For beginners who have never been exposed to NLP or Linux, even simple questions can become obstacles to achieving the final results. So, experts, please refrain from reading. No matter what, keep going; there is always a solution.
In statistical natural language processing, it is actually impossible to observe large-scale language instances. Therefore, people simply use text as a substitute and treat the contextual relationships in the text as substitutes for the contextual relationships of language in the real world. A collection of texts is referred to as a corpus, and when there are several such text collections, we call it a collection of corpora.
Introduction to Word2Vec:
Word2Vec is a tool that converts words into vector forms. It simplifies the processing of text content into vector operations in vector space, calculating the similarity in vector space to represent the semantic similarity of the text. Word2Vec is an open-source tool proposed by Google in 2013. It is a Deep Learning model (in fact, the model is relatively shallow and cannot strictly be considered a deep model. If another layer related to specific applications, such as Softmax, is added on top of Word2Vec, it would resemble a deep model more closely). It represents words as real-valued vectors and employs two models: CBOW (Continuous Bag-Of-Words Model) and Skip-Gram (Continuous Skip-Gram Model).
The source code for Word2Vec is written in C language for Linux. If you want to compile it on Windows, you need to use Cygwin; alternatively, you can try installing a Linux system on other virtual machines. Cygwin provides a Unix-like simulation environment on the Windows platform. The installation takes about half an hour, after which you can compile Word2Vec in Cygwin without needing to modify any code.
For beginners who have never been exposed to NLP or Linux, even simple questions can become obstacles to achieving the final results. So, experts, please refrain from reading. No matter what, keep going; there is always a solution.
In statistical natural language processing, it is actually impossible to observe large-scale language instances. Therefore, people simply use text as a substitute and treat the contextual relationships in the text as substitutes for the contextual relationships of language in the real world. A collection of texts is referred to as a corpus, and when there are several such text collections, we call it a collection of corpora.
Introduction to Word2Vec:
Word2Vec is a tool that converts words into vector forms. It simplifies the processing of text content into vector operations in vector space, calculating the similarity in vector space to represent the semantic similarity of the text. Word2Vec is an open-source tool proposed by Google in 2013. It is a Deep Learning model (in fact, the model is relatively shallow and cannot strictly be considered a deep model. If another layer related to specific applications, such as Softmax, is added on top of Word2Vec, it would resemble a deep model more closely). It represents words as real-valued vectors and employs two models: CBOW (Continuous Bag-Of-Words Model) and Skip-Gram (Continuous Skip-Gram Model).
The source code for Word2Vec is written in C language for Linux. If you want to compile it on Windows, you need to use Cygwin; alternatively, you can try installing a Linux system on other virtual machines. Cygwin provides a Unix-like simulation environment on the Windows platform. The installation takes about half an hour, after which you can compile Word2Vec in Cygwin without needing to modify any code.
 I had never used Cygwin before; I had only heard about it and seen installations of virtual machines running Linux systems. So I started from scratch and installed multiple times because some packages were not loaded.
First, install a Linux environment simulator on Windows; Cygwin is recommended.
http://www.cygwin.com/install.html
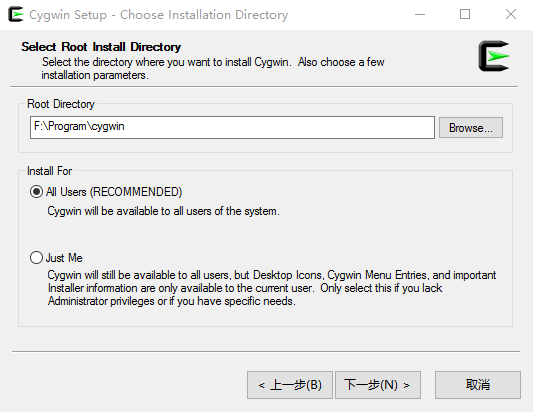
(1) Choose the installation path.
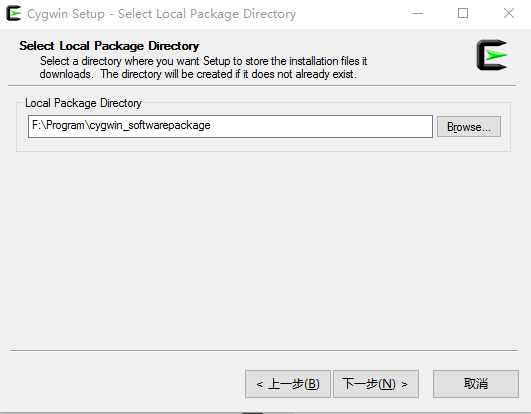
(2) Choose the installation package path.
