Author: louwill
From: Deep Learning Notes
Language models are one of the core concepts in natural language processing. Word2Vec is a neural network-based language model and a method for word representation. Word2Vec includes two structures: skip-gram and CBOW (Continuous Bag of Words), but essentially both are operations for dimensionality reduction of vocabulary.
We view NLP language models as a supervised learning problem: given context words, output the target word, or given the target word, output the context words. The mapping between input and output defines the language model. The purpose of such a language model is to check if the arrangement conforms to the rules of natural language; to put it more simply, it checks if it makes sense.
Thus, based on the idea of supervised learning, the protagonist of this article—Word2Vec—is a natural language model trained based on neural networks. Word2Vec is an NLP analysis tool proposed by Google in 2013, characterized by vectorizing vocabulary, allowing us to quantitatively analyze and mine the relationships between words. Therefore, Word2Vec is also a type of word embedding representation discussed in the previous lecture, except that this vectorized representation requires training through a neural network.
Word2Vec trains a neural network to obtain a language model regarding the relationship between input and output. Our focus is not on how well this model is trained, but rather on obtaining the trained neural network weights, which are used for the vectorized representation of input vocabulary. Once we have the word vectors for all vocabulary in the training corpus, subsequent NLP research becomes relatively easier.
Word2Vec includes two models. One is the CBOW model, which predicts the target word given context words, and the other is the skip-gram model, which predicts the context based on a given word.
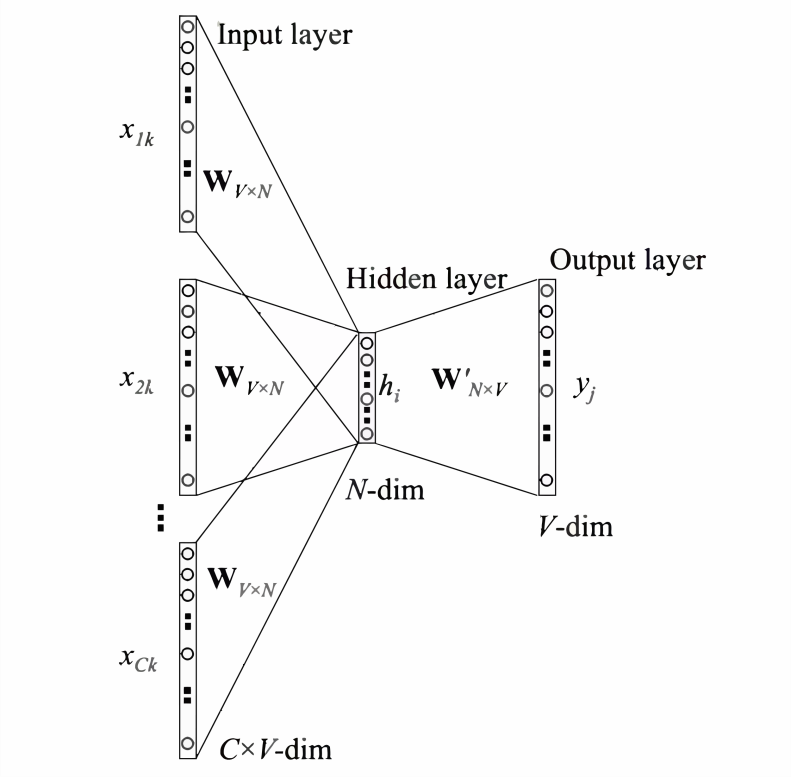
The application scenario of the CBOW model is to predict the target word based on context, so our input is the context words. Of course, the original words cannot be used as input; here, the input is still the one-hot vector of each vocabulary, and the output is the probability of each word in the given vocabulary being the target word. The structure of the CBOW model is shown in Figure 1.
