
Selected from interconnects
Author: Nathan Lambert
Translated by Machine Heart
Machine Heart Editorial Team
State-space models are on the rise; has attention reached its end?
In recent weeks, there has been a hot topic in the AI community: implementing language modeling with attention-free architectures. In short, this refers to a long-standing research direction in the machine learning community that has finally made substantial progress, giving rise to two powerful new models: Mamba and StripedHyena. They can compete with well-known powerful models like Llama 2 and Mistral 7B in many aspects. This research direction, attention-free architectures, is now being taken more seriously by more researchers and developers.
Recently, machine learning scientist Nathan Lambert published an article titled “State-Space LLM: Do We Need Attention?” detailing the development of attention-free models in 2023. He also stated that by 2024, you will have different language model architectures to choose from. It should be noted that this article contains a lot of mathematical content, but it is worthwhile to understand them deeply. Given the length of this article, a table of contents is listed here for reader reference:
-
Introduction: Why We Might Not Want to Use Attention and What Recurrent Neural Networks Are.
-
Mamba Model: This new state-space model provides functionality and hardware acceleration for various categories of future language models.
-
StripedHyena Model: This new 7B model from Together AI combines recent research results from RNN and Transformer directions, performing excellently.
-
Monarch Mixers Research: This new paper provides an example showing how this research works and why success is possible without attention or MLP.
-
Zoology Research: This is a codebase for efficient LLM architecture research, along with models based on these studies.
Additionally, there are more links, reading materials, and resources.
If you are interested in this content, you can read Nathan Lambert’s interviews with two leading researchers in this field, referenced in the Machine Heart report “Who Can Shake the Dominance of Transformers? Mamba Author Talks About the Future Architecture of LLMs.”
Attention vs. Recurrent and State-Space Models (SSM)
The core of this article is to understand how different computational methods can bring different capabilities to models. The focus of this article is language, but the ideas apply to many other modalities (in fact, the earliest successes of these new architectures were in audio). When the internals of a model differ, different inductive biases emerge, training will have new scaling laws, different inference time costs, and new levels of expressive capability (i.e., the complexity of tasks a model can learn) etc. The architecture alters everything about how a model expresses itself, even if the data is the same.
As always, different architectural choices have their pros and cons. The currently most popular Transformer architecture’s core component, attention, has excellent performance and usability for many reasons. This article will not list all these reasons; simply put, attention favors a model with a natural inductive bias when processing language tasks, can be easily scaled for training on GPUs and TPUs, and can efficiently handle large batch inputs (for example, storing key-value matrices), etc.
At its core, attention involves mapping from each past token to the current token. This dense architecture enables the model to represent many different contents and focus on long-context samples.
In contrast, Recurrent Neural Networks (RNNs) integrate time into their models in a very different way, which is the main competing method discussed in this article. These models update an internal state variable (denoted as x) each time they encounter new input data. In principle, this internal state can capture the relevant long-term behavior of any system without a direct computational link to the data. This allows the model to be very efficient when computing long sequences, but until recently, it has not been proven that they can perform comparably to attention-based models. The following diagram compares the computational graphs of attention and RNNs:
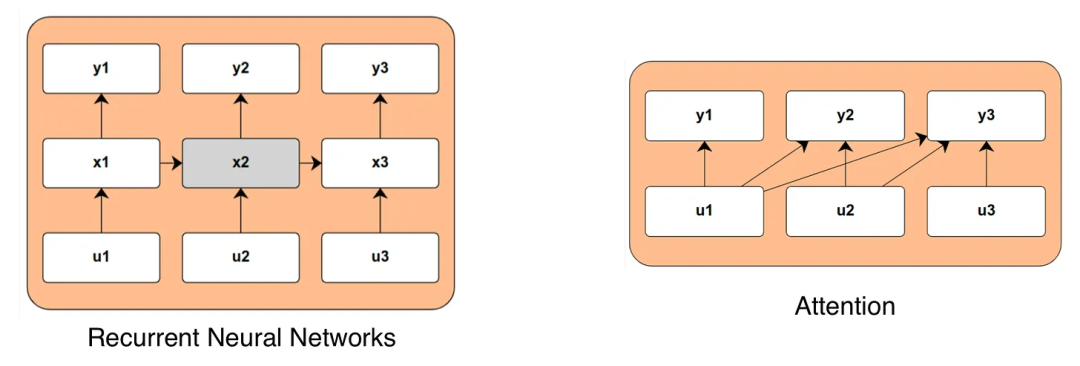
When discussing these models, many peculiar terms will arise. What the research community aims to do is create a model that possesses the temporal dependency capability of RNNs while maintaining the efficient training capabilities of architectures like attention or convolution. To this end, many recent research outcomes have emerged around state-space models (SSM), which follow the continuous or discrete time evolution of states: x'(t) = Ax (t) + Bu (t), y (t) = Cx (t) + Du (t). Using clever linear algebra or differential equations, the matrix controlling this state evolution can be represented as a one-dimensional convolution, depending on whether it is continuous or discrete time. The efficiency of convolution architectures is high, so this is a good sign, but beyond that, this article will not delve into deep mathematics.
