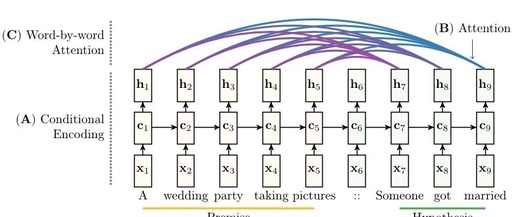
[Introduction]The Attention mechanism originates from mimicking human thinking patterns and has been widely applied in machine translation, sentiment classification, automatic summarization, automatic question answering, dependency analysis, and other machine learning applications. The editor has compiled a review on the application of Attention mechanisms in NLP titled An Introductory Survey on Attention Mechanisms in NLP Problems, and provided some related code links.
Overview
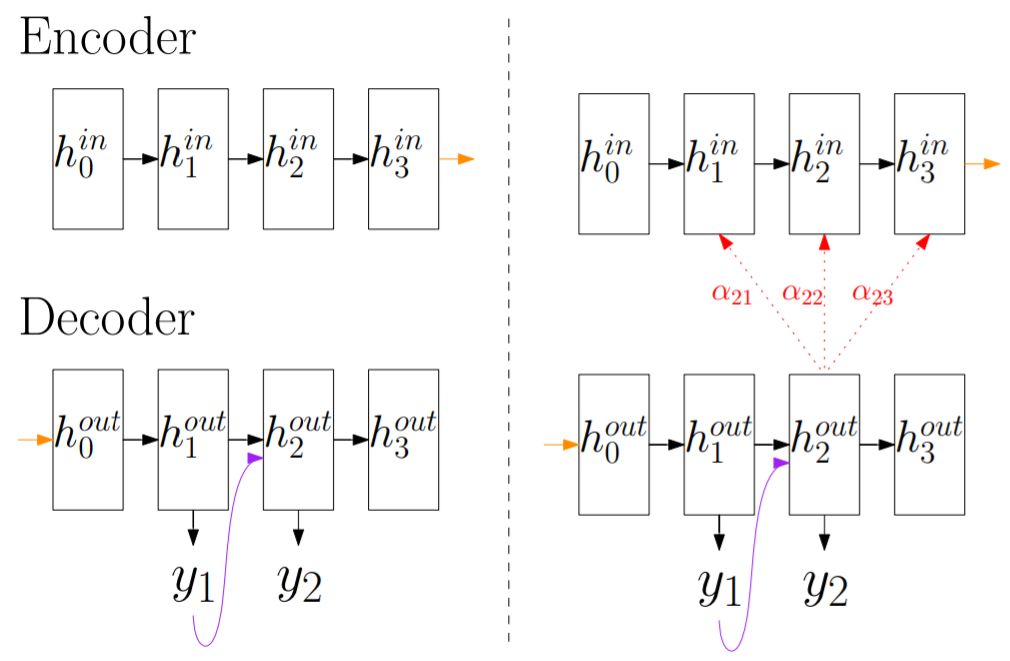
In the figure below, the left side shows the traditional Seq2Seq model (encoding a sequence and then decoding it), which is based on the traditional LSTM model. In the decoder, the hidden state at a certain timestamp only depends on the current hidden state and the output from the previous timestamp. The right side shows the Attention-based Seq2Seq model, where the output of the decoder also depends on a context feature (c), which is obtained through a weighted average of the hidden states from all timestamps in the encoder, with the weights being the Attention Scores (a) between the current timestamp and each timestamp in the encoder.
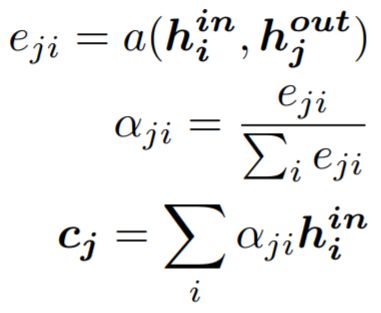
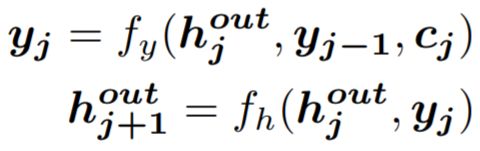
General Form of Attention
The following formula represents the basic form of Attention (Basic Attention), where u is the matching feature vector based on the current task, used to interact with the context. vi is the feature vector at a certain timestamp in the sequence, ei is the unnormalized Attention Score, ai is the normalized Attention Score, and c is the context feature for the current timestamp calculated based on the Attention Scores and the feature sequence v.

In most cases, ei can be calculated using several methods as shown below:
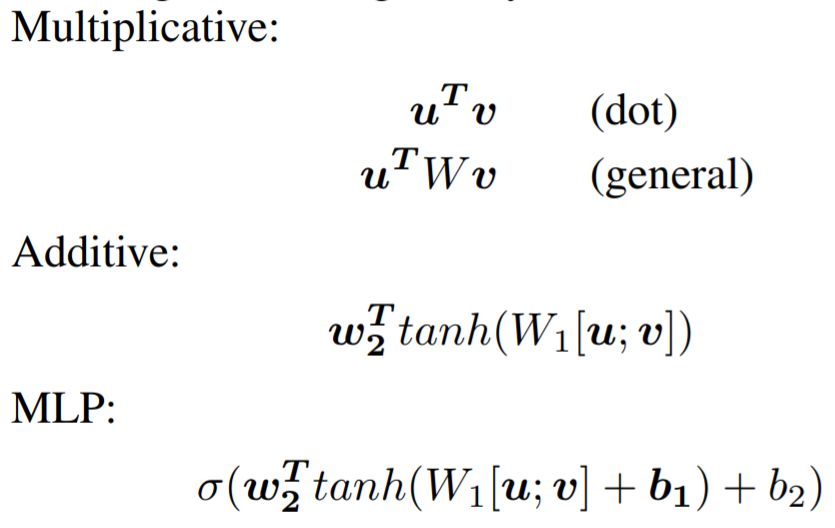
In practical applications, in addition to the basic Attention, there are various variants of Attention. Below we introduce some common variants:
Variant – Multi-dimensional Attention
For each u, Basic Attention generates an Attention Score ai for each vi, meaning each u corresponds to a 1-D Attention Score vector. Multi-dimensional Attention produces a higher-dimensional Attention matrix aimed at capturing Attention features in different feature spaces, such as some forms of 2D Attention shown below:
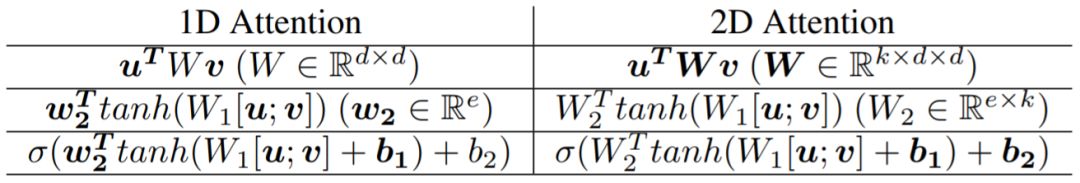
Variant – Hierarchical Attention
Some Attention algorithms consider Attention between different semantic levels. For example, the model below sequentially uses word-level and sentence-level Attention to obtain better features:
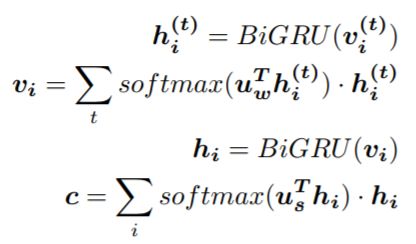
Variant – Self Attention
Replacing u in the above formula with vi from the context sequence gives us Self Attention. In NLP, Self Attention can capture some dependency relationships between words in a sentence. Additionally, in some tasks, the semantics of a word is closely related to the context. For example, in the following two sentences, the word “bank” refers to both a financial institution and the edge of a river. To accurately determine the current meaning of “bank,” we can rely on the context of the sentence.
I arrived at the bank after crossing the street.
I arrived at the bank after crossing the river.
Variant – Memory-based Attention
The form of Memory-based Attention is as follows, where {(ki, vi)} is called Memory, which is actually the synonyms of the input. Particularly, when ki and vi are equal, Memory-based Attention is the same as Basic Attention.
