
Selected from arXiv
Compiled by Machine Heart
Contributors: Wu Pan
Deep neural networks (DNNs) have achieved performances that rival or even surpass humans in many tasks, but their generalization ability is still far inferior to that of humans. A recent paper from Tübingen University and other institutions compared the robustness of target recognition between humans and DNNs, yielding some interesting insights. Machine Heart has compiled an introduction to this paper.
-
Paper link: https://arxiv.org/pdf/1808.08750.pdf
-
Project link: https://github.com/rgeirhos/generalisation-humans-DNNs
Abstract
We compared the robustness of humans and current convolutional deep neural networks (DNNs) in target recognition using 12 different types of image degradation methods. First, by comparing three well-known DNNs (ResNet-152, VGG-19, GoogLeNet), we found that regardless of the operations performed on the images, humans were more robust in almost all cases. We also observed that as the signal weakened, the differences in classification error patterns between humans and DNNs increased. Secondly, our research shows that DNNs trained directly on distorted images perform better on the same type of distortion they were trained on than humans, but exhibit very poor generalization when tested on other types of distortions. For instance, a model trained on salt-and-pepper noise does not robustly handle uniform white noise, and vice versa. Therefore, the change in noise distribution between training and testing is a significant challenge faced by deep learning vision systems, which can be systematically addressed through lifelong machine learning methods. Our new dataset contains 83,000 meticulously measured human psychophysical trials, providing useful references for lifelong robustness based on the image degradations set by the human visual system.

Figure 1: Classification performance of ResNet-50 trained from scratch on (potentially distorted) ImageNet images. (a) The model trained on standard color images performs nearly perfectly on color images (better than human observers). (b) Similarly, the model trained and tested on images with added uniform noise also outperforms humans. (c) Significant generalization problems: the model trained on images with added salt-and-pepper noise performs inconsistently when tested on images with uniform noise—even though these two types of noise appear quite similar to the human eye.
1 Introduction
1.1 Deep Neural Networks as Human Object Recognition Models
Humans perform visual recognition at a rapid pace in daily life, seemingly effortlessly, and largely independent of perspective and object orientation [Biederman (1987)]. The rapid recognition primarily completed by the fovea during a single gaze is referred to as “core object recognition” [DiCarlo et al. (2012)]. For example, when viewing a “standard” image, we can reliably identify the target at the center of our field of view in less than 200 milliseconds during a single gaze [DiCarlo et al. (2012); Potter (1976); Thorpe et al. (1996)]. Because of the speed of object recognition, researchers often assume that core object recognition is primarily achieved through feedforward processing, although feedback connections are ubiquitous in primate brains. Object recognition in primate brains is believed to occur via the ventral visual pathway, which consists of a hierarchical structure of areas V1-V2-V4-IT, where information from the retina is first transmitted to the V1 cortex [Goodale and Milner (1992)].
Just a few years ago, the animal visual system was the only known system capable of performing a wide range of visual object recognition. However, this has changed, as brain-inspired deep neural networks trained on millions of labeled images have reached human-level performance in object classification on natural scene images [Krizhevsky et al. (2012)]. DNNs are now applicable to various types of tasks and have set new state-of-the-art records, even achieving performances that were previously thought to require decades to solve algorithmically [He et al. (2015); Silver et al. (2016)]. Because DNNs and humans can achieve similar accuracy, some work has begun to explore the similarities and differences between DNNs and human vision. On one hand, due to the complexity of the brain and the diversity of neurons, the network units of DNNs have been greatly simplified [Douglas and Martin (1991)]. On the other hand, a model’s ability often does not depend on replicating the original system, but rather on the model’s ability to capture the essential aspects of the original system and abstract them from the implementation details [e.g., Box (1976); Kriegeskorte (2015)].
