If you are interested in machine learning or have been engaged in it, then classification and regression are the most common terms. However, there is another common technique called the similarity problem, which can discover whether two inputs are similar; this is known as a Siamese Neural Network.
Assuming you are familiar with CNNs used for image classification and have previously trained an image classification model or a standard classification type, you should be able to use a standard deep learning network or fully connected layer network to recognize models for dog and cat images.
Image classification model using traditional deep learning neural network architecture
First, we must obtain a labeled dataset containing images of dogs and cats. After training the neural network, when any image is input, the network can only output labels of either dog or cat. This is a standard computer vision problem known as image classification.
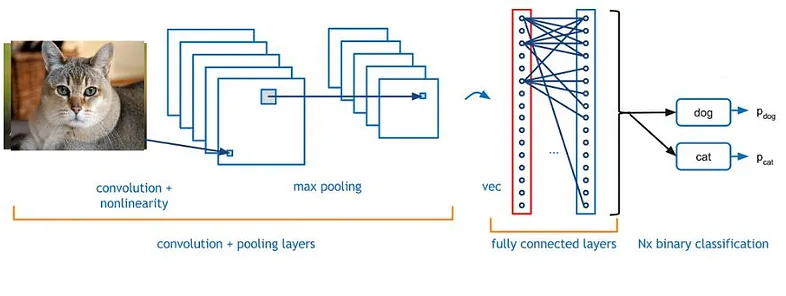
In classification, the input image is fed into the neural network (either a neural network or a fully connected layer network), and finally, at the output layer, we obtain a probability distribution list of all categories (using Softmax or any other activation function based on the classification problem to be solved).
However, during training, we need a large number of images for each category (cats and dogs), and if the network is only trained on the aforementioned two categories of images, we cannot expect it to make predictions or tests on any other categories, such as “elephants”.
If we want our model to classify images of elephants as well, we first need to obtain a large number of elephant images, then we must retrain the model on these images before making predictions.
In some applications, we do not have enough data to represent each category, and for use cases like employee attendance systems, the number of categories may grow exponentially. Therefore, the cost of data collection and retraining is high each time a new category is added or a new employee joins.
As a result, algorithms like similarity score learning or Siamese Neural Networks have become alternatives to traditional classification algorithms.
What is similarity learning?
Similarity learning is a supervised machine learning technique aimed at allowing the model to learn a similarity function that measures how similar two objects are and returns a similarity value.
When objects are similar, a high score is returned; when images or objects are different, a low score is returned. Now, let’s look at some use cases of similarity learning, which is also known as one-shot classification (Siamese Networks).
Use Cases of Siamese Networks
Here we will see two use cases of similarity learning, first in employee attendance and secondly in signature verification systems.
In a Siamese network, we only need one training example for each class. Hence the name One Shot. Let’s try to understand this with a real-world practical example.
-
Employee Attendance System
Suppose we want to build an attendance system for a small company with only 20 employees (a small number, making things simple), and the system must recognize the faces of the employees.
Problems in Building Attendance Systems
The first problem is the training data images; we first need to organize a large number of different images for each employee in the organization.
When new employees join or leave the organization, we need to painstakingly collect data again and retrain the entire model. This is not efficient for scalable systems, especially for large organizations where personnel changes occur almost weekly. For such scenarios requiring scalable systems, a Siamese network model can be a great solution.
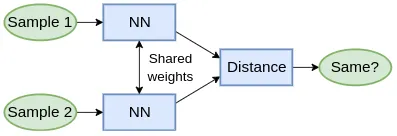
Now, what the Siamese network does is not classify the test image as one of the 20 people in the organization, but instead takes that person’s reference image as input and generates a similarity score indicating the probability that the two input images belong to the same person.
Using an S-shaped function, the similarity score ranges between 0 and 1.
A similarity score of 0 indicates dissimilarity, while a similarity score of 1 indicates complete similarity. Any number between 0 and 1 will be interpreted accordingly.
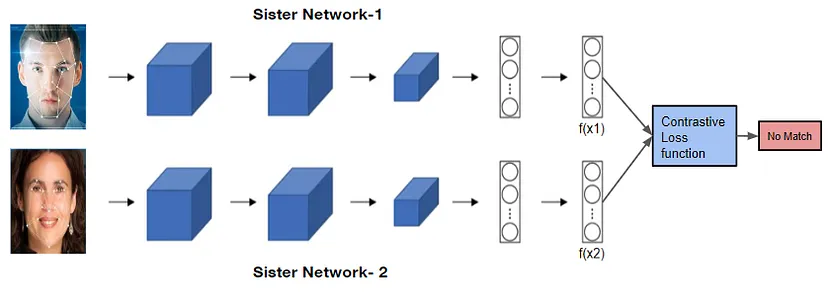
The Siamese network does not learn to classify images into any output categories. Instead, it learns using a similarity function that takes two images as input and provides the probability of how similar these images are. Baidu also uses similar technology to develop a facial recognition system for its employees within the organization.
