the multi-spectral channel attention framework — FcaNet;
-
By exploring the impact of using different numbers of frequency components and their different combinations, proposed a two-step criterion for selecting frequency components;
-
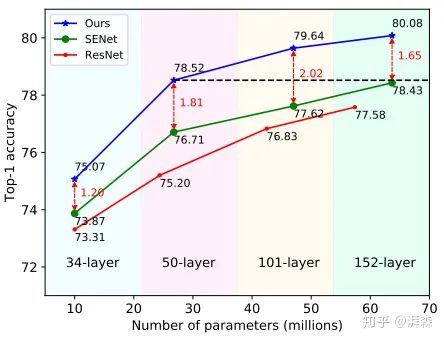
Extensive experiments show that this method achieves the best levels on both the ImageNet and COCO datasets. Based on the ResNet-50 backbone network, under the same parameter amount and computational cost, the proposed method can achieve 1.8% higher Top-1 accuracy on ImageNet compared to SENet;
-
The proposed method is not only effective but also very simple, requiring only a single line of code modification in existing channel attention implementations.
4.3 Method
4.3.1 Review of Channel Attention and Discrete Cosine Transform
-
Channel Attention:
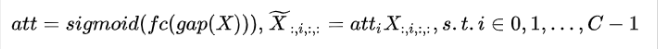
-
Discrete Cosine Transform:
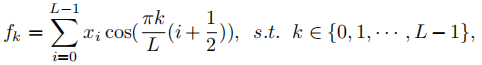
Here, 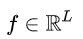 is the spectrum of DCT,
is the spectrum of DCT, 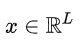 represents the input, and L is the length of the input component. Furthermore, the 2D DCT can be represented as:
represents the input, and L is the length of the input component. Furthermore, the 2D DCT can be represented as:
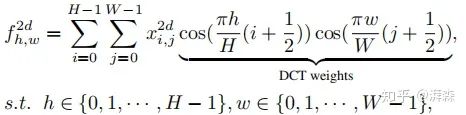
Similarly, here h and w represent the height and width of the input component, and the latter half represents the corresponding DCT weights. Accordingly, we can write its inverse transform as:
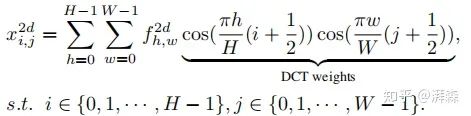
To simplify calculations and facilitate narration, the author later removes some normalization factor constants. From the above formulas, it can be seen that GAP is the preprocessing method of existing channel attention methods; while DCT can be viewed as a weighted sum of the input, where the cosine part represents its corresponding weights. Therefore, we can treat the GAP operation as the simplest frequency spectrum of the input, as mentioned, using only a single GAP is insufficient to represent all feature information, and the author will introduce the multi-spectral channel attention method below.
DCT belongs to the realm of Signal Processing and is the core algorithm in the JPEG image compression algorithm. Those who have not studied signal processing may find it a bit challenging; it is recommended to review this course briefly to understand some basic concepts and then study Fourier transform, as DCT is essentially a constrained version of the DFT of the input signal, or a special case of DFT. If you are still resistant to mathematics, you can simply think of DCT as a method to achieve better frequency domain energy concentration; in simple terms, it condenses relatively important information in the image together. The simplest understanding is that it can focus. Speaking of this, I believe everyone is somewhat enlightened; “focus” is precisely what attention does, and the author applies this idea here. Maths is important!
The author concludes here, of course, based on the separability criterion of summation, we can also rewrite the 2D DCT in the following form:
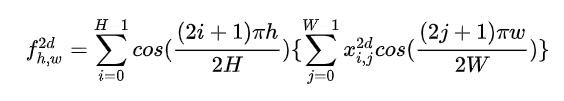
More generally, we can also write it in matrix multiplication form:
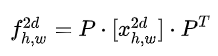
, where P is the transformation coefficient matrix.
4.3.2 Derivation of Multi-Spectral Channel Attention Framework and Criteria for Selecting Frequency Components
The author first presents a theorem: GAP is a special case of 2D DCT, and its result is proportional to the lowest frequency component of the 2D DCT.
