
Click the “AI Meets Machine Learning” above to select the “star” public account
Original content delivered first-hand

1. What is Attention Mechanism?
In the past two years, attention models (Attention Models) have been widely used in various types of deep learning tasks such as natural language processing, image recognition, and speech recognition, making it one of the core technologies in deep learning that deserves attention and in-depth understanding.
When we look at something, our attention is focused on a specific part of that thing. In other words, when our gaze shifts elsewhere, our attention also shifts accordingly. This means that when people notice a target or a scene, the distribution of attention across each spatial location within that target or scene is different. ——— (Consider this: for images, certain striking scenes will first attract attention because our brain is sensitive to such things. For text, we usually read with a purpose, searching sequentially, but during the understanding process, we focus based on our inherent objectives. The attention model should be combined with specific purposes (or tasks).)
From the perspective of the function of Attention, we can classify types of Attention from two angles: Spatial Attention (image) and Temporal Attention (sequence). Based on practical applications, Attention can also be divided into Soft Attention and Hard Attention. Soft Attention considers all data, calculating corresponding attention weights without setting filtering conditions. Hard Attention filters out some attention that does not meet the criteria after generating attention weights, effectively setting its attention weight to zero, meaning it no longer pays attention to those non-compliant parts.
2. Encoder-Decoder Framework
The idea of the encoder-decoder model is simple: for RNN language models, when calculating the probability of the output sequence E, another RNN processes the source sequence F to compute the initial state of the language model. The meaning of encoder-decoder is: to “encode” the information of F into a hidden state through the first neural network, and then use the second neural network to predict E, “decoding” that hidden state into the output sequence.
The model structure is shown in the figure
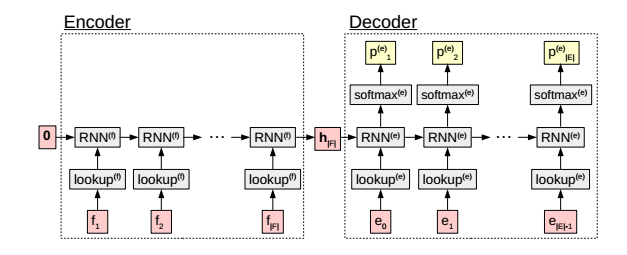
The processing unit of the encoder layer is RNN(f), while the decoder layer is RNN(e). The output of the decoder layer uses softmax to obtain the probability of outputting that hidden layer at time t.
3. Attention Model
Attention Concept
The traditional Encoder-Decoder has the drawback that regardless of how long the previous context is and how much information it contains, it ultimately has to be compressed into a few hundred-dimensional vectors. This means that the larger the context, the more information the final state vector loses.
In fact, since the context is known at input, a model can fully utilize all or part of the context information during decoding, rather than just the last state.
The idea of Attention is that after obtaining the Encoder vector, during the decoding process, the model will use not only the vector but also the RNN hidden layer vector corresponding to each word. It is worth noting that Attention is essentially a concept that can have various implementations.
The concept of attention can be implemented in many ways, with various categories, such as the distinction between soft and hard (the distinction mainly lies in that soft attention obtains the context Ci through a weighted sum, where the largest weight can be seen as aligned; while hard attention’s context C is composed of a fixed one or several encoder hidden states, represented by classification to determine whether to select a certain hidden state).
Research Progress on Attention
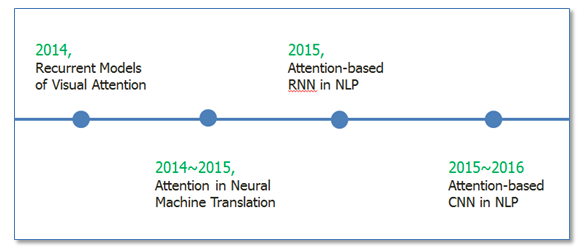
The Attention mechanism was first proposed in the field of visual images, probably in the 1990s, but it really gained momentum with the Google Mind team’s paper “Recurrent Models of Visual Attention,” where they used the attention mechanism in RNN models for image classification. Then, Bahdanau et al. used a similar attention mechanism in their paper “Neural Machine Translation by Jointly Learning to Align and Translate” for machine translation tasks, where translation and alignment were performed simultaneously. Their work is considered the first to apply the attention mechanism to the NLP field. Subsequently, RNN models based on the attention mechanism began to be applied to various NLP tasks. Recently, how to use the attention mechanism in CNN has also become a research hotspot. The following figure illustrates the general trend of research progress in attention.