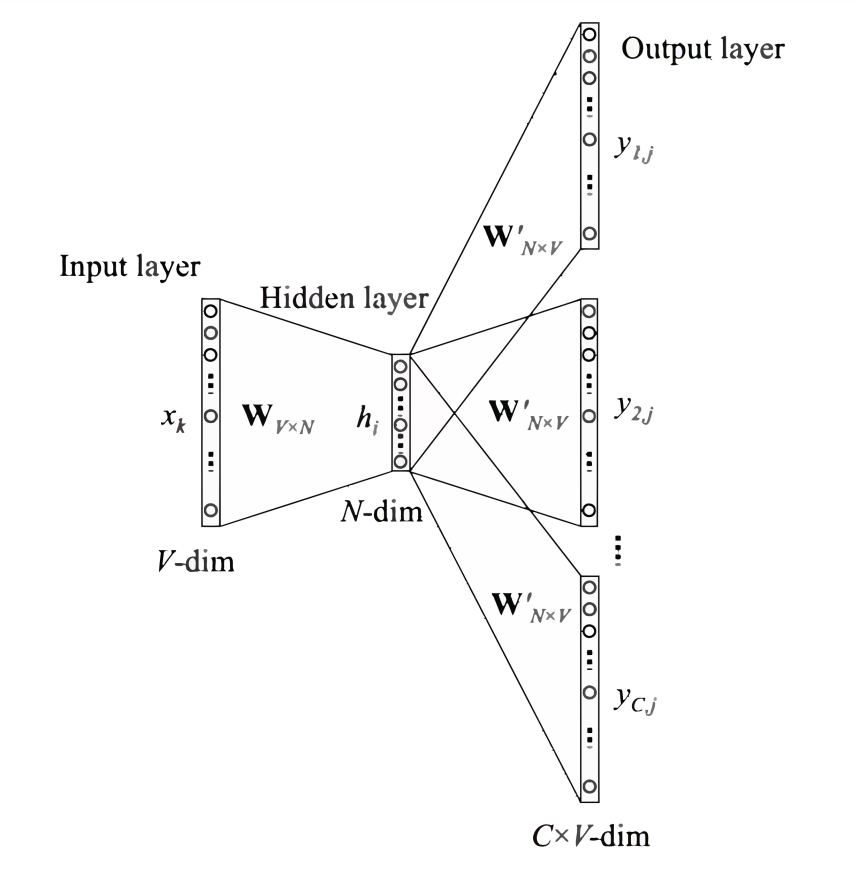
The application scenario of the skip-gram model is to predict context words based on the target word, so our input is any word, and the output is the probability of each word in the given vocabulary being the context word. The structure of the skip-gram model is shown in Figure 2.
From the structure diagrams of the CBOW and skip-gram models, we can see that besides differences in input and output, there are no significant distinctions. By swapping the input layer of CBOW with the output layer, it essentially transforms into the skip-gram model, and the two can be understood as a mutual inversion relationship.
From the perspective of supervised learning, Word2Vec is essentially a multi-class classification problem based on neural networks. When the output vocabulary is very large, techniques like Hierarchical Softmax and Negative Sampling are needed to accelerate training. However, from the perspective of natural language processing, Word2Vec is not focused on the neural network model itself, but rather on the vectorized representation of vocabulary obtained