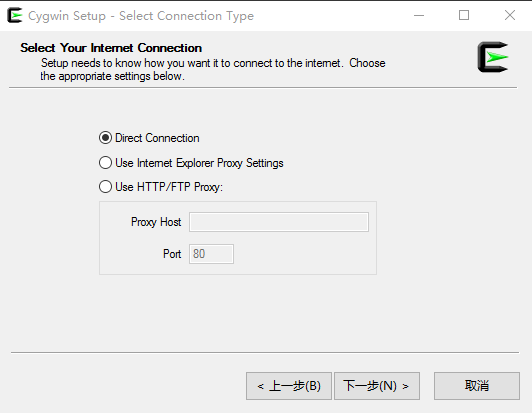
(3) For the first installation, choose Direct Connection.
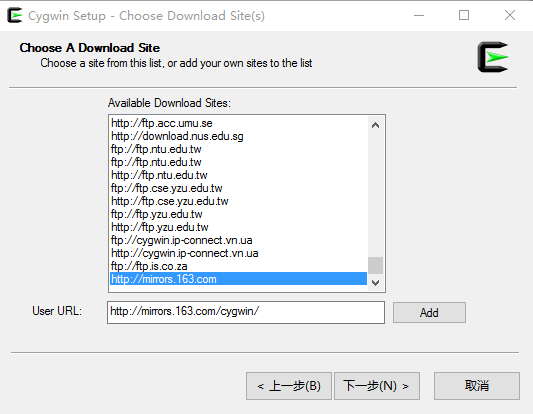
(4) Choose the 163 mirror for downloading; it is relatively fast.
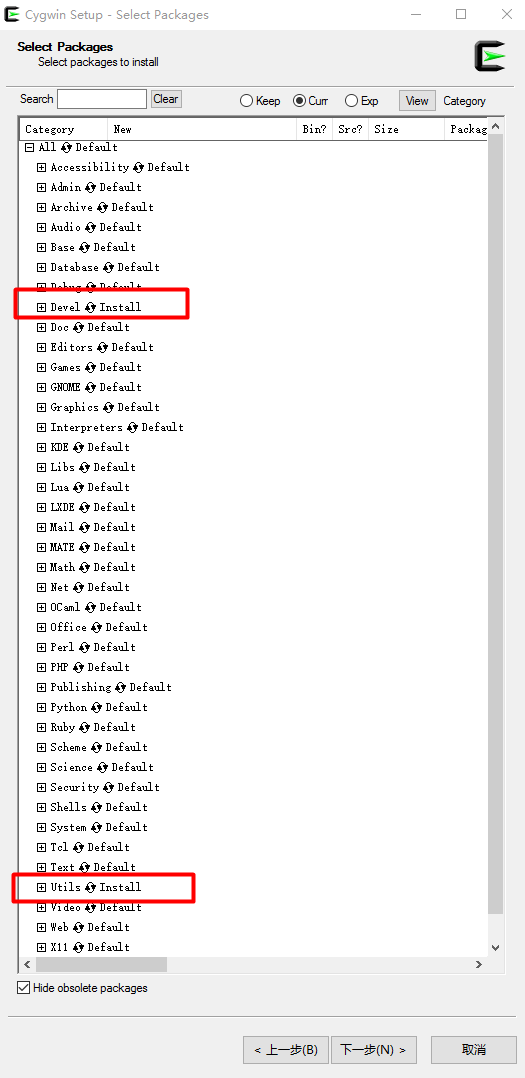
(5) Since Word2Vec requires a Linux environment, be aware during installation: by default, the make command tool is not installed (which will be needed later), so during installation, when choosing packages, select the Devel and Utils modules, as shown below:
(6) After that, just keep clicking to confirm the installation. Once installed, this icon will appear on the desktop:
Downloading and Using Word2Vec
(1) Download Word2Vec from the following link: https://github.com/dav/word2vec
This tool provides an efficient implementation of the continuous bag-of-words and skip-gram architectures for computing vector representations of words. These representations can be subsequently used in many natural language processing applications and for further research.