How do Siamese Neural Networks solve the problems mentioned above?
1) Unlike traditional neural networks in deep learning, Siamese networks do not require many instances of categories; a few instances are sufficient to build a good model.
2) The main advantage of Siamese networks is that in applications like attendance where facial detection is needed, when there are new employees or new classes in our model, the network only needs one facial image of that employee to detect their face. Using this image as a reference image, the network will compute the similarity score for any new instance. This is why we say the network predicts scores in one shot and is referred to as a one-shot learning model.
-
Signature Verification System Using Siamese Networks
Siamese networks can also be used to compare the signature of an account holder with the signature on a check or any document requiring the account holder’s signature, which needs to be verified by bank employees for security purposes.
If the similarity score exceeds a certain threshold (which needs to be determined based on the model’s training performance), the check is accepted; if the similarity score is low, there is a higher likelihood that the signature is forged.
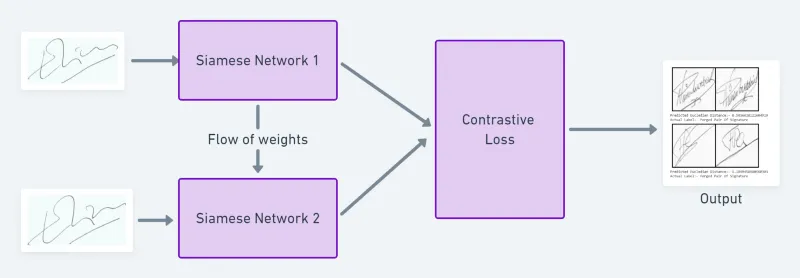
This also makes the system scalable, reduces development time, and even decreases the demand for data and retraining time, making the system more efficient.
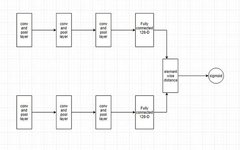
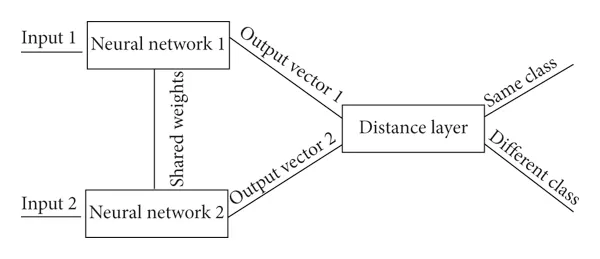
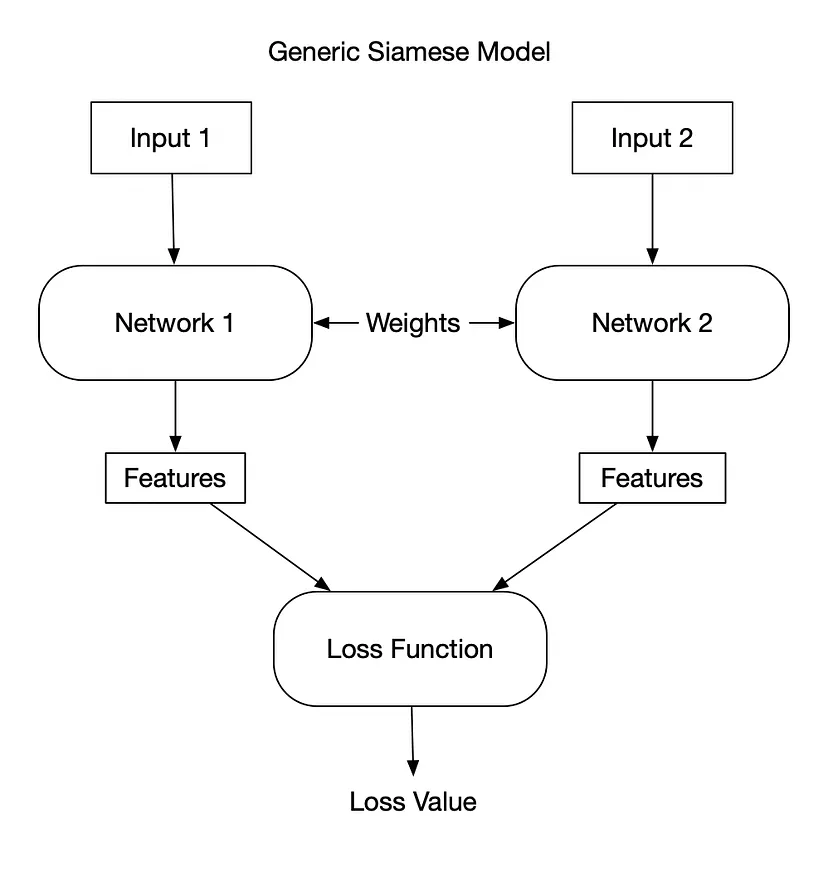
Siamese Neural Network Architecture
A Siamese network is an artificial neural network that consists of two or more identical subnetworks, meaning they have the same configuration, parameters, and weights.