after training. This representation allows the final word vector dimensions to be much smaller than the vocabulary size, making Word2Vec essentially a dimensionality reduction operation. We reduce tens of thousands of vocabularies from high-dimensional space to low-dimensional space, which greatly benefits downstream tasks in NLP.
The Training Process of Word2Vec: Taking CBOW as an Example
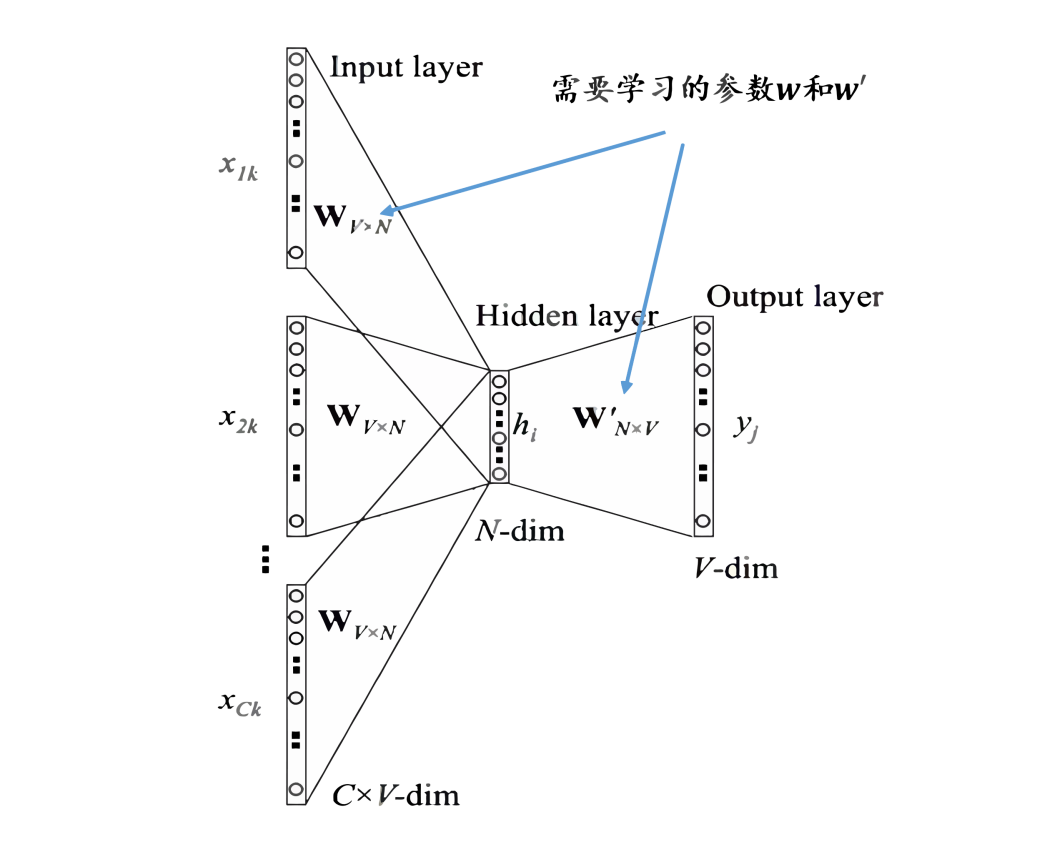
Due to the similarity between skip-gram and CBOW, this section will illustrate how Word2Vec trains to obtain word vectors using only the CBOW model as an example. Figure 3 highlights the parameters that the CBOW model needs to train. It is clear that we need to train the weights from the input layer to the hidden layer and from the hidden layer to the output layer.
Figure 3 Training Weights of CBOW
The basic steps for training the CBOW model include:
-
Represent the context words as one-hot vectors for model input, where the dimension of the vocabulary is the number of context words;
-
Then multiply the one-hot vectors of all context words by the shared input weight matrix;