Assuming h and w in the 2D DCT are 0, we can derive the following expression:
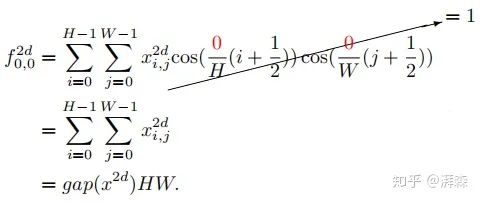
Note: cos(0)=1. The left side of the above is the lowest frequency component of the 2D DCT, which can be seen to be proportional to GAP. After proving this point, the next consideration is how to integrate other frequency components into the channel attention mechanism. Based on the above formula, we naturally rewrite the inverse transform of the 2D DCT as follows:
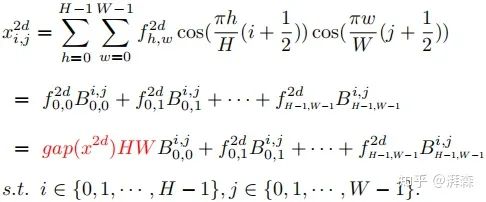
Here, B represents the frequency components, which can also be understood as the weight components of DCT. Based on the above formula, we can naturally decompose image features into combinations of different frequency components. It can be seen that the GAP operation only utilizes one of these frequency components.
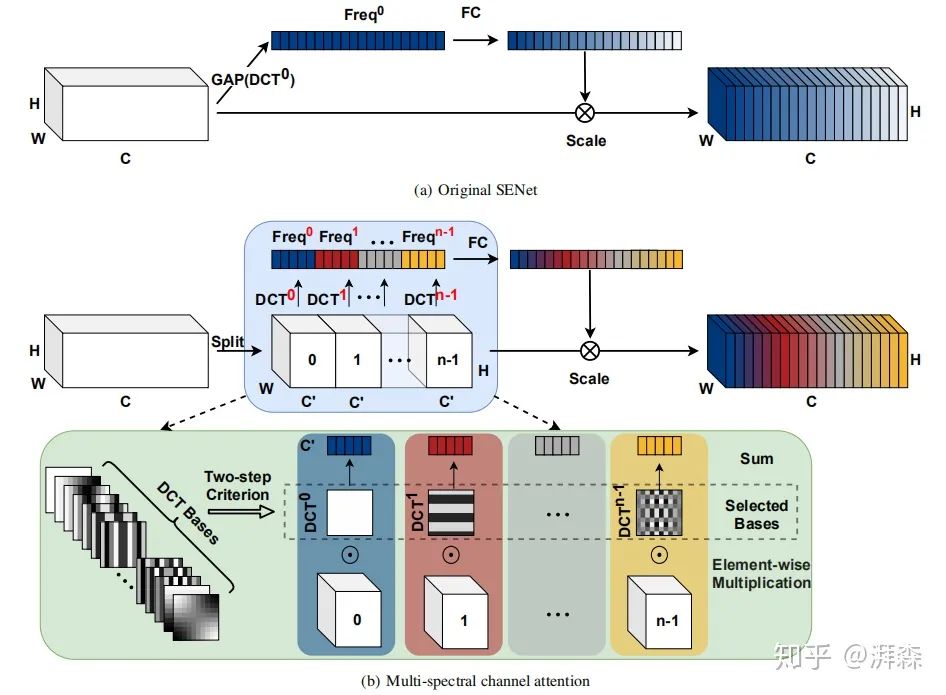
The above diagram compares the original SE module with the MCA module proposed by the author. As mentioned earlier, to introduce more information, the author suggests using 2D DCT to integrate multiple frequency components, including the lowest frequency component, i.e., GAP. The specific operation process is: first, divide the input X into n parts along the channel dimension, where n must be divisible by the number of channels. For each part, assign the corresponding 2D DCT frequency component, and the result can serve as the preprocessing result of channel attention (similar to GAP):
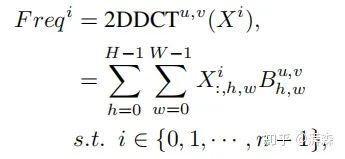
Next, we can merge the frequency components of each part:
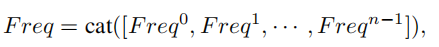
Here,  is the multi-spectral vector. Therefore, the entire MCA framework can be expressed as follows:
is the multi-spectral vector. Therefore, the entire MCA framework can be expressed as follows:
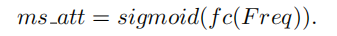
Next, let’s discuss the criteria for selecting frequency components. For each part  , the key is the selection of frequency component indices [u, v]. For each channel feature with a spatial size of
, the key is the selection of frequency component indices [u, v]. For each channel feature with a spatial size of  , we can use the 2D DCT to decompose it into
, we can use the 2D DCT to decompose it into  frequency components, thus the total number of frequency components should be
frequency components, thus the total number of frequency components should be  . For example, taking the output of the ResNet-50 backbone network as an example,
. For example, taking the output of the ResNet-50 backbone network as an example,  can reach 2048. Therefore, testing all combinations is very costly and unnecessary. The author presents a two-step criterion to select frequency components in the MCA module. The main idea is:
can reach 2048. Therefore, testing all combinations is very costly and unnecessary. The author presents a two-step criterion to select frequency components in the MCA module. The main idea is:
-
In the first step, calculate the results for each frequency component in channel attention separately;
-
In the second step, select the Top-k performance best frequency components based on the obtained results.
As for how to measure the performance of each frequency component, the author does not elaborate here. Although it is mentioned in the subsequent section 4.2 in the ablation experiments, the author simply
4.3.3 Discussion on Method Validity, Complexity Analysis, and Code Implementation
-
Discussion on Method Validity
We have analyzed that existing channel attention methods using GAP as a preprocessing method actually discard the information of other frequency components except for the lowest frequency component. The author naturally embeds more frequency component information into the MAC framework in the frequency domain. Numerous works have previously proven that there are many redundant features in CNNs, such as Ghost-Net and OctaveConv, so when two channel features exhibit high similarity, the GAP operation will yield similar results. However, in the MCA framework, different frequency components contain different information, thus allowing us to extract more information from redundant channels.
-
Complexity Analysis
The author analyzes the complexity of the proposed method from the perspectives of parameter amount and computational cost. First, since the weights involved in the 2D DCT operation are a set of constants pre-computed, there is no additional parameter amount introduced compared to original channel attention methods like SE. Secondly, in terms of computational cost, MCA only incurs a slightly higher cost than SE, which can be ignored.
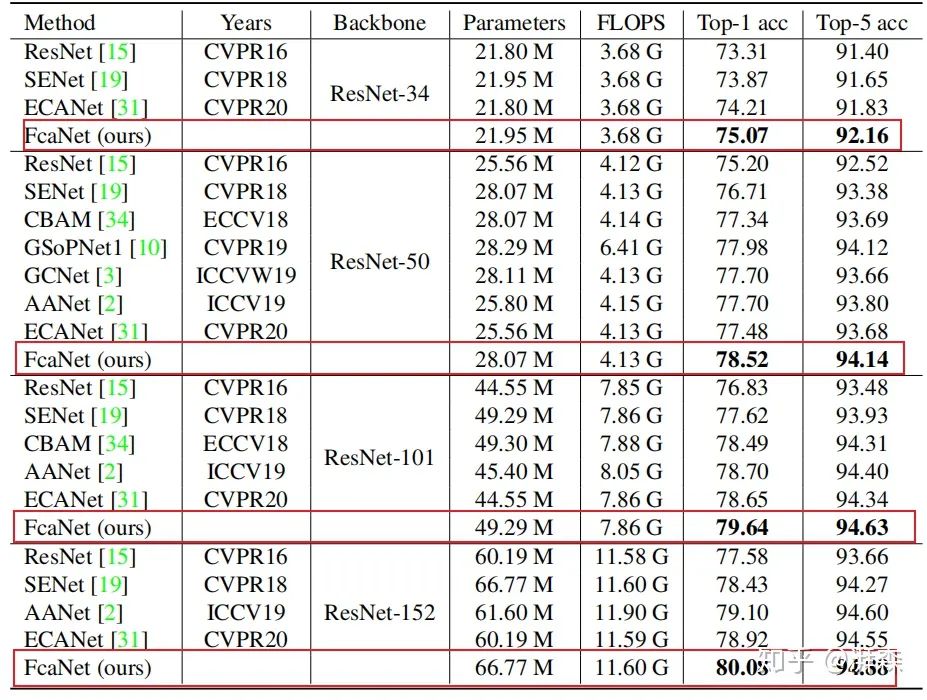
The author adds, “All other results are quoted from their original papers if available.” This raises several issues; considering the current improvements in hardware computing power, performance will likely be somewhat better, and the author also applied tricks from the articles “Deep Residual Learning for Image Recognition” and “Bag of Tricks for Image Classification with Convolutional Neural Networks” during the experimental process. To be rigorous, a fair comparison should be made under the same experimental conditions, and the results obtained would be more objective. Perhaps the relative improvement over other rivals is not a large margin but trivial contributions.
