
Author: JayLou, NLP Algorithm Engineer
Zhihu Column: High Energy NLP Journey
This article is authorized, click “Read the original” at the end:
https://zhuanlan.zhihu.com/p/56382372
This article summarizes word vectors in natural language processing in a Q&A format: including Word2Vec, GloVe, FastText, ELMo, and BERT.
Table of Contents
1. Text Representation and Comparison of Word Vectors 1. What methods are there for text representation? 2. How to understand word vectors from language models? How to understand the distributional hypothesis? 3. What problems exist with traditional word vectors? How to solve them? What are the characteristics of various word vectors? 4. What are the differences between Word2Vec and NNLM? (Word2Vec vs NNLM) 5. What are the differences between Word2Vec and FastText? (Word2Vec vs FastText) 6. What are the differences between GloVe, Word2Vec, and LSA? (Word2Vec vs GloVe vs LSA) 7. What are the differences between ELMo, GPT, and BERT? (ELMo vs GPT vs BERT) 2. In-depth Analysis of Word2Vec 1. What are the two models of Word2Vec? 2. What are the two optimization methods of Word2Vec? How are their objective functions determined? What is the training process? 3. In-depth Analysis of GloVe 1. What is the construction process of GloVe? 2. What is the training process of GloVe? 3. How is the loss function of GloVe determined? 4. In-depth Analysis of BERT (Comparing with ELMo and GPT) 1. Why does BERT use a bidirectional Transformer Encoder instead of a decoder? 2. What are the differences in handling unidirectional and bidirectional language models between ELMo, GPT, and BERT? 3. Is it really simple for BERT to construct a bidirectional language model? Could it not just concatenate the Transformer decoder like ELMo? 4. Why use Marked LM instead of directly applying the Transformer Encoder? 5. Why doesn’t BERT always replace masked words with the actual [MASK] token?
1. Text Representation and Comparison of Word Vectors
1. What methods are there for text representation?
Here’s a summary of text representation, i.e., how can a piece of text be represented mathematically?
-
Bag-of-words based on one-hot, tf-idf, textrank, etc.;
-
Topic models: LSA (SVD), pLSA, LDA;
-
Fixed representation based on word vectors: Word2Vec, FastText, GloVe;
-
Dynamic representation based on word vectors: ELMo, GPT, BERT;
2. How to understand word vectors from language models? How to understand the distributional hypothesis?
The four types mentioned above are the most commonly used text representations in the NLP field. Text is composed of each word, and when discussing word vectors, one-hot can be considered the simplest form of word vector, but it has problems such as the curse of dimensionality and semantic gap; constructing a co-occurrence matrix and using SVD to build word vectors leads to high computational complexity; early research on word vectors usually originated from language models, such as NNLM and RNNLM, whose main purpose is the language model, and word vectors are merely a byproduct.
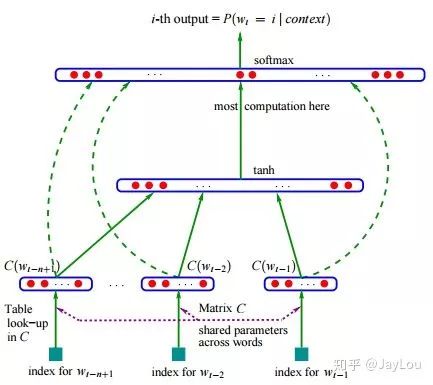
The so-called distributional hypothesis can be expressed in one sentence: words with similar contexts have similar meanings. This leads to Word2Vec and FastText; in these types of word vectors, although their essence is still a language model, their goal is not the language model itself, but the word vectors. The series of optimizations they perform are all aimed at obtaining word vectors faster and better. GloVe, on the other hand, constructs word vectors based on global corpora, combining the context to leverage the advantages of LSA and Word2Vec.

3. What problems exist with traditional word vectors? How to solve them? What are the characteristics of various word vectors?
The word vectors obtained through the above methods are fixed representations and cannot solve the issue of polysemy, such as “Trump”. To address this, dynamic representation methods based on language models have been introduced: ELMo, GPT, and BERT.