-
Average the vectors obtained in the previous step to form the hidden layer vector;
-
Multiply the hidden layer vector by the shared output weight matrix;
-
Apply softmax activation to the computed vector to obtain a probability distribution, taking the index with the highest probability as the predicted target word.
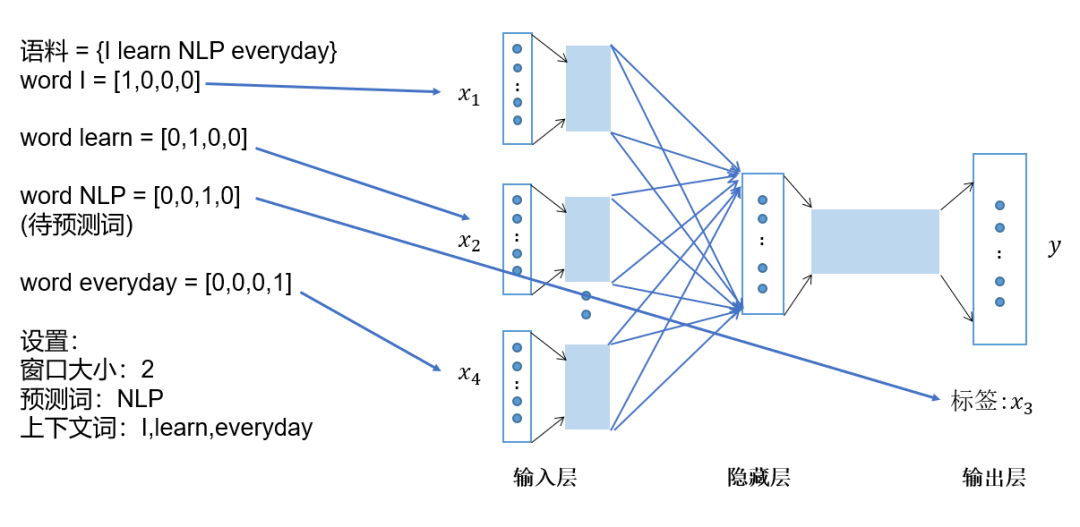
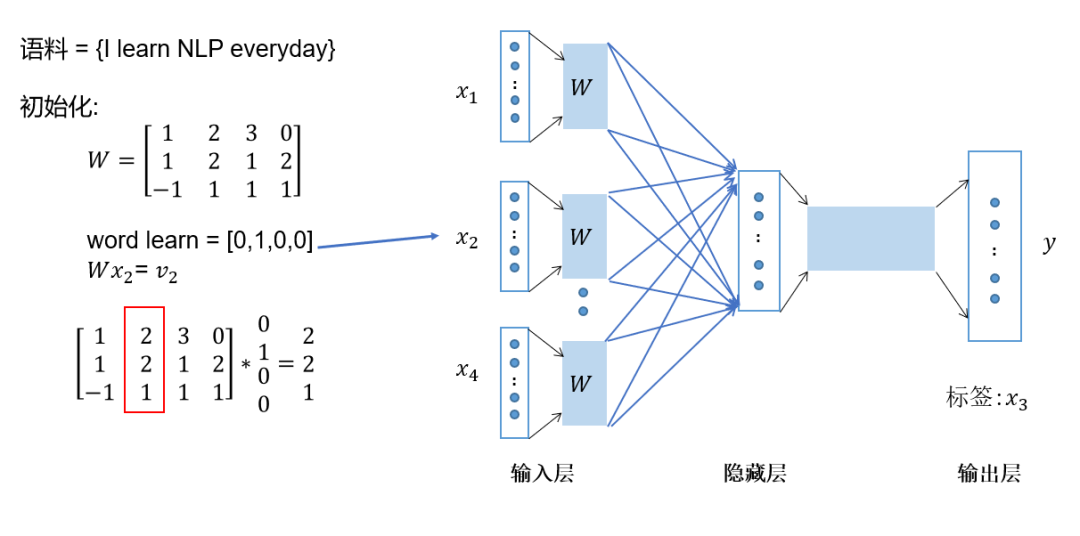
Let’s illustrate this with a specific example. Assume the corpus is “I learn NLP every day”, using “I learn every day” as context words and “NLP” as the target word. Both context and target words are represented as one-hot vectors as shown in Figure 4.
Figure 4 CBOW Training Process 1: One-hot Representation Input
Then, multiply the one-hot representation by the input layer weight matrix, which is also called the embedding matrix and can be randomly initialized. As shown in Figure 5.
Figure 5 CBOW Training Process 2: One-hot Input Multiplied by Embedding Matrix
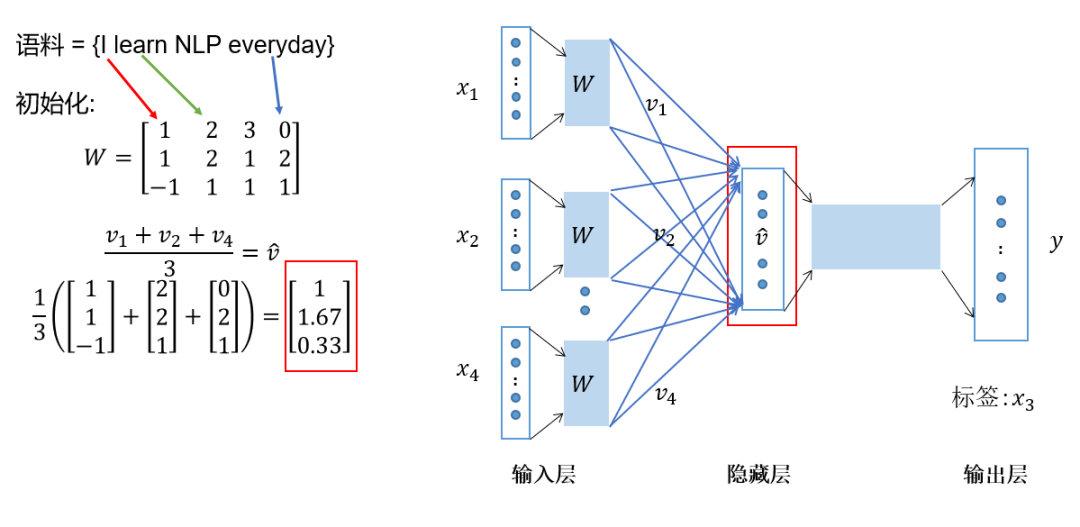
Next, average the resulting vectors to form the hidden layer vector, as shown in Figure 6.