One of the most significant properties of the human visual system is its robust generalization ability. Even when the input distribution undergoes significant changes (such as different lighting conditions and weather types), the human visual system can cope easily. For instance, even when raindrops or snowflakes obscure an object, humans can still identify it with high accuracy. Although humans certainly encounter many such variations throughout their lives (which for DNNs corresponds to what we call “training time”), it seems that the way humans generalize is very universal and not limited to previously seen distributions. Otherwise, we would not be able to comprehend scenes with entirely new elements, nor would we be able to handle previously unseen noise. Even if a person has never had confetti sprinkled on their head, they can still effortlessly recognize targets in a parade. Naturally, such a universally robust mechanism is not only necessary for animal visual systems; enabling artificial visual systems to possess a “vision” that transcends the distributions used during their training time to handle a variety of visual tasks will also require similar mechanisms. Deep learning used in autonomous driving is one prominent example: even if the system has never seen confetti rain during training, it still needs to demonstrate robust classification performance during a parade. Therefore, from a machine learning perspective, the robustness against general noise can serve as a highly relevant case for lifelong machine learning, as the generalization ability required for lifelong machine learning does not rely on the standard assumption of using independent and identically distributed (i.i.d.) samples at test time [Chen and Liu (2016)].
1.2 Comparison of Generalization Abilities
DNNs generally exhibit good generalization performance: first, DNNs can learn sufficiently general features from the training distribution, achieving high accuracy on independent and identically distributed test distributions; although DNNs also have enough capacity to completely memorize the training data [Zhang et al. (2016)]. Many studies have focused on understanding this phenomenon [e.g., Kawaguchi et al. (2017); Neyshabur et al. (2017); Shwartz-Ziv and Tishby (2017)]. Secondly, features learned in one task often only transfer to related tasks, such as transferring from classification tasks to saliency prediction tasks [Kümmerer et al. (2016)], emotion recognition tasks [Ng et al. (2015)], medical imaging tasks [Greenspan et al. (2016)], and many other transfer learning tasks [Donahue et al. (2014)]. However, transfer learning still requires substantial training before being used for new tasks. Here, we adopt a third setting: generalization from the perspective of lifelong machine learning [Thrun (1996)]. That is, how does a visual learning system perform when processing a new type of image degradation after having learned to handle one specific type? As a measure of robustness in object recognition, we can test the ability of classifiers or visual systems to withstand changes in input distribution to a certain extent, that is, whether their recognition performance is good enough when evaluated on a test distribution that differs to some extent from the training distribution (i.e., testing in a realistic scenario rather than testing on independent and identically distributed samples). Using this approach, we can measure the ability of DNNs and human observers to cope with gradually distorted raw images caused by parameterized image processing.
First, we will evaluate the best-performing DNN trained on ImageNet, namely GoogLeNet [Szegedy et al. (2015)], VGG-19 [Simonyan and Zisserman (2015)], and ResNet-152 [He et al. (2016)], and compare their performances against humans across 12 different image distortions, examining how each fares in generalization to previously unseen distortions. Figure 2 shows the types of distortions, including additive noise or phase noise.
In the second set of experiments, we will train networks directly on distorted images to see how they perform in general when handling noisy inputs, and how much training on distorted images can assist in processing other forms of distortions in the form of data augmentation. Researchers have conducted many psychophysical studies on human behavior in object recognition tasks, which involve measuring accuracy on images with different colors (grayscale and color) or contrast, and with varying amounts of visible noise. Studies indicate that this method indeed aids in exploring the human visual system, revealing information about its internal computations and mechanisms [Nachmias and Sansbury (1974); Pelli and Farell (1999); Wichmann (1999); Henning et al. (2002); Carandini and Heeger (2012); Carandini et al. (1997); Delorme et al. (2000)]. Therefore, similar experiments may also help us understand how DNNs work, especially by comparing with high-quality measurements of human behavior.
It is particularly noteworthy that the human data in our experiments were obtained from controlled experimental environments (rather than using services like Amazon Mechanical Turk, as these services do not allow us to adequately control presentation time, monitor calibration, viewing angles, and participants’ attention during the experiment). Our meticulously measured behavioral dataset contains 82,880 trials from 12 experiments, and these data, along with related materials and code, are publicly available: https://github.com/rgeirhos/generalisation-humans-DNNs
2 Methods
This section will report the paradigms, processes, image processing methods, observers, and core elements of DNNs used; the information here is sufficient for readers to understand the relevant experiments and results. For deeper interpretations, please refer to the supplementary materials, which contain more detailed information to help researchers reproduce our experiments.