Characteristics of various word vectors:
(1) One-hot representation: curse of dimensionality, semantic gap;
(2) Distributed representation:
-
Matrix decomposition (LSA): uses global corpus features, but SVD solution has high computational complexity;
-
Word vectors based on NNLM/RNNLM: word vectors are byproducts, leading to inefficiency;
-
Word2Vec, FastText: high optimization efficiency, but based on local corpora;
-
GloVe: based on global corpora, combining the advantages of LSA and Word2Vec;
-
ELMo, GPT, BERT: dynamic features;
4. What are the differences between Word2Vec and NNLM? (Word2Vec vs NNLM)
1) Both can essentially be seen as language models;
2) Word vectors are merely a byproduct of NNLM; while Word2Vec is also essentially a language model, it focuses on the word vectors themselves, thus performing many optimizations to improve computational efficiency:
-
Compared to NNLM, Word2Vec directly sums the word vectors instead of concatenating them and discards the hidden layer;
-
Considering that softmax normalization requires traversing the entire vocabulary, hierarchical softmax and negative sampling are used for optimization. Hierarchical softmax essentially generates a weighted path-minimal Huffman tree, reducing the search path for high-frequency words; negative sampling is more direct, effectively performing negative sampling for each word in each sample;
5. What are the differences between Word2Vec and FastText? (Word2Vec vs FastText)
1) Both can learn word vectors unsupervised, but FastText considers subwords during training;
2) FastText can also perform supervised learning for text classification, with the following main characteristics:
-
Structure similar to CBOW, but the learning objective is the manually labeled classification result;
-
Uses hierarchical softmax to establish a Huffman tree for the output classification labels, assigning shorter search paths to categories with more labels in the sample;
-
Introduces N-grams, considering word order features;
-
Introduces subwords to handle long words and address out-of-vocabulary issues;
6. What are the differences between GloVe, Word2Vec, and LSA? (Word2Vec vs GloVe vs LSA)
1) GloVe vs LSA
-
LSA (Latent Semantic Analysis) can construct word vectors based on the co-occurrence matrix, essentially using global corpora for SVD matrix decomposition, but SVD has high computational complexity;
-
GloVe can be seen as an efficient matrix decomposition algorithm optimized from LSA, using Adagrad to optimize the least square loss;
2) Word2Vec vs GloVe
-
Word2Vec is trained on local corpora, with feature extraction based on sliding windows; GloVe’s sliding window is used to construct the co-occurrence matrix, based on global corpora, indicating that GloVe needs to pre-statistic co-occurrence probabilities; thus, Word2Vec can perform online learning, while GloVe needs to gather fixed corpus information.
-
Word2Vec is unsupervised learning, while GloVe is commonly considered unsupervised learning, but in reality, GloVe does have labels, i.e., co-occurrence counts.
-
The loss function of Word2Vec is essentially a weighted cross-entropy with fixed weights; GloVe’s loss function is a least square loss function, with weights that can undergo mapping transformations.
-
Overall, GloVe can be seen as a global Word2Vec with changed objective and weight functions.
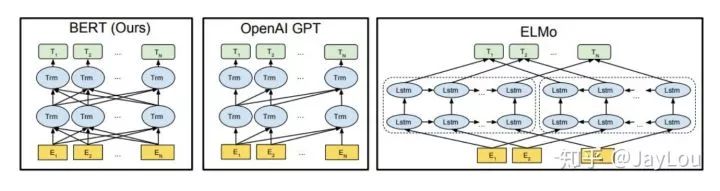
7. What are the differences between ELMo, GPT, and BERT? (ELMo vs GPT vs BERT) Previously, the introduced word vectors were all static word vectors, which could not solve the issue of polysemy. Below we will introduce three types of word vectors: ELMo, GPT, and BERT, all of which are dynamic word vectors based on language models. We will compare these three from several aspects:
(1) Feature Extractors: ELMo uses LSTM for extraction, while GPT and BERT use Transformers for extraction. Many tasks indicate that the feature extraction capability of Transformers is stronger than that of LSTM. ELMo uses 1 layer of static vectors + 2 layers of LSTM, with limited multi-layer extraction capability, while GPT and BERT’s Transformers can utilize multiple layers and have strong parallel computing capabilities.
(2) Unidirectional/Bidirectional Language Models:
-
GPT uses a unidirectional language model, while ELMo and BERT use bidirectional language models. However, ELMo is actually a concatenation of two independently trained unidirectional language models (in opposite directions), which is weaker in feature fusion capability than BERT’s integrated fusion method.
