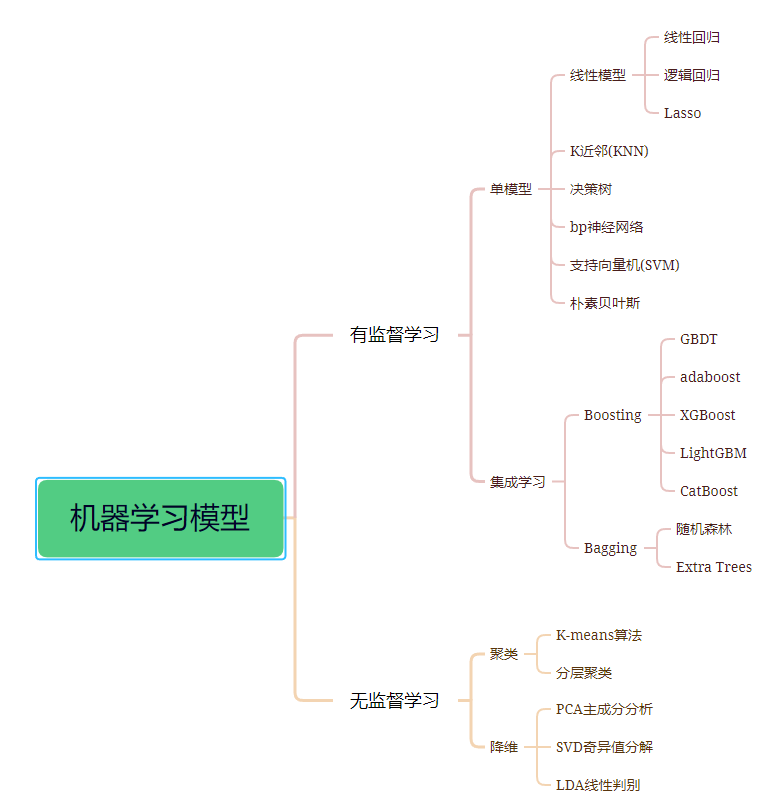
1. Supervised Learning
-
Classification problems: Predicting the category of a sample (discrete). For example, determining gender, health status, etc. -
Regression problems: Predicting the corresponding real number output (continuous) of a sample. For example, predicting the average height of people in a certain area.
1.1 Single Model
Linear regression refers to a regression model composed entirely of linear variables. In linear regression analysis, only one independent variable and one dependent variable are included, and their relationship can be approximately represented by a straight line; this type of regression analysis is called simple linear regression analysis.
If the regression analysis includes two or more independent variables, and there is a linear relationship between the dependent variable and the independent variables, it is called multiple linear regression analysis.
Used to study the influence relationship between X and Y when Y is categorical data. If Y has two categories, such as 0 and 1 (e.g., 1 for willing and 0 for not willing, 1 for purchase and 0 for no purchase), it is called binary logistic regression; if Y has three or more categories, it is called multi-class logistic regression.
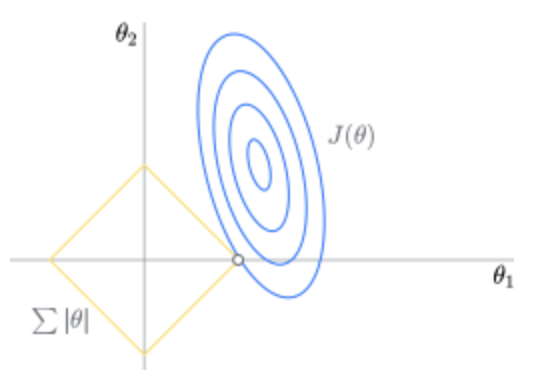
1.13 Lasso
The main difference between KNN for regression and classification lies in the decision-making process during the final prediction. For classification predictions, KNN generally uses the majority voting method, meaning it predicts the class of the sample based on the majority class among the K nearest samples in the training set.
For regression, KNN typically uses the average method, taking the average output of the K nearest samples as the regression prediction value. However, their theories are the same.
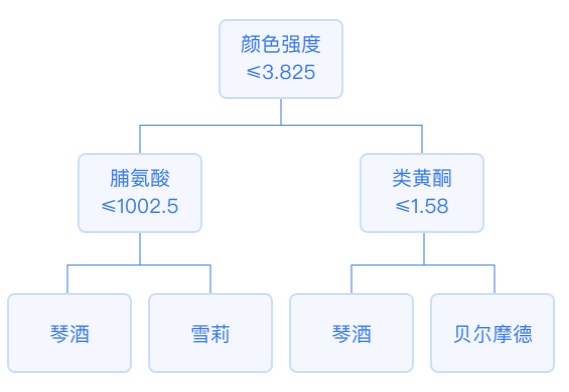
In a decision tree, each internal node represents a splitting problem: it specifies a test on a certain attribute of the instance, splitting the samples reaching that node according to a specific attribute, and each successor branch of that node corresponds to a possible value of that attribute.
The leaf nodes of the classification tree contain samples where the output variable’s mode is the classification result. The leaf nodes of the regression tree contain samples where the output variable’s mean is the predicted result.
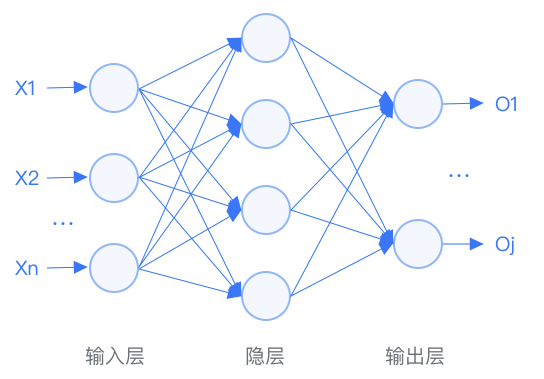
The BP neural network is a multi-layer feedforward network trained by the error backpropagation algorithm and is one of the most widely used neural network models. The learning rule of the BP neural network uses the steepest descent method to continuously adjust the network’s weights and thresholds through backpropagation, minimizing the classification error rate (minimizing the sum of squared errors).
-
The first stage is the forward propagation of signals from the input layer through the hidden layer to the output layer; -
The second stage is the backward propagation of errors from the output layer to the hidden layer and finally to the input layer, adjusting the weights and biases from the hidden layer to the output layer and from the input layer to the hidden layer in turn.

Support Vector Machine Regression (SVR) uses nonlinear mapping to map data into a high-dimensional feature space, allowing the independent and dependent variables to have good linear regression characteristics in that space. After fitting in that feature space, it returns to the original space.
Support Vector Machine Classification (SVM) is a type of generalized linear classifier that performs binary classification of data using supervised learning methods, with the decision boundary being the maximum margin hyperplane solved from the learning samples.
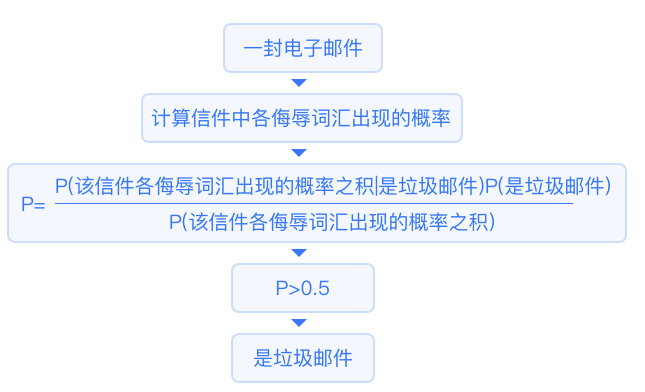
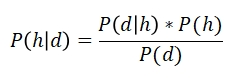
This algorithm assumes that all variables are independent of each other.
1.2 Ensemble Learning

-
Boosting
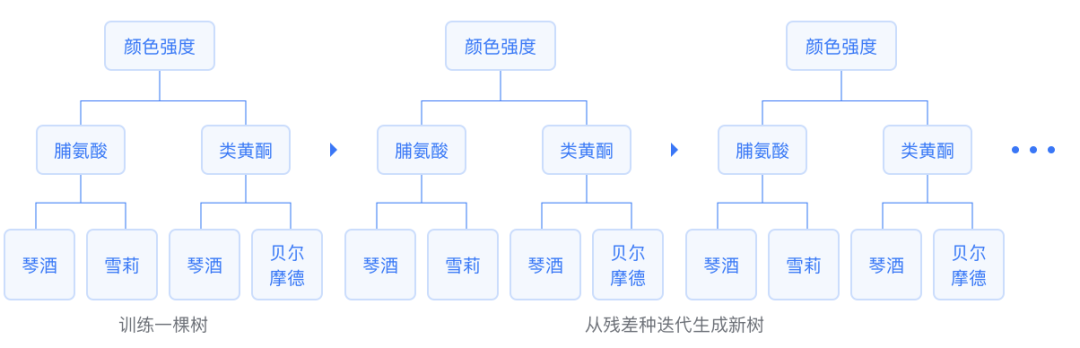
GBDT is a Boosting algorithm that uses CART regression trees as base learners. It is an additive model that serially trains a set of CART regression trees, ultimately summing the predictions of all regression trees to obtain a strong learner, where each new tree fits the negative gradient direction of the current loss function. The final output is the sum of this set of regression trees, directly yielding regression results or applying the sigmoid or softmax function to obtain binary or multi-class classification results.
1.22 AdaBoost
AdaBoost assigns a high weight to learners with low error rates and a low weight to learners with high error rates, combining weak learners with corresponding weights to generate a strong learner. The difference between regression and classification algorithms lies in the way error rates are calculated; classification problems generally use a 0/1 loss function, while regression problems generally use a squared loss function or a linear loss function.
1.23 XGBoost
XGBoost is an efficient implementation of GBDT. Unlike GBDT, XGBoost adds a regularization term to the loss function; and since some loss functions are difficult to derive, XGBoost uses the second-order Taylor expansion of the loss function for fitting.
1.24 LightGBM
LightGBM is an efficient implementation of XGBoost, which discretizes continuous floating-point features into k discrete values and constructs a histogram with a width of k. It then traverses the training data to calculate the cumulative statistics of each discrete value in the histogram. During feature selection, it only needs to find the optimal split point based on the discrete values of the histogram and uses a leaf-wise growth strategy with depth restrictions, saving considerable time and space costs.
1.25 CatBoost
-
Bagging
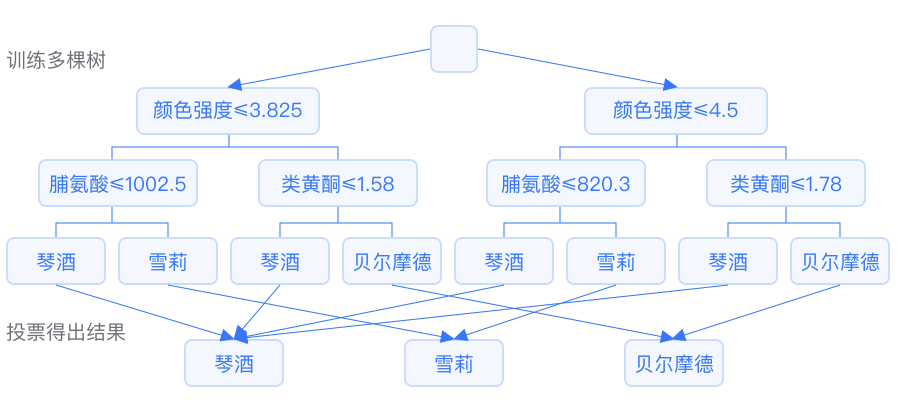
Extra Trees (Extremely Randomized Trees) is very similar to random forests. The term “extremely random” refers to the random feature and threshold partitioning in decision trees, resulting in greater shape and difference variability in each decision tree.
2. Unsupervised Learning
2.1 Clustering
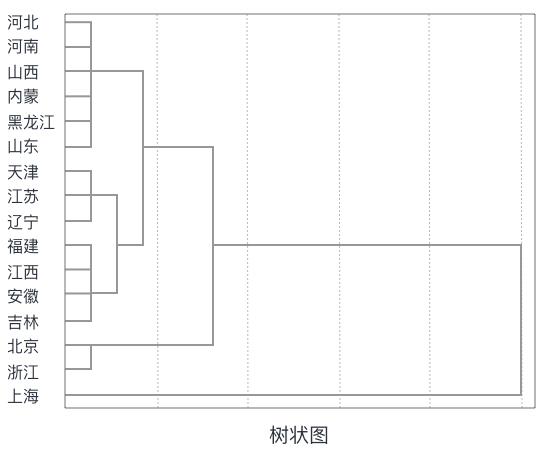
2.2 Dimensionality Reduction
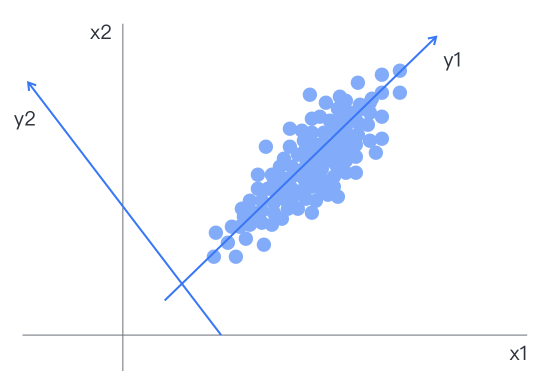
Principal component analysis linearly combines multiple correlated indicators to explain as much information as possible from the original data with the least dimensions. The resulting variables after dimensionality reduction are linearly independent of each other, and the newly determined variables are linear combinations of the original variables, with the later principal components having a smaller weight in variance, indicating weaker capacity for summarizing original information.
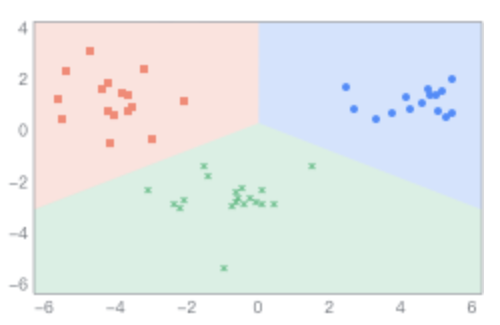
The principle of linear discriminant analysis is to project samples onto a line such that the projection points of similar samples are as close as possible, while the projection points of different samples are as far apart as possible. When classifying new samples, they are projected onto the same line, and their class is determined based on the position of their projection points.
Edit / Zhang Zhihong
Review / Fan Ruiqiang
Recheck / Zhang Zhihong
Click below
Follow us