2.1 Paradigms, Processes, and 16-class-ImageNet
For this study, we developed an experimental paradigm aimed at fairly comparing human observers and DNNs using a forced-choice image classification task. Achieving a fair psychophysical comparison faces several challenges: first, many high-performing DNNs are trained on the ILSVRC 2012 database [Russakovsky et al. (2015)], which contains 1,000 fine-grained categories (e.g., over 100 types of dogs). If humans are asked to name these targets, they would naturally use the names of broader categories (e.g., they would say “dog” rather than “German Shepherd”). Therefore, we developed a mapping method using the hierarchy of WordNet [Miller (1995)] to map 16 broad category types (e.g., dog, vehicle, or chair) to their corresponding ImageNet categories. We refer to this dataset as 16-class-ImageNet, as it groups a subset of ImageNet into 16 broad categories: airplane, motorcycle, ship, car, chair, dog, keyboard, oven, bear, bird, bottle, cat, clock, elephant, knife, truck). Then, during each trial, an image will be displayed on the computer screen, and the observer must select the correct category by clicking on one of the 16 categories. For the pre-trained DNNs, the total softmax values mapped to specific broad categories are computed. The category with the highest total is used as the final decision of the network.
Another challenge is that standard DNNs only use feedforward computation during inference time, while feedback connections are ubiquitous in the human brain [Lamme et al. (1998); Sporns and Zwi (2004)]. To prevent this difference from becoming a primary confounding factor in our experimental comparisons, the presentation time for human observers was limited to 200ms. After displaying an image, a 200ms 1/f noise mask is also presented—this method is known in psychophysics to minimize feedback effects in the brain as much as possible.
2.2 Observers and Pre-trained Deep Neural Networks
The data from human observers were compared against the classification performances of three pre-trained DNNs: GoogLeNet, VGG-19, and ResNet-152. For each of the 12 experiments we conducted, there were 5 or 6 observers involved (except for the experiment with only color images, which had only three observers as many studies have performed similar experiments [Delorme et al. (2000); Kubilius et al. (2016); Wichmann et al. (2006)]. The observers had normal vision or corrected vision.
2.3 Image Processing Methods
We conducted a total of 12 experiments in a well-controlled psychophysical laboratory environment. In each experiment, various (potentially parameterized) image distortions were applied to a large number of images, ranging from “no distortion/full signal” to “distorted/(weaker) signal.” We then measured how classification accuracy changed with signal strength. Among the image processing methods we used, three were binary (color vs. grayscale, true color vs. inverse color, original vs. equalized power spectrum); one processing method had 4 different levels (rotation 0, 90, 180, 270 degrees); and another had 7 levels (0, 30…180 degrees of phase noise); other distortion methods each had 8 different levels. These methods included: uniform noise (controlled by the “width” parameter of the boundary of additive uniform noise at the pixel level), contrast reduction (contrast varying from 100% to 1%), and three different processing methods from the Eidolon toolbox [Koenderink et al. (2017)]. These three Eidolon experiments correspond to different versions of parameterized image processing, with the “reach” parameter controlling the strength of the distortion. Additionally, for experiments trained on distortions, we also evaluated performance on stimuli with salt-and-pepper noise (controlled by parameter p, which indicates the probability of setting a pixel to black or white; p∈[0,10,20,35,50,65,80,95]%).
For more information on different image processing methods, please refer to the supplementary materials, which also include illustrations of various processing methods and distortion levels. Figure 2 shows an illustration of each type of distortion. Overall, the image processing methods we chose can represent many different types of potential distortions.