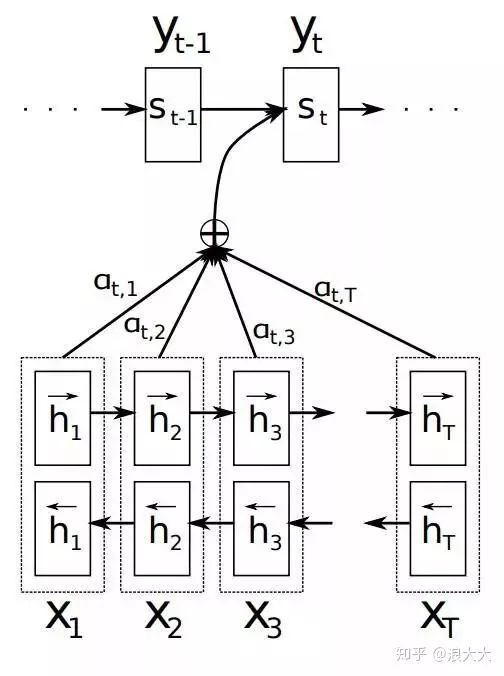
The Encoder-Decoder model introduced above does not reflect the “Attention Model,” so it can be seen as a distracted model. Why is it called a distracted model? Please observe the generation process of each word in the target sentence Y as follows:
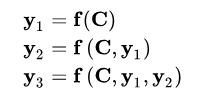
Where f is the nonlinear transformation function of the decoder. From here, it can be seen that when generating a word in the target sentence, regardless of which word is generated, whether it is y1, y2, or y3, they all use the same semantic encoding C from sentence X, with no differences. The semantic encoding C is generated by encoding each word of sentence X through the Encoder, which means that regardless of which word is generated, y1, y2, or y3, every word in sentence X has the same influence on generating a particular target word yi (in fact, if the Encoder is RNN, theoretically, the later input words have a greater influence, rather than equal weight. This is probably why Google found that reversing the input sentence during translation yields better results). This explains why this model does not reflect attention.
Introducing the AM model, taking the translation of an English sentence as an example: Input X: Tom chases Jerry. Ideal output: Tom chases Jerry.
When translating “Jerry,” it should reflect the varying degrees of influence that English words have on the translation of the current Chinese word, for instance, providing a probability distribution value (weight) like below:
(Tom,0.3)(Chase,0.2)(Jerry,0.5)
Each English word’s probability represents the attention distribution model’s allocation of attention to different English words when translating the current word “Jerry” (i.e., the weight of the original word X on the translation of the current word). This is certainly helpful for correctly translating the target language word, as it introduces new information. Similarly, each word in the target sentence should learn the attention distribution probability information corresponding to the words in the source sentence. This means that when generating each word Yi, the previous uniform intermediate semantic representation C will be replaced with a changing Ci based on the current generated word. The key to understanding the AM model lies here: it transforms from a fixed intermediate semantic representation C to a changing Ci that incorporates the attention model based on the current output word.
Thus, the process of generating target sentence words becomes:
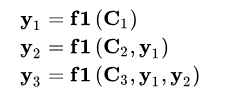
Each Ci may correspond to different attention distribution probability distributions for words in the source sentence, for example, in the above English-Chinese translation, the corresponding information may be as follows:

Where the function f2 represents a certain transformation function of the Encoder for the input English word. For instance, if the Encoder uses an RNN model, the result of this f2 function is often the state value of the hidden layer node at a certain moment after inputting xi; g represents the transformation function that synthesizes the intermediate semantic representation of the entire sentence based on the intermediate representation of the words, which in general practices is often a weighted sum of the constituent elements, i.e., the formula commonly seen in papers:



 is an output of a softmax model, with the sum of the probability values equal to 1.
is an output of a softmax model, with the sum of the probability values equal to 1.
 represents an alignment model used to measure the alignment degree of the j-th word on the encoder side with the i-th word on the decoder side (influence degree). In other words, when generating the i-th word on the decoder side, to what extent is it influenced by the j-th word on the encoder side? There are many ways to calculate the alignment model, representing different Attention models. The simplest and most commonly used alignment model is the dot product matrix, which multiplies the output hidden state ht on the target side by the output hidden state on the source side. Common alignment calculation methods are as follows:
represents an alignment model used to measure the alignment degree of the j-th word on the encoder side with the i-th word on the decoder side (influence degree). In other words, when generating the i-th word on the decoder side, to what extent is it influenced by the j-th word on the encoder side? There are many ways to calculate the alignment model, representing different Attention models. The simplest and most commonly used alignment model is the dot product matrix, which multiplies the output hidden state ht on the target side by the output hidden state on the source side. Common alignment calculation methods are as follows:

Where,  represents the alignment degree between source and target words. It can be seen that common alignment relationship calculation methods include dot product, weighted network mapping (General), and concat mapping.
represents the alignment degree between source and target words. It can be seen that common alignment relationship calculation methods include dot product, weighted network mapping (General), and concat mapping.
