BioRAG: A RAG-LLM Framework for Biological Question Reasoning
The question-answering systems in the life sciences face challenges such as rapid discovery, evolving insights, and complex interactions of knowledge entities, necessitating a comprehensive knowledge base and precise retrieval. To address this, we introduce BioRAG, a retrieval-augmented generation framework that combines large language models. First, we parse, index, and segment 22 million papers to build a foundational knowledge base and train a domain-specific embedding model. By integrating a hierarchy of domain knowledge, we optimize vector retrieval and parse complex relationships between queries and context. For time-sensitive queries, BioRAG breaks down the problem and uses search engines for iterative retrieval and reasoning. Experiments show that BioRAG excels in multiple life science question-answering tasks, surpassing fine-tuned LLMs, LLMs integrated with search engines, and other scientific RAG frameworks.
https://arxiv.org/abs/2408.01107
This article introduces a large biological knowledge reasoning system. Although this system focuses on the field of biology, the approach can be extended to the construction of large knowledge reasoning systems in other fields.
1. Current Status and Issues of Large Biological Knowledge Reasoning Systems
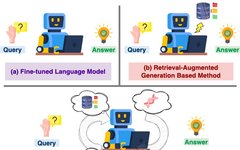
Large knowledge reasoning systems in the field of biology can be divided into two main streams (as shown in the figure above (a-b)).
-
• Fine-tuned language models: For example, bioBERT, sciBERT, and large language models customized for specific domains, such as PMC-Llama and Llava-med. These models are trained on domain-specific corpora, embedding deep domain knowledge within the models. However, the embedded knowledge may be incomplete, and the computational cost of updates is high.
-
• Retrieval-augmented generation methods: Following the pattern of information indexing and retrieval, information enhancement, and answer generation. For instance, PGRA uses a retriever to search and reorder context before generating answers. Subsequent research aims to improve these systems by optimizing retrieval processes using previous answers, enhancing model capabilities through iterative feedback loops, or expanding the knowledge base with search engines to include the latest information. Although RAG-based methods address the issue of information updates, they often overlook the inherent complexities of biological knowledge.
Based on the above discussion, we summarize three challenges in building efficient biological question reasoning systems:
-
• The scarcity of high-quality domain-specific corpora. Despite the abundance of publications in biological research, there is still a severe lack of extensive and high-quality datasets for building robust information indexing models.
-
• The inherent complexity of biological knowledge systems. This complexity is further highlighted by the interdisciplinary nature of modern biological research. Therefore, automated question reasoning systems must be capable of understanding and processing multifaceted and often ambiguous biological queries.
-
• The continuous updating of knowledge. Biology is a dynamic field with new discoveries emerging constantly, and existing theories are often revised or replaced. This dynamic change requires question reasoning systems to adeptly select knowledge sources from databases or current search engines to reflect accurate scientific understanding.
To address these challenges, the authors propose BioRAG: a novel retrieval-augmented generation framework integrated with large language models for biological question reasoning.
2. What is BioRAG
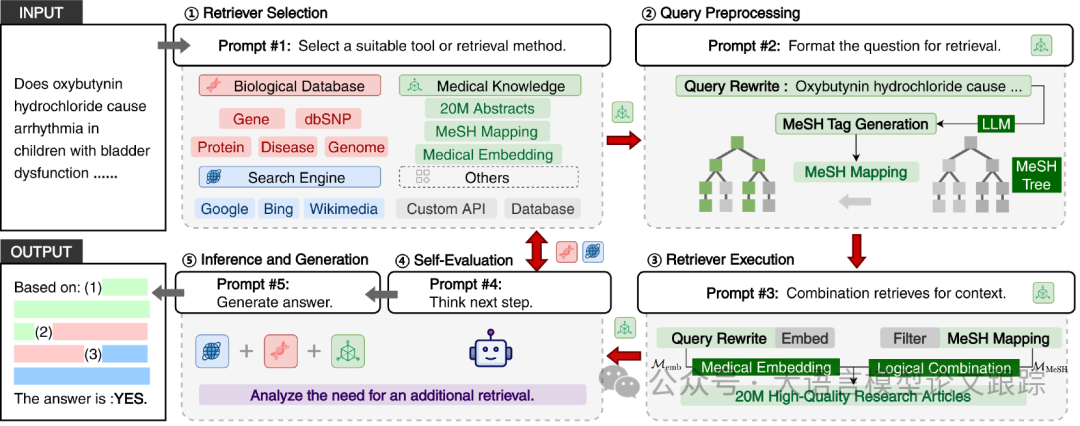
First, a large number of research articles in the biological field are parsed, indexed, and segmented to build a high-quality training corpus.