In most cases, we only train one of the N (the number of subnetworks chosen to solve the problem) subnetworks and use the same configuration (parameters and weights) for the other subnetworks.
Siamese networks are used to find the similarity of inputs by comparing their feature vectors.
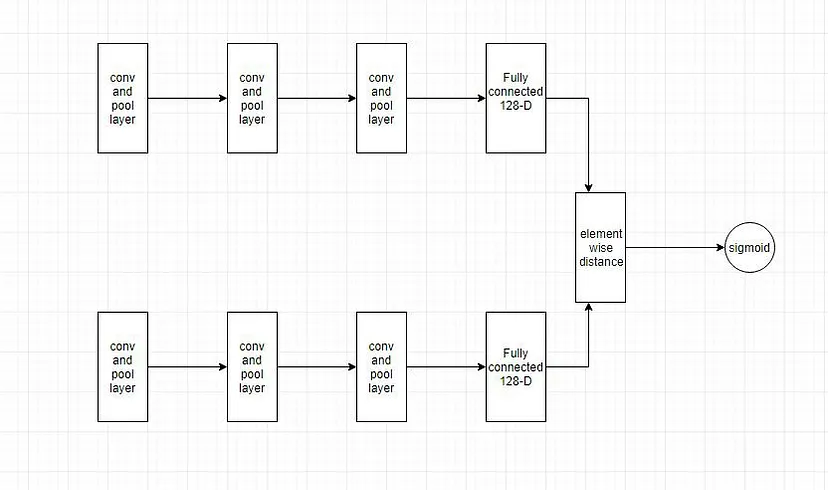
Step-by-step Explanation of How Siamese Network Architecture Works
We have two images, and we want to compare whether they are similar or not.
1. The first subnetwork takes image (A) as input, passes through convolutional layers and fully connected layers, and obtains a vector representation of the image.
2. The second image (B) is then passed through a network with exactly the same weights and parameters.
3. Now we have two encodings E(A) and E(B) from the corresponding images, and we can compare these two encodings to understand how similar the two images are. If the images are similar, the encodings will also be very similar.
4. We will measure the distance between these two vectors; if the distance is small, the two vectors are similar or belong to the same class, while if the distance is larger, the two vectors are different based on the score.
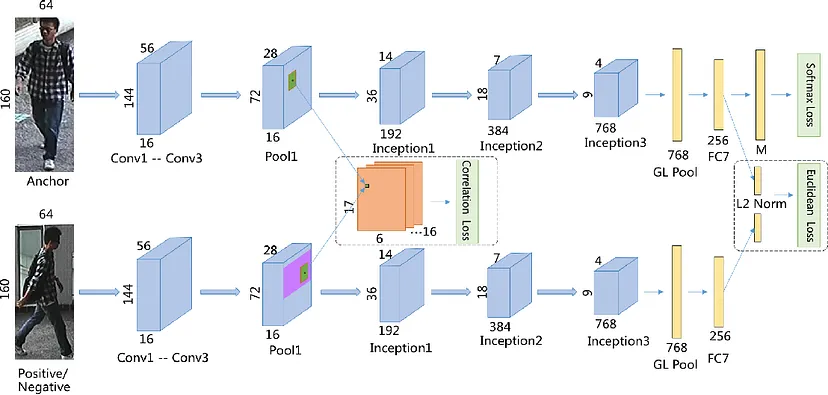
In the Siamese network architecture, the loss function plays a crucial role in distinguishing between pairs of similar and dissimilar images.
Loss Functions in Siamese Networks
Let’s take a look at the two main loss functions in Siamese networks, namely contrastive loss and triplet loss.
-
Contrastive Loss Function
The Siamese network does not classify input images but distinguishes them. Therefore, classification loss functions like cross-entropy are not the best choice.
Instead, this Siamese network architecture is better suited to using contrastive loss.
This function only evaluates the Siamese network’s ability to distinguish between given image pairs.
The formula for the contrastive loss function is as follows:
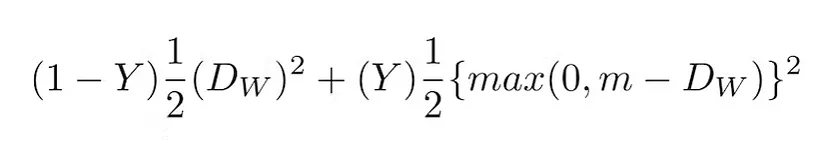
Where Dw is defined as the Euclidean distance between the outputs of the Siamese network.
Mathematically, the formula for Euclidean distance is:
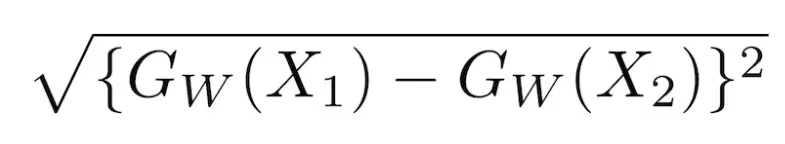
Y is either 1 or 0. If the first image and the second image belong to the same class, the value of Y is 0; otherwise, Y is 1.
max() is a function that represents the higher value between 0 and m-Dw.
m is a threshold greater than 0. The margin indicates that dissimilar pairs beyond this threshold do not lead to loss.
-
Triplet Loss Function
Triplet loss allows our model to map two similar images closer to each other and farther from dissimilar sample image pairs.
This approach is achieved using triplet compositions:
1. Anchor image – this is the reference image.
2. Positive image – this is just another variant of the anchor image.
This helps the Siamese network model learn the similarity between the two images.
3. Negative image – this is an image that is different from the two images above.
This helps our model learn the differences from the anchor image.
Now, to increase the distance between similar and dissimilar output vectors and to map similar images closer together, there is a term called margin. The margin increases the separation between similar and dissimilar vectors and eliminates any trivial solutions for the outputs.
This similarity or dissimilarity is measured by using L2 distance and cosine distance to measure the distance between the two vectors.
This is our loss function, where a is the anchor image, p is the positive image, and n is the negative image.

Advantages and Disadvantages of Siamese Networks
The main advantages or benefits of Siamese networks are:
1. Robustness to Class Imbalance: Due to one-shot learning, a small number of images of the same class (very few training data) is sufficient for the Siamese network to classify these images in the future.
2. Integration with One of the Classifier Algorithms: Due to its learning mechanism being different from classification algorithms, integrating Siamese networks with classifiers can perform better than averaging two related supervised models (e.g., GBM and RF classifier algorithms).
3. Semantic Similarity: The trained Siamese network focuses on learning embeddings that group the same classes together (in deep neural networks). Therefore, it can learn semantic similarity.
The disadvantages or downsides of Siamese networks are:
1. Requires more training time than traditional neural network architectures and machine learning algorithms: Siamese networks involve learning from pairs, which is slower than traditional types of machine learning, but neural networks learn faster than Siamese networks.
2. Does not output probabilities: Since the training of Siamese networks involves pairwise learning, it does not output predicted probabilities but rather outputs distances to each class (using Euclidean distance and other distance formulas) ranging between 0 and 1.
Implementation Process of Siamese Networks
Every machine learning model has three stages: the first is training and validation, the second is testing, and the third is deployment.
For almost all applications developed using Siamese networks, the following steps are the same.
Training the Network
The training process for Siamese networks is as follows:
-
Initialize the Siamese network, loss function, and optimizer (like Adam, Adagrad, SGD, etc.).
-
Pass images from the image pairs one by one through the Siamese network, as the training here involves pairwise learning.
-
Calculate the loss using the outputs of the first and second images.
-
Calculate the model’s gradients through backpropagation.
-
Use the optimizer to update weights to minimize the loss after a certain number of epochs.
-
Once we reach the maximum number of epochs set for the model and obtain the least possible loss.
-
Save the model.
Testing the Model
-
Load test data.
-
Pass image pairs and labels.
-
Find the Euclidean distance between images.
-
Display similar image pairs.
Below is an example of implementing a Siamese network using Keras along with dataset links:
This is another example link for measuring text similarity using Siamese networks:
https://github.com/dimartinot/Text-Semantic-Similarity
How to Improve Siamese Networks or Similarity Learning?
Choice of Loss Function: We have seen two types of loss functions, namely contrastive loss and triplet loss.
We can say that triplet loss is more effective than contrastive loss because it helps us rank and produces better results than other loss functions. But if we could find a better loss function, we could definitely improve the network’s performance.
“Deep Metric Learning with Angular Loss” and “Correcting Triplet Loss’s Triplet Selection Bias” are some methods that can be researched. Recent research papers indicate that we can also use classification loss functions like cross-entropy to train Siamese networks and still achieve good results.
Sampling: The triplets in the dataset (all images) can be sampled in a way to improve the model’s accuracy.
Integration of Siamese Networks with Other Classification Algorithms: We can also use different algorithms and networks and train them on different triplets based on our data.



