Hugging Face is a chatbot startup based in New York, focusing on NLP technology, with a large open-source community. Especially, the open-source natural language processing and pre-trained model library, Transformers, has been downloaded over a million times and has more than 24,000 stars on GitHub. Transformers provides a large number of state-of-the-art pre-trained language model architectures and calling frameworks in the NLP field.
https://www.oreilly.com/library/view/natural-language-processing/9781098103231/
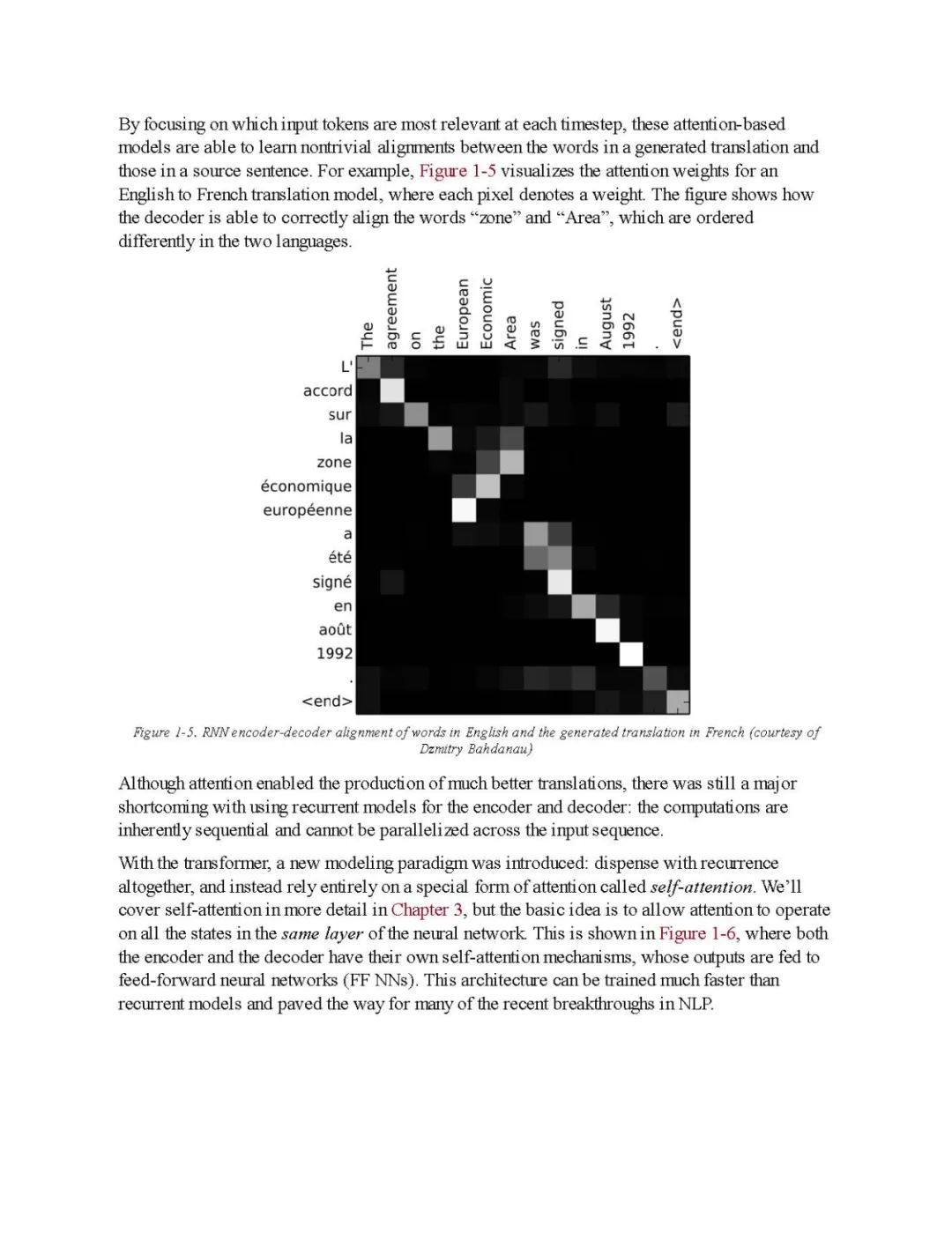
Since its launch in 2017, Transformers has quickly become the dominant architecture for achieving state-of-the-art results on various natural language processing tasks. If you are a data scientist or programmer, this practical book shows you how to use the Python-based deep learning library Hugging Face Transformers to train and scale these large models.
Transformers have been used to write real news stories, improve Google search queries, and even create chatbots that tell jokes. In this guide, authors Lewis Tunstall, Leandro von Werra, and Thomas Wolf (one of the founders of Hugging Face Transformers) use a hands-on approach to teach you how Transformers work and how to integrate them into applications. You will quickly learn about the various tasks they can help you solve.
Build, debug, and optimize Transformers models for core NLP tasks such as text classification, named entity recognition, and question answering.
-
Learn how to use Transformers for cross-lingual transfer learning.
-
Apply Transformers in real-world scenarios where labeled data is scarce.
-
Utilize techniques such as distillation, pruning, and quantization to make Transformers models efficient for deployment.
-
Train Transformers from scratch and learn how to scale to multiple GPUs and distributed environments.
