
Datawhale Insights
Author: Eternity, Datawhale Member
Datawhale Insights
Author: Eternity, Datawhale Member
Take Home Message: Janus is a simple, unified, and scalable multimodal understanding and generation model that decouples visual encoding from multimodal understanding and generation, alleviating potential conflicts between the two tasks. In the future, it can be expanded to incorporate more input modalities. Janus-Pro builds on this foundation, optimizing training strategies (including increasing training steps, adjusting data ratios, etc.), increasing data (including using synthetic data, etc.), and scaling up the model size (expanded to 7 billion parameters), resulting in improvements in the model’s multimodal understanding and text-to-image instruction following capabilities.

Janus-Pro is an advanced version of the previous work Janus, specifically including (1) optimized training strategies, (2) expanded training data, and (3) larger model size. Through these improvements, Janus-Pro has made significant progress in multimodal understanding and text-to-image instruction following capabilities while also enhancing the stability of text-to-image generation. Before interpreting Janus-Pro, let’s review Janus.
Review of Janus
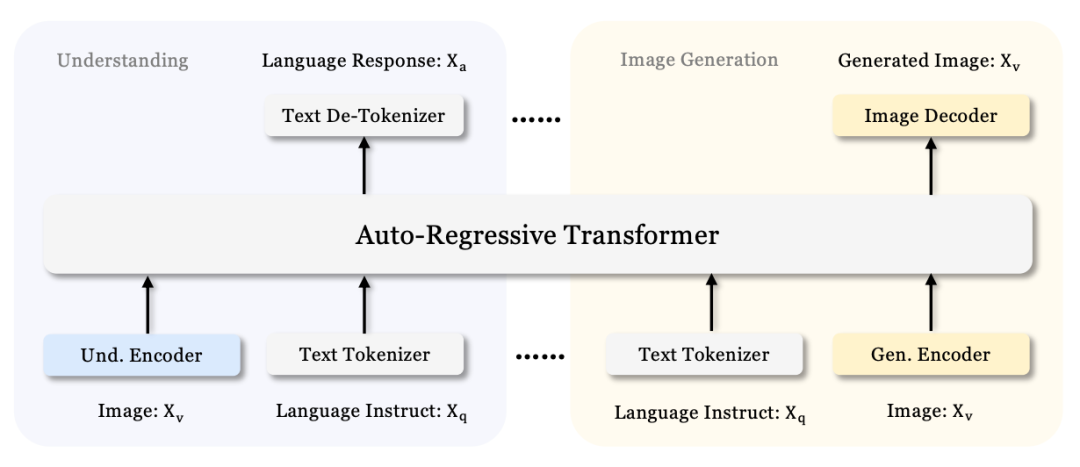
-
For text understanding, use the built-in Tokenizer of the LLM to convert text into discrete IDs; -
For multimodal understanding, use the SigLIP encoder to extract high-dimensional semantic features from images (Note: The SigLIP encoder is also used in the Guardrails section of Cosmos), and use an Adaptor (2-layer MLP) to map the extracted features to the text feature space of the LLM;
-
Long edge adjusted to 384 pixels, using RGB(127, 127, 127) to pad the short edge to 384 pixels; -
For visual generation, use the VQ Tokenizer to convert images into discrete IDs, and use an Adaptor (2-layer MLP) to map each ID to the text feature space of the LLM;
-
Short edge adjusted to 384 pixels, long edge cropped to 384 pixels; -
The overall training uses 16 nodes, each containing 8 Nvidia A100 GPUs;
-
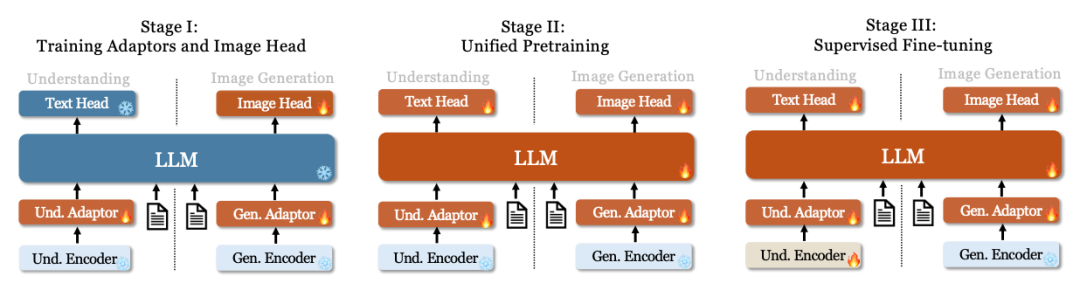
Stage 1: Train Adaptor and Image Head, creating a connection between language elements and visual elements in the embedding space, enabling the LLM to understand entities in images and acquire preliminary visual generation capabilities;
-
For multimodal understanding, use 1.25 million image-text paired subtitle data from SHareGPT4V, format: <image><text>;
-