-
Both GPT and BERT use Transformers, which have an encoder-decoder structure. GPT’s unidirectional language model uses the decoder part, where the decoder only sees incomplete sentences; BERT’s bidirectional language model uses the encoder part, which uses complete sentences.
2. In-depth Analysis of Word2Vec
1. What are the two models of Word2Vec?
Word2Vec has two models: CBOW and Skip-Gram:
-
CBOW predicts
wgivencontext(w); -
Skip-Gram predicts
context(w)givenw;
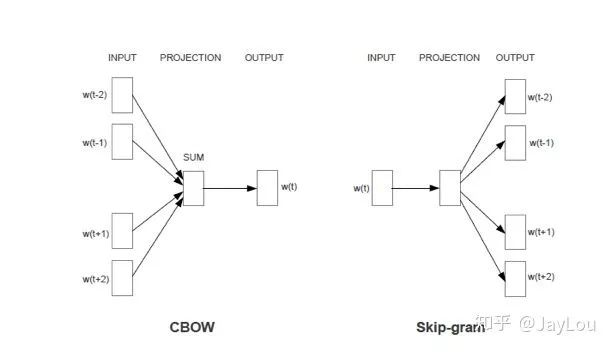
Compared to NNLM, the main goal of Word2Vec is to generate word vectors rather than language models. In CBOW, the projection layer directly sums the word vectors instead of concatenating them, and discards the hidden layer; these sacrifices are all aimed at reducing computational load and making training more efficient.
2. What are the two optimization methods of Word2Vec? How are their objective functions determined? What is the training process?
In unoptimized CBOW and Skip-gram, the training process for each word in each sample must traverse the entire vocabulary, which requires softmax normalization, calculating error vectors and gradients to update two word vector matrices (these two word vector matrices are essentially the final word vectors, which can be seen as having different initializations). As the corpus size grows and the vocabulary expands, training becomes impractical. To solve this problem, Word2Vec supports two optimization methods: hierarchical softmax and negative sampling. This section provides only key introductions; for mathematical derivations, please refer to “Mathematical Principles of Word2Vec”.
(1) Hierarchical Softmax Based CBOW and Skip-gram
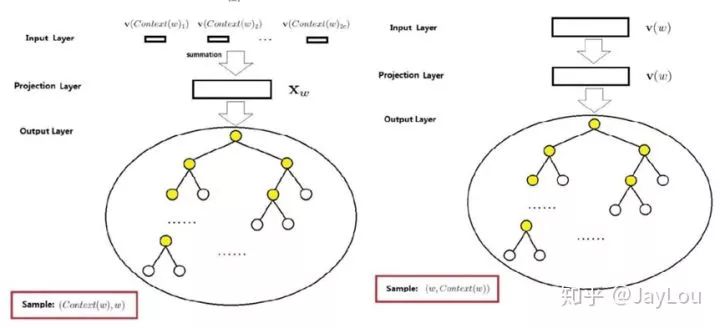
Hierarchical softmax uses a binary tree to represent the words in the vocabulary, with each word as a leaf node. For a vocabulary size of V, the corresponding binary tree contains V-1 non-leaf nodes. If each non-leaf node is marked as 1 for left turn and 0 for right turn, then each word has a unique code composed of {0, 1} from the root node to reach that leaf node (essentially Huffman coding, where the Huffman tree is the shortest path length tree, ensuring that high-frequency words have shorter paths and lower-frequency words have longer paths, greatly reducing computational load).
The objective function in CBOW aims to maximize the conditional probability  , which is equivalent to:
, which is equivalent to:
In Skip-gram, the objective function aims to maximize the conditional probability  , which is equivalent to:
, which is equivalent to:
(2) Negative Sampling Based CBOW and Skip-gram
Negative sampling is a different optimization strategy compared to hierarchical softmax; compared to hierarchical softmax, negative sampling is more direct—it provides negative samples for each training instance.