-
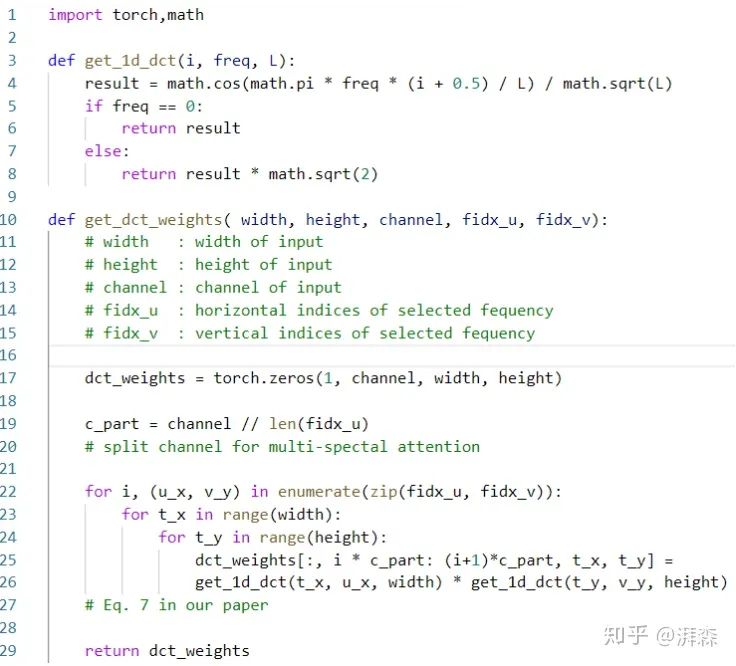
Code Implementation
The 2D DCT can be regarded as a weighted sum of the input, thus it can be implemented through simple element-wise multiplication and summation:

4.4 Experiments
4.4.1 Ablation Experiments
-
Effectiveness of Individual Frequency Components
To investigate the impact of different frequency components on channel attention, only one individual frequency component is used at a time. Considering that the smallest feature map size on ImageNet is 7×7, the author divides the entire 2D DCT frequency space into 7×7 parts, resulting in a total of 49 experimental groups. To speed up the experiments, a standard ResNet-50 network trained for 100 epochs was first used as the baseline model. Then, channel attention was added to the baseline model with different frequency components to verify its effectiveness. Subsequently, based on the same experimental setup, the added model was fine-tuned for 20 rounds with a learning rate of 0.02.
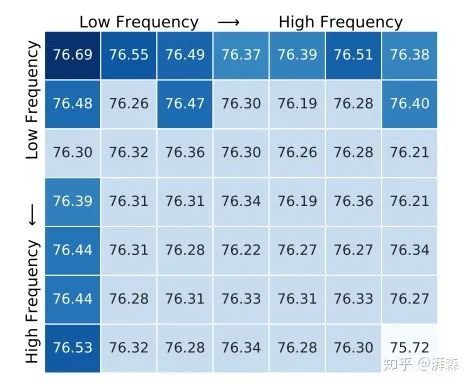
The experimental results, as described above, show that when the [u, v] component is [0, 0], the effect is the best, corresponding to SE-Net’s GAP operation, and also verifies the conclusion that DNN prefers low-frequency information. Nevertheless, the results also indicate that other frequency components contribute to the network, meaning we can embed this information.