For visual generation, use 1.2 million samples from ImageNet1k, format: <category name><image>;
-
Stage 2: Unified Pre-training, using a multimodal corpus for unified pre-training to learn multimodal understanding and generation. This stage uses pure text data, multimodal understanding data, and visual generation data. Simple visual generation training is conducted using ImageNet-1k, followed by using general text-to-image data to enhance the model’s visual generation capability in open domains;
-
Pure text data: DeepSeek-LLM pre-training corpus;
-
Interleaved image-text data: WikiHow and WIT datasets;
-
Image Caption Data: Images from multiple sources, with some images re-captioned using open-source multimodal models, data format is question-answer pairs, such as <image>Describe the image in detail.<caption>;
-
Table and Chart Data: Corresponding table and chart data from DeepSeek-VL, data format is <question><answer>;
-
Visual Generation Data: Image-caption pairs from multiple datasets and 2 million internal data;
-
During training, there is a 25% probability of randomly using only the first sentence of the caption;
-
ImageNet samples only appear in the initial 120K training steps, while images from other datasets appear in subsequent 60K steps;
-
Stage 3: Supervised Fine-tuning, fine-tune the pre-trained model using instruction fine-tuning data to enhance its ability to follow instructions and engage in dialogue. All parameters except the generation encoder are fine-tuned. While supervising answers, both system and user prompts are masked. To ensure that Janus is proficient in both multimodal understanding and generation, the model is not fine-tuned for specific tasks separately. Instead, we use a mix of pure text dialogue data, multimodal understanding data, and visual generation data to ensure versatility across various scenarios;
-
Text Understanding: Using data from specific sources;
-
Multimodal Understanding: Using instruction tuning data from multiple sources;
-
Visual Generation: Using a subset of image-text pairs from some second-stage datasets and 4 million internal data;
-
Data format is: User:<Input Message>
Assistant: <Response>;
Training Objectives
Janus is an autoregressive model, trained using cross-entropy loss function, calculating loss on the text sequences for pure text understanding and multimodal understanding tasks. For visual generation tasks, loss is calculated only on the image sequences. To keep the design simple, no different loss weights are assigned to different tasks.