Next, by combining the pre-built research hierarchy with the embedding model, accurate context retrieval is achieved.
To address emerging biological knowledge, BioRAG can adaptively select knowledge sources from search engines, existing domain-specific tools, or indexed research articles.
Once the framework determines that sufficient information has been collected, it generates answers based on the reasoning materials.
2.1 Internal Biological Information Sources
In biological question-answering systems, high-quality domain-specific corpora are crucial for enriching information sources and enhancing embedding models.
To achieve this, research papers are extracted from the global biomedical article database maintained by the National Center for Biotechnology Information (NCBI). This database aggregates over 37 million scientific citations and abstracts from the 1950s to the present, covering a wide range of biomedical fields, including clinical medicine and molecular biology.
-
• Local data preparation: Over 37 million original papers were downloaded, and then 14 million low-quality entries were filtered out. The Unstructured tool (https://github.com/Unstructured-IO) was used to preprocess these texts, designed for efficiently ingesting and processing unstructured text data. The filtering process includes using regular expression techniques to remove garbled text and excluding non-semantic content such as hyperlinks, charts, tables, and other embedded tags. This meticulous process generated a corpus containing 22,371,343 high-quality, processed PubMed abstracts.
-
• Information indexing: To further optimize the retrieval performance for summaries of specific biological questions, a dedicated biological embedding model was developed within the BioRAG framework. This model is based on PubMedBERT. It was enhanced using CLIP (Contrastive Language-Image Pre-training) technology, enabling model fine-tuning.
Based on this, a localized high-quality biological carrier database was constructed to support efficient and effective query processing and retrieval operations. This database serves as a key resource for quickly and accurately obtaining relevant biomedical information, significantly enhancing the BioRAG framework’s ability to handle complex biological questions.
2.2 External Information Sources
Due to the rapid development of biological research and the continuous integration of new discoveries, external biological knowledge is crucial for biological reasoning. To address this issue, two external information sources have been introduced.
2.2.1 Biological Data Centers
BioRAG integrates the following databases, each of which has unique uses in a broader biological analysis context:
-
• (1) Gene Database https://www.ncbi.nlm.nih.gov/gene/: This resource provides comprehensive information about the function, structure, and expression of specific genes. It is highly valuable for addressing queries related to gene mechanisms, gene actions, and gene expressions, promoting a deeper understanding of gene-related phenomena.
-
• (2) dbSNP Database https://www.ncbi.nlm.nih.gov/snp/: This database contains a wealth of single nucleotide polymorphisms (SNPs), providing critical insights for studying genetic variations and their potential associations with various diseases. It is particularly useful for exploring the genetic basis of disease and trait inheritance.
-
• (3) Genome Database https://www.ncbi.nlm.nih.gov/genome/: This database provides complete genomic sequences and is crucial for studying the structure, function, and evolution of genomes across different organisms. It supports comprehensive genomic analyses and comparative studies, enhancing our understanding of genomic architecture and its functional impacts.
-
• (4) Protein Database https://www.ncbi.nlm.nih.gov/protein/: This resource provides detailed information about protein sequences, structures, and functions. It is significant for exploring biological processes related to proteins, understanding molecular functions, and studying complex interactions within proteomes.