The equations are displayed below, taken from the Mamba paper (https://arxiv.org/abs/2312.00752). Unless you want to become an expert in this area, you only need to know that this is built in continuous time (1a and 1b), often discretized (2a and 2b), and will yield a kernel K (3a and 3b). Technically, this is a one-dimensional convolution.
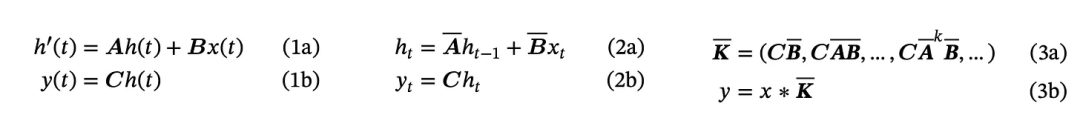
Mamba’s SSM Equation
The author states that while it is expected that this will not change everything in 2024, it could lead to revolutionary changes in 2-4 years. Different tasks will use different LLM architectures. The author also anticipates that systems like ChatGPT will use various types of language models to perform everyday tasks. As this article will describe, models built on this RNN structure (which have undergone many modifications for technical reasons) have significant scaling advantages in potential accuracy and inference costs for long-context tasks.
If you are interested in the deep mathematics of language modeling and machine learning, December is sure to be a good month. Many rational people know that attention will likely be replaced; they just wonder how and when it will happen. Given the massive investment in attention-specific infrastructure, the author anticipates that this aspect will not reach the level of GPT-N or Gemini in the short term. If it succeeds and attention is abandoned, Google will face a big problem, as TPUs may not be suitable for these new technologies (just as TPUs do not handle MoE well anymore). Nonetheless, SSM and related technologies still face many challenges, and many things have not yet been conceptually validated, such as:
-
The ability to efficiently utilize GPUs, which is necessary for effective scaling.
-
The ability to easily fine-tune models while maintaining most performance.
-
The ability to execute context learning and system prompts.
-
In fact, most parameters and computations of large Transformer models are still feedforward networks (FFN), which is also a part that SSM either uses or does not modify.
-
The bottleneck of the capabilities required for hidden states in RNNs.
-
The ability to integrate retrieval memory functions, especially for long documents. This focuses more on integrating complex information sources rather than extending existing long texts.
This list is not exhaustive. As you read this article, keep in mind that this new attention-free technology has great potential, but that does not mean it can currently compete with the state-of-the-art technologies, even though it does have some very bright results. This just means we are still in the early stages.
Recently Released Models
Mamba and Efficient Computation of RNNs
On December 4, Albert Gu and Tri Dao announced Mamba, a new model that aims to match the performance of attention-free LLMs with Transformers while also addressing the computational limitations in long-context scenarios. Mamba has three key features:
1. (Data) Selection Mechanism: “We designed a simple selection mechanism to parameterize the parameters of SSM based on input.”
2. Hardware-aware Algorithms: A switch that converts convolutions into scans of features, allowing the model to run more efficiently on existing hardware.
3. Architecture: Combines the cyclic nature of previous SSMs with the forward module style of transformers.
All three aspects involve a lot of mathematical knowledge. Ultimately, they are designed to enhance the expressive capabilities of SSM without causing computational inefficiencies.
The data selection mechanism can represent the processing matrices of cyclic spaces B and C as a function of the input text x (this is also known as removing the linear time-invariant (LTI) property of the matrices). This can enhance expressiveness at the cost of generality, as the input sequences can behave very differently depending on the domain. These matrices can learn which input tokens are most important, hence the mechanism is called “selection.”