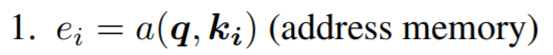
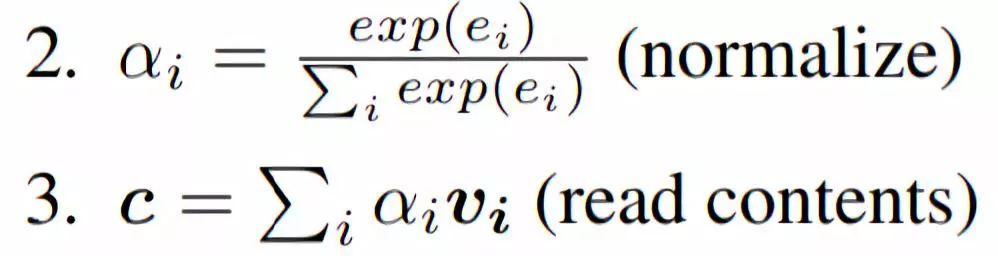
For example, in QA questions, Memory-based Attention can iteratively update Memory to shift attention to the location of the answer.

Evaluation of Attention
Quantitative evaluation of Attention can be done through intrinsic and extrinsic methods. Intrinsic evaluation is based on labeled Alignment data, thus requiring a large amount of manual labeling. The extrinsic method is simpler, directly comparing the model’s performance on specific tasks. However, the issue with extrinsic evaluation is that it is difficult to determine whether performance improvements are due to the Attention mechanism.
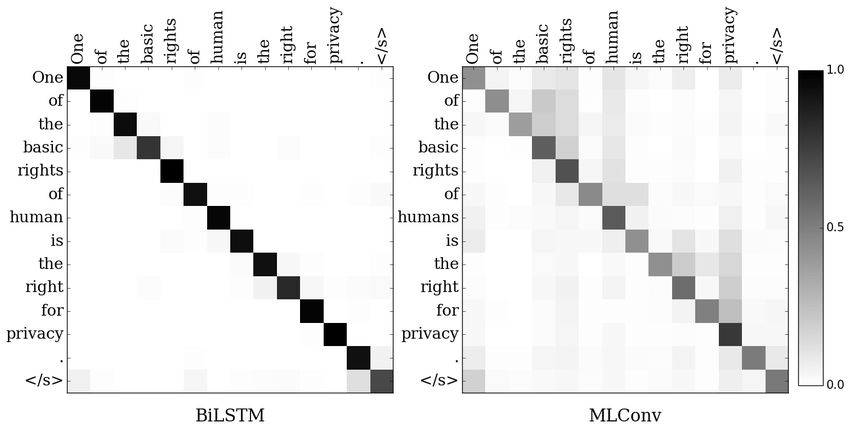
Quantitative evaluation is typically achieved through visualized heatmaps:
Related Attention Code
-
Neural Machine Translation by Jointly Learning to Align and Translate: https://github.com/tensorflow/nmt
-
Hierarchical Attention Networks for Document Classification: https://github.com/richliao/textClassifier
-
Coupled Multi-Layer Attentions for Co-Extraction of Aspect and Opinion Terms: https://github.com/happywwy/Coupled-Multi-layer-Attentions
-
Attention Is All You Need: https://github.com/Kyubyong/transformer
-
End-To-End Memory Networks: https://github.com/facebook/MemNN
References:
-
An Introductory Survey on Attention Mechanisms in NLP Problems: https://arxiv.org/abs/1811.05544
Please follow the Zhuanzhi Official Account (scan the QR code below, or click on the blue Zhuanzhi above)
-
Reply “ISAM” in the background to obtain the latest PDF download link~
-END-
Zhuan · Zhi
Complete Knowledge Materials on 26 Topics in Artificial Intelligence and join the Zhuanzhi AI service group: Welcome to scan WeChat to join the Zhuanzhi AI Knowledge Star Group, and obtain professional knowledge tutorial videos and consult with experts!

Please log in to www.zhuanzhi.ai or click to read the original text, register and log in to Zhuanzhi to obtain more AI knowledge materials!
Please add the Zhuanzhi Assistant WeChat (scan the QR code below to add), join the Zhuanzhi theme group (please note the theme type: AI, NLP, CV, KG, etc.) for communication~
Please follow the Zhuanzhi official account to obtain professional knowledge in artificial intelligence!
Click “Read the original text” to use Zhuanzhi