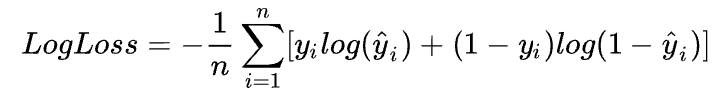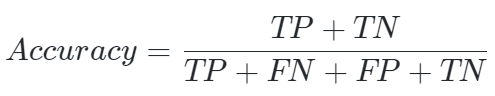Definition of Machine Learning
Machine Learning is essentially about enabling computers to learn patterns from data and predict future data based on those patterns.
Machine Learning includes algorithms such as clustering, classification, decision trees, Bayesian methods, neural networks, and deep learning.
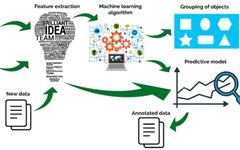
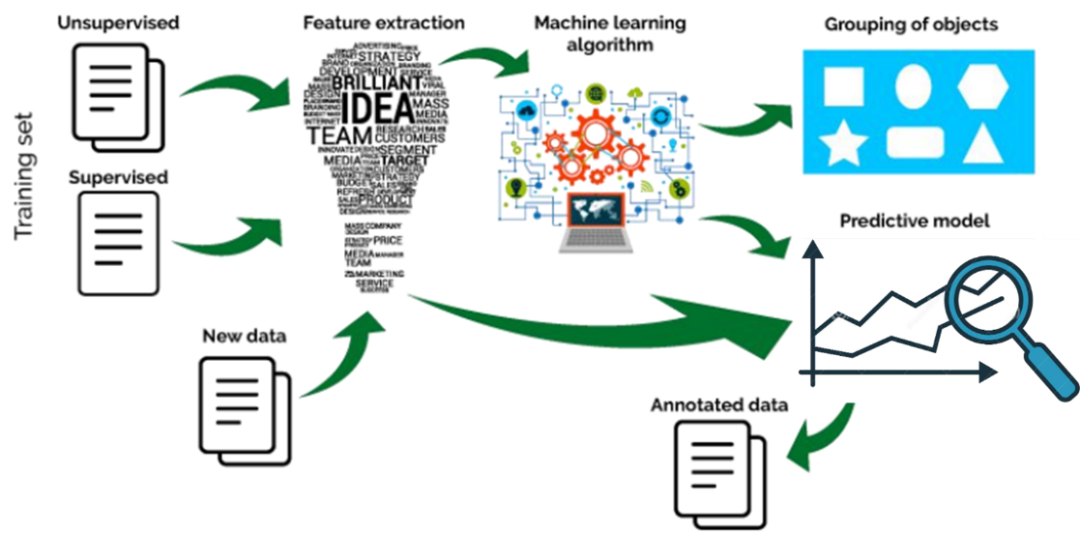
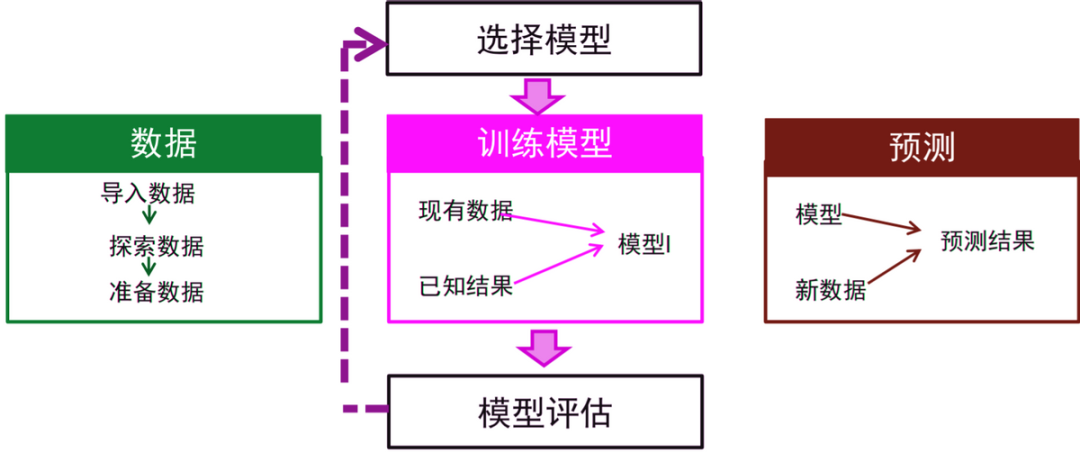
The basic idea of Machine Learning is to mimic the human learning process, where we generally solve new problems through experience, summarizing patterns to predict the future. The basic process of Machine Learning is as follows:
Basic Process of Machine Learning
Development History of Machine Learning
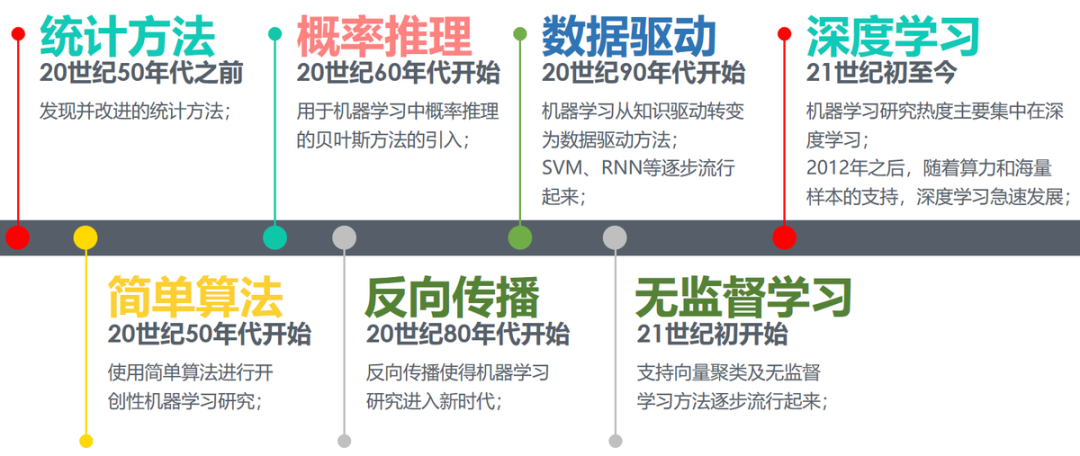
The timeline of the development of Machine Learning is as follows:
Development History of Machine Learning
Since the proposal of the Turing Test in the 1950s and Samuel’s development of the Western chess program, Machine Learning has officially entered its development phase.
-
From the mid-60s to the late 70s, development almost stagnated.
-
The introduction of the backpropagation (BP) algorithm for training multi-parameter linear programming (MLP) in the 1980s marked a renaissance for Machine Learning.
-
The introduction of the “decision tree” (ID3 algorithm) in the 1990s, followed by the support vector machine (SVM) algorithm, shifted Machine Learning from a knowledge-driven to a data-driven approach.
-
In the early 21st century, Hinton proposed deep learning, which revitalized research in Machine Learning.
Starting in 2012, with the improvement of computing power and the availability of massive training samples, deep learning has become a hot topic in Machine Learning research and has led to widespread applications in the industry.
Categories of Machine Learning
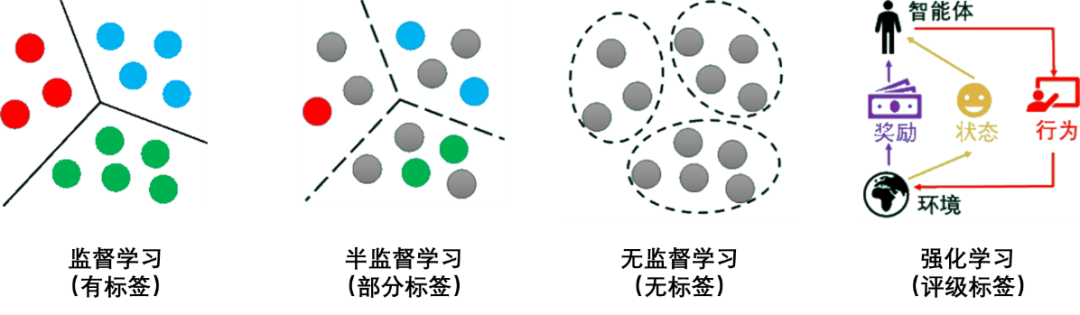
Over decades of development, Machine Learning has derived many classification methods. Based on different learning patterns, it can be divided into supervised learning, semi-supervised learning, unsupervised learning, and reinforcement learning.
Supervised Learning is the process of learning a model from labeled training data and then using that model to predict the labels of new data. The higher the accuracy of the classification labels, the higher the accuracy of the learning model and the more precise the prediction results.
Supervised Learning is mainly used for regression and classification.
Common regression algorithms in supervised learning include linear regression, regression trees, K-nearest neighbors, Adaboost, and neural networks.
Common classification algorithms in supervised learning include Naive Bayes, decision trees, SVM, logistic regression, K-nearest neighbors, Adaboost, and neural networks.
Semi-Supervised Learning is a learning mode that utilizes a small amount of labeled data along with a large amount of unlabeled data.
Semi-Supervised Learning focuses on incorporating unlabeled samples into supervised classification algorithms to achieve semi-supervised classification.
Common semi-supervised learning algorithms include Pseudo-Label, Π-Model, Temporal Ensembling, Mean Teacher, VAT, UDA, MixMatch, ReMixMatch, and FixMatch.
Unsupervised Learning is the process of finding hidden structures from unlabeled data.
Unsupervised Learning is mainly used for association analysis, clustering, and dimensionality reduction.
Common unsupervised learning algorithms include Sparse Auto-Encoder, Principal Component Analysis (PCA), K-Means, DBSCAN, and Expectation-Maximization (EM) algorithm.
Reinforcement Learning is similar to supervised learning but does not use sample data for training; it is a learning mode through trial and error.
In reinforcement learning, there are two interactive objects: the agent and the environment, along with four core elements: policy, reward function, value function, and environment model, where the environment model is optional.
Reinforcement Learning is commonly used in applications such as robot obstacle avoidance, board games, advertising, and recommendations.
To aid understanding, gray dots represent unlabeled data, while other colored dots represent labeled data from different categories. The diagrams for supervised learning, semi-supervised learning, unsupervised learning, and reinforcement learning are as follows:
Application of Machine Learning
Machine Learning is the process of abstracting real-world problems into mathematical models, training the data model using historical data, and then solving new data based on the data model, converting the results back into answers to real-world problems. The general steps for implementing Machine Learning applications are as follows:
-
Abstract the real problem into a mathematical problem;
-
-
Select or create a model;
-
Model training and evaluation;
-
Here we take an example from the Kaggle competition Cats vs. Dogs to provide a simple introduction, and those interested can experiment personally.
1. Abstract the Real Problem into a Mathematical Problem
Real Problem: Given an image, let the computer determine whether it is a cat or a dog?
Mathematical Problem: A binary classification problem, where 1 indicates the result is a dog, and 0 indicates the result is a cat.
Data download link: https://www.kaggle.com/c/dogs-vs-cats.
After downloading the Kaggle Cats vs. Dogs dataset, it is divided into 3 files: train.zip, test.zip, and sample_submission.csv.
The training set contains 25,000 images of cats and dogs, half of each, with each image containing the image itself and its name. The naming convention follows the “type.num.jpg” format.
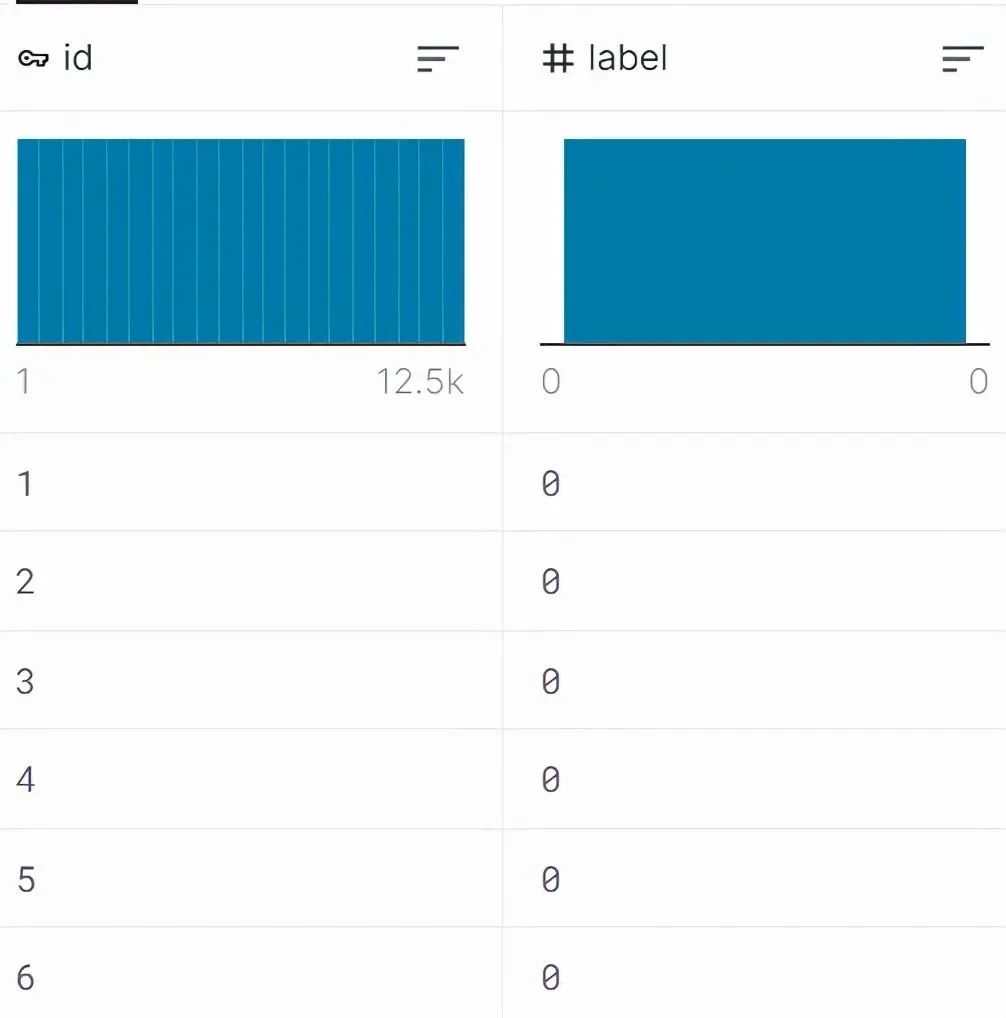
The test set contains 12,500 images of cats and dogs without labels indicating whether they are cats or dogs, with each image named according to the “num.jpg” convention.
The sample_submission.csv needs to have the final test results written into the .csv file.
Sample Submission Example
We will divide the data into three parts: training set (60%), validation set (20%), and test set (20%) for subsequent validation and evaluation work.
There are many models in Machine Learning, and the choice of model depends on data type, sample size, and the problem itself.
For this problem, which mainly deals with image data, a Convolutional Neural Network (CNN) can be considered for binary classification, as one of the advantages of choosing CNN is that it avoids the need for preprocessing the images (such as feature extraction). The structure of the CNN for cat and dog recognition is shown below:
The bottom layer is the input layer, used to read the image as the network’s data input; the top layer is the output layer, which predicts and outputs the category of the input image. Since we only need to distinguish between cats and dogs, the output layer has only 2 neurons; layers between the input and output layers are called hidden layers, also known as convolutional layers, with 3 hidden layers set here.
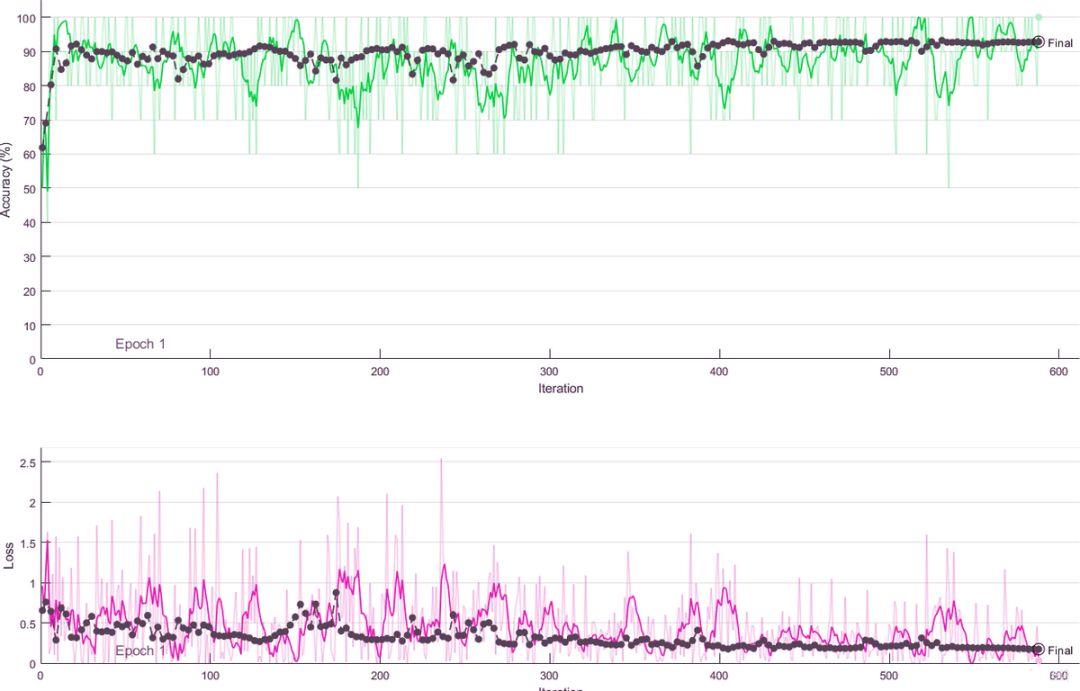
4. Model Training and Evaluation
We predefine the loss function to calculate the loss value, and evaluate the training model using accuracy. The log loss function serves as the model evaluation metric:
Accuracy is used to measure the accuracy of the algorithm’s predictions:
TP (True Positive) is the number of positive class predictions that are true positives.
FP (False Positive) is the number of negative class predictions that are incorrectly predicted as positive.
TN (True Negative) is the number of negative class predictions that are true negatives.
FN (False Negative) is the number of positive class predictions that are incorrectly predicted as negative.
Loss and accuracy during training
With the trained model, we load an image for recognition to see how well it performs:
Trend Analysis of Machine Learning
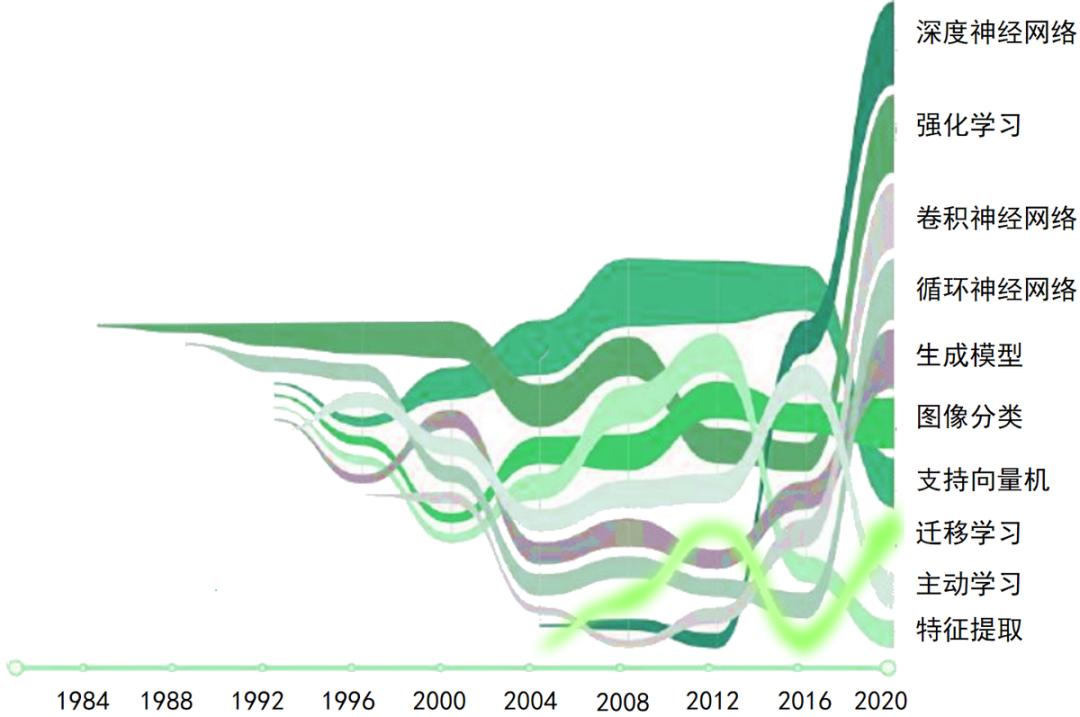
The real research and development of Machine Learning began in the 1980s. Using the AMiner platform, we generated the following trend graph from statistical analysis of recent Machine Learning papers:
It can be seen that deep neural networks, reinforcement learning, convolutional neural networks, recurrent neural networks, generative models, image classification, support vector machines, transfer learning, active learning, and feature extraction are hot research topics in Machine Learning.
Research on deep learning technologies, represented by deep neural networks and reinforcement learning, has been rising rapidly and remains a hot topic in recent years.
Finally, quoting a line from Han Yu’s “On Learning”:
“Excellence comes from diligence, while neglect leads to failure; actions are shaped by thought, while carelessness leads to ruin.”
「The End」
Source: Dolphin Data Science Laboratory;
Copyright Notice: Some content from this account comes from the internet. Please indicate the original link and author when reprinting. If there is any infringement or error in the source, please contact us.
For more related knowledge, please reply:“Moonlight Treasure Box”;
Data Analysis (ID: ecshujufenxi ) is a WeChat account for internet technology and data circles, and is also a member of the WeMedia self-media alliance, covering an audience of 50 million.