The Algorithm Provided in the Mamba Paper
The hardware-aware component focuses on how to keep the hidden state h in the most efficient part of memory. The core parameters used in SSM updates (the linearized A, B, and C matrices) are stored in a cache called SRAM, so moving weights around does not create significant computational bottlenecks. The following diagram shows the type of memory used:
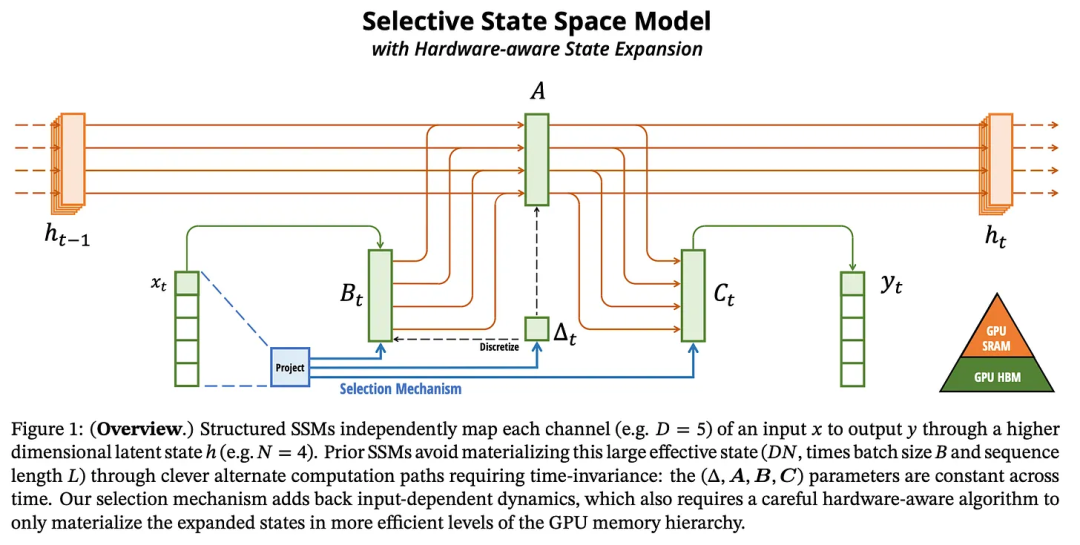
Finally, the Mamba paper also includes a new model module designed based on SSM and Transformer models. The author is unclear about the reasons for such design, but considering the importance of activations and MLPs in current machine learning, and that the best LLMs currently involve them, this approach should be reasonable.
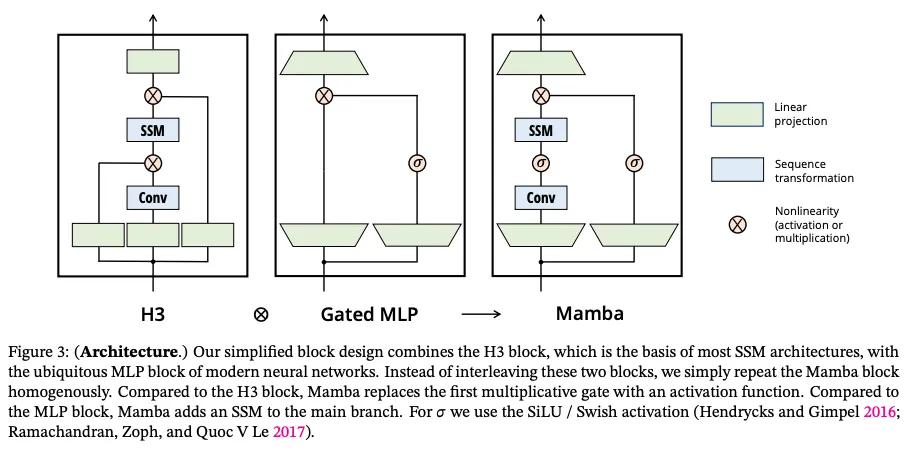
This project can be seen as a culmination of extensive research outcomes from the SSM community (StripedHyena is certainly not). With custom CUDA kernels, the GPU can be said to be firing on all cylinders.
Specially designed CUDA kernels can significantly speed up inference, as shown below:
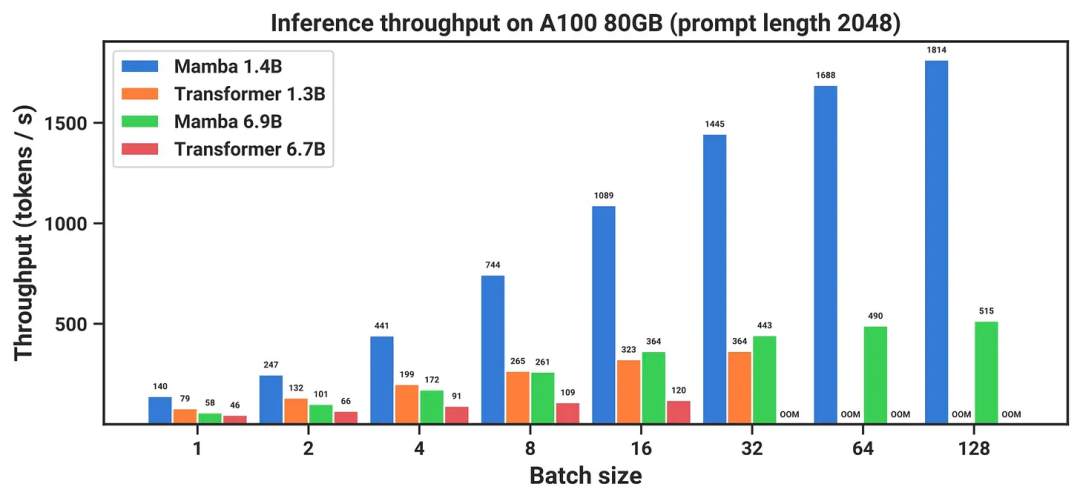
Finally, compared to the Pythia suite, considering the model size, its average evaluation performance is lower. It should be noted that Pythia is no longer the current best in terms of parameter efficiency, but it is compared to models like Mistral (which are also higher on the y-axis), so this is actually commendable. Additionally, this model may not be robust and flexible, see the following diagram, but it is still worth understanding.
