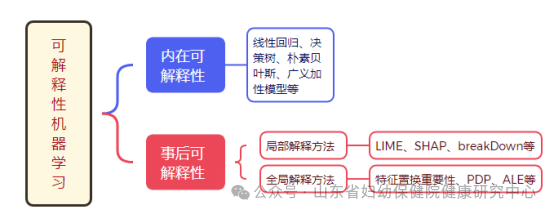
1.Intrinsic Explainability
Intrinsic explainability, also known as pre-explainability, refers to the capability of machine learning models to be understood without additional information by training simple structures that are inherently interpretable or by integrating interpretability into specific model structures. For example:
lLinear Regression: Explaining each feature’s contribution to the prediction results through the model’s coefficients;
lDecision Trees: Displaying feature importance and decision paths in a tree structure;
lNaive Bayes: Providing the contribution of each feature to the classification probability;
lGeneralized Additive Models: Visually presenting the impact of each feature through smooth function graphs.
These models inherently possess high interpretability due to their simple structures, but their performance is often limited when dealing with complex data.
2.Post-hoc Explainability
Post-hoc explainability refers to using explanation methods or constructing explanation models to explain the working mechanisms, decision behaviors, and bases of a given trained model. Post-hoc explanation methods can be divided into two categories based on their scope: local interpretation methods and global interpretation methods. Local interpretation methods explain why a model makes a certain prediction for a single sample or a group of samples, while global interpretation methods can provide general rules or statistical inferences about the overall model, understanding each variable’s impact.
(1) Examples of Local Interpretation Methods:
lLIME (Local Interpretable Model-agnostic Explanations): One of the most popular post-hoc explanation methods for black box models, proposed by Marco Ribeiro et al. in 2016, which explains a sample’s prediction result through local linear approximations of the model output. Advantages: Flexible and applicable to any model.
lSHAP (Shapley Additive Explanations): Proposed by Lundberg and Lee in 2017, based on game theory, assigning a contribution value to each feature. SHAP also averages the Shapley values of all sample variables to determine global variable importance. Advantages: Can explain both global and local feature impacts, theoretically rigorous.
lbreakDown: Proposed by Staniak et al. in 2018, similar to SHAP, which decomposes the model prediction into the incremental contributions of each feature, visually displaying each feature’s impact on the prediction results and its cumulative contribution. Advantages: Faster computation speed, more intuitive explanations.
(2) Examples of Global Interpretation Methods:
lFeature Permutation Importance: Evaluating feature importance by randomly shuffling feature values and observing changes in model performance. Advantages: Simple to use, applicable to various models.
lPartial Dependence Plot (PDP): Graphically displaying the average impact of one or more features on the model output. Characteristics: Considers the average impact of all samples on predictions, but averaging across all samples may result in positive and negative effects canceling each other out, and does not allow for correlations between variables.
lAccumulated Local Effects (ALE): Measuring the local average impact of feature value changes on model predictions, avoiding feature correlation bias, thus clearly reflecting the overall impact trend of features on predictions. Characteristics: Improves PDP, reducing the influence of feature correlations on explanations.
1.Simple Models (e.g., regression, decision trees): Directly use model structure for explanation.
2.Complex Models (e.g., deep learning, random forests): Combine SHAP, LIME, and other methods.
3.High-risk Scenarios (e.g., healthcare, finance): Prioritize explanation methods with strong theoretical support and high transparency.
1.Healthcare: Explaining diagnostic models or treatment recommendation systems, such as disease prediction or drug recommendations.
2.Financial Services: Evaluating the decision logic of models in credit scoring, risk analysis, and fraud detection systems.
3.Industrial Manufacturing: Analyzing models for optimizing production processes and predicting equipment failures.
4.Environmental Science: Analyzing the feature contributions of climate change models and pollution prediction models.
5.Autonomous Driving and Traffic: Evaluating the reliability of decision models for path planning and obstacle detection.
6.Public Policy and Social Sciences: Assessing the fairness and influencing factors of policy decision models.