-
Impact of the Number of Frequency Components on Performance
After obtaining the performance of each frequency component, the second step is to determine the optimal number of frequency components selected for the MCA module. For simplicity, the author selects the Top-k highest performing frequency components, where k can be 1, 2, 4, 8, 16, or 32, etc.
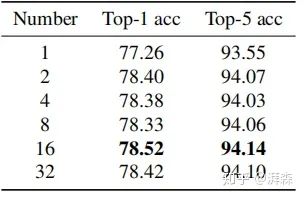
From the experimental results, it can be seen that all applications of multi-spectral results significantly outperform the pure GAP (corresponding to Number=1), with the best experimental effect observed at N=16, selecting 16 frequency components, although the overall differences are not large.
4.4.2 Comparison with Other SOTA Models
The author compares the proposed method with other mainstream channel attention models in classification, detection, and segmentation tasks:
-
In classification tasks, tests were conducted using ResNet-34, ResNet-50, ResNet-101, and ResNet-152 backbone branches, showing that Fca-Net achieves a TOP-1 accuracy that surpasses SE-NET by 1.20%, 1.81%, 2.02%, and 1.65%, respectively, across different backbone networks. At the same time, under very low computational costs, its performance also surpasses GSOPNET.
-
In detection tasks, under the premise of using Faster-RCNN and Mask-RCNN as detectors, it significantly outperforms other methods.
-
In addition to object detection, the proposed method was also tested on instance segmentation tasks, although the differences in this part were not very significant.
Appendix
-
Research on Different Frequency Component Combination Strategies
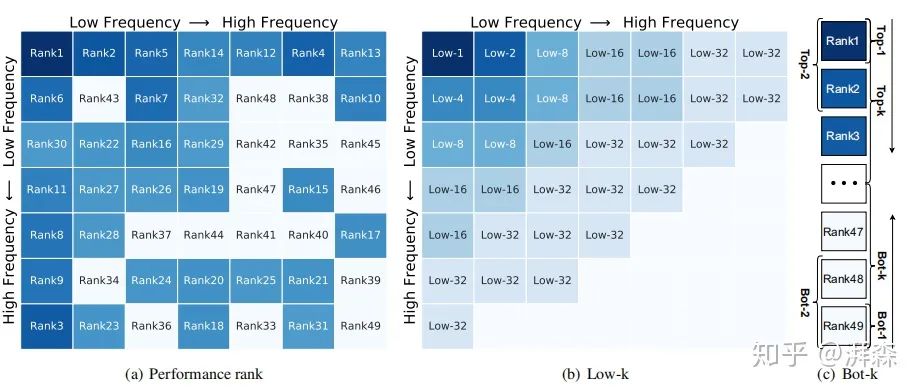
In the ablation experiment section, the second step of the author’s two-step selection criterion involves selecting the Top-k frequency components with the best performance. In the appendix, the author also conducts two other combination strategies, selecting all frequency components as shown in the upper left corner of the above figure (i.e., low-1, low-2,…, low-32); another group selects the Top-k frequency components with the worst performance:

From the experimental results, it can be seen that the Top-k performance of the worst frequency combinations is significantly lower than that of the strategy selecting low-frequency frequency components, which also fully verifies that low-frequency components are important, i.e., DNN pays more attention to low-frequency components. Of course, the optimal experimental effect is still to select the Top-k components with the best performance.