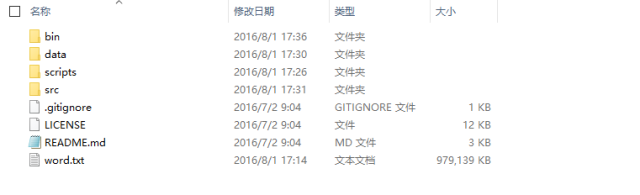
After downloading, it looks like this (excluding the last word.txt):
I had never used Cygwin before; I had only heard about it and seen installations of virtual machines running Linux systems. So I started from scratch and installed multiple times because some packages were not loaded.
First, install a Linux environment simulator on Windows; Cygwin is recommended.
http://www.cygwin.com/install.html
(1) Choose the installation path.
(2) Choose the installation package path.
(3) For the first installation, choose Direct Connection.
(4) Choose the 163 mirror for downloading; it is relatively fast.
(5) Since Word2Vec requires a Linux environment, be aware during installation: by default, the make command tool is not installed (which will be needed later), so during installation, when choosing packages, select the Devel and Utils modules, as shown below:
(6) After that, just keep clicking to confirm the installation. Once installed, this icon will appear on the desktop:
Downloading and Using Word2Vec
(1) Download Word2Vec from the following link: https://github.com/dav/word2vec
This tool provides an efficient implementation of the continuous bag-of-words and skip-gram architectures for computing vector representations of words. These representations can be subsequently used in many natural language processing applications and for further research.
After downloading, it looks like this (excluding the last word.txt):
 Since I had never used Cygwin or any Linux-related software before, I always encountered errors when trying to use make directly in the Cygwin terminal window.
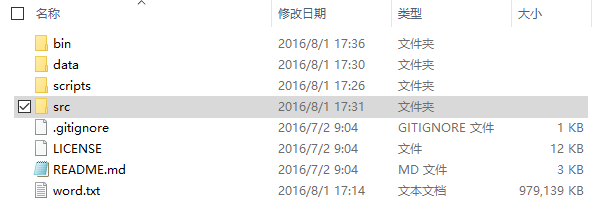
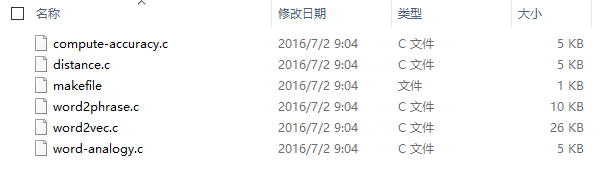
(2) Open Cygwin, switch to the downloaded Word2Vec folder, enter the ./src folder (the files shown below are visible in the Windows window), then type make in the Cygwin window and press Enter:
After running make, some executable files will be generated in the bin folder, which can be seen in the Windows window:
(3) After entering the bin folder, type the following code in the Cygwin window (because we need to use word2vec.exe from the bin files).
time ./word2vec -train 2.txt -output 3.txt -cbow 1 -size 100 -window 8 -negative 25 -hs 0 -sample 1e-4 -threads 20 -binary 0 -iter 15
-train “data/2.txt” indicates that the model is trained on the specified corpus; 2.txt is the corpus to be trained, which should be pre-processed with tokenization for Chinese. The details about tokenization will be explained at the end.
-cbow 1 indicates using the CBOW model; setting it to 0 means using the Skip-Gram model.
-size 100 means the dimension of the word vectors is 100.
-window 8 means the training window size is 8, considering eight words before and after a word. -negative 25 -hs 0 indicates whether to use negative sampling or the hierarchical softmax algorithm.
-sample 1e-4 indicates the threshold.
-threads 20 indicates the number of threads.
-binary 0 indicates that the output file is saved in non-binary format.
-iter 15 indicates the number of iterations.
About the Training Corpus and Related Processing
This time, the requirement is to train a Chinese corpus, which involves the tokenization process. For the first training, it is recommended to find a smaller text (around 1M), save it as a .txt document, replace punctuation with spaces, and use the Ansj tool for tokenization. Import the Ansj jar package into a Java project, then create the following class (your own code) to read the file, process it line by line, tokenize it, and write the file to complete the tokenization process.
public static void main(String[] args) throws Exception {
String infilepath=”D:\1.txt”;//source file
String outfilepath=”D:\2.txt”;//tokenized file
BufferedReader readfile = new BufferedReader (new InputStreamReader(new FileInputStream(infilepath),”GB2312″));
BufferedWriter writefile = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(outfilepath),”GB2312″));
while((line= readfile.readLine())!= null){
System.out.println(line);
writefile.write(ToAnalysis.parse(line).toString());
writefile.flush(); //flush the buffer data to the file
System.out.println(“Tokenization complete”);
After training, there may be occurrences of consecutive spaces in the result, which can be replaced in Word. Below is the result after tokenization.