For CBOW, the objective function is to maximize:
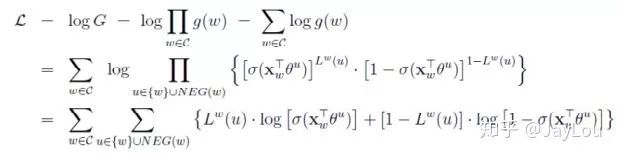
For Skip-gram, the objective function is to maximize:
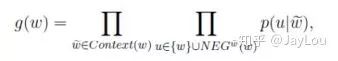
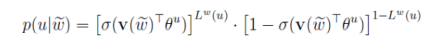
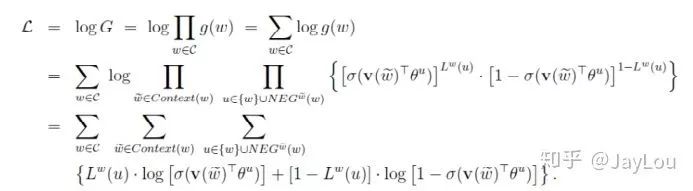
The negative sampling algorithm is essentially a weighted sampling process, where the negative sample selection mechanism is linked to word frequency.

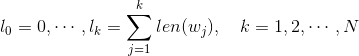
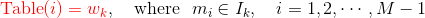
The specific approach is to make non-equidistant divisions of the interval [0,1] with N+1 points, and introduce M equidistant divisions in the interval [0,1], where M >> N. In the source code, M = 10^8 is chosen. Then the two divisions are projected to obtain a mapping relationship: during sampling, each time an integer i between [1, M-1] is generated, Table(i) corresponds to a sample; when sampling a positive example, it is skipped (rejection sampling).
3. In-depth Analysis of GloVe
GloVe stands for Global Vectors for Word Representation, which is a word representation tool based on global word frequency statistics (count-based & overall statistics).
1. What is the construction process of GloVe?
(1) Build a co-occurrence matrix based on the corpus, where each element  represents the frequency of word
represents the frequency of word  and context word
and context word  appearing together within a specific context window size.
appearing together within a specific context window size.
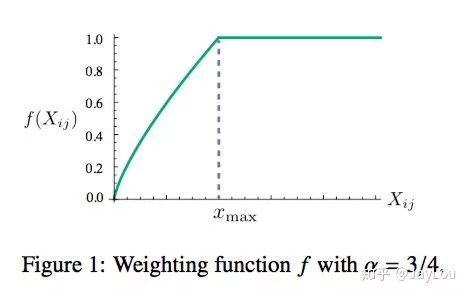
(2) Construct the approximate relationship between word vectors (Word Vector) and the co-occurrence matrix, with the objective function being:  This loss function’s basic form is the simplest mean square loss, but it adds a weight function
This loss function’s basic form is the simplest mean square loss, but it adds a weight function  :
:
Experiments have shown that  has little effect on the results, and the original authors adopted
has little effect on the results, and the original authors adopted  . The results when
. The results when  is used are better than when
is used are better than when  is used. Below is the function graph when
is used. Below is the function graph when  is used:
is used:
2. What is the training process of GloVe?
-
It is essentially supervised learning: although GloVe does not require manual labeling and is considered unsupervised learning, it still has labels, which are
 .
. -
The vectors
 and
and  are the learning parameters. The training method is essentially the same as that of supervised learning, using the AdaGrad gradient descent algorithm, randomly sampling all non-zero elements in the matrix
are the learning parameters. The training method is essentially the same as that of supervised learning, using the AdaGrad gradient descent algorithm, randomly sampling all non-zero elements in the matrix  , setting the learning rate to 0.05, iterating 50 times for vector sizes less than 300, and iterating 100 times for other sizes until convergence.
, setting the learning rate to 0.05, iterating 50 times for vector sizes less than 300, and iterating 100 times for other sizes until convergence. -
The final learned word vectors are
 and
and  . Since
. Since  is symmetric, from a theoretical standpoint,
is symmetric, from a theoretical standpoint,  and
and  are also symmetric. Their only difference lies in their initial values, resulting in different final values. Thus, these two are essentially equivalent and can both be used as final results. However, to enhance robustness, we ultimately choose the sum of both
are also symmetric. Their only difference lies in their initial values, resulting in different final values. Thus, these two are essentially equivalent and can both be used as final results. However, to enhance robustness, we ultimately choose the sum of both  as the final vector (the different initializations act as different random noise, thus enhancing robustness).
as the final vector (the different initializations act as different random noise, thus enhancing robustness).