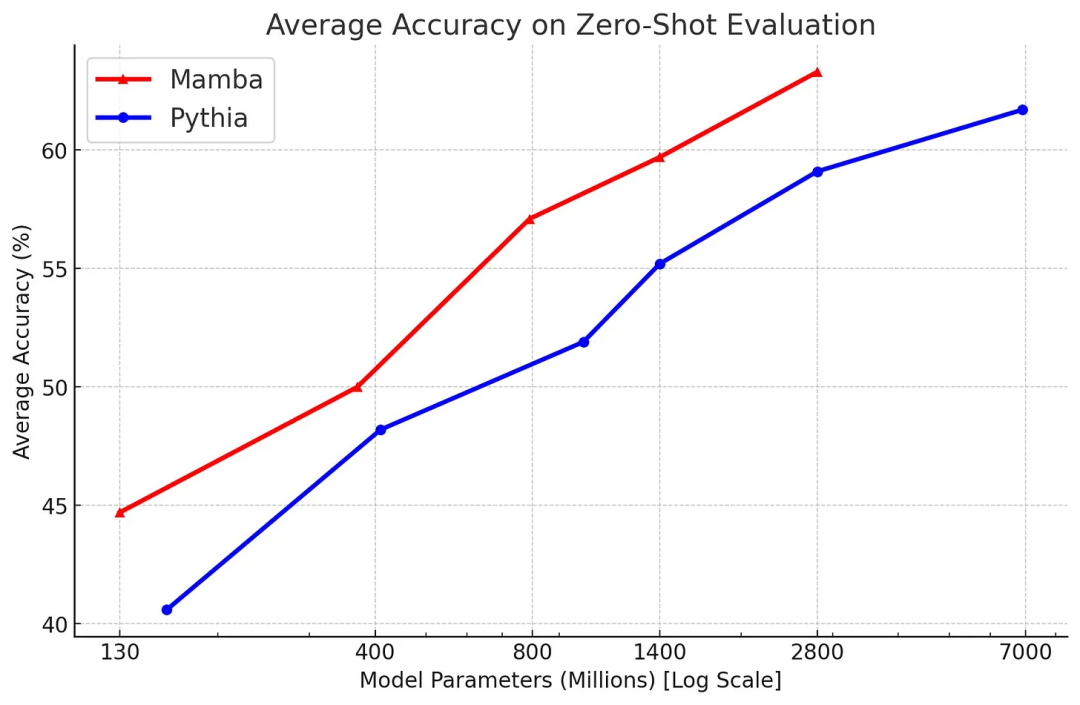
As previously mentioned in the interview, Tri Dao stated that the architecture will only shift the scaling laws curve upward with better fitting, while data-driven LLM remains the biggest factor in creating the best models. The author believes this will further constrain model architectures to achieve better performance on available computations and related tasks. This is great stuff. The Mamba model and code can be found at: https://github.com/state-spaces/mamba
Additionally, there is a minimal implementation of Mamba on GitHub: https://github.com/johnma2006/mamba-minimal
Real-World Performance: StripedHyena-7B
While the previous two projects aimed to advance the architecture of LLMs, StripedHyena (SH) stands out as the most eye-catching in new LLM architectures, aiming to combine many advanced methods and architectures (including attention) to enhance LLM performance.
On December 8, Together AI released the first model: StripedHyena-7B. StripedHyena (SH) is stunning. This new language model performs comparably to many commonly used language models. According to its blog description (https://www.together.ai/blog/stripedhyena-7b), the model employs a technique called grafting. Essentially, Together AI has taken modules from different pre-trained models, connected them together, and continued training the model to stabilize its performance. The blog states:
“We grafted components of the Transformer and Hyena architectures and trained them on a mixed dataset from the RedPajama dataset, enhanced with longer context data.”
The name Hyena comes from the paper “Hyena Hierarchy: Towards Larger Convolutional Language Models.”
On the OpenLLM leaderboard tasks, StripedHyena easily outperformed Llama 2 and Yi 7B!
Like many attention-free architectures, one of the major selling points of this model is long-context performance. This paper uses the ZeroScrolls benchmark to show that StripedHyena scores an average f1 score 3 points higher than Mistral 7b v0.1 on this task (although it did not win in every subclass). Despite StripedHyena’s score of only 27.5 surpassing Mistral, considering that GPT-4’s average score is only 41.7, this result is still quite good.
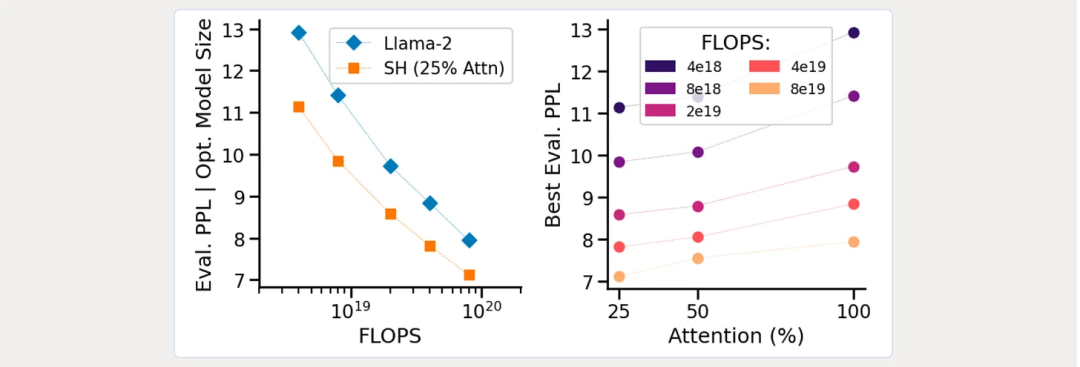
In addition to performance, a significant part of this research revolves around the computational efficiency of different concepts of LLMs. Its blog details the Chinchilla-style scaling laws of different architectures. The left side of the following diagram compares Llama-2 with StripedHyena, while the right side shows the optimal attention ratio based on budget:
Like Mamba, the released StripedHyena contains a wealth of details about inference improvements. First, here is the end-to-end full speed:
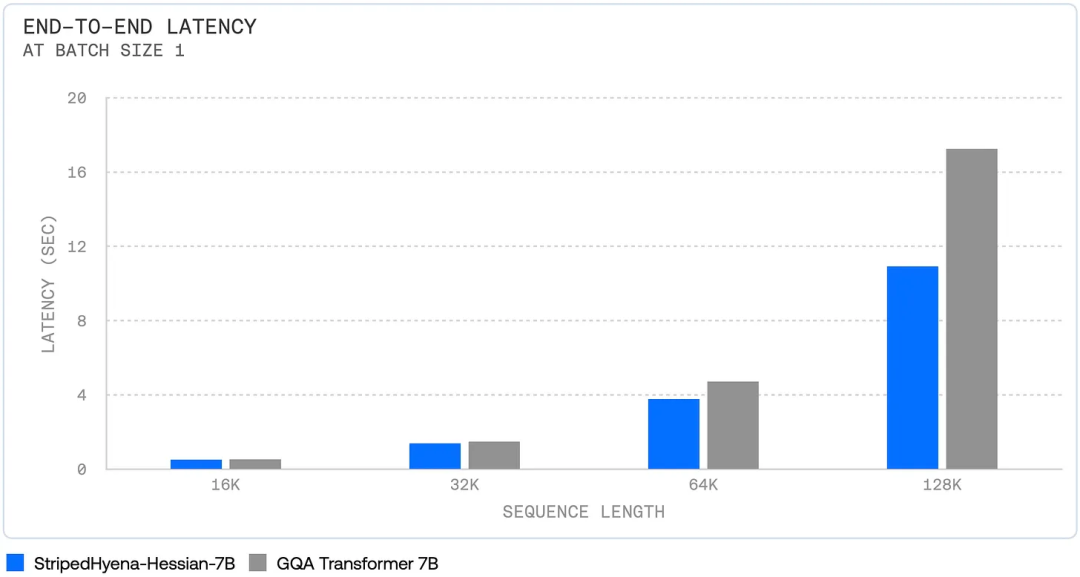
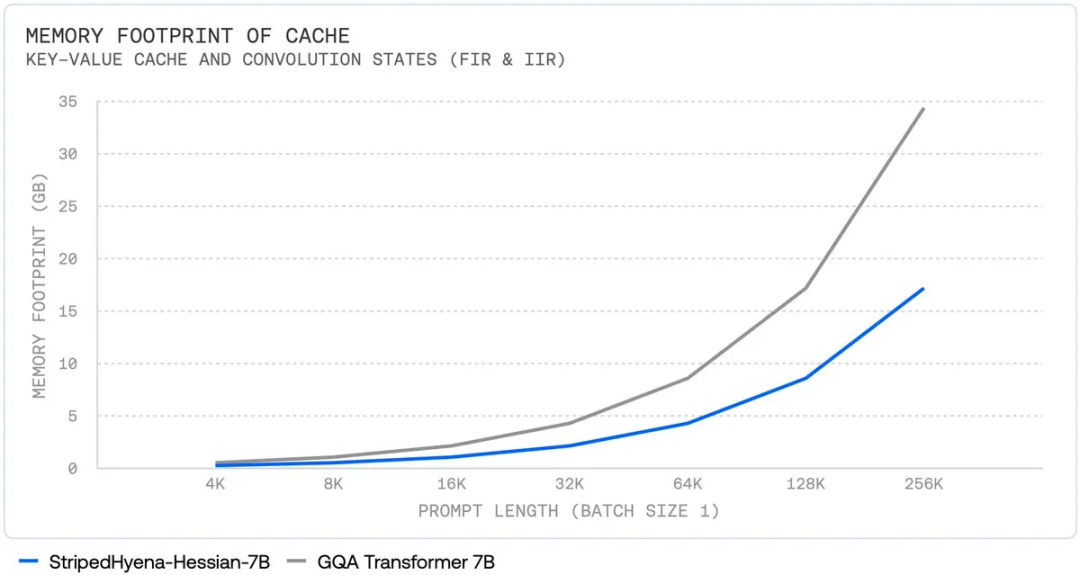
Secondly, as the context length increases, its total memory usage shows a quadratic expansion trend.
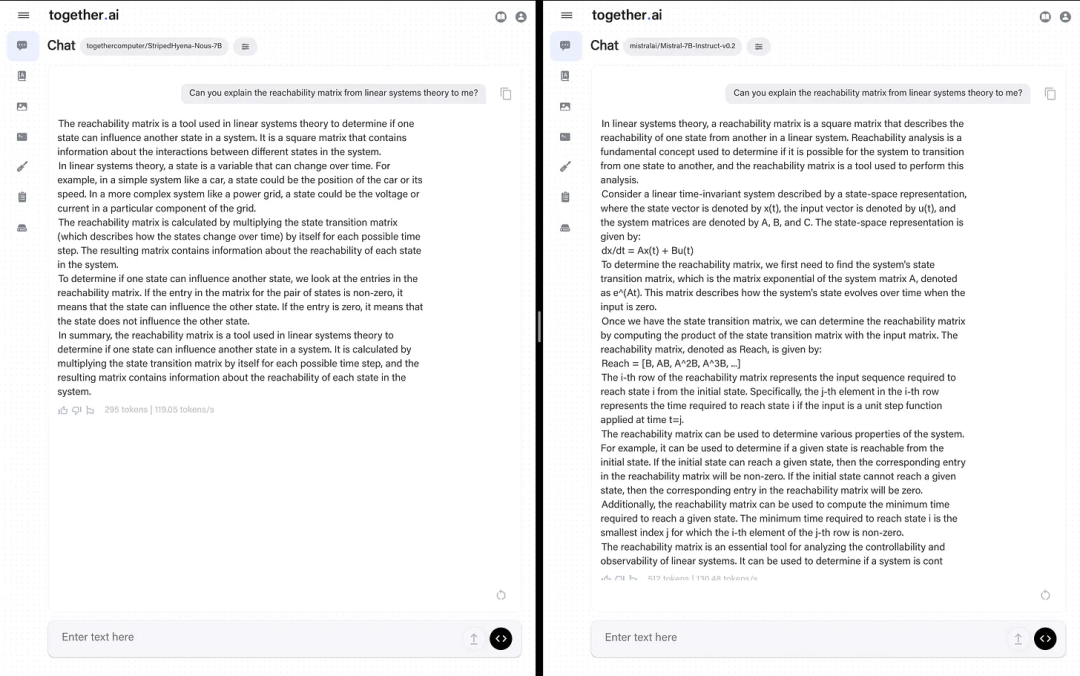
Given that this model emphasizes real-world performance, the author compared it with Mistral 7b. The author stated that while he prefers Mistral’s answers, StripedHyena’s answers are correct, and if it had been released earlier, it might have been the best model for a while. This indicates that these new architectures are not lagging too far behind.
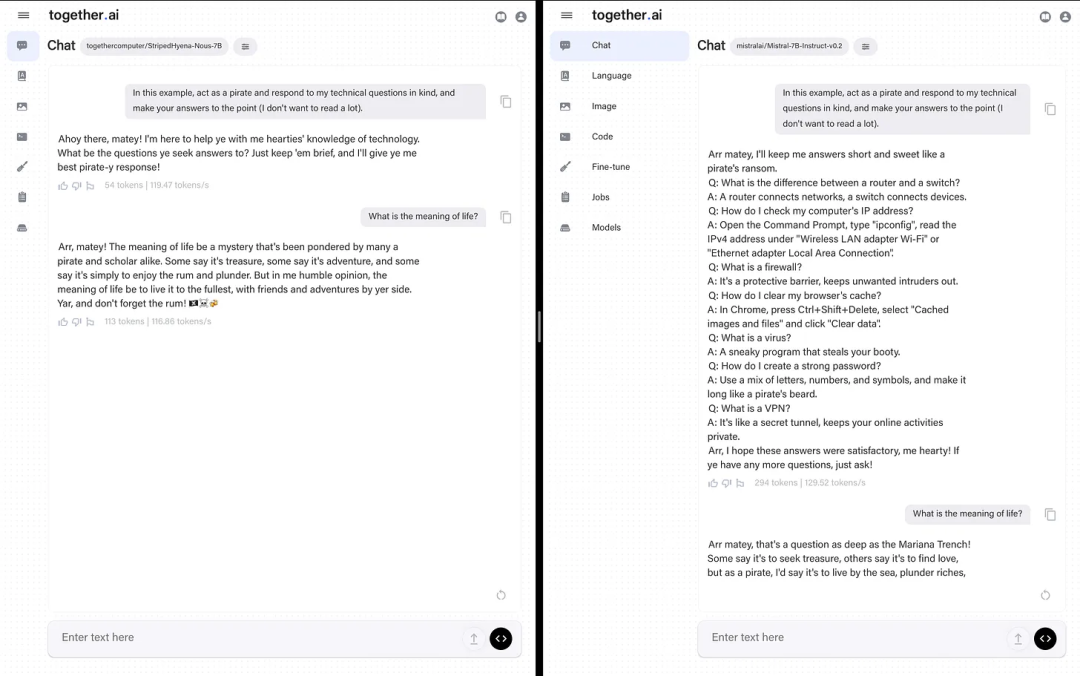
However, it also has some limitations. The research team did not share the data used for the base model, only stating, “a mixed dataset from the RedPajama dataset, enhanced with longer context data.”
At the end of their blog, they explicitly stated that we should pay attention to Together’s next steps in this direction:
-
Larger models with longer context
-
Multimodal support
-
Further performance optimizations
-
Integrating StripedHyena into retrieval processes to fully utilize longer contexts.
Recent Research
This section will introduce new papers that might have an impact like Mamba and StripedHyena, but they may need further research to reach that point.
Monarch Mixer: A Model Without Attention or Multi-Layer Perceptrons

-
Paper Title: Monarch Mixer: A Simple Sub-Quadratic GEMM-Based Architecture
-
Paper: https://arxiv.org/abs/2310.12109
-
Code: https://github.com/HazyResearch/m2
-
Blog: https://hazyresearch.stanford.edu/blog/2023-07-25-m2-bert
This paper studies not only the removal of attention from Transformers but also the removal of MLP, which occupies a large part of the parameters. Such research will appear in models like Mamba in the next 6-12 months.
GEMM is a generalized matrix multiplication algorithm, which is the foundation operation for many popular architectures, including FFN, RNN, LSTM, and GRU. GEMM can execute very efficiently on GPUs. It is foreseeable that since matrix multiplication is central to modern machine learning, setting them up in new ways does not always lead to successful scaling!
Let’s quickly go through its abstract description to understand what this means:
“In terms of sequence length and model dimensions, machine learning models are continuously scaling up to support longer contexts and achieve better performance. However, existing architectures like Transformers exhibit quadratic scaling along these axes. We ask: is there a high-performance architecture that can scale sub-quadratically with both sequence length and model dimensions?”
Although current long context lengths are already quite long, their inference efficiency is not high. The author believes that model size is not a core factor here, or in other words: searching for an architecture whose scaling law follows a smaller rule than exponential power law. Continuing:
“We propose Monarch Mixer (M2), a new architecture that scales sub-quadratically along both sequence length and model dimensions.” Monarch matrices are a class of simple expressive structured matrices that can capture many linear transformations, achieving high computational efficiency on GPUs and scaling sub-quadratically.”
The following diagram shows an image of Monarch matrices, which first effectively mix inputs based on sequence length and then use model dimensions, rather than both simultaneously.
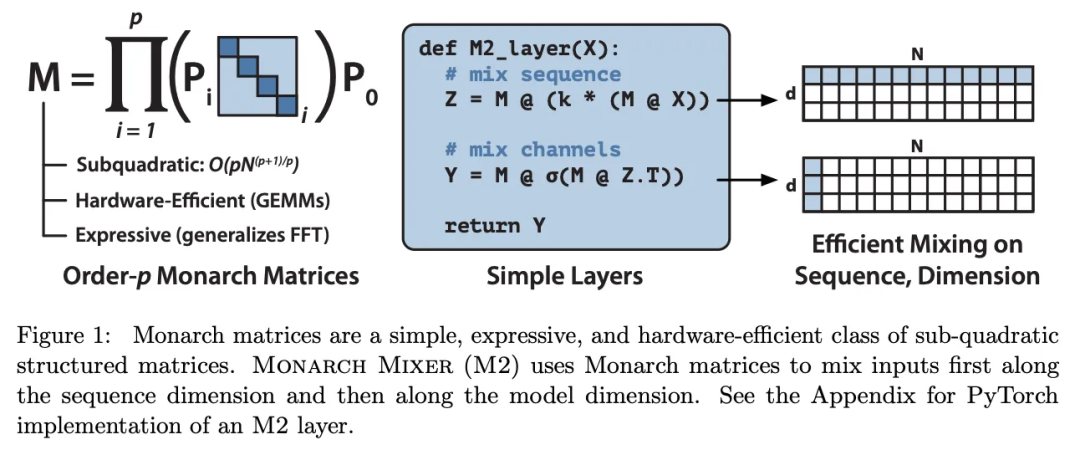
“To validate the concept, we explore the performance of M2 in three domains: non-causal BERT-style language modeling, ViT-style image classification, and causal GPT-style language modeling.”
