
Hua Xiansheng, IEEE Fellow, ACM Distinguished Scientist, TR35 Awardee, Alibaba researcher/senior director. He joined Alibaba’s search division in 2015, responsible for the big data multimedia content analysis and image search algorithm team. Prior to that, he served as a senior researcher, chief R&D officer, and senior researcher at Microsoft Research China, Bing Search Engine at Microsoft Headquarters, and Microsoft Research in the U.S. He graduated with a Ph.D. from Peking University in 2001 and has been engaged in research and development in image and video content analysis and search.
The technical term for CAPTCHA is Completely Automated Public Turing test to tell Computers and Humans Apart, which is a method used to distinguish between humans and computers. Typically, a computer generates a question that is easy for humans but very difficult for computers; those who can answer are judged to be human[1].
The CAPTCHA test is not a standard Turing test because the standard Turing test is designed for humans to assess computers. The usual goal of artificial intelligence researchers is to design systems that can pass the Turing test, making it impossible for humans to distinguish whether they are interacting with a person or a machine, thus demonstrating that artificial intelligence can approach human intelligence. The common form of Turing test is conversation; of course, it is not face-to-face conversation but rather “keyboard conversation”; otherwise, it would be obvious whether the other party is human or machine.
Passing this test is certainly not easy. Until June 2014, the University of Reading in the UK announced that a chatbot named Eugene Goostman from Russia had passed the Turing test for the first time at the 2014 Turing Test Competition held by the Royal Society in London, fooling humans into thinking “he” was a 13-year-old boy[2]. The judging criterion was: a series of keyboard conversations within 5 minutes led 30% of the people to believe it was a real person. Of course, the Turing test has other tasks and methods, such as a recent paper in Science discussing how to enable a computer to learn to write a handwritten character just by “glancing at it,” making it indistinguishable from human writing[3].
In contrast, CAPTCHA is a method where the computer poses questions to humans (of course, the design of these questions is also done by humans, then automatically generated by the computer). The purpose of CAPTCHA is to prevent computers from passing the verification, thereby stopping people from using computers to perform actions they shouldn’t. Typically, these actions can be done in large quantities or at high speeds using computer programs, disrupting the normal usage order for real users. For example, registering a large number of free email accounts to send spam emails, registering a large number of fake users on social media like Weibo as someone’s “zombie followers,” and using automated ticket-grabbing software, etc.
Early CAPTCHAs mostly used distorted text to evade OCR (Optical Character Recognition) technology, such as Yahoo’s early CAPTCHA version EZ-Gimpy. Later, there were versions that added curves to distorted characters and crowded characters together, sometimes making it difficult for real people to recognize them.

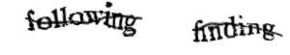
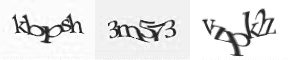
Figure 1: Different Character Verification Codes (Credit: Wikipedia)
A good CAPTCHA scheme has a simple characteristic: easy for humans to recognize, but difficult for machines. Strictly speaking, just like password schemes, the algorithm for generating CAPTCHAs should be public, allowing for the public verification of the algorithm’s security, but in practice, this is rarely done. In typical scenarios that require CAPTCHA, such as email applications, it is also required that the answer possibilities (solution space) of the CAPTCHA be sufficiently large, making the success rate of guessing extremely low.
For instance, if there is even a 1% or smaller chance of guessing correctly, it cannot effectively prevent machines from automatically registering a large number of email accounts to send spam. For example, a four-digit CAPTCHA has 10,000 possible outcomes, and without any intelligence, the probability of a computer guessing correctly is 0.01%. If some intelligence is added, raising the guessing probability to 1%, it still cannot effectively prevent machines from automatically registering email accounts. If it is 16 English letters, the size of the solution space is 52 raised to the power of 16, making the probability of guessing extremely low.
Of course, in some scenarios, CAPTCHAs do not need to have a large solution space, especially for systems with high real-time requirements and complex services (such as online transactions), because cracking programs are difficult to generate high QPS attacks in a short time. However, if the solution space is too small, it may be exhausted offline in advance, and online matching can find the answer. We will further discuss how to design better CAPTCHAs later; first, let’s see why image recognition is used for CAPTCHAs.
Image recognition CAPTCHAs have been attempted for over a decade. One advantage of image CAPTCHAs is that users do not need to type the recognized text; they only need to click on the corresponding image. The key is still to ensure the solution space is large enough and that machine algorithms are fundamentally unable to complete the task. For example, in 2003, Microsoft Research proposed a method that leveraged human sensitivity to facial regions, altering faces through head rotation, changing lighting, complex backgrounds, etc., causing computer face detection algorithms to fail while humans could easily identify the face’s location[4].

Figure 2: Face Verification Code (Credit: Yong Rui, et al.)
In 2009, there was an image CAPTCHA called VidoopCAPTCHA, which is similar to the image CAPTCHAs we see today; the difference is that each image contained a letter, requiring users to input the letter corresponding to the prompt. However, it was cracked by a student from Columbia University that year, and it is no longer in use; the company called Vidoop also no longer exists. Around 2010, a company called Confident Technologies developed a CAPTCHA that is more similar to the popular image CAPTCHAs today[5]. The difference is that it requires users to make three identifications, with only one answer being correct each time. Currently, 139 websites on the Internet use this technology.
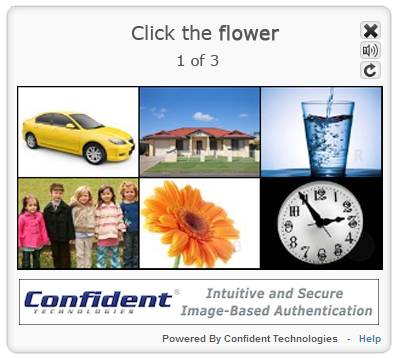
Figure 3: Confident Technologies’ Image Recognition CAPTCHA
Typically, the prompt text given by image CAPTCHA systems is not as easily recognizable as the word “flower” in Figure 3; instead, it is distorted text, which means it is also an embedded text recognition CAPTCHA. In other words, the prompt text in the image recognition CAPTCHA is a text recognition “verification code,” although it only requires human recognition without needing to type. The technology of text recognition CAPTCHA and possible attacks exceed the scope of this article, and due to space limitations, we will not discuss them.
So, can current automatic image recognition technology crack such CAPTCHAs? If so, how is it achieved? Before discussing this issue, let’s look at the current state of image recognition technology.
Image recognition has been studied in academia for decades; the idea of connecting a camera to a computer for it to recognize what it sees was proposed about 50 years ago (by Turing Award winner Marvin Minsky). This insight seems unremarkable today, but it was quite difficult to propose 50 years ago—imagine trying to predict technology 50 years into the future, or even 5 years into the future.
Image recognition methods can be divided into two main categories: model-based methods and search-based methods. Model-based methods are the most researched and used in the industry. Model-based methods attempt to learn a “model” that describes these labels (for example, the label of the first image in Figure 3 is “car”) through various machine learning methods using images with known labels. Thus, for a new unknown image, the model can determine what label it should have.
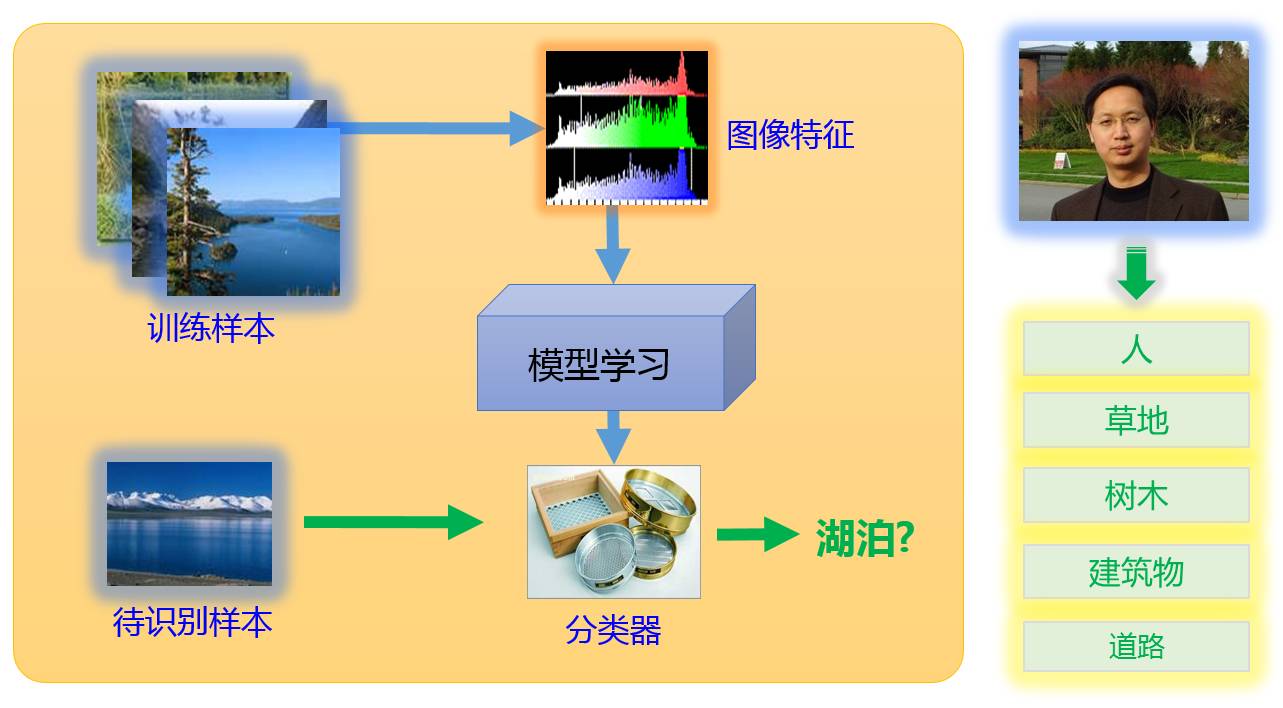
Figure 4: Schematic Diagram of Model-Based Image Recognition
Search-based methods emerged only in the era of big data, based on building a database of known labeled image data that can be efficiently retrieved, known as image indexing. Typically, a large number of images are required to build the index, but the labels of the images can have some noise. Thus, for a test image, we search this database for several images that are the same or similar, and then combine the labels of these images to predict the label of the test image.
Of course, the essence of these two categories of methods is not different; the search method utilizes the technology of large-scale image indexing without establishing a model, but directly uses this data for matching. Therefore, we can consider this large index as a special model. In the era of big data, recognition and search have become inseparable; accurate search relies on recognition, and extensive recognition also relies on search. In many reports, I often discuss recognition and search together.
Reliable image recognition methods started with the introduction of SIFT image features at the end of the last century. In the following decade, most researchers attacked this problem from the perspective of features and models. For example, in terms of features, SIFT and HOG, and in terms of models, SVM, Boosting, DPM, etc. Around 2012, deep convolutional neural networks began to be applied in the field of image recognition, addressing both model and feature issues simultaneously. This means that deep learning can train image recognition models directly from image pixels or obtain more effective feature descriptions of images through the same training, and then use traditional machine learning models to train recognition models. Essentially, deep learning methods have outperformed all traditional methods, significantly advancing the accuracy of image recognition.
ImageNet image recognition (classification) is the most influential public competition for image recognition algorithms, where the basic task is to train a 1000-class image recognizer. Before the use of deep learning methods, the best “top-5 accuracy” (the likelihood that one of the top 5 predicted labels for a test image is correct) was only about 74%. Deep learning improved this result by nearly 10 percentage points on the first attempt, reaching 83.6%. The best result in 2015 reached 96.3%[6].
However, for an image recognition system that hopes to be used in practice, there are three aspects to consider: data, system, and user feedback. The real world does not consist of just 1000 classes of images; if each class requires a large number of labeled images, the workload is still considerable. For example, there are approximately 900 not-so-rare flower species, around 500 purebred dog breeds, and about 50,000 cities; Taobao has more than 10,000 physical products. Therefore, researchers have begun to explore how to efficiently or even automatically create datasets. The system requirements are to ensure that model training is completed within a controllable time frame and that image recognition can be completed in a very short time (e.g., tens of milliseconds). User feedback involves continuously absorbing user behavior data during the use of a recognition system to gradually improve the system’s accuracy and coverage.
In summary, the performance of an image recognition system can be evaluated from the following four aspects:
(1) Accuracy: Measures whether the content in the image can be correctly recognized, which is the primary focus for most people, including the ImageNet competition;
(2) Coverage: Measures how many types of semantics can be recognized; this is less focused on in academia but plays a crucial role in whether a recognition system can be applied in real-world scenarios. In the industry, for example, recognition APIs provided by major search engine companies (Microsoft, Google, and Baidu) can recognize more content (approximately in the tens of thousands);
(3) Efficiency: Primarily measures how quickly results can be recognized and how quickly a recognizer can be trained or updated;
(4) User Experience: Considers how to compensate for deficiencies in recognition accuracy, coverage, or efficiency in products and user interfaces.
For example, a year ago, I developed a system called Prajna[7], which automatically trains data acquisition and cleaning methods to quickly train various image recognizers, including dog breeds, flowers, plants, landmarks, food, and more. Its method of automatic data acquisition is beneficial for addressing coverage issues without requiring manual labeling, significantly shortening the cycle for producing a new recognizer to just a few hours to a few days.
Once, I attended a gathering at a friend’s house, where there was a beautiful flower that everyone wanted to know the name of, but the host had forgotten. So, I activated my flower recognizer, successfully identifying the flower (see the image below). At that time, many image recognition programs could only identify it as a type of flower but could not determine its specific name. This illustrates that in practical application systems, “coverage” is incredibly important.

Figure 5: My Image Recognition System Prajna Identified This as “Amaryllis”
So, with these latest advancements in image recognition, can we crack the current image recognition CAPTCHAs on some websites? Before discussing this issue, let’s look at what else image recognition can do beyond potentially cracking CAPTCHAs and recognizing species that humans cannot.
With nearly twenty years of experience in image recognition and search, I believe one of the most practical user-demanded applications of image recognition should be product recognition and search (as mentioned, recognition and search are often inseparable today). A typical application scenario is finding desired products through photography, such as Amazon’s FireFly and Alibaba’s “Snap and Search”. I am the R&D director for the “Snap and Search” algorithm, and I will briefly introduce the application of image recognition in product search via photography. Due to space limitations, I can only provide a very brief overview, hoping to have the opportunity to discuss the history of image search technology and the cutting-edge technologies and interesting applications in “Snap and Search” in another article (you can catch a glimpse of it in [8]).
In “Snap and Search,” for the product photos taken by users, we first need to identify the general category, such as whether it’s an upper garment, pants, bag, snack, etc. Then we need to determine the location of the product of interest in the image, commonly referred to as “object detection.” Next, we generate a description of this object, which is usually a high-dimensional vector. The generation of this vector is achieved by training a multi-class product recognizer. Finally, we use this feature to search within a well-indexed large product database for similar or identical products to return to the user. These key steps, including product recognition, object detection, and feature extraction, are accomplished using deep learning methods.
Why is this application scenario considered a “must-have”? On one hand, there are many situations where users cannot describe what they need with words and can only search through examples; on the other hand, this continuously improving product currently has millions of active users daily, generating nearly ten million transactions each day.
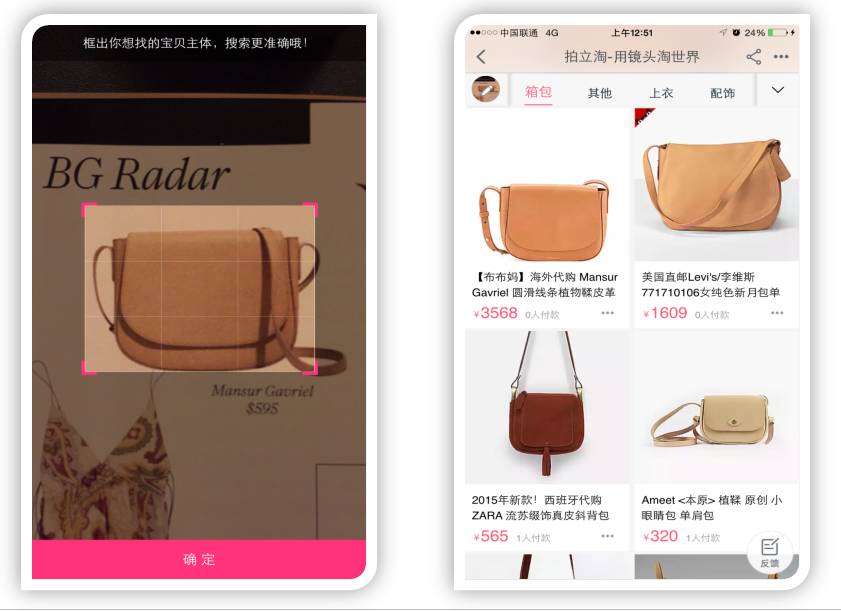
Figure 6: An Example of Product Search in “Snap and Search”. Left: Product Photo Taken by User and Automatically Highlighted Product Area; Right: Recognition Result (Bag) and Search Results.
What does it mean to crack? Does it mean that one must be able to recognize all images to be considered cracked? Not necessarily; if the recognition accuracy reaches a certain value, that would suffice. For example, for email registration, a very low accuracy rate could pose a threat, such as 10% or even lower. For online ticket purchasing systems, around 10% could also pose a significant threat (some websites report that for currently popular image recognition CAPTCHAs, the success rate of real people is only 8%).
How large is the solution space for currently popular image recognition CAPTCHAs? Typically, one sees CAPTCHAs recognizing 8 images, usually with 1 to 3 correct answers (not sure if there are 4 correct answers), so the total combinations of possible answers are limited. If answered randomly, there is a 1/92 (1.1%) chance of getting it right (if the correct answers are increased to 1 to 4, this probability drops to 0.06%). This means that if the cracking program has no intelligence, it would only succeed once in 92 attempts. Of course, this probability may not be very effective in preventing email registrations, but it is still effective in scenarios like online transactions where timing is critical.
If there is an automatic recognition program to assist? If the number of categories is not too high (e.g., only a few hundred), it is not impossible to train an automatic recognizer for these images after identifying the possible object categories (the methods won’t be detailed here). Of course, the premise is being able to automatically recognize the prompt text, which is generally easier than image recognition, although the prompt text can also be somewhat distorted (as previously mentioned, the technology for character CAPTCHAs is not discussed in this article). Assuming our “top-1 recognition rate” (the first recognized object name is correct) is 30%, then 1 in 3 to 4 attempts can successfully recognize, which poses a sufficient threat to the CAPTCHA system. Using recognition APIs from Google, Baidu, or Microsoft is also a method, but these APIs are not optimized for these categories and are unlikely to have recognition rates as high as those trained specifically for these categories.
Some have mentioned using image comparison methods to crack CAPTCHAs, which involves repeatedly using the CAPTCHA backend to crawl down all or most of the object images, manually labeling them, and then directly comparing them during online verification. This method is also a good idea but requires professionals in image retrieval to implement effectively, as it involves two things: suitable feature descriptions for the images (if directly using image pixels, noise can render comparison methods ineffective) and indexing technology to ensure fast retrieval (if there are not many backend images, this step can be omitted).
So, does this mean that image CAPTCHAs have no future? Certainly, the above methods are merely ideal scenarios for cracking ideas; a CAPTCHA system can introduce many variables and constraints to make cracking more difficult. However, increasing the difficulty of the questions contradicts the original purpose of CAPTCHAs; consider how can something that is difficult for ordinary people to recognize be used to distinguish between computers and humans?
Based on experience, I suggest some strategies for image recognition CAPTCHAs; the basic ideas remain: (1) questions should be easy for humans but difficult for machines; (2) the solution space should be large enough; (3) current image recognition methods should not handle it well. Possible methods include:
(1) Adding complex backgrounds to the images to be recognized and merging them into a seamless image;
(2) Using similar items that recognition algorithms easily confuse;
(3) Continuously changing the background patterns and puzzle methods;
(4) Adding some disturbances to the foreground objects;
(5) Increasing the number of detailed object categories;
(6) Introducing attribute recognition elements beyond object recognition;
I believe that if CAPTCHAs adopt these strategies, the difficulty of cracking will increase significantly, making it challenging even for experts in automatic image recognition, or for a period of time, they may not be able to solve them, thus losing the incentive to tackle the problem. As technology advances, updates can be made to keep the crackers from keeping pace with the question setters. For example, using just some of the methods mentioned, one can see that if a CAPTCHA looks like the image below, humans should still be able to recognize it (I tested it with my 8-year-old son, and he could identify it correctly in about 2 seconds), while machines would likely find it challenging (of course, not just this scenario, but a large number of similar scenarios). 🙂

Figure 7: CAPTCHA Problem: Click on the red top of the person sitting. What, not difficult enough? Then click on the smallest cup in the image.
There is actually a simple strategy, which is to fully utilize this CAPTCHA system to quickly increase and iterate the system’s data, making it difficult for crackers to keep up (I won’t elaborate on the methods here; those in the know will understand).
Let’s return to the positive uses of image recognition. Although there has been significant progress in image recognition, there are still many challenges in real-world image recognition. As mentioned earlier, in relatively small sets (such as the 1000-class recognition of ImageNet), recognition accuracy has improved rapidly over the years. However, the real world is complex, and the required recognition coverage and accuracy need to be high, and the speed must be fast. I believe that relying solely on model and feature methods will not completely resolve the issues; future solutions should integrate the five elements of model, feature, data, system, and user feedback to gradually achieve the ideal recognition results.
[1] Wikipedia. https://en.wikipedia.org/wiki/CAPTCHA
[2] Wikipedia. https://en.wikipedia.org/wiki/Eugene_Goostman
[3] BM Lake, et al. Human-level concept learning through probabilistic program induction. Science. Vol 350, no 6266, pp 1332-1338.Dec 11 2015.
[4] Yong Rui, Zicheng Liu. Excuse me, but are you human? ACM Multimedia 2003
[5] Confident CAPTCHA. http://confidenttechnologies.com/confident-captcha
[6] Large Scale Visual Recognition Challenge 2015. http://image-net.org/challenges/LSVRC/2015/results
[7] Xian-Sheng Hua, Jin Li. Prajna: Towards Recognizing Whatever You Want from Images without Image Labeling. AAAI 2015.
[8] http://i.wshang.com/Post/Default/Index/pid/41859.html
-
For more valuable content, please follow InfoQ [id: infoqchina] WeChat public account

-
10 Technical Articles You Don’t Want to Miss in 2015
-
Q News丨Oracle Confirms Java 9 Delayed! Microsoft Releases Azure Backup Server…
-
Case Study丨Detailed Explanation of Dangdang’s Distributed Job Framework Elastic-Job
-
What is OpenResty mentioned in the Smartisan Phone Conference?