3. How is the loss function of GloVe determined? (From GloVe Explanation)



4. In-depth Analysis of BERT (Comparing with ELMo and GPT)
BERT stands for Bidirectional Encoder Representation from Transformers. The core of BERT is the bidirectional Transformer Encoder, which poses the following questions and provides answers:
1. Why does BERT use a bidirectional Transformer Encoder instead of a decoder?
BERT Transformer uses bidirectional self-attention, while GPT Transformer uses restricted self-attention, where each token can only process its left context. Bidirectional Transformers are generally referred to as “Transformer encoders,” while left context is called “Transformer decoders”; the decoder cannot obtain the information to be predicted.
2. What are the differences in handling unidirectional and bidirectional language models between ELMo, GPT, and BERT?
Among the three models mentioned above, only BERT relies on both left and right contexts. But isn’t ELMo bidirectional? In fact, ELMo uses two independently trained LSTMs, one from left to right and the other from right to left, which is weaker in feature fusion capability than BERT’s integrated fusion method. GPT uses a left-to-right Transformer, essentially a “Transformer decoder”.
3. Is it really simple for BERT to construct a bidirectional language model? Could it not just concatenate the Transformer decoder like ELMo?
The authors of BERT believe that this concatenated bidirectional method still cannot fully understand the semantics of an entire sentence. A better approach is to use full-context predictions for masked tokens, i.e., using “can/achieve/language/representation/…/model” to predict [MASK]. The authors refer to this full-context prediction method as deep bidirectional.
4. Why use Marked LM instead of directly applying the Transformer Encoder?
It is known that the deeper the Transformer, the better the learning effect. But why not directly apply a bidirectional model? Because increasing the depth of the network leads to label leakage. As shown in the figure below:
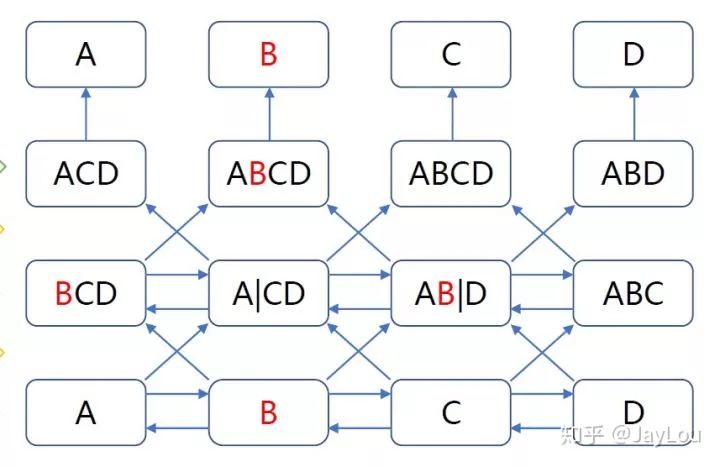
Deep bidirectional models are more powerful than shallow connections of left-to-right models or left-to-right and right-to-left models. Unfortunately, standard conditional language models can only be trained from left to right or right to left, as bidirectional conditional effects would allow each word to indirectly “see itself” in multiple layers of context.
To train a deep bidirectional representation, the research team adopted a simple method: randomly masking some input tokens and only predicting those that are masked. This process is referred to as “masked LM” (MLM) in the paper.
5. Why doesn’t BERT always replace masked words with the actual [MASK] token?
Essential Reading for NLP | Understand Google BERT Model in Ten Minutes: While this indeed allows the team to obtain a bidirectional pre-training model, this method has two drawbacks. First, there is a mismatch between pre-training and fine-tuning, as the [MASK] token is never seen during fine-tuning. To address this, the team does not always replace the masked words with the actual [MASK] token. Instead, the data generator randomly selects 15% of the tokens. For example, in the sentence “my dog is hairy,” the selected token is “hairy.” The data generator performs the following actions instead of always replacing the selected word with [MASK]: 80% of the time: replace the word with the [MASK] token, e.g., my dog is hairy → my dog is [MASK]; 10% of the time: replace the word with a random word, e.g., my dog is hairy → my dog is apple; 10% of the time: keep the word unchanged, e.g., my dog is hairy → my dog is hairy. The purpose of this approach is to bias the representation towards the actual observed words. The Transformer encoder does not know which words it will be asked to predict or which words have been replaced with random words, so it is forced to maintain the distributed contextual representation of each input token. Moreover, since random replacements only occur in 1.5% of all tokens (i.e., 15% of 10%), this seemingly does not impair the model’s language understanding ability. The second drawback of using MLM is that each batch only predicts 15% of the tokens, indicating that the model may require more pre-training steps to converge. The team demonstrated that MLM converges slightly slower than left-to-right models (which predict every token), but the performance gains from the MLM model far exceed the increased training costs.