Seated on the ground, in this bustling city, letting go of all the pressure that shouldn’t exist, freely imagining and chatting. Xiaoyan drinks beer, suddenly tears flow uncontrollably. He leans on the table and cries. The people around glance at him and then continue eating and chatting because those who have eaten at the big stall for a long time are used to seeing strangers’ tears. He calls out the name of his senior sister, crying and shouting. He knocks over the beer bottle, and the glass shards fall on his leg, which is wearing shorts. His leg is injured, but he continues to cry. He doesn’t even feel the blood flowing from his leg; he only recalls the past, which makes him feel painful. He says, “Don’t leave me, please don’t leave me. Don’t say I’m a child; I have grown up! I have grown up!” My tears are welling up in my eyes because I know he has been single during the best time of his career in the past two years. He is tired of crying and lifts his head. I see his red eyes. He says, “Can I call her?” I nod. He takes out his phone and skillfully dials the number he has memorized. The call connects, but neither of them speaks. He just keeps crying for a long time and then says, “I’m sorry, I was just a kid then.” At this moment, he looks just like a child, tears falling onto his leather shoes, snot dripping onto his suit. Xiaoyan falls asleep crying at the big stall. My brother and I carry him to the hotel. Suddenly, his phone rings with a number that has not been saved. I answer, but there is no sound. I say, “I am Shanglong.” The other end says Shanglong tells him to be happy. The next day, when he wakes up, life will continue as before. Xiaoyan will still embark on the road back to the United States, and I will continue to do what I should do. In fact, we are all the same. No matter how beautiful the past was or how moving the story was, we all have to return to reality and say goodbye to youth. We tease Xiaoyan, who cried like a dog yesterday, and question what happened between the two. He shyly says, “Did I lose my composure that much?” I say, “I really regret not bringing a DV to record it all.” Xiaoyan laughs and says, “At least it’s better than you, a single dog.” Just like that, he learned to joke. Before leaving, we passed by that big stall again. Xiaoyan paused for a moment and said, “I want to buy a few skewers of meat. Let’s eat together.” I laughed and said, “Don’t worry, I’ll pack the leftovers to take home.” Friendship and time. Some say friends don’t need to contact each other often; they just need to call when needed. They are always there. I believe that friends should not only be there when needed but also occasionally keep in touch, no matter how far apart we are; as long as the heart is close, it’s enough. What is touching is when a long-lost friend suddenly calls in the dead of night and cries out, “I’m sorry.” This story has been brewing in my mind for five years, and I didn’t know how to conclude it. Finally, because of that phone call, the knot deep in our hearts was untied. This ending may not be perfect, but it’s eternal. The roar of youth and the entanglement of time let us silently reminisce as we grow up. The monkey was my classmate in high school. To be precise, we are not classmates; he is just my friend. Because he didn’t perform well in school, he didn’t get into high school and went to a vocational school next door. At that time, the gangster culture was all the rage, and students from the neighboring vocational school would often flaunt their long hair in groups in front of our school, whistling at girls and even cornering boys to “talk” while pulling and pushing. Over time, whenever people heard that students from their school were coming, they would take a detour. The relationship between the monkey and me was very good. During those high school years, he taught me about society, and I taught him about studying. Back then, I unintentionally mingled in the underworld, just wanting to get into a good university and then live quietly. But youth didn’t give me the peaceful time I wanted. One afternoon, I……
The file resulting from the tokenization corresponds to the 2.txt file, but the name can be defined differently. In the Cygwin window, type: time ./word2vec -train 2.txt -output 3.txt -cbow 1 -size 100 -window 8 -negative 25 -hs 0 -sample 1e-4 -threads 20 -binary 0 -iter 15
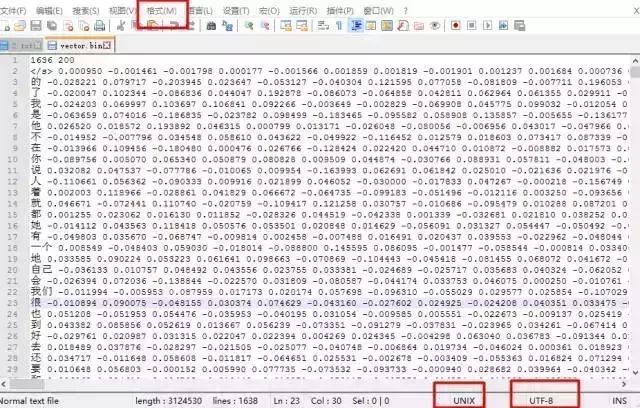
You can see the trained file 3.txt in the word2vec/bin folder. If you previously chose binary 0, this file can be directly opened in Windows, showing the results below, or viewed through vi 2.txt in the Linux environment.