-
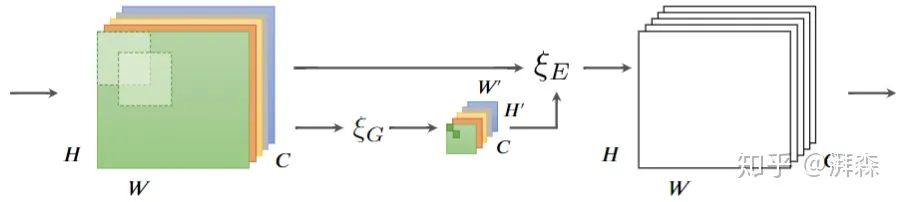
Visualization of Discrete Cosine Transform
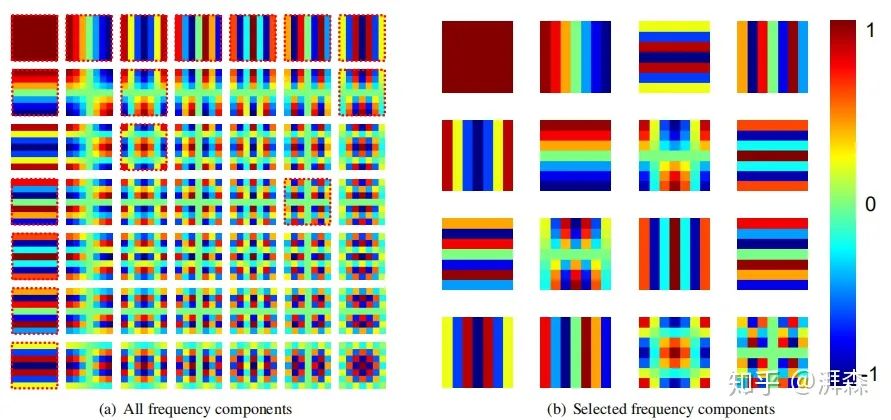
From the above image, it can be seen that the basis functions of 2D DCT are composed of regular horizontal and vertical cosine waves, which are orthogonal to each other and independent of the data. Furthermore, based on the frequency components selected by the two-step criterion, it can be observed that the selected frequency components are usually low-frequency.
-
DCT Initialization Code
Conclusion
Recently, many articles have begun to approach from the frequency domain perspective. If you are interested, you can learn about the articles proposed by Alibaba at CVPR 2020, which also seems to use DCT? Although the author has continuously emphasized that their method is very effective and requires only one line of code, based on the experimental results described, it seems that the author did not conduct controlled group experiments under uniform conditions, but directly copied the results reported in other methods’ original papers. Additionally, the claim of “one line of code” is somewhat forced, as the core code that truly works is encapsulated, merely using a simple switch for invocation, which strictly speaking should not count. Overall, the idea of this article is quite good, and regarding performance, we will wait for the source code to be made public for verification; submitting to the upcoming ICCV should be a sure thing.
To summarize, the advantages of the Attention mechanism are as follows: Few Parameters ● Fast Speed ● Good Performance.
Many of the recently published methods related to attention mechanisms are largely improvements based on the original methods, and the extent and effectiveness of these improvements are subjective. Although most of these enhancements likely stem from numerous tricks not reported or unfair due to data leakage, or clever selection of experimental comparison objects, it is still impressive how the authors demonstrate their logic in storytelling. We can learn a lot from this.
Interestingly, to overcome the increasingly competitive conference submission volume and avoid reviewers perceiving the submissions as repetitive and directly giving you an early reject, many papers have started to embellish conventional operations with fancy terminology. For instance, a 1×1 convolution should be called a projection function; the multiplication of two matrices of the same order can be referred to as the Hadamard product; the calculation of similarity between two matrices can be termed affinity computation, etc.
On the other hand, most improvement directions are largely consistent, generally starting from different dimensions, complexities, and time-frequency domains. For example, in terms of dimensions, there are channel, spatial, temporal, category, etc.; complexity mainly refers to optimizing parameter and computational costs based on dimensions; domain mainly refers to transformations from time domain to frequency domain; of course, there are also many cross-domain attempts, such as the recently popular Transformer mechanism in the field of computer vision; or expanding 2D attention to 3D, etc.
In fact, by savoring the essence of these ideas, familiarizing oneself with the principles, and understanding the development context of CV, one will find that ideas abound everywhere. Even if one cannot innovate from the principles, a simple permutation and combination along with storytelling and writing prowess can lead to numerous top conferences and journals calling out to us — submission is like an ocean; only those who dare to send it out have the qualification to be accepted.
I wrote all afternoon; life is tough, and creation is not easy. Let’s refuse to freeload, starting with you and me. If you find it helpful, please feel free to follow, like, bookmark, share, and give a five-star hit. Thank you.

Note: CV

Computer Vision Group Chat
Scan to join the group.
I love computer vision
WeChat ID: aicvml
QQ Group: 805388940
Weibo Zhihu: @I love computer vision
Submission: [email protected]
Website: www.52cv.net