Figure 6 CBOW Training Process 3: Averaging
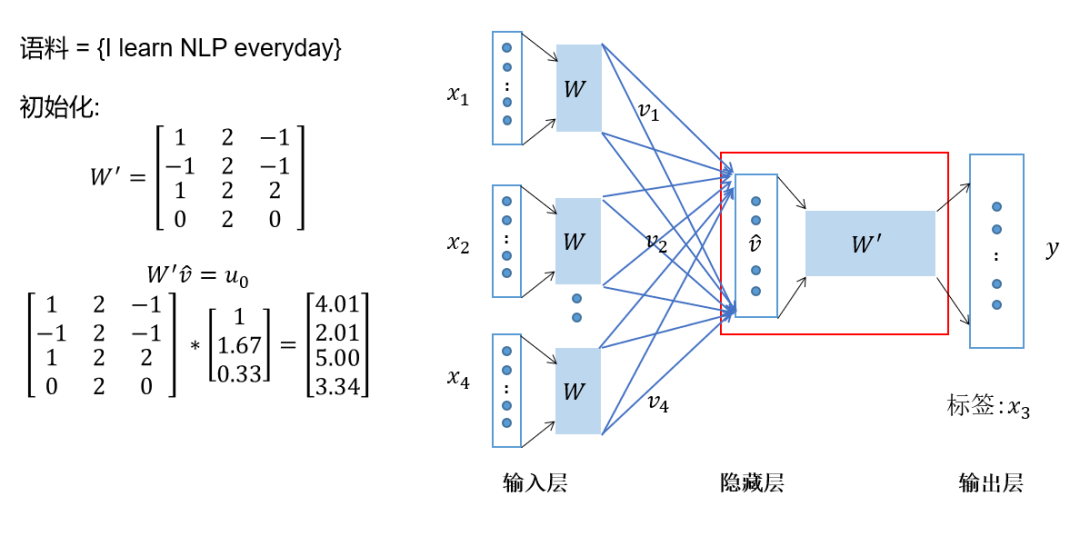
Then, multiply the hidden layer vector by the output layer weight matrix, which is also an embedding matrix that can be initialized. This results in the output vector, as shown in Figure 7.
Figure 7 CBOW Training Process 4: Hidden Layer Vector Multiplied by Embedding Matrix
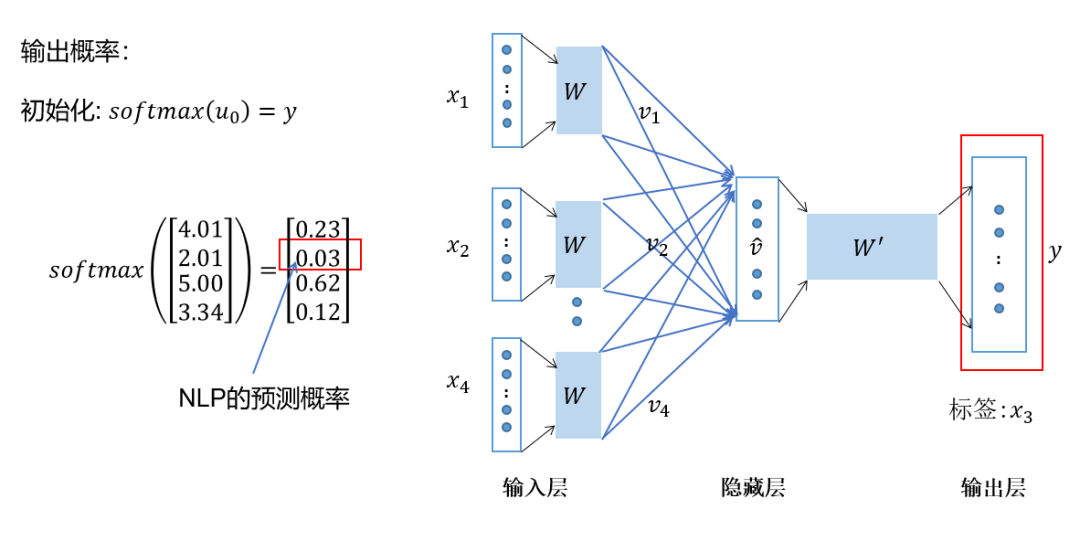
Finally, apply softmax activation to the output vector to obtain the actual output and compare it with the true label, then optimize the training based on the loss function.