Inference
Using the next token prediction method, for pure text understanding and multimodal understanding, tokens are sequentially sampled from the prediction distribution. For image generation, classifier-free guidance is used.
Possible Extensions
-
For multimodal understanding, 1) choose stronger visual encoders, 2) use dynamic high-resolution techniques;
-
For visual generation, 1) select more fine-grained encoders, 2) use loss functions specifically designed for visual generation, 3) combine causal attention and parallel methods;
-
More modalities, able to integrate 3D point clouds, haptic, EEG, and other input modalities;
Janus-Pro Upgrade
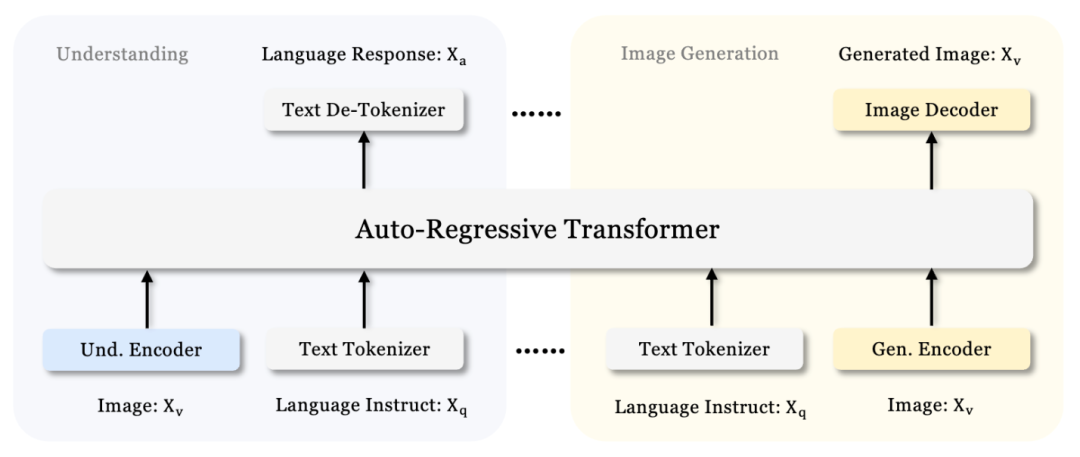
Janus has limited training data and a relatively small model capacity (1B), leading to shortcomings in some aspects, such as poor image generation representation under short prompts and unstable quality of text-to-image generation. The architecture of Janus-Pro is the same as Janus, as shown in the figure below:
Main Improvements
-
Training Strategies -
Stage 1: Increase training steps, fully train on ImageNet;
-
Stage 2: No longer use ImageNet, directly use regular text-to-image training data;
-
Stage 3: Modify the data ratio in the fine-tuning process, changing the ratio of multimodal data, pure text data, and text-to-image from 7:3:10 to 5:1:4; -
Data Scale -
Multimodal Understanding
-
Stage 2: Increase by 90 million samples, including image caption data YFCC, table and chart document understanding data Doc-matrix;
-
Stage 3: Add additional datasets from DeepSeek-VL2, such as MEME understanding; -
Visual Generation: Real-world data may contain low quality, leading to unstable text-to-image generation and producing aesthetically poor outputs. Janus-Pro uses 72 million synthetic aesthetic data samples, with a 1:1 ratio of real data to synthetic data in the unified pre-training stage (Stage 2); -
Model Scale -
Expanding model parameters to 7 billion parameters;
Experimental Details
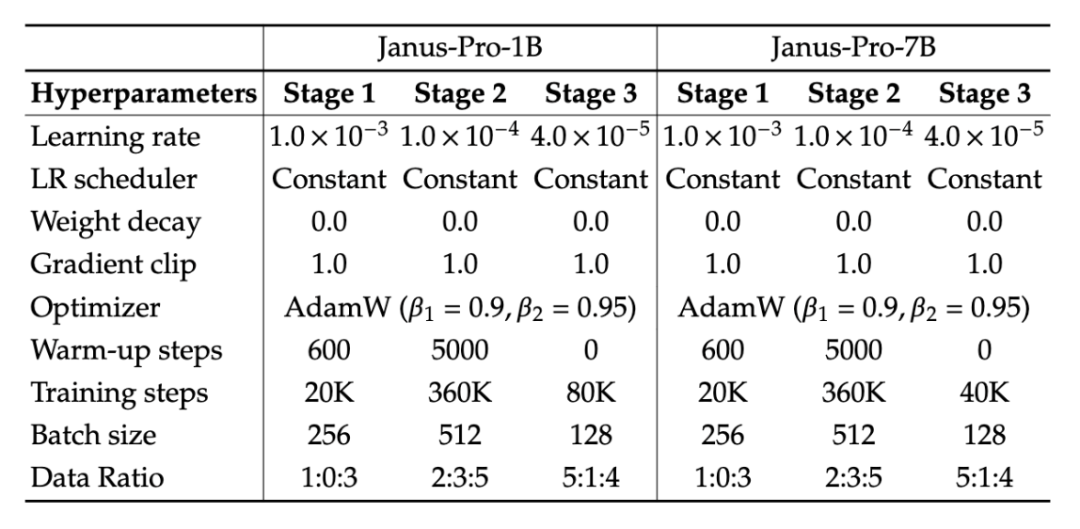
Compared to Janus, the experimental details of Janus-Pro are basically the same. In contrast, the larger parameter model uses more cluster nodes (from 16 to 32).
Shortcomings
For multimodal understanding, the input resolution is limited to 384×384, affecting the performance of fine-grained visual tasks. For text-to-image generation, low resolution leads to a lack of detail in the generated results.
 Let’s “Like” the Three连↓
Let’s “Like” the Three连↓