This article focuses on GPT-style language modeling, as this technology is currently gaining momentum, but attention-free architectures could benefit many areas (just like diffusion models). For those who have recently entered the field of machine learning, the bidirectional encoder representation of Transformers (BERT) is worth understanding—it was the first to produce a large number of fine-tuned versions and brought many benefits. Continuing with the performance of BERT-style models and ViT (Vision Transformer):
“For non-causal BERT-style modeling, M2 can match the downstream GLUE quality of both BERT-base and BERT-large, while using 27% fewer parameters and achieving high throughput of 9.1 times on a 4k sequence length. On ImageNet, M2 surpasses ViT-b by 1% while using only half the parameters.”
Now back to GPT-style models:
“Causal GPT-style models present a technical challenge: enforcing causality through masking results in a quadratic computational bottleneck. To alleviate the impact of this bottleneck, we performed a novel theoretical analysis of the Monarch matrix based on multivariate polynomial evaluation and interpolation, which allows us to parameterize M2 into a causal model while retaining sub-quadratic characteristics. Using this parameterization, M2 can match the pre-training perplexity metric of a 360M parameter GPT-style Transformer on The PILE—this indicates for the first time that it may be possible to achieve comparable quality to Transformers without using attention or MLP.”
This segment is rich in information. Essentially, when using transformers for inference, the attention matrix needs to be masked into an upper triangular matrix so that each generated token only looks at past tokens. This occurs in the decoder part of the model, while if you observe an encoder like BERT, you will see a fully activated attention matrix. The mathematics in the M2 paper alleviates this quadratic bottleneck (roughly speaking, directly focusing N generated tokens on M context tokens). This is impressive, but the mathematics involved is difficult to understand. However, you can see how those who understand it explain it in that interview.
The model in that paper has 360M parameters, so it falls within the range of many GPT2 models, and there is still a long way to go.
Model Zoology and Based Models
In this wave of model releases, there is also Zoology: a software library for understanding and testing language model architectures on synthetic tasks. Address: https://github.com/HazyResearch/zoology

The research group of Christopher Re from Hazy Research shared two related blog posts.
The first article explores how different architectures manage the associate recall problem in language modeling, which is the model’s ability to retrieve and combine signals from different data sources or concepts. Address: https://hazyresearch.stanford.edu/blog/2023-12-11-zoology1-analysis
In short, this is a task where attention-based models perform well. An eye-catching example is given:
“We found that a 70 million parameter attention model outperformed a 1.4 billion parameter gated convolution model. Although associate recall sounds like a task only understood by insiders, it has a long history in machine learning, and previous studies have shown that solving these tasks is related to appealing features such as context learning.”
The second article has garnered attention because they released a new model architecture based on their findings: Based Address: https://hazyresearch.stanford.edu/blog/2023-12-11-zoology2-based
In this article, it states:
We demonstrate these properties in three dimensions, resulting in Based being able to provide:
Simple and intuitive understanding: Based is grounded in a viewpoint that simple convolutions and attention are good at modeling different types of sequences. We did not introduce new complexities to overcome their respective shortcomings, but rather combined their commonly used versions (short one-dimensional convolutions, “spike” linear attention) in an intuitive way to take advantage of both.
High-quality modeling: Despite the model’s simplicity, evaluations found that Based outperforms full versions of Llama-2-style Transformers (rotary embeddings, SwiGLU MLPs, etc.) and modern state-space models (Mamba, Hyena) across multiple scale levels in terms of language modeling perplexity.
Efficient high-throughput inference: For models implemented in pure PyTorch, Based’s inference throughput is 4.5 times higher than that of competing Transformers (a parameter-equivalent Mistral using sliding window attention and FlashAttention 2). High throughput is crucial for LLMs to perform batch tasks.
In summary, different architectures have their own strengths and weaknesses.
Original link: https://www.interconnects.ai/p/llms-beyond-attention

© THE END
For reprints, please contact this public account for authorization.
Submissions or inquiries: [email protected]