If there is garbled text, you can use Notepad to convert the format.
Since I had never used Cygwin or any Linux-related software before, I always encountered errors when trying to use make directly in the Cygwin terminal window.
(2) Open Cygwin, switch to the downloaded Word2Vec folder, enter the ./src folder (the files shown below are visible in the Windows window), then type make in the Cygwin window and press Enter:
After running make, some executable files will be generated in the bin folder, which can be seen in the Windows window:
(3) After entering the bin folder, type the following code in the Cygwin window (because we need to use word2vec.exe from the bin files).
time ./word2vec -train 2.txt -output 3.txt -cbow 1 -size 100 -window 8 -negative 25 -hs 0 -sample 1e-4 -threads 20 -binary 0 -iter 15
-train “data/2.txt” indicates that the model is trained on the specified corpus; 2.txt is the corpus to be trained, which should be pre-processed with tokenization for Chinese. The details about tokenization will be explained at the end.
-cbow 1 indicates using the CBOW model; setting it to 0 means using the Skip-Gram model.
-size 100 means the dimension of the word vectors is 100.
-window 8 means the training window size is 8, considering eight words before and after a word. -negative 25 -hs 0 indicates whether to use negative sampling or the hierarchical softmax algorithm.
-sample 1e-4 indicates the threshold.
-threads 20 indicates the number of threads.
-binary 0 indicates that the output file is saved in non-binary format.
-iter 15 indicates the number of iterations.
About the Training Corpus and Related Processing
This time, the requirement is to train a Chinese corpus, which involves the tokenization process. For the first training, it is recommended to find a smaller text (around 1M), save it as a .txt document, replace punctuation with spaces, and use the Ansj tool for tokenization. Import the Ansj jar package into a Java project, then create the following class (your own code) to read the file, process it line by line, tokenize it, and write the file to complete the tokenization process.
public static void main(String[] args) throws Exception {
String infilepath=”D:\1.txt”;//source file
String outfilepath=”D:\2.txt”;//tokenized file
BufferedReader readfile = new BufferedReader (new InputStreamReader(new FileInputStream(infilepath),”GB2312″));
BufferedWriter writefile = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(outfilepath),”GB2312″));
while((line= readfile.readLine())!= null){
System.out.println(line);
writefile.write(ToAnalysis.parse(line).toString());
writefile.flush(); //flush the buffer data to the file
System.out.println(“Tokenization complete”);
After training, there may be occurrences of consecutive spaces in the result, which can be replaced in Word. Below is the result after tokenization.
