

01
Introduction
Following the successful launch of DeepSeek-V3 and DeepSeek-R1, DeepSeek has introduced an enhanced version of the Janus multimodal model, Janus-Pro, continuing to push the boundaries of artificial intelligence. In the rapidly evolving field of AI, multimodal models that can seamlessly understand and generate text and image content are becoming increasingly important. Janus-Pro represents a significant leap in this field, featuring optimized training strategies, expanded datasets, and architectural innovations. This advanced model sets a new benchmark for multimodal understanding and text-to-image generation. This article explores the major advancements, architectural framework, and performance metrics of Janus-Pro, while also addressing its limitations and potential areas for improvement.

02
Janus-Pro is an advanced version of DeepSeek’s Janus multimodal model, designed to excel in understanding and generating content involving text and images. The model is based on the foundational principles established by Janus and introduces several key advanced technologies that make it stand out:
-
Optimized Training Strategy: Janus-Pro employs a more efficient training strategy, focusing on better utilization of data and resources. -
Expanded Training Dataset: The model combines real data sources and synthetic data, enhancing its robustness and adaptability. -
Larger Model Scale: The parameter scale of Janus-Pro ranges from 1 billion (1B) to 7 billion (7B), improving performance and stability, especially in tasks such as text-to-image generation and multimodal understanding.
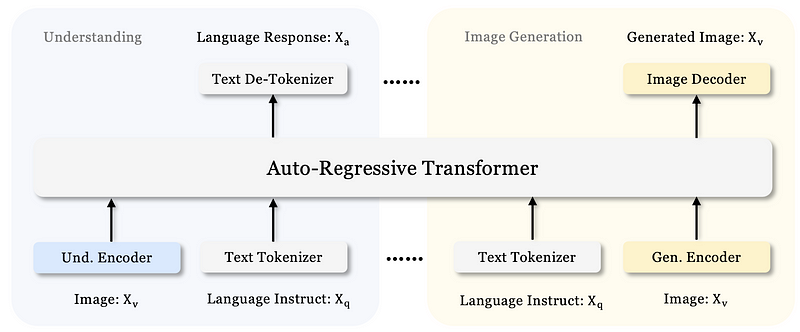
03
-
Multimodal Understanding: Using the SigLIP encoder to extract semantic features and mapping these features into the LLM’s space through understanding adapters. -
Text-to-Image Generation: Utilizing VQ Tokenizer and generative adapters to embed code libraries into the LLM’s input space.
The two feature sequences are concatenated and input to the LLM, which generates the final output in an autoregressive manner. Additionally, Janus-Pro includes a randomly initialized prediction head for image prediction in visual generation tasks.
04
At the core of the Janus-Pro architecture is the concept of decoupled visual encoding, which processes images using different encoding methods based on the task at hand. Here’s how it works:
-
Understanding Tasks: For tasks such as image description or visual question answering, Janus-Pro employs a semantic encoder called SigLIP to extract meaningful features from images.
-
Generation Tasks: For tasks like text-to-image generation, the model uses VQ Tokenizer and adapters to convert images into discrete IDs, which are then used to generate new images.
05
The optimized training strategy of Janus-Pro plays a crucial role in enhancing its capabilities. The training process is divided into three stages, each with specific objectives:
-
First Stage: In this stage, the focus is on training the adapters and image heads using datasets like ImageNet. Keeping the parameters of the large language model (LLM) fixed allows the model to effectively capture pixel dependencies.
-
Second Stage: In this stage, ImageNet data is no longer used; instead, conventional text-to-image data is used to train the model directly. This shift allows for more effective utilization of text-to-image data, improving overall performance and training efficiency.
-
Third Stage: During supervised fine-tuning, the data ratio is adjusted to prioritize multimodal understanding without compromising visual generation capabilities. This ensures that Janus-Pro excels in both understanding and generation tasks.
06
Data scale expansion is another key factor in the improvements of Janus-Pro. The model benefits from a larger training dataset for multimodal understanding and visual generation:
-
Multimodal Understanding: Janus-Pro adds approximately 90 million samples from various sources such as YFCC, Doc-matix, and DeepSeek-VL2, covering content like dialogues and task understanding.
-
Visual Generation: The model replaces real-world data with a balanced combination of real and synthetic data, containing about 72 million synthetic aesthetic samples. This expansion enhances Janus-Pro’s ability to generate stable and visually appealing images.
By leveraging larger and more diverse datasets, Janus-Pro’s capabilities become more comprehensive, allowing it to adapt to a wider range of tasks and input types.
07
Let’s take a look at the performance of the model:
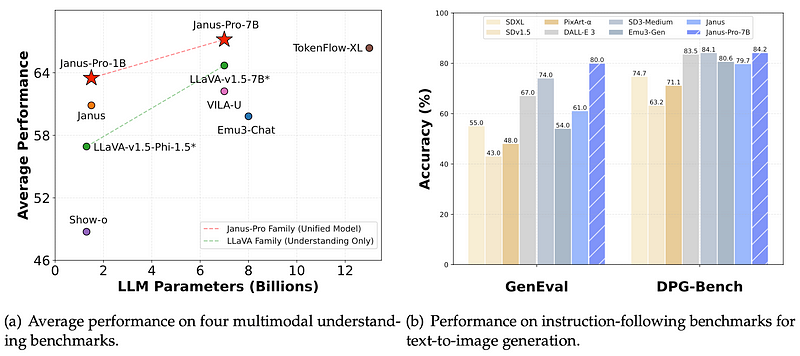
Janus-Pro performs exceptionally well in multimodal understanding benchmarks, surpassing state-of-the-art models across various metrics. Notably:
-
In the MMBench benchmark, Janus-Pro-7B scored 79.2, outperforming competitors such as Janus, TokenFlow, and MetaMorph.
-
While some specialized models may perform well on specific tasks, Janus-Pro consistently ranks among the top in multiple benchmarks such as POPE, MME, MMB, and MMMU.
Janus-Pro also excels in text-to-image generation tasks, achieving impressive results in benchmarks such as GenEval and DPG-Bench:
-
In GenEval, Janus-Pro-7B scored 0.80, surpassing models like DALL-E 3 and Stable Diffusion 3 Medium.
-
On DPG-Bench, Janus-Pro achieved a score of 84.19, again outperforming competitors such as DALL-E 3 and Stable Diffusion 3 Medium.
These high scores indicate that Janus-Pro is adept at generating detailed, semantically coherent images according to simple or complex instructions.

08
Despite its many advantages, Janus-Pro also has some limitations:
-
Resolution Limitations: The model’s maximum input resolution is 384×384, which may hinder performance on tasks that require fine details, such as Optical Character Recognition (OCR).
-
Image Quality: Similarly, the resolution limitations and the compression techniques used by the VQ tokenizer can lead to images lacking in detail, especially in small facial areas.
Researchers believe that improving image resolution could help address these limitations, potentially leading to greater performance gains.
09
Janus-Pro has made significant strides in the field of multimodal AI models, excelling in understanding and generating content across text and images. With optimized training strategies, expanded datasets, and a unique architectural framework, Janus-Pro sets a new benchmark for versatility and effectiveness in multimodal tasks.
While there are still areas for improvement, particularly in image resolution, Janus-Pro demonstrates the rapid advancements in AI research. As we continue to challenge the limits of machines, models like Janus-Pro will undoubtedly play a key role in the future development of artificial intelligence.
Reference Document: https://github.com/deepseek-ai/Janus/blob/main/janus_pro_tech_report.pdf
Reference Code: https://github.com/deepseek-ai/Janus
Click the card above to follow me
Add me on WeChat to join the exclusive fan group!