Figure 8 CBOW Training Process 5: Softmax Activation Output
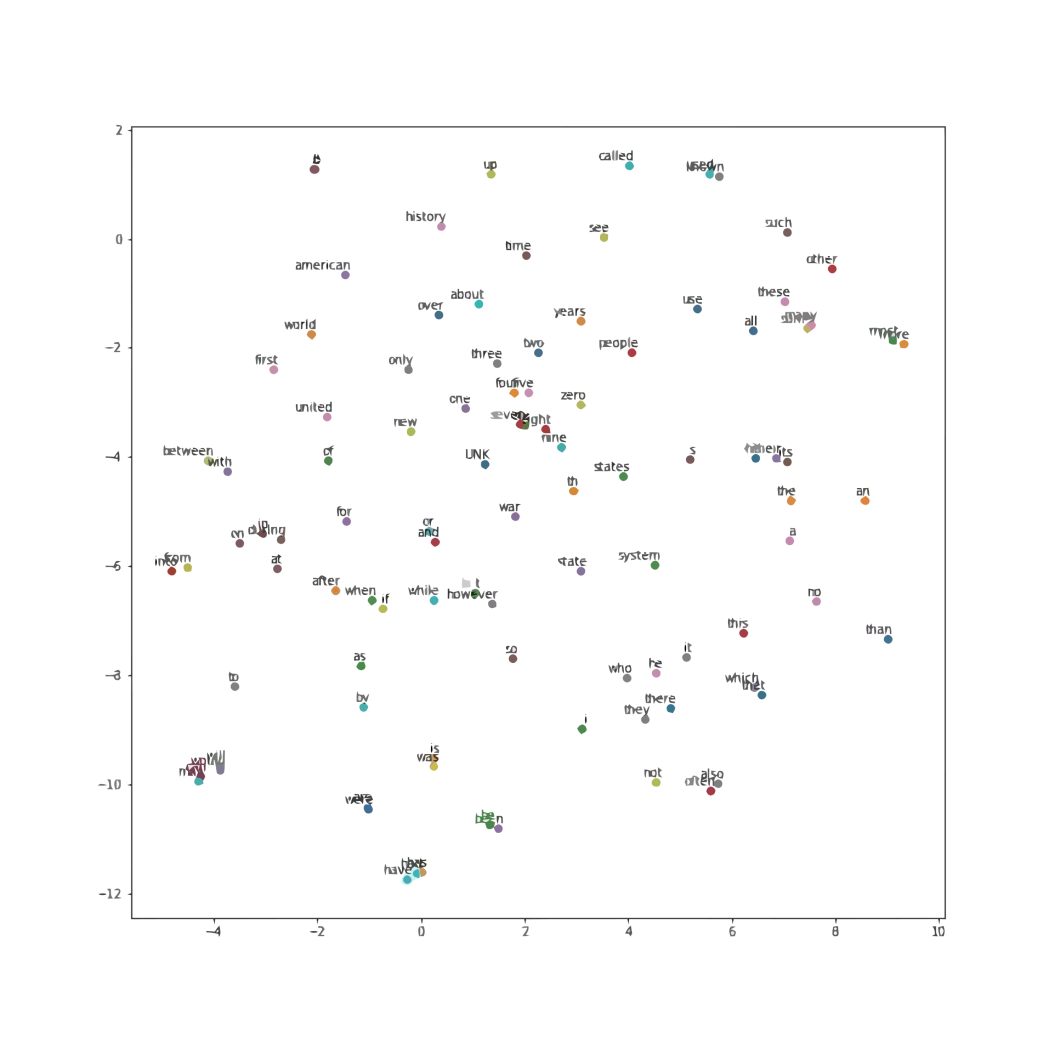
The above is the complete calculation process of the CBOW model, which is also one of the basic methods of Word2Vec to train vocabulary into word vectors. Whether it is the skip-gram model or the CBOW model, Word2Vec generally provides high-quality word vector representations. Figure 9 is a visualization of the 128-dimensional skip-gram word vectors trained with 50,000 words compressed into a 2-dimensional space.
Figure 9 Visualization Effect of Word2Vec
As can be seen, semantically similar words are clustered together, proving that Word2Vec is a reliable method for word vector representation.
Previous Highlights:
CNN Image Classification: From LeNet5 to EfficientNet
[Original Release] Derivation of Machine Learning Formulas and Code Implementation 30 Lectures.pdf
[Original Release] Deep Learning Semantic Segmentation Theory and Practical Guide.pdf

If you like it, just click to see!