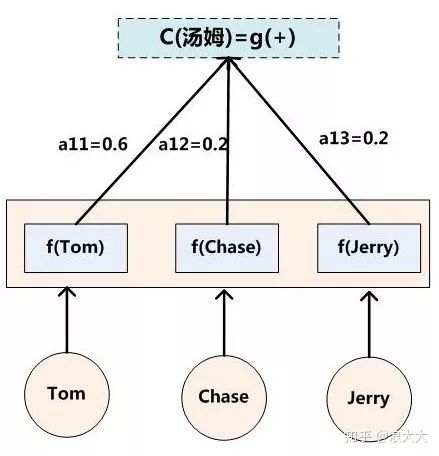
Assuming Ci contains the above “Tom,” then Tx is 3, representing the length of the input sentence, h1=f(“Tom”), h2=f(“Chase”), h3=f(“Jerry”), with corresponding attention model weights of 0.6, 0.2, and 0.2, making the g function a weighted sum function. If visually represented, when translating the Chinese word “Tom,” the formation process of the intermediate semantic representation Ci corresponding to the mathematical formula is similar to the following figure:
There is another question: when generating a target sentence word, such as “Tom,” how do you know the attention distribution probability values needed for the AM model for input sentence words? In other words, how do you obtain the probability distribution corresponding to “Tom”?
Key point (the process of obtaining attention weights) (Tom,0.3)(Chase,0.2)(Jerry,0.5) is derived how?
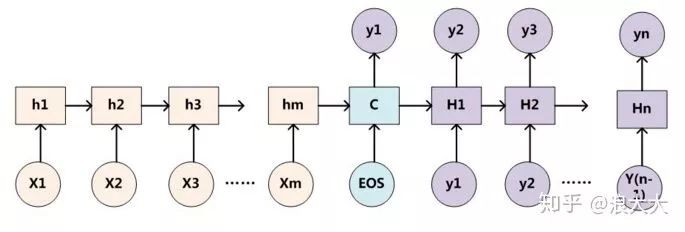
For convenience of explanation, we assume a refinement of the non-AM model’s Encoder-Decoder framework in Figure 1, where both the Encoder and Decoder use RNN models, which is a common model configuration. Thus, Figure 1 is transformed into the following:
The general calculation process for attention distribution probability values is as follows:
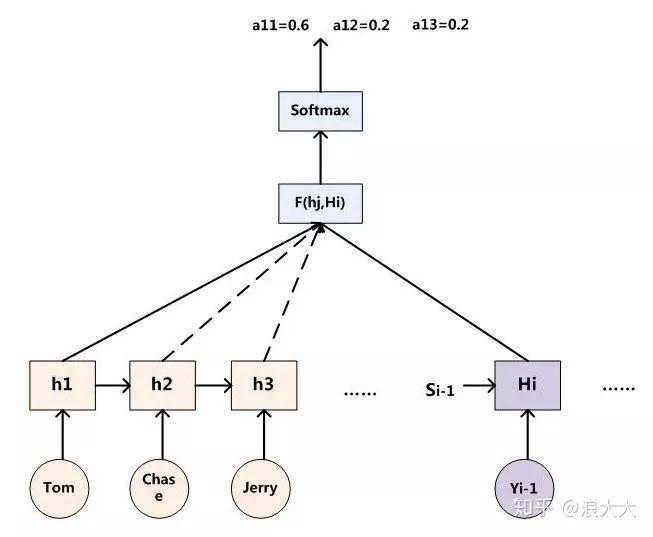
For an RNN-based Decoder, to generate the word yi at time i, we know the output value Hi of the hidden layer node at time i before generating Yi. Our goal is to calculate the attention distribution probability values for the input sentence words “Tom,” “Chase,” and “Jerry” with respect to Yi. We can compare the hidden layer node state Hi at time i with each word’s corresponding RNN hidden layer node state hj in the input sentence, using the function F(hj, Hi) to obtain the alignment likelihood between the target word Yi and each input word. This F function may adopt different methods in various papers, and the output of the function F is normalized via Softmax to yield attention distribution probability values that fit within the probability distribution range (thus obtaining the attention weights). Figure 5 shows the alignment probabilities corresponding to the input sentence words when the output word is “Tom.” Most AM models adopt the aforementioned calculation framework to compute attention distribution probability values, differing only in the definition of F.
The content above represents the basic idea of the Soft Attention Model (where any data receives a weight without filtering conditions), which is the foundational concept for most AM models you can find in the literature. The differences likely lie in applying this model to solve different application problems. So how to understand the physical meaning of the AM model? Generally, literature tends to view the AM model as a word alignment model, which makes a lot of sense. The probability distribution of each generated word in the target sentence corresponding to the input sentence words can be understood as the alignment probability of the input sentence words with the target generated word. This is very intuitive in the context of machine translation: traditional statistical machine translation typically includes a phrase alignment step, while the attention model serves a similar purpose. In other applications, understanding the AM model as the alignment probability between input and target sentence words is also a smooth idea.
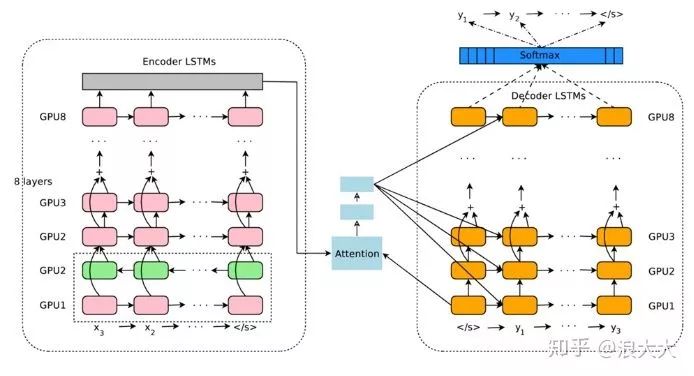
Figure 6 illustrates the Google neural network-based machine translation system deployed online in 2016, which significantly improved translation results compared to traditional models, reducing the translation error rate by 60%. Its architecture is based on the Encoder-Decoder framework with the attention mechanism mentioned above, with the main difference being that its Encoder and Decoder use an 8-layer stacked LSTM model.
Of course, conceptually, understanding the AM model as an influence model is also reasonable, meaning that when generating the target word, each input sentence word has a degree of influence on generating that word. This thought process is also a good way to understand the physical meaning of the AM model.
Rush used the AM model to create a generative summary, providing a very intuitive example of an AM.
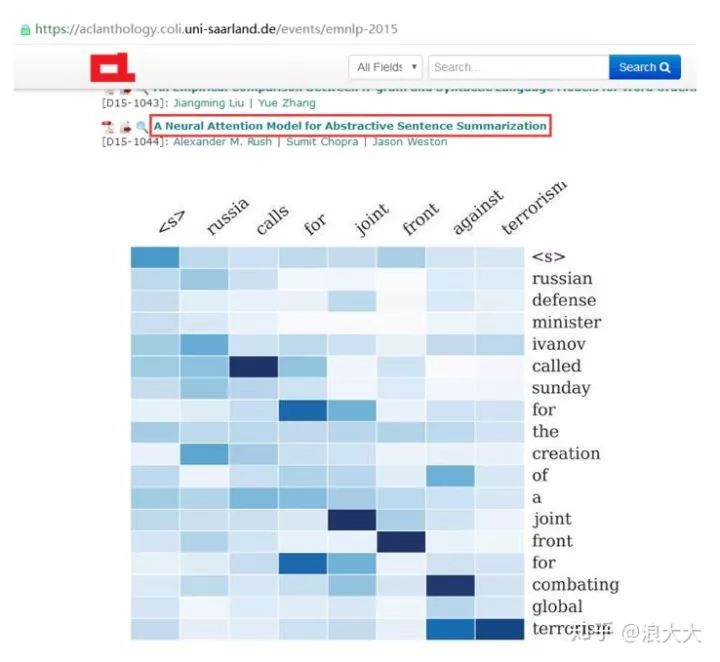
In this example, the input sentence X for the Encoder-Decoder framework is: “Russian defense minister Ivanov called Sunday for the creation of a joint front for combating global terrorism.” The corresponding sentence on the vertical axis in the figure. The generated summary sentence Y is: “Russia calls for a joint front against terrorism,” corresponding to the sentence on the horizontal axis in the figure. It can be seen that the model has correctly extracted the main part of the sentence. Each column in the matrix represents the AM allocation probability corresponding to each input word for the generated target word, with darker colors indicating higher allocated probabilities. This example is very helpful for intuitively understanding AM.
Source: Zhihu, Lang Dada Link: https://zhuanlan.zhihu.com/p/61816483
Recommended Reading
Content| How to Write Academic Papers
Resources| Recommended NLP Books and Courses (with Material Download)
Content| Comprehensive Understanding of N-Gram Language Model
Resources| Recommended Book “Machine Learning for OpenCV”
Welcome to follow us for more insightful content!