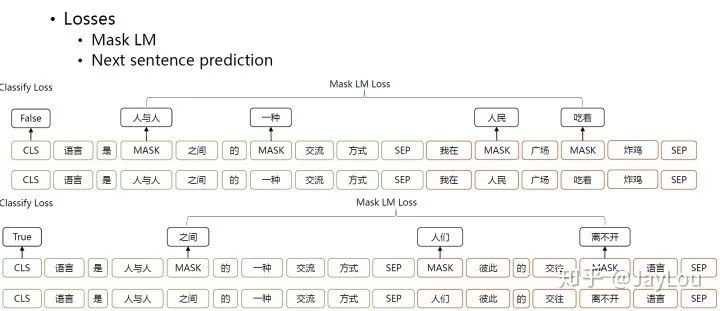
The main innovations of the BERT model lie in the pre-training methods, which utilize Masked LM and Next Sentence Prediction to capture word and sentence-level representations.
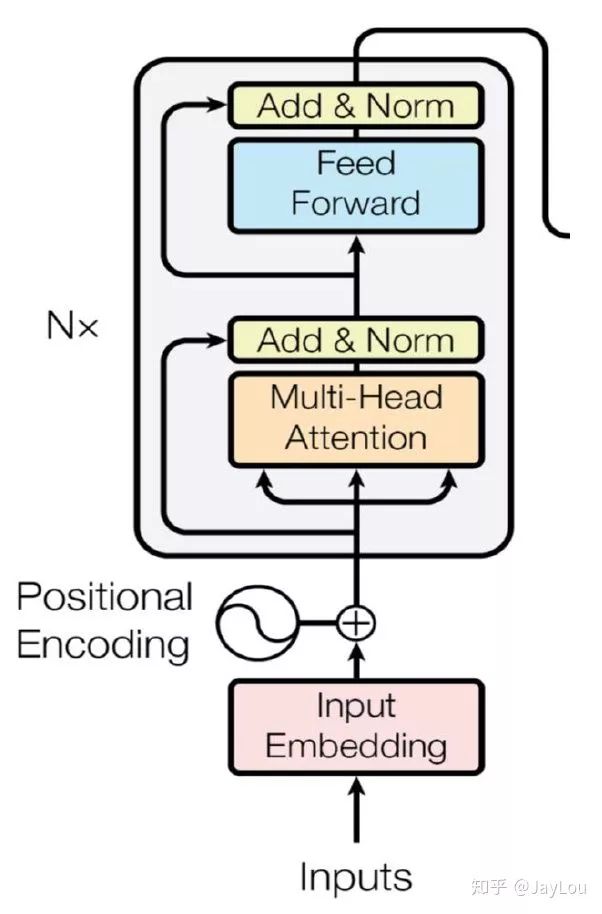
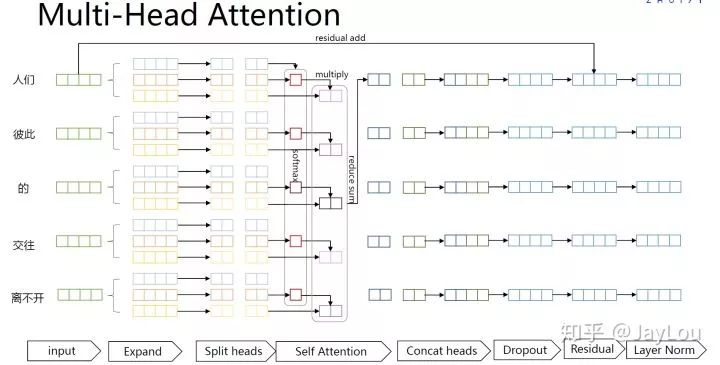
Below is the overall structure of the Transformer Encoder model:
Reference
-
Mathematical Principles of Word2Vec
-
GloVe Explanation
-
From Word Embedding to BERT Model—A History of Pre-training Techniques in Natural Language Processing
-
Essential Reading for NLP | Understand Google BERT Model in Ten Minutes
-
Google BERT Analysis—Get Started with the Most Powerful NLP Training Model in Two Hours