1. Introduction
In today’s field of artificial intelligence, the application of multimodal large models in robotics is becoming increasingly widespread. This article aims to introduce how to convert multimodal large models to the gguf format and quantize them for efficient deployment on the ollama platform. Through this process, we achieve more efficient model operation and lower resource consumption.
2. Principle Introduction
The conversion and quantization of multimodal large models are aimed at optimizing model performance and resource usage. Mainstream conversion methods include converting models from safetensor format to .bin or gguf format. We choose the gguf format because it has better compatibility and performance on the ollama platform.
3. Hardware Introduction for Implementation and Deployment
1. Model Format Conversion
During the implementation process, we used high-performance server hardware, such as RTX4090*2 graphics cards, to ensure sufficient computing power and memory support during the conversion and quantization processes. Additionally, the support from the ollama platform ensures the efficient operation of the model.
2. Hardware Deployment Environment: Qinglong Humanoid Robot
The concept of embodied intelligence can be traced back to 1950 when Turing proposed in his paper “Computing Machinery and Intelligence” that machines can interact with their environment like humans, autonomously plan, make decisions, act, and possess execution capabilities, which is the ultimate form of AI. The difference between large language models and traditional machine learning lies in their strong generalization ability, with breakthroughs in complex task understanding, continuous dialogue, and zero-shot reasoning. This provides new solutions for robots’ understanding, continuous decision-making, and human-machine interaction capabilities. In the era of large models, large models serve as the “brain” of robots, while multimodal serves as the “small brain.” The training and testing of models combined with cloud services can conduct end-to-end real-time training and testing in virtual simulation scenarios on the cloud, rapidly completing edge-side iterations and development, which greatly accelerates the evolution speed of embodied intelligent agents.
Currently, many large companies have laid out plans in the field of embodied intelligence, such as industrial manufacturing, warehousing logistics, surveillance detection, environmental exploration, emergency rescue, and swarm combat. Google has released PaLM-E; Microsoft has expanded ChatGPT into the field of robotics; Alibaba’s Qianwen large model has been integrated into industrial robots, etc.
Boston Dynamics: Robots like Spot, Stretch, and Atlas are examples of embodied large model robots. Boston Dynamics is conducting research combining robotic functionality and expressiveness, including four research areas (cognitive AI, motion AI, advanced hardware design, and ethics). The latest research directions include: (1) Observation-Understanding-Practice projects, combining motion and cognitive abilities. E.g., robots observing human behavior on production lines, imitating human dancing, practicing without manual programming; scene recognition (work), navigation, understanding human tasks, using tools; perceiving cars, parts, human behavior, etc. Consumer applications: teaching robots to cook their favorite dishes. (2) Inspection-Diagnosis-Repair projects (medical, nuclear radiation repair, oil drilling platforms). E.g., inspecting whether equipment is functioning normally, intelligent diagnosis, repairs; fixing household appliances. (3) Agile mobile manipulation projects. (4) Ethical projects, including the laws and policies of robots, technology and design, social norms, and market forces.
ABB: (1) Stereoscopic warehouses; (2) Robotic vision applications: ① Robot guidance: item picking, box picking, stacking and unstacking, assembly guidance, picking and placing; ② Quality inspection: assembly testing, geometric analysis, defect detection; ③ Navigation and mapping: human-machine safety, AGV navigation, collision avoidance; programming; (3) RAPID programming (owned by ABB, system code and application code modules), Wizard (visual programming), guided programming (robot teaching), autonomous path planning; (4) Industrial robots: material handling, high-precision assembly, spot welding, laser welding, glue dispensing, machining.
The Qinglong Full-Size General Humanoid Robot is an outstanding representative in this field. It features a highly biomimetic torso configuration and human-like motion control, with capabilities such as fast walking, agile obstacle avoidance, robust uphill and downhill movement, and resistance to impact disturbances. It has up to 43 degrees of freedom, with a maximum joint peak torque of 396N.m, making it close to human flexibility and strength.