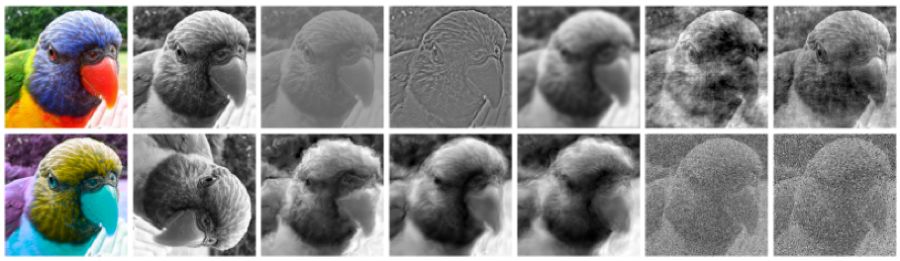
Figure 2: Results of a bird image after undergoing all types of distortion processing. From left to right, the image processing methods are: (top row): color original (undistorted), grayscale, low contrast, high pass, low pass (blur), phase noise, power equalization; (bottom row): inverse color, rotation, Eidolon I, Eidolon II, Eidolon III, additive uniform noise, salt-and-pepper noise. All distortion levels used are provided in the supplementary materials.
2.4 Training on Distorted Images
In addition to evaluating standard pre-trained DNNs on distorted images (results shown in Figure 3), we also trained networks directly on distorted images (Figure 4). These networks were trained on the 16-class-ImageNet, which is a subset of the standard ImageNet dataset, as detailed in Section 2.1. This reduced the size of the undisturbed training set to about one-fifth of the original size. To correct for the highly imbalanced sample sizes of each category, we weighted each sample in the loss function according to the number of samples corresponding to the respective category. All networks trained in these experiments used a ResNet-like architecture, differing from the standard ResNet-50 only in the number of output neurons—from 1,000 down to 16 to correspond to the 16 broad categories of the dataset. The weights were initialized using a truncated normal distribution with a mean of zero and a standard deviation of , where n is the number of output neurons in a layer.
During training from scratch, we performed data augmentation using different combinations of image processing methods. When training the network on multiple types of image processing (models B1-B9 and C1-C2 in Figure 4), the type of image processing (including undistorted images, i.e., standard color images) was uniformly selected, and we applied only one processing at a time (i.e., the network never sees a single image with multiple image processing methods applied simultaneously, but note that some image processing methods inherently include other methods: for example, uniform noise is always added after converting to grayscale and reducing contrast to 30%). For a given image processing method, the amount of perturbation was uniformly selected based on the levels used at test time (see Figure 3).
All other aspects of the training process followed the standard training procedure for ResNet on ImageNet: we used SGD with a momentum of 0.997, a batch size of 64, and an initial learning rate of 0.025. The learning rate was multiplied by 0.1 after 30, 60, 80, and 90 epochs (when training for 100 epochs) or after 60, 120, 160, and 180 epochs (when training for 200 epochs). We used TensorFlow 1.6.0 [Abadi et al. (2016)] for training. In the training experiments, all image processing methods had more than two levels, except for Eidolon stimuli (as the generation of these stimuli was computationally too slow for ImageNet training). For comparison, we additionally included contrasts of color vs. grayscale and salt-and-pepper noise (as there was no human data on salt-and-pepper noise, but informal comparisons between uniform noise and salt-and-pepper noise indicated that human performance was similar, see Figure 1(c)).
3 Generalization Ability of Humans and Pre-trained DNNs to Image Distortions
To evaluate generalization ability under weaker signals, we tested 12 different image degradation methods. These images with different signal strengths were then presented to human observers and pre-trained DNNs (ResNet-152, GoogLeNet, and VGG-19) in the laboratory environment for classification. Figure 3 provides a visual comparison of results.
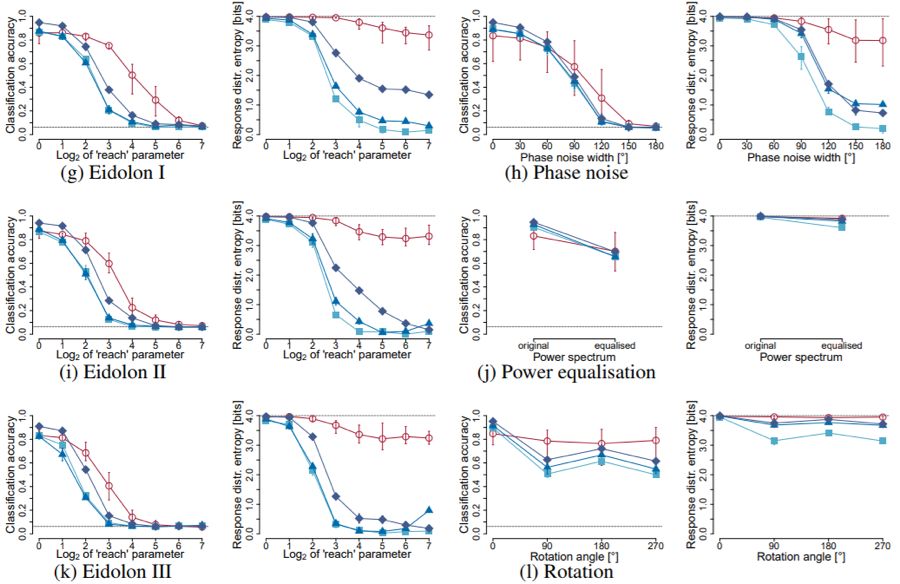
Figure 3: Classification accuracy and response distribution entropy of GoogLeNet, VGG-19, and ResNet-152 compared to human observers. “Entropy” refers to the Shannon entropy of the response/decision distribution (16 categories). Here, we measure the deviation from specific categories: using a test dataset balanced in the number of images per category can yield a maximum possible entropy of 4 bits. If the network or observer favors responding to certain categories, the entropy will decrease (in the extreme case of always responding to a single category, it will drop to 0 bits, regardless of the true category). The “error bars” representing human performance show the entire range of results from all participants. Section 2.3 will explain the image processing methods, and visual results can be found in the supplementary materials.
While human and DNN performance is close with relatively small color-related distortions (like grayscale conversion or inverse color), we found that human observers were more robust to all other distortions: with slight advantages on low contrast, power equalization, and phase noise images, and greater advantages on uniform noise, low-pass, high-pass, rotation, and the three Eidolon experiments. Furthermore, there were significant differences in the error patterns measured by response distribution entropy (indicating biases towards specific categories). As the signal weakened, human participants’ responses were more or less evenly distributed across the 16 categories, while all three DNNs exhibited biases towards specific categories. These biases could not be fully explained by prior category probabilities and varied by specific distortions. For example, for images with strong uniform noise, ResNet-152 almost exclusively predicted the bottle category (regardless of the true category), while for images with severe phase noise, it could only predict dog or bird categories. One might think of simple techniques to reduce the differences in response distribution entropy between DNNs and humans. One possible method is to increase the softmax temperature parameter and assume that the model’s decisions are sampled from this softmax distribution rather than taken from argmax. However, increasing the response distribution entropy of DNNs in this way would significantly reduce classification accuracy, thus requiring a trade-off (see supplementary materials Figure 8).
These results are consistent with previous reports of similar findings in DNNs regarding color information processing compared to humans [Flachot and Gegenfurtner (2018)], but the accuracy of DNN recognition significantly declines due to image degradations such as noise and blurriness [Vasiljevic et al. (2016); Dodge and Karam (2016, 2017a, 2017b); Zhou et al. (2017)]. Overall, under various image distortions, DNNs perform worse than humans in generalizing to weaker signals. Although the human visual system has encountered many distortions throughout evolution and life, we clearly have not encountered many of the exact image processing methods in our tests. Therefore, our human data suggests that a high level of generalization ability is fundamentally possible. We find that there may be many reasons for the differences in generalization ability between humans and DNNs: are there limitations in the current network architectures (as Dodge and Karam (2016) hypothesized), preventing DNNs from matching the complex computations in the human brain? Are there issues with the training data (as Zhou et al. (2017) suggested)? Or are today’s training methods/optimization methods insufficient to achieve robust and general object recognition? To understand the differences we found, we conducted another batch of experiments—training networks directly on distorted images.
4 Training DNNs Directly on Distorted Images
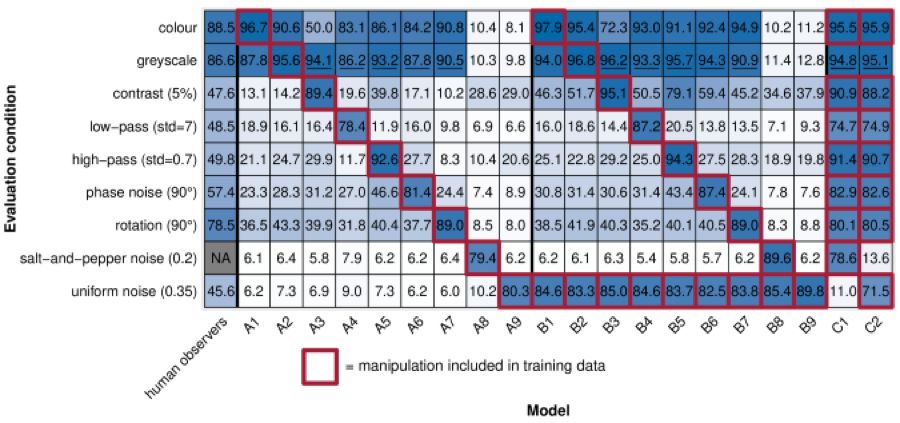
Figure 4: Classification accuracy (percentage) of networks trained on potentially distorted data. The rows represent different moderate difficulty testing conditions (specific conditions are provided in parentheses, units same as Figure 3). The columns correspond to networks trained in various ways (the leftmost column: human observers for comparison; no human data on salt-and-pepper noise). All networks were trained from scratch on (potentially processed) 16-class-ImageNet. The red boxes indicate the processing methods used in the training data of the corresponding networks; additionally, results marked with an underline indicate that “grayscale” was part of the training data, as some distortion methods included completely contrast-reduced grayscale images. Models A1-A9: ResNet-50 trained on a single distortion (100 epochs). Models B1-B9: ResNet-50 trained on uniform noise and another distortion (200 epochs). Models C1 and C2: ResNet-50 trained on all distortions except one (200 epochs). The randomly selected probability is one-sixteenth, i.e., 6.25%.
We trained a network from scratch on each distortion directly on the 16-class-ImageNet images (which may have undergone image processing). The results of the training are shown in Figure 4 (A1-A9). We found that these specific networks consistently outperformed human observers on the types of image processing they were trained on (i.e., the good results on the diagonal in the figure). This indicates that the current architectures used (such as ResNet-50) and training methods (standard optimizers and training processes) are sufficient to “solve” distortions under independent and identically distributed training/testing conditions. We not only address the differences in performance between humans and DNNs observed by Dodge and Karam (2017a) (who fine-tuned networks on distortions but did not achieve human-level performance), but we also surpass human levels in this regard. Although the structure of the human visual system is certainly more complex [Kietzmann et al. (2017)], it seems that such complexity is not necessary for addressing these types of image processing problems.
However, as previously pointed out, robust generalization ability is not about solving specific known problems in advance. Therefore, we tested the performance of networks trained on specific types of distortions on other distortions. The non-diagonal data in Figure 4 A1-A9 are the experimental results. Overall, we found that in some cases, training on a specific distortion slightly improved performance on other distortions, but in other cases, the opposite result was observed (the comparison object being a pure ResNet-50 trained on color images, i.e., model A1 in the figure). All networks performed close to random guessing on salt-and-pepper noise and uniform noise, even the networks trained directly on their respective other noise models. Since these two types of noise appear quite similar to the human eye (as shown in Figure 1(c)), this result may still be quite surprising. Therefore, a network trained on one type of distortion does not always achieve performance improvements on other distortions.
Since training only on a single type of distortion seems insufficient to provide DNNs with strong generalization abilities, we also trained the same architecture (ResNet-50) in two other settings. Models B1-B9 in Figure 4 show the results after training on a combination of one specific distortion and uniform noise (each training data from every image processing method at 50%). The reason for selecting uniform noise is that it appears to be the most challenging distortion for all networks, so including this specific distortion in the training data may be beneficial. Additionally, we also trained models C1 and C2 on all distortions except one (removing uniform noise or salt-and-pepper noise).
We found that compared to models A1-A9, the object recognition performance of models B1-B9 improved—whether in the distortions they were actually trained on (the good results on the diagonal in Figure 4) or in other distortions that did not appear in the training data. However, this improvement was largely likely due to model B1-B9 being trained for 200 epochs, rather than the 100 epochs used for A1-A9, as the performance of model B9 (trained and tested on uniform noise, 200 epochs) was also due to model A9 (trained and tested on uniform noise, 100 epochs). Therefore, when significant distortions are present, longer training times may be more beneficial, but integrating other distortions into the training process does not seem to yield universal benefits. Furthermore, we also found that even for a single model, achieving high accuracy across all 8 distortions it was trained on is possible (models C1 and C2), but for the remaining two distortions (uniform noise or salt-and-pepper noise), the object recognition accuracy was only 11%-14%; compared to dedicated networks trained on the same distortion (with accuracy exceeding 70%), this accuracy is much closer to random guessing.
Overall, these findings suggest that merely using distortions for data augmentation may be insufficient to overcome the generalization problems we observed. The question may need to be reframed—not “Why is the generalization ability of DNNs so good (under independent and identically distributed conditions)?” [Zhang et al. (2016)], but rather “Why is the generalization ability of DNNs so poor (under non-independent and identically distributed conditions)?” How the DNNs currently regarded as computational models of human object recognition will address this challenge remains to be seen in future research. This exciting field lies at the intersection of cognitive science/visual perception and deep learning, drawing inspiration and new ideas from both domains simultaneously: the subfield of domain adaptation in computer vision (see Patel et al. (2015) for a review) is studying robust machine reasoning methods that are unaffected by changes in input distribution, while the field of human vision research is accumulating evidence for the advantages of local gain control mechanisms. These standardization processes seem crucial for many aspects of robust vision in animals and humans [Carandini and Heeger (2012)], and they can predict human visual data [Berardino et al. (2017); Schütt and Wichmann (2017)] and prove useful for computer vision [Jarrett et al. (2009); Ren et al. (2016)]. Is there a connection between neural normalization processes and the generalization ability of DNNs? This will be an interesting direction for future research.
5 Conclusion
We conducted a behavioral comparison of the robustness of target recognition between humans and DNNs based on 12 different image distortions. We found that, compared to human observers, the performance of three well-known DNNs (ResNet-152, GoogLeNet, and VGG-19) trained on ImageNet rapidly declines as the signal-to-noise ratio decreases due to image distortions. Additionally, we also found that as the signal weakened, the differences in classification error patterns between humans and DNNs gradually increased. We conducted 82,880 psychophysical trials under well-controlled laboratory conditions, and the results indicate that there are still significant differences in the ways humans and current DNNs process target information. In our setup, these differences could not be overcome by training on distorted images (i.e., data augmentation): although DNNs can perfectly handle the specific distortions they were trained on, they remain helpless against distortion types they have not seen before. Because the types of potential distortions are essentially infinite (both theoretically and in practical applications), it is impossible to train on every distortion. When deviating from the conventional independent and identically distributed assumption (which is often unrealistic), DNNs encounter generalization problems. We believe that addressing this generalization issue is critical for both creating robust machine reasoning and better understanding human object recognition. We hope that our findings and the meticulously measured and freely available behavioral data will provide a useful new benchmark for improving the robustness of DNNs and inspire neuroscientists to find the mechanisms in the brain responsible for this remarkable robustness.
This article is compiled by Machine Heart, please contact this public account for authorization to reproduce.
✄————————————————
Join Machine Heart (Full-time reporter/intern): [email protected]
Submissions or inquiries for reports: content@jiqizhixin.com
Advertising & Business Cooperation: [email protected]