2.2.2 Search Engines
To ensure access to the latest discussions and developments, BioRAG integrates various search engines, including Google, Bing, arXiv, Wikimedia, and Crossref. Each platform contributes uniquely to information aggregation:
-
• (1) Google and Bing: These search engines broadly search for various content on the web, including news articles, blogs, and forums, providing insights into public discussions and concerns related to scientific topics. The breadth of this information is crucial for understanding the societal impacts and general discourse surrounding scientific issues.
-
• (2) arXiv: As a repository for preprint papers, arXiv provides access to the latest research reports and academic articles across multiple scientific disciplines before peer review. This source is invaluable for keeping up with the latest scientific theories and experiments.
-
• (3) Wikimedia: Known for its user-friendly content, Wikimedia provides easy-to-understand explanations of complex scientific concepts and principles. This resource helps simplify advanced topics for broader public understanding and educational purposes.
-
• (4) Crossref: This service acts as a comprehensive aggregator of academic citation data, providing links to peer-reviewed academic publications and their citation networks. Crossref is essential for obtaining high-quality research outcomes and understanding their impact on academia.
2.3 Self-Evaluation Information Retriever
BioRAG incorporates a self-evaluation mechanism to continuously assess the sufficiency and relevance of the information it collects.
-
• Internal Information Retrieval: To effectively address the inherent complexities of biological knowledge systems, BioRAG employs an integrated approach that combines clearly defined hierarchies with indexed information to conduct comprehensive internal information retrieval. First, a M_textMeSH model is trained to predict the MeSH of the input question. Next, we fine-tune the Llama3-8B model using a template as shown in the figure below to classify the given question. A MeSH filtering SQL is constructed to generate conditional retrieval. If a candidate result has a consistent MeSH with the given question, it is considered relevant. Then, a vector retrieval process is employed to rank relevant results based on the cosine similarity of sentence embeddings between the input question and the filtered results.
-
• Self-Evaluation Strategy: To ensure the accuracy and timeliness of retrieved information, BioRAG introduces a self-evaluation strategy to assess the sufficiency of data collected from the internal knowledge base. Driven by a backend large language model, it aims to determine whether the internally retrieved information is adequate to address the posed question. If internal content is insufficient, the model will revert to relevant external knowledge sources. Additionally, when the initial evaluation indicates that a scientific question requires broader searches or specific entity data retrieval, the model tends to utilize external tools. This approach supports the framework’s goal of providing precise, up-to-date, and comprehensive answers, aiding better decision-making and advancing research and applications in life sciences.
2.4 Prompts
To maximize the utility of the retrieved corpus and knowledge, a series of prompts have been specifically designed in BioRAG. The prompts are defined as follows:
-
• Prompt #1: To provide the most helpful and accurate response to the following Question: {Question}. You have been given descriptions of several RETRIEVAL METHODS: {Retrieval}. Please select the RETRIEVAL METHODS you consider the most appropriate for addressing this question.
-
• Prompt #2: Based on the RETRIEVAL METHODS you selected, and considering the Question and the Input Requirements of the retrieval method, please REWRITE the search query accordingly.
-
• Prompt #3: Now, using the rewritten QUERY and the retrieval FILTER methods, perform a logical combination to execute the search effectively.
-
• Prompt #4: Based on the RETRIEVAL RESULTS from the above steps, please evaluate whether the RESULTS support answering the original Question. If they do not support it, output “NO”. If they do support it, output “YES”.
-
• Prompt #5: Based on the RETRIEVAL RESULTS, perform comprehensive reasoning and provide an answer to the Question.
In addition, a series of operation manuals have been compiled for professional biological tools and databases to maximize their capabilities. Specific operational instructions are as follows:
-
• Manual # Gene: The gene database search engine is a valuable resource for obtaining comprehensive information about genes, covering gene structure, function, and related genetic events. It is particularly suitable for answering detailed questions about gene research and discoveries. To use this search engine effectively, please enter the specific gene name.
-
• Manual # dbSNP: The dbSNP database search engine is a key tool for obtaining detailed information about single nucleotide polymorphisms (SNPs) and other genetic variations. It is especially suitable for answering questions about genetic diversity, allele frequencies, and related genetic studies. To use this search engine effectively, please enter the specific SNP identifier or genetic variation name.
-
• Manual # Genome: The genome database search engine is an essential tool for accessing comprehensive information about entire genomes, including sequences, annotations, and functional elements. It is particularly suitable for answering complex questions about genome structure, variations, and comparative genomics. To use this search engine effectively, please enter the specific genome name or identifier.
-
• Manual # Protein: The protein database search engine is a key resource for obtaining detailed information about proteins, including sequences, structures, functions, and interactions. It is particularly suitable for answering questions about protein biology, biochemical properties, and molecular functions. To use this search engine effectively, please enter the specific protein name or identifier.
-
• Manual # Web Search: The web search engine is a powerful tool designed to quickly and effectively help you find information about current events. It is particularly suitable for obtaining the latest news, updates, and developments on various topics. To use this search engine effectively, simply enter a relevant search query.
-
• Manual # PubMed: The PubMed local vector database search engine is an advanced tool that employs vector-based search technology to retrieve biomedical literature and research articles. It is particularly useful for answering detailed questions about medical research, clinical studies, and scientific discoveries. To use this search engine effectively, the input should be a specific query or topic of interest.
3 Comparative Analysis of Results
3.1 Results of Biology-Related Tasks
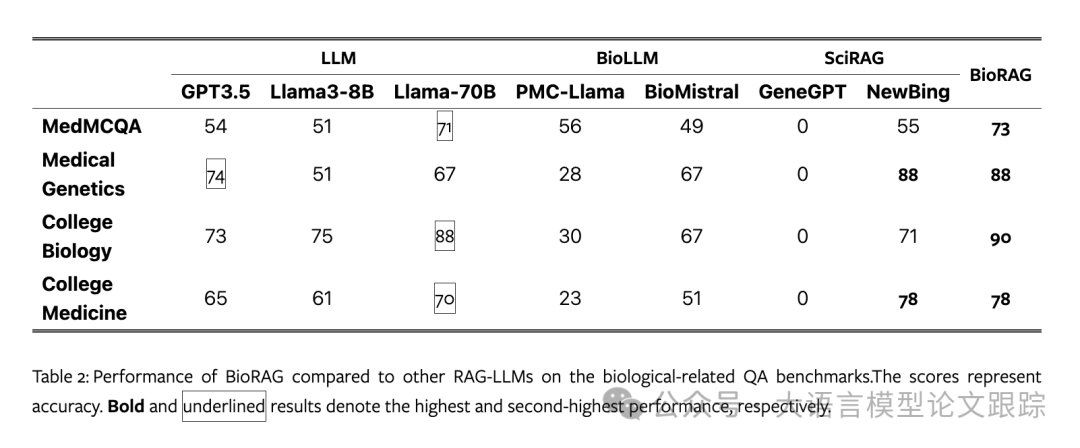
To verify the effectiveness of the proposed model, biological question-answering tasks were first conducted. The results are shown in the table above:
-
• (1) Based on the results from BioLLMs and GPT-3.5, fine-tuning on domain-specific data significantly benefits domain-specific tasks. Given that the scale of BioLLMs is much smaller than that of GPT-3.5, their performance is comparable to that of GPT-3.5.
-
• (2) The performance of BioRAG surpasses that of BioLLMs and GPT-3.5, indicating the importance of both local and external datasets.
-
• (3) Although BioRAG is much smaller than SciRAG (NewBing), its performance is superior. This advantage stems from two aspects: customized prompts and the utilization of both local and external information sources. NewBing cannot access specialized databases, lacking the technical biological descriptions necessary for reasoning.
-
• (4) GeneGPT scored zero in this task because it was tailored specifically for the GeneTuring dataset, leading to insufficient generalization capability.
3.2 Results of Professional Biological Reasoning
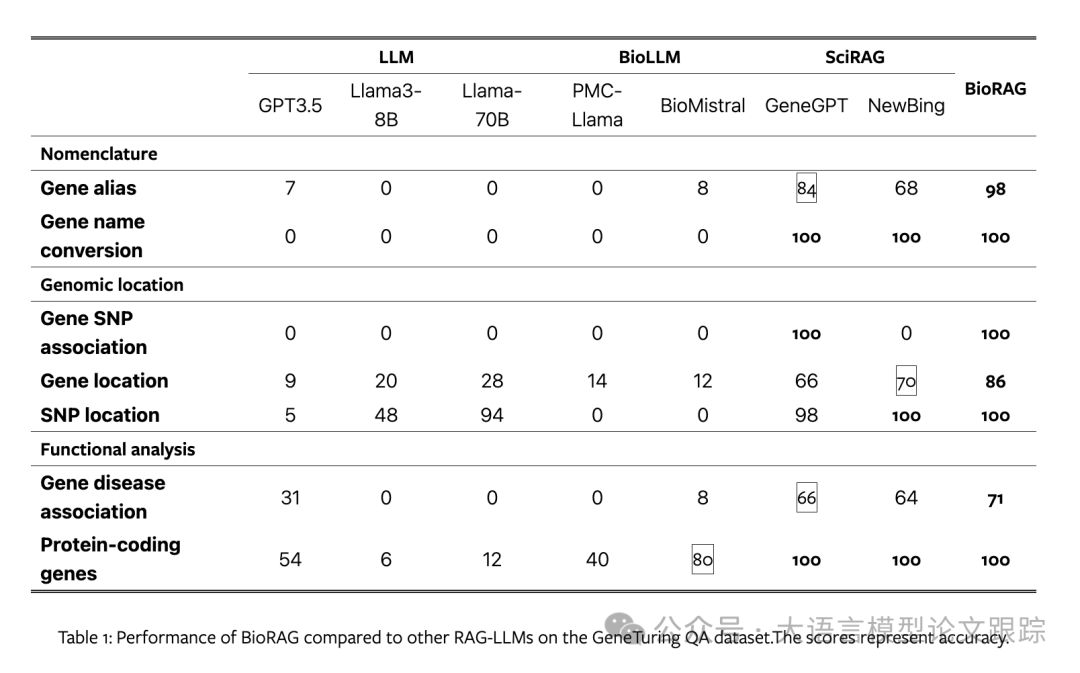
The GeneTuring dataset encompasses more specialized biological questions, and the corresponding reasoning processes heavily rely on technical biological literature and descriptions. The results are shown in the table above.
Due to the lack of training data in this dataset, BioLLMs performed poorly without fine-tuning, reflecting insufficient generalization capability.
In this dataset, the authors focus on analyzing GeneGPT, NewBing, and BioRAG:
-
• (1) In the nomenclature task, BioRAG and GeneGPT ranked first and second, respectively, as both could access the Gene database. BioRAG integrated results from search engines, whereas GeneGPT did not, leading to the gap between the two.
-
• (2) The reasoning for genomic position tasks relies on specialized Gene and dbSNP databases. Both BioRAG and GeneGPT achieved 100% accuracy in the gene SNP association subtask, as they both could access the dbSNP database. However, NewBing scored zero in this task due to its inability to access the dbSNP database. The challenge in the gene position subtask lies in the diversity of gene names. GeneGPT’s interface does not support advanced searches, resulting in incomplete retrieved names. In contrast, general search engines like NewBing can provide more comprehensive search results when query entities have variations or ambiguities. Therefore, in this task, NewBing performed better than GeneGPT. BioRAG supports both interfaces and achieved the best results in this task.
-
• (3) The functional analysis task relies on the gene database and related PubMed papers. The PubMed corpus provides detailed gene-disease relationships. Although NewBing can retrieve metadata, BioRAG integrates the local PubMed database with other specialized databases to achieve optimal results.
3.3 Ablation Analysis
To evaluate the contributions of each component of BioRAG, extensive ablation studies were conducted using the GeneTuring dataset, systematically removing each component to assess its impact on performance across various tasks.
-
• (1) Impact of the Database: Results indicate that the gene database plays a critical role in performance. For instance, when this component is removed, the accuracy of tasks like gene position significantly decreases. General search engines and the local PubMed database also have positive effects, but their impact is not as significant compared to the gene database.
– (2) Component Contributions: Among the components, the self-evaluation mechanism is crucial for maintaining high accuracy across most tasks. The MeSH filter and query rewriting can also enhance performance, but their absence does not reduce results as severely as the removal of self-evaluation.
– (3) Impact of the Base Language Model: Comparing the two base models, Llama-3-70B generally outperforms Llama-3-8B across all tasks, indicating that larger model sizes help better handle complex biological queries. These findings highlight the importance of integrating various data sources and advanced components within the BioRAG framework to achieve optimal performance in biological question reasoning tasks. By understanding each component’s contributions, BioRAG can be better optimized for different tasks and datasets.
3.4 Case Studies
To visually compare the reasoning differences between BioRAG and the baselines, three typical case studies were selected.
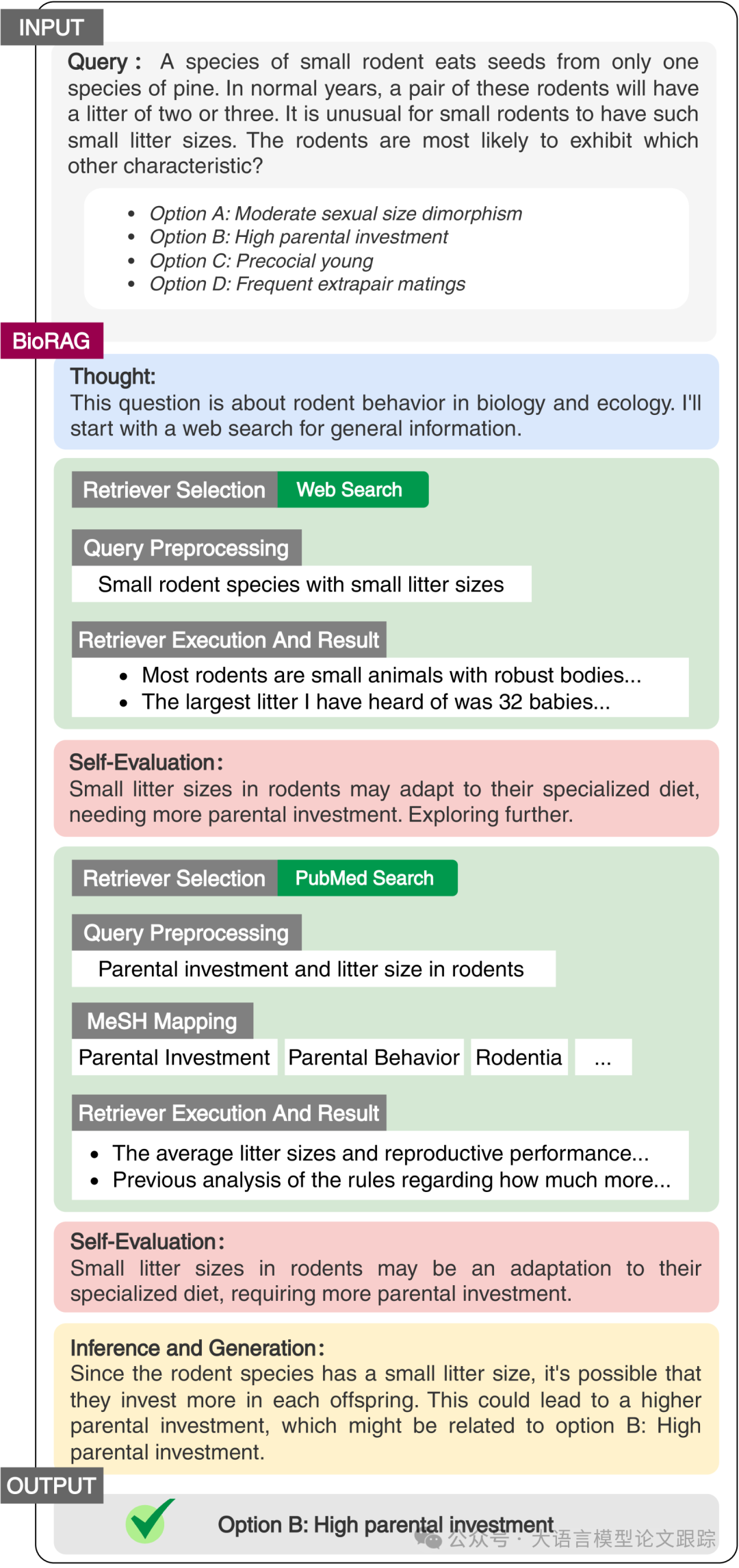
First, a case study is provided to demonstrate the workflow of BioRAG (as shown in the figure above). Selected from the undergraduate biology dataset, BioRAG conducted two self-evaluations: initially, it started from a general web search for information, but the results were insufficient to support answering the question. Therefore, BioRAG performed a second self-evaluation and invoked the more specialized PubMed database. The results this time were accurate and sufficient to support answering the question, allowing BioRAG to provide a final answer based on the results.
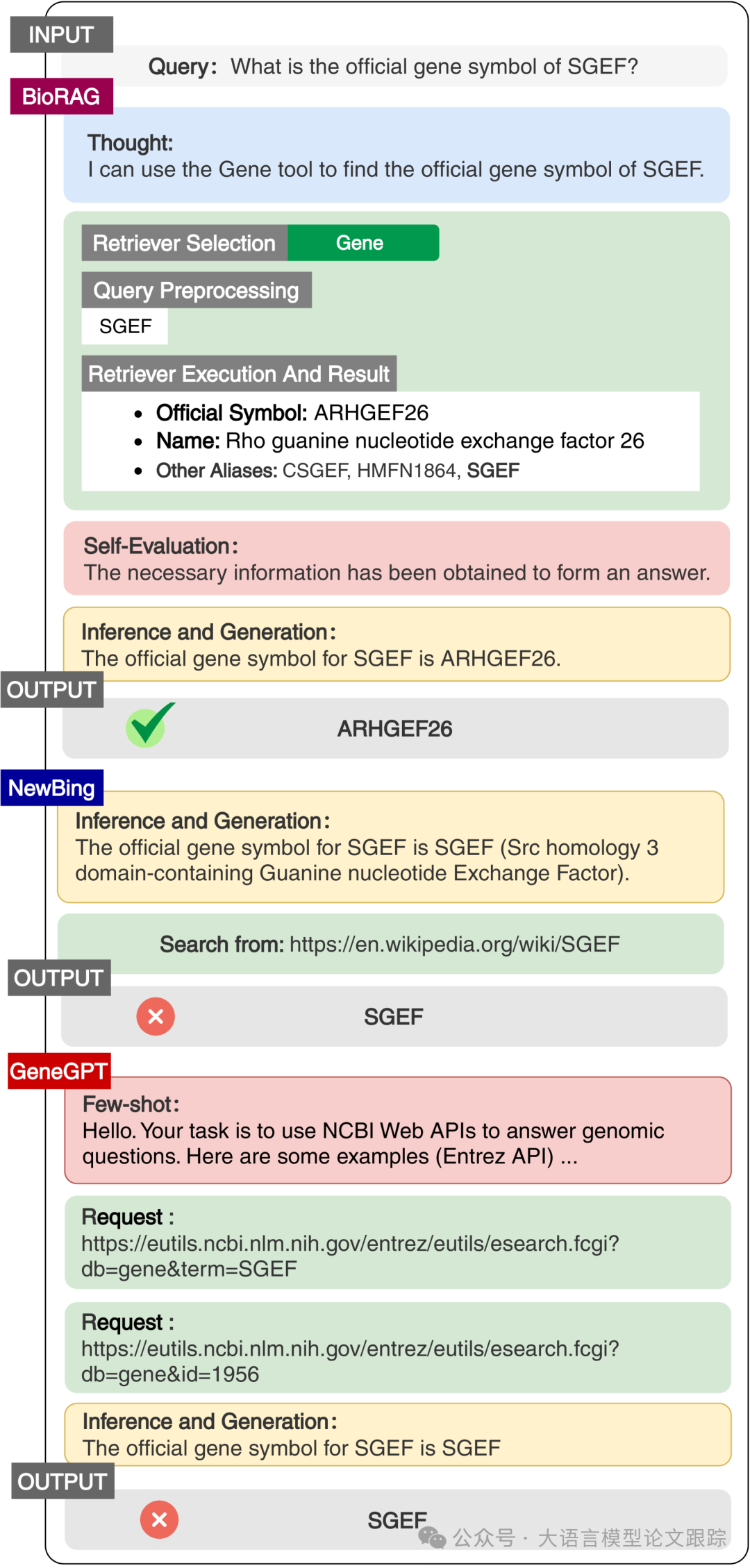
The second case study was conducted on the gene alias task in the GeneTuring dataset (as shown in the figure above). The challenge in this task lies in the variations of gene names. NewBing retrieved responses from Wikimedia. However, Wikimedia is not specialized enough to provide aliases for the input genes, resulting in incorrect answers.
GeneGPT’s prompts were overly complex and irrelevant to the current task. Furthermore, its NCBI API only returned gene IDs rather than names, preventing the large language model (LLM) from recognizing them, ultimately leading to incorrect conclusions.
In contrast, BioRAG employed fuzzy query techniques, allowing for higher tolerance of errors while obtaining more relevant feedback. Each feedback result contained detailed information such as gene aliases, enabling BioRAG to answer accurately.

In the third case study on the gene-disease association task within the GeneTuring dataset, the logical reasoning required relies on gene databases and related PubMed literature. The abstracts from PubMed provide detailed connections between genes and diseases.
NewBing retrieved responses from Geekymedics, but while that site provides extensive medical information, it failed to deliver the precise details required for gene-disease associations. Therefore, NewBing’s answers were inaccurate due to reliance on non-specialized resources.
GeneGPT incorrectly selected the NCBI API, which returned complex and lengthy HTML pages filled with irrelevant information. In this ambiguous information context, GeneGPT provided incorrect answers.
In the reasoning process of BioRAG, it comprehensively utilized gene databases, the local PubMed database, and web searches to collect and cross-verify gene information related to B-cell immunodeficiency. This process included query preprocessing, executing searches, and self-evaluating at each step to ensure the comprehensiveness and accuracy of results. BioRAG’s reasoning process is thorough, integrating various data sources to confirm the relationship between specific genes and B-cell immunodeficiency.
Source | Large Language Model Paper Tracking
Click the link at the bottom left of the article to read the original text. For academic sharing purposes only, please delete immediately if there is any infringement.
Editor / Garvey
Reviewed by / Fan Ruiqiang
Rechecked by / Garvey
Click below
Follow us