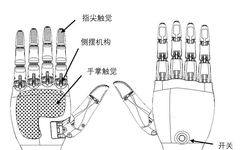
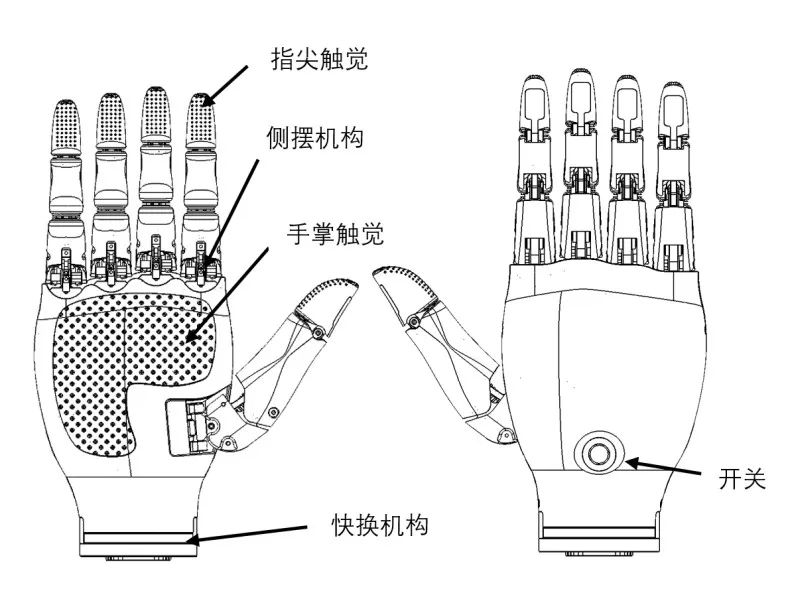
The Qinglong robot’s dexterous hands are designed with a modular structure, allowing for quick detachment and replacement with humanoid robotic arms. Each fingertip and palm section integrates array-type tactile sensors for precise contact perception. The overall appearance design references human hands and actual grasping needs, resembling human hands, with a simple and aesthetic design. It features a high grasp-to-weight ratio and adaptive grasping characteristics, with fast response speed, agile movement, and a highly human-like appearance; it uses a quick-change mechanism for easy assembly and disassembly with robotic arms; it has tactile perception capabilities, with fingers designed based on modular principles.
|
Serial Number |
Technical Parameters of the Dexterous Hand |
|
1 |
The main body has 19 degrees of freedom, 6 active degrees of freedom, the thumb has 3 degrees of freedom (2 active degrees of freedom), allowing for active bending and stretching, and lateral swinging. All four fingers have 4 degrees of freedom (1 active degree of freedom), allowing for active bending and stretching and passive lateral swinging. |
|
2 |
The total weight of the hand does not exceed 600g. |
|
3 |
Speed (finger movement): 90 degrees/S. |
|
4 |
Response speed: 10ms |
|
5 |
Single finger load not less than 15N. |
|
6 |
Total hand load (four-finger fist) not less than 5kg. |
|
7 |
Rated voltage: 8.4V. |
4. Deployment Process Introduction
1. Preparation Work: First, clone the ollama and llama.cpp code repositories and initialize the submodules.
2. Install Dependencies: Install the necessary Python packages in a virtual environment.
3. Build Quantization Tools: Use the make command to build the quantization tools.
4. Convert Model Format: Convert the multimodal large model from safetensor format to gguf format.
5. Quantize Model: Use the llama-quantize tool to quantize the model.
6. Fine-tune the Model and Import into Ollama: Create a Modelfile and run and upload the ollama model locally.
5. Deployment Steps
1. Simple Language Model Conversion Method
Reference: https://blog.csdn.net/spiderwower/article/details/138506271
2. Download Ollama and Llama.cpp
git clone https://gitcode.com/gh_mirrors/oll/ollama.git
git clone https://gitcode.com/gh_mirrors/ll/llama.cpp.git
git clone https://gitee.com/Zyi-opts/llama.cpp-zh.git3. Model Conversion Format and Quantization
Place the llama.cpp folder into ollama/llm (replace the original empty llama.cpp folder).
cd /llama.cpp
pip install -r requirements.txt
python convert.py D:\huggingface\robollava-merged --outtype f16 --outfile D:\huggingface\robollava-convert/conSince llama.cpp does not support multimodal large models, use the following method: (in autodl server/linux).
Reference:
https://blog.csdn.net/weixin_53162188/article/details/137754362
https://ollama.fan/getting-started/import/#setup
① Preparation Work:
git clone https://github.com/ollama/ollama.git
cd ollama
git submodule init
git submodule update llm/llama.cpp② Install Dependencies:
python3 -m venv llm/llama.cpp/.venv
source llm/llama.cpp/.venv/bin/activate
pip install -r llm/llama.cpp/requirements.txt③ Build Quantization Tools:
make -C llm/llama.cpp quantize④ Convert Model Format: (on server RTX4090, otherwise memory may be insufficient, requires q4_0 precise gguf format large model file)
a. Convert the multimodal large model file from safetensor format to .bin format (for record only).
Use the tool: https://github.com/davidtorcivia/convert-safetensor-to-bin/tree/main
After configuring the environment according to the link, modify the safetensor-to-bin.py file as follows:
safetensor-to-bin.py code as follows:
import torch
import os
from safetensors import safe_open
import argparse
from safetensors.torch import load_file, save_file
def convert_safetensors_to_bin(input_path, output_path): if os.path.isdir(input_path): # If the input is a directory, all .safetensors files need to be processed tensors = {} for file in os.listdir(input_path): if file.endswith('.safetensors'): file_path = os.path.join(input_path, file) tensors.update(load_file(file_path)) else: # If the input is a single .safetensors file tensors = load_file(input_path)
# Save as .bin format torch.save(tensors, output_path) print(f"Model converted successfully and saved to {output_path}")
if __name__ == "__main__": parser = argparse.ArgumentParser(description="Convert .safetensors model to .bin format") parser.add_argument('input_path', type=str, help='Path to the input .safetensors file') parser.add_argument('output_path', type=str, help='Path to save the output .bin file') args = parser.parse_args() convert_safetensors_to_bin(args.input_path, args.output_path)b. Convert the multimodal large model file from safetensor format to gguf format.
pip install torch safetensors transformers gguf llama-cpp-python# Create st2gguf.py in the previously created /autodl-tmp/LLAVA folder, with the following code:
import os
import sys
import torch
from gguf import GGUFWriter, MODEL_ARCH_NAMES # Add LLaVA directory to Python path
sys.path.append('/root/autodl-tmp/LLaVA')
from llava.model.language_model.llava_llama import LlavaLlamaForCausalLM as LlavaForConditionalGeneration # Set paths
model_dir = '/root/autodl-tmp/robollava-merged'
output_path = '/root/autodl-tmp/robollava.gguf' # Load model
model = LlavaForConditionalGeneration.from_pretrained(model_dir, torch_dtype=torch.float16) # Convert to GGUF format
def convert_llava_to_gguf(model, output_path): config = model.config gguf_writer = GGUFWriter(output_path, "llama") # Add model parameters to GGUF for name, param in model.state_dict().items(): gguf_writer.add_tensor(name, param.detach().cpu().numpy()) # Add architecture information and other metadata metadata = { "llama.architecture": "llama", "llama.vocab_size": config.vocab_size, "llama.dim": config.hidden_size, "llama.multiple_of": 256, "llama.n_heads": config.num_attention_heads, "llama.n_layers": config.num_hidden_layers, "llama.n_kv_heads": getattr(config, 'num_key_value_heads', config.num_attention_heads), "llama.norm_eps": config.rms_norm_eps, "llama.max_seq_len": config.max_position_embeddings, "llama.context_length": config.max_position_embeddings, "llama.tensor_data_type": str(config.torch_dtype), "llama.rope.scaling_type": "none", "llama.rope.freq_base": getattr(config, 'rope_theta', 10000.0), } # Add metadata for key, value in metadata.items(): if hasattr(gguf_writer, 'add_string'): gguf_writer.add_string(key, str(value)) elif hasattr(gguf_writer, 'add_data'): gguf_writer.add_data(key, str(value)) else: print(f"Warning: Unable to add metadata '{key}': {value}") # Complete and save GGUF file gguf_writer.write_header_to_file() gguf_writer.write_kv_data_to_file() gguf_writer.write_tensors_to_file() gguf_writer.close()
print("Starting conversion...")
convert_llava_to_gguf(model, output_path)
print("GGUF file has been created successfully.")⑤ Quantize Model: (the following method can only quantize large language models)
#cd /path/to/llama.cpp
make llama-quantize
./bin/llama-quantize /root/autodl-tmp/robollava.gguf /root/autodl-tmp/robollava-q4_0.gguf⑥ Fine-tune the model and import into ollama
# Create Modelfile
FROM /home/yyang/Matcha-agent/robollava/robollava.gguf
TEMPLATE """{{- if .System }}<|system|>{{ .System }}</s>{{- end }}<|user|>{{ .Prompt }}</s><|assistant|>"""
PARAMETER stop "<|system|>"
PARAMETER stop "<|user|>"
PARAMETER stop "<|assistant|>"
PARAMETER stop "</s>"4. Create Local Ollama Model
ollama create robollava -f /home/yyang/Matcha-agent/robollava/Modelfile5. Run Local Ollama Model
ollama run robollava6. Upload Ollama Model
cat /usr/share/ollama/.ollama/id_ed25519.pub
ollama cp robollava XXX/robollava # according to your homepage
ollama push XXX/robollava6. Effect Description
Through the above process, we successfully converted the multimodal large model to the gguf format and quantized it. The model can run on the ollama platform, significantly reducing resource consumption and improving performance.
The step-by-step explanation is as follows:



