
Local life scenarios involve numerous challenging computer vision tasks, such as menu recognition, sign recognition, dish recognition, product recognition, pedestrian detection, and indoor visual navigation.

The core technologies corresponding to these computer vision tasks can be categorized into three types: object recognition, text recognition, and 3D reconstruction.
From November 30 to December 1, 2018, the WOT Global Artificial Intelligence Technology Summit, hosted by 51CTO, was grandly held at the JW Marriott Hotel in Beijing.
This summit focused on artificial intelligence, where Li Pei, head of the artificial intelligence department of Alibaba Local Life Research Institute, shared various problems encountered in the process of image recognition and the solutions sought.
What Are Local Life Scenarios?

Our understanding of local life scenarios is: evolving from traditional O2O to OMO (Online-Merge-Offline).
For O2O applications like ride-hailing and food delivery, the boundaries between online and offline are becoming increasingly blurred.
Traditional online orders are no longer limited to offline flow; there is interaction and integration happening between them.

In 2018, we saw Didi investing heavily to build and manage its own fleet. They installed many monitoring devices in the cars to attempt to transform the offline interactions between vehicles and people.
Similarly, for Ele.me, we not only reformed the delivery of offline logistics but also experimented with robots for unmanned delivery, as well as introducing smart delivery boxes and other innovations.
It is evident that our core task in local life scenarios is to apply intelligent IoT (AI + IoT) to OMO scenarios.
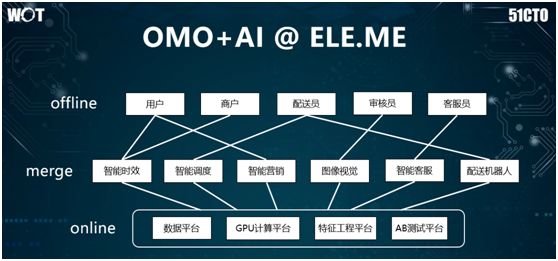
The image above illustrates the logical architecture of Alibaba Local Life’s AI applications. Similar to other AI application computing platforms, we utilize several common components at the bottom layer, including: data platform, GPU platform, feature engineering platform, and AB testing platform.
On top of this, we have modules such as intelligent delivery, order scheduling, and intelligent marketing. Meanwhile, algorithm personnel have conducted various data mining, machine learning, and optimization.

Currently, for Alibaba Local Life, our image vision team handles all recognition and detection tasks related to images and vision within the local life group. All image processing is based on deep learning.
I will introduce our practices from the following three aspects:
-
Object recognition.
-
Text recognition. This specifically refers to recognizing text on menus, shop signs, and product packaging images, rather than traditional recognition of newspaper or magazine content.
-
3D reconstruction.
Object Recognition

In our life scenarios, there is a significant demand for object recognition, such as:
-
Ele.me needs to detect whether riders are dressed appropriately. Given the large number of riders, manual control is clearly not feasible.
Thus, we added a dress detection feature in the rider’s app. Riders only need to send a selfie that includes their hat, clothing, and food delivery box to the platform daily, and our image algorithm can automatically perform detection and recognition in the background.
By detecting faces, we can identify whether it is the rider themselves, and check their food delivery box and helmet.
-
Scene object recognition. By detecting pedestrians, office chairs, and elevator buttons, we ensure that robots can recognize various objects in unmanned delivery scenarios.
-
Compliance detection. There are numerous product, dish, and sign images on the Ele.me platform, as well as business licenses, health permits, and health certificates.
Therefore, we need to collaborate with government departments to verify whether the business licenses and health permits of restaurants have been tampered with using watermarks and QR codes.
Additionally, we require that restaurant dish images do not include the restaurant’s sign text. This involves a significant amount of computer vision processing.
-
Scene text recognition. Based on object recognition, we apply target detection to recognize text on objects, such as dishes and prices on menus.

For evaluating image target detection, there are currently two industry indicators:
-
Mean Average Precision. This refers to the accuracy of object box classification. First, calculate the accuracy for each category, and then obtain the overall accuracy across all categories.
-
IOU (Intersection Over Union). This is the ratio of the overlap between the predicted object box and the actual standard object box, which is the ratio of the intersection to the union.
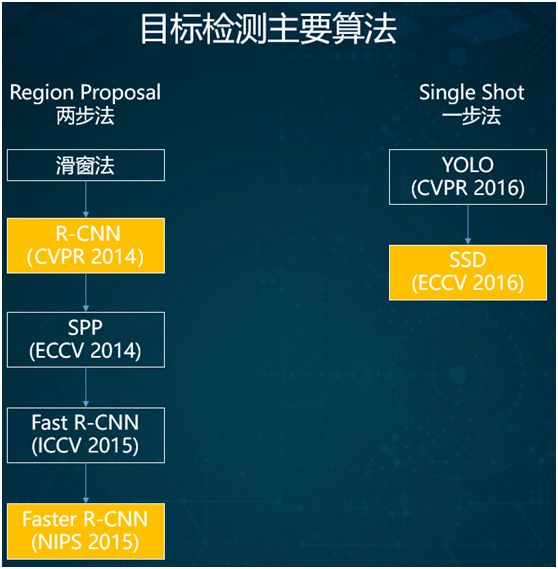
The image above lists commonly used basic algorithms for target detection, which can be divided into two categories:
-
Two-stage methods
-
One-stage methods
Two-stage methods have been around longer, originating from traditional sliding window methods. In 2014, R-CNN, which employed deep learning for object detection, emerged.
Subsequently, the SPP method with pyramid pooling appeared, followed by the development of Fast R-CNN and Faster R-CNN versions.
Of course, when the Faster R-CNN algorithm is applied to robots for real-time detection, it often puts tremendous pressure on the system’s performance to achieve millisecond-level detection feedback.
Therefore, one-stage methods were proposed, the most commonly used being the SSD algorithm introduced in 2016.
Although some new algorithms emerged in 2017 and 2018, they have not gained widespread recognition and require further “settling”.
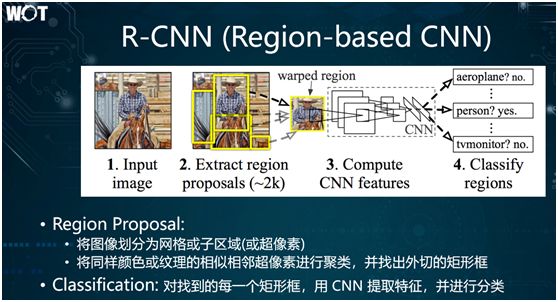
Next, we will discuss the solution algorithms for different scene targets. Here, I will not involve any formulas or derivations, but will describe the core ideas behind various target detection algorithms in simple and straightforward language.
The simple idea of R-CNN is:
-
Region Proposal. First, divide the target image into many grid cells, which are called superpixels; then cluster similar neighboring superpixels with the same color or texture and find the outer rectangle. This rectangle is called the Region Proposal.
-
Classification. First, use CNN to extract features; then obtain the linear graph of the convolution and perform regular classification using SoftMax or other classification methods.

The biggest problem with the various R-CNN processes is: the excessive number of candidate boxes generated. Due to the varying shapes of the rectangles, including length, width, center coordinates, etc., if a single image contains many objects, the number of detected rectangles can reach thousands.
Given that each candidate box requires a separate CNN classification, the overall efficiency of the algorithm is not high. However, R-CNN provides a new solution idea as the basis for subsequent improved algorithms.
The characteristics of SPP (Spatial Pyramid Pooling) are:
-
All candidate boxes share a single forward computation of the convolutional network. That is: first perform a one-time CNN computation on the entire image to extract features, and then perform subsequent operations on the feature response map. This significantly improves performance as it only requires convolutional computation.
-
Obtaining ROI regions at different scale spaces through a pyramid structure. That is: by dividing the image into many different resolutions, detecting objects at different scales.
For example, if an image contains both an elephant and a dog, due to the large size difference between the elephant and the dog, traditional R-CNN detection can only focus on the area occupied by the elephant.
SPP will shrink the image to locate the smaller image. It can first detect the elephant, then zoom in to detect the dog. This allows it to capture features of the image at different scales.
-
Fast R-CNN simplifies SPP while using various acceleration strategies to improve performance. However, it does not significantly change the algorithm strategy.
-
Faster R-CNN creatively proposes using a neural network RPN (Region Proposal Networks) to replace traditional R-CNN and SPP, gaining widespread application.
It uses a neural network to obtain object boxes, then uses subsequent CNN to detect the object boxes, achieving end-to-end training.
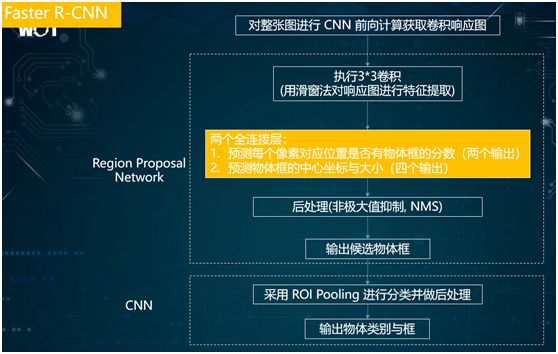
The image above is a logical framework diagram of the execution of Faster R-CNN that I have organized, with the process as follows:
-
Use CNN to compute the convolution response map of the image.
-
Execute 3×3 convolution.
-
Use two fully connected layers to predict whether there is an object box at each pixel’s corresponding position, generating two outputs (the probability of “yes” and “no”).
If there is an object box output, predict the center coordinates and size of the object box. Here, there are four outputs (the X and Y coordinates of the center, as well as the length and width). Therefore, for each object box, there are a total of six outputs.
-
Use the general NMS for post-processing, aiming to filter out some overlapping object boxes. For example, if there is a group of puppies in the image, the detected object boxes may overlap.
By using NMS, we can merge or ignore these highly overlapping boxes and finally output the candidate object boxes.
-
Use CNN for classification.
It is evident that the various two-stage methods mentioned above, while high in precision, are relatively slow. In many real-world scenarios, we need to detect targets in real-time.
For instance, in autonomous driving, we need to detect surrounding vehicles, pedestrians, and road signs in real-time. Therefore, one-stage methods come into play. YOLO and SSD belong to this category.
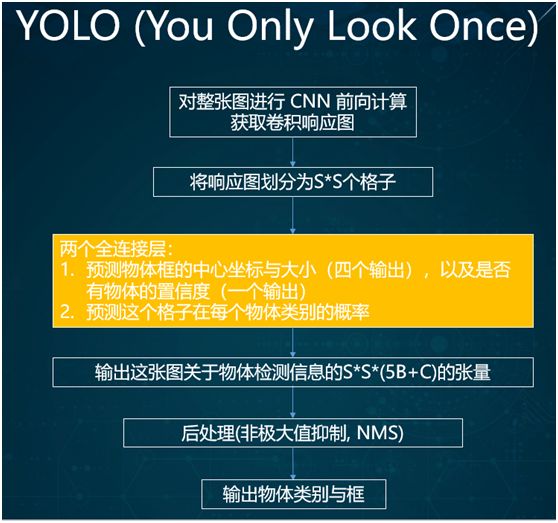
The core idea of the YOLO method is: only scan the entire image once, with the process as follows:
-
Use CNN to obtain the convolution response map.
-
Divide the response map into S*S grid cells.
-
Use two fully connected layers to predict the center coordinates and size of the object box, as well as the probability of the grid belonging to the object category.
-
Store all object detection information in a tensor.
-
Use post-processing to output the object category and box.
Due to this method being relatively old, it is generally not the first choice in practical applications.
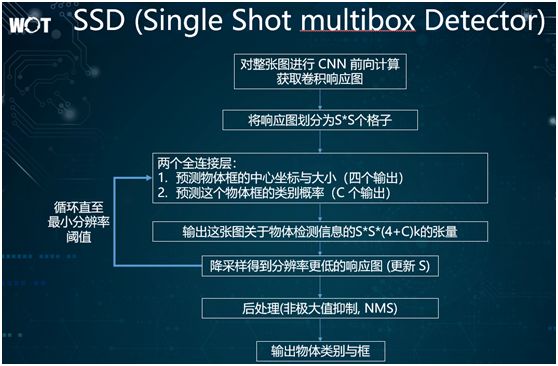
As our first choice, SSD adopts a processing method similar to the pyramid structure. It continuously downsamples the given image through iterations to obtain a lower resolution image.
Simultaneously, after downsampling the low-resolution image, this method repeatedly performs object detection to uncover object information.
Thus, the core idea of SSD is: to divide the same image into multiple levels, using downsampling from each level to the next level, thereby detecting the object boxes in each level image and presenting them.
It is evident that for YOLO, SSD can discover targets at different resolutions, uncover more candidate object boxes, and during subsequent reordering, we will obtain more lines of predictions.
Of course, SSD is also a very complex algorithm, containing many details and parameters that need adjustment, which may make it seem difficult to control.
Additionally, SSD is still a rectangular box detection algorithm; if the target object itself has an irregular shape or is elongated, we need to use the latest segmentation to achieve this.
Text Recognition

In addition to recognizing ID cards, health certificates, and business licenses through traditional OCR methods, we also need to perform OCR recognition in the following scenarios:
-
By recognizing shop signs to ensure that the uploaded photos match the shop’s own description.
-
By recognizing receipts and labels, transforming the traditional logistics process, which relies on human flow, into a more automated process.
-
Recognizing various menus.
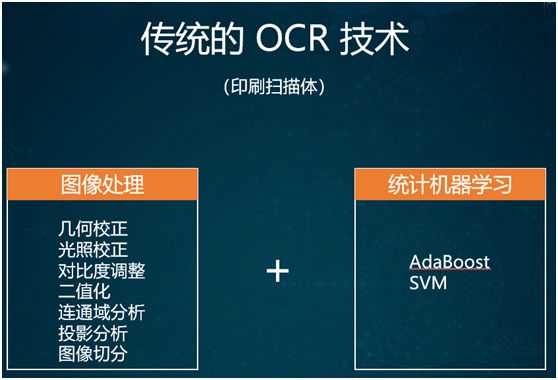
The traditional OCR process generally consists of three steps:
-
Simple image processing. For example: geometric correction based on the shooting angle.
-
Extracting features of the digital image and cutting it into individual characters.
-
Using statistical machine learning methods like AdaBoost or SVM for individual character optical text recognition.
However, for the following reasons, this process is not suitable for menu recognition in shops:
-
Due to excessive reliance on camera angles and geometric corrections, processing mobile captures involves a lot of semi-manual correction operations.
-
Since the target text is mostly outdoor advertisements, it is affected by lighting and shadows, and camera shake may cause blurriness, making traditional recognition models not robust and weak in anti-interference capability.
-
Due to the excessive chaining of the three-step model, the errors caused by each step may propagate and accumulate to the next step.
-
Traditional methods are not end-to-end models, and text line recognition must perform single character segmentation, making it impossible to recognize an entire line.

Therefore, we have adopted a two-step deep learning-based recognition solution: text line detection + text line recognition.
First, locate the text area in the image, and then use an end-to-end algorithm to achieve text line recognition.
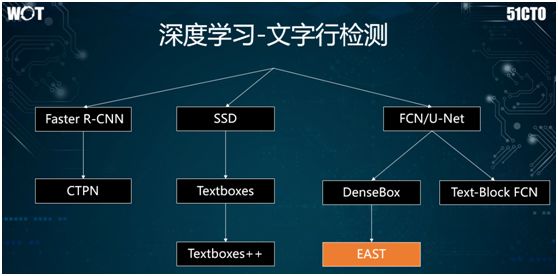
As shown in the image above, text line detection is derived from object recognition algorithms, including:
-
The CTPN method, which originated from Faster R-CNN, specifically for text line detection.
-
Textboxes and Textboxes++, derived from SSD.
-
EAST, derived from fully convolutional networks, also known as U-Net.
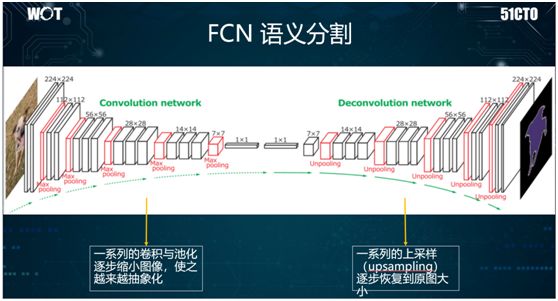
Speaking of fully convolutional networks (FCN), they are often used for semantic segmentation, and their OCR effect is also the best.
In principle, it uses convolutional networks to extract features, continuously performing convolution and pooling operations to reduce the size of the image.
Then, it performs deconvolution and unpooling operations to gradually enlarge the image, thus finding the edges of the objects in the image. Hence, the entire structure is U-shaped, strongly associated with U-Net.
As shown in the image above: we continuously reduce a clear image to obtain blue and white points with only a few pixels, and then gradually enlarge it to reveal multiple blue and white regions.
Next, based on this area, we use SoftMax for classification. Ultimately, we can find the edges of the objects in the image.

Through practice, we found that the best-performing method is based on the fully convolutional network EAST. As shown in the image above, its characteristic is the ability to detect quadrilaterals of any shape, rather than being limited to rectangles.
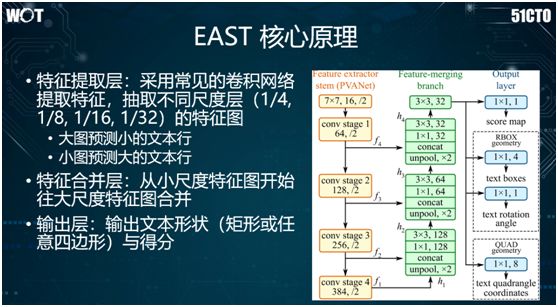
The core principle of EAST is: we continuously perform convolution operations on the left yellow area to shrink the image. In the middle green area, we merge features of different scales.
In the right blue area, we perform two types of detection based on the extracted features:
-
RBOX (rotated rectangle), assuming a text block is still rectangular, it is rotated to display the text above.
-
QUAD (arbitrary quadrilateral), given four points, connect them to form a quadrilateral for text detection.
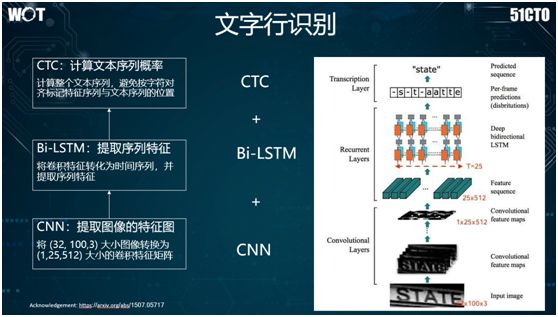
For text line recognition, the commonly used method in the industry is CTC + Bi-LSTM + CNN. As shown in the image above, we should look from bottom to top: first, we use CNN to extract the convolution feature response map of the given image.
Next, we convert the convolution features of the text line into sequence features and use bidirectional LSTM to extract the sequence features; finally, we use the CTC method to calculate the probability corresponding to the sequence features of the image and the text sequence features.

It is worth mentioning that the basic principle of the CTC method is: first, by adding a blank character, use SoftMax to classify the step features and the corresponding characters.
Thus, for each image sequence, it can obtain the probability of the character sequence appearing. After post-processing, the blank characters and repeated symbols are removed, ultimately outputting the result.
3D Reconstruction
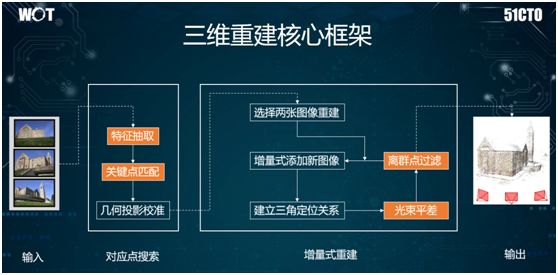
In autonomous driving scenarios, we may sometimes need to construct a three-dimensional structure of a building by moving cameras and collecting data.
As shown in the image above, the core framework is: first, perform not only CNN feature extraction on various given images, we can also use SIFT methods (see below) to extract some corner features.
Then, we triangulate these corners to find the spatial location of the camera through matching.
Finally, we use bundle adjustment to continuously construct the relationship between the spatial location and the camera itself, thereby achieving 3D construction.
As mentioned, SIFT feature extraction is characterized by its relatively slow speed. Therefore, to meet the near real-time 3D construction requirements while the camera is moving, we need to perform extensive tuning on this algorithm.
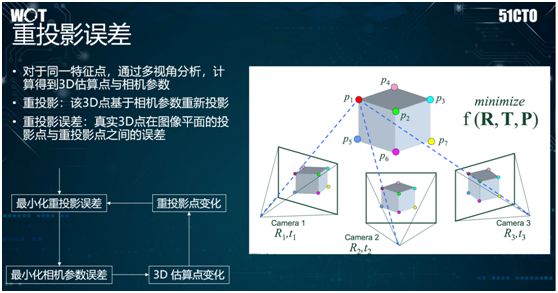
Additionally, in 3D reconstruction, we need to pay attention to the concept of reprojection error. This arises because typically, three-dimensional points in reality are projected onto the camera and converted into points on a plane.
If we want to construct a three-dimensional model based on planar images, we need to reproject the points from the plane back into three-dimensional space.
However, if our estimation of the camera parameters is not accurate, it can lead to discrepancies between the reprojected points and their true positions in the three-dimensional world.
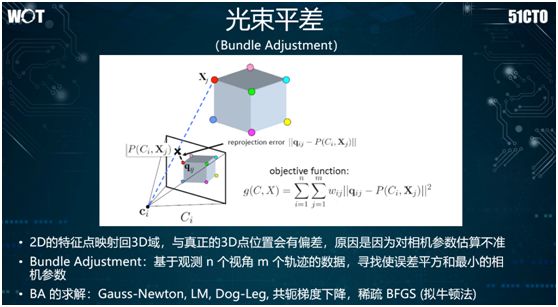
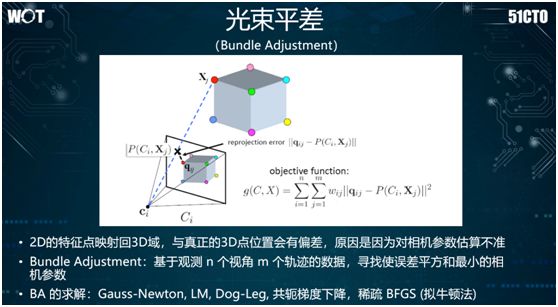
As mentioned earlier, we can also use bundle adjustment to solve the linear equations of the matrix. It typically employs sparse BFGS (quasi-Newton method) for solving, thereby restoring each three-dimensional point in space.

The final step involves filtering outliers. During the 3D reconstruction process, we encounter a lot of noise points, so to filter them, we will use the RANSAC method for outlier filtering.
In principle, it randomly samples a portion of points, constructs a free model, and then evaluates the best model.

As shown in the image above, due to the numerous edge position features in the two images above, we can use RANSAC outlier filtering to correspond their feature points and ultimately synthesize an image. Moreover, through the algorithm, we can automatically detect that the second image is tilted in angle.
In summary, we have experimented with numerous algorithms in the fields of object recognition, text recognition, and 3D reconstruction. We hope that through the above analysis, everyone can gain an understanding of the effects of various algorithms.
Author: Li Pei
Introduction: Head of the AI Department at Alibaba Local Life Research Institute
Editors: Tao Jialong, Sun Shujuan
Submission: If you have submissions or wish to seek coverage, please contact [email protected]

Recommended Articles:
I’m a technical director, why do you keep asking me about technical details?
What the heck is a middle platform? Everything you want to know is here!
I tried my best, so why are there still bugs?