Seated on the ground, in this bustling city, letting go of all the pressure that shouldn’t exist, freely imagining and chatting. Xiaoyan drinks beer, suddenly tears flow uncontrollably. He leans on the table and cries. The people around glance at him and then continue eating and chatting because those who have eaten at the big stall for a long time are used to seeing strangers’ tears. He calls out the name of his senior sister, crying and shouting. He knocks over the beer bottle, and the glass shards fall on his leg, which is wearing shorts. His leg is injured, but he continues to cry. He doesn’t even feel the blood flowing from his leg; he only recalls the past, which makes him feel painful. He says, “Don’t leave me, please don’t leave me. Don’t say I’m a child; I have grown up! I have grown up!” My tears are welling up in my eyes because I know he has been single during the best time of his career in the past two years. He is tired of crying and lifts his head. I see his red eyes. He says, “Can I call her?” I nod. He takes out his phone and skillfully dials the number he has memorized. The call connects, but neither of them speaks. He just keeps crying for a long time and then says, “I’m sorry, I was just a kid then.” At this moment, he looks just like a child, tears falling onto his leather shoes, snot dripping onto his suit. Xiaoyan falls asleep crying at the big stall. My brother and I carry him to the hotel. Suddenly, his phone rings with a number that has not been saved. I answer, but there is no sound. I say, “I am Shanglong.” The other end says Shanglong tells him to be happy. The next day, when he wakes up, life will continue as before. Xiaoyan will still embark on the road back to the United States, and I will continue to do what I should do. In fact, we are all the same. No matter how beautiful the past was or how moving the story was, we all have to return to reality and say goodbye to youth. We tease Xiaoyan, who cried like a dog yesterday, and question what happened between the two. He shyly says, “Did I lose my composure that much?” I say, “I really regret not bringing a DV to record it all.” Xiaoyan laughs and says, “At least it’s better than you, a single dog.” Just like that, he learned to joke. Before leaving, we passed by that big stall again. Xiaoyan paused for a moment and said, “I want to buy a few skewers of meat. Let’s eat together.” I laughed and said, “Don’t worry, I’ll pack the leftovers to take home.” Friendship and time. Some say friends don’t need to contact each other often; they just need to call when needed. They are always there. I believe that friends should not only be there when needed but also occasionally keep in touch, no matter how far apart we are; as long as the heart is close, it’s enough. What is touching is when a long-lost friend suddenly calls in the dead of night and cries out, “I’m sorry.” This story has been brewing in my mind for five years, and I didn’t know how to conclude it. Finally, because of that phone call, the knot deep in our hearts was untied. This ending may not be perfect, but it’s eternal. The roar of youth and the entanglement of time let us silently reminisce as we grow up. The monkey was my classmate in high school. To be precise, we are not classmates; he is just my friend. Because he didn’t perform well in school, he didn’t get into high school and went to a vocational school next door. At that time, the gangster culture was all the rage, and students from the neighboring vocational school would often flaunt their long hair in groups in front of our school, whistling at girls and even cornering boys to “talk” while pulling and pushing. Over time, whenever people heard that students from their school were coming, they would take a detour. The relationship between the monkey and me was very good. During those high school years, he taught me about society, and I taught him about studying. Back then, I unintentionally mingled in the underworld, just wanting to get into a good university and then live quietly. But youth didn’t give me the peaceful time I wanted. One afternoon, I……
The file resulting from the tokenization corresponds to the 2.txt file, but the name can be defined differently. In the Cygwin window, type: time ./word2vec -train 2.txt -output 3.txt -cbow 1 -size 100 -window 8 -negative 25 -hs 0 -sample 1e-4 -threads 20 -binary 0 -iter 15
You can see the trained file 3.txt in the word2vec/bin folder. If you previously chose binary 0, this file can be directly opened in Windows, showing the results below, or viewed through vi 2.txt in the Linux environment.
If there is garbled text, you can use Notepad to convert the format.
Formatting: Clear Water and Spring
Proofreading: Clear Water and Spring
Final Review: Jake

Let the apples fall harder!!!
Collective Intelligence Work: “Approaching 2050: Attention, Internet, and Artificial Intelligence”

▼
 ← Scan the QR code to purchase~
← Scan the QR code to purchase~
As the artificial intelligence program AlphaGo defeats human Go world champion Li Shishi with a score of 4:1, concerns about machines conquering humans are rising. “Approaching 2050: Attention, Internet, and Artificial Intelligence” depicts a new scenario of harmonious coexistence and co-evolution between humans and machines. In the visible future, humans will increasingly immerse themselves in various virtual worlds for different experiences, while willingly feeding their attention to the machine world to promote its evolution.
This book interprets technological fields, including the Internet, artificial intelligence, crowdsourcing, human computation, computer games, and virtual reality, from the perspective of attention, and creatively proposes a series of new concepts: the theory of attention, the Turing machine-participant model, the era of “games +”, attention-based economy, automated game design, automated entrepreneurship, attention currency, wish trees, etc. All of these will provide profound insights into understanding the relationship between technology and humanity, as well as into the future development and direction of human society.

Long press to recognize the QR code, follow the Collective Intelligence Club WeChat,
Let us get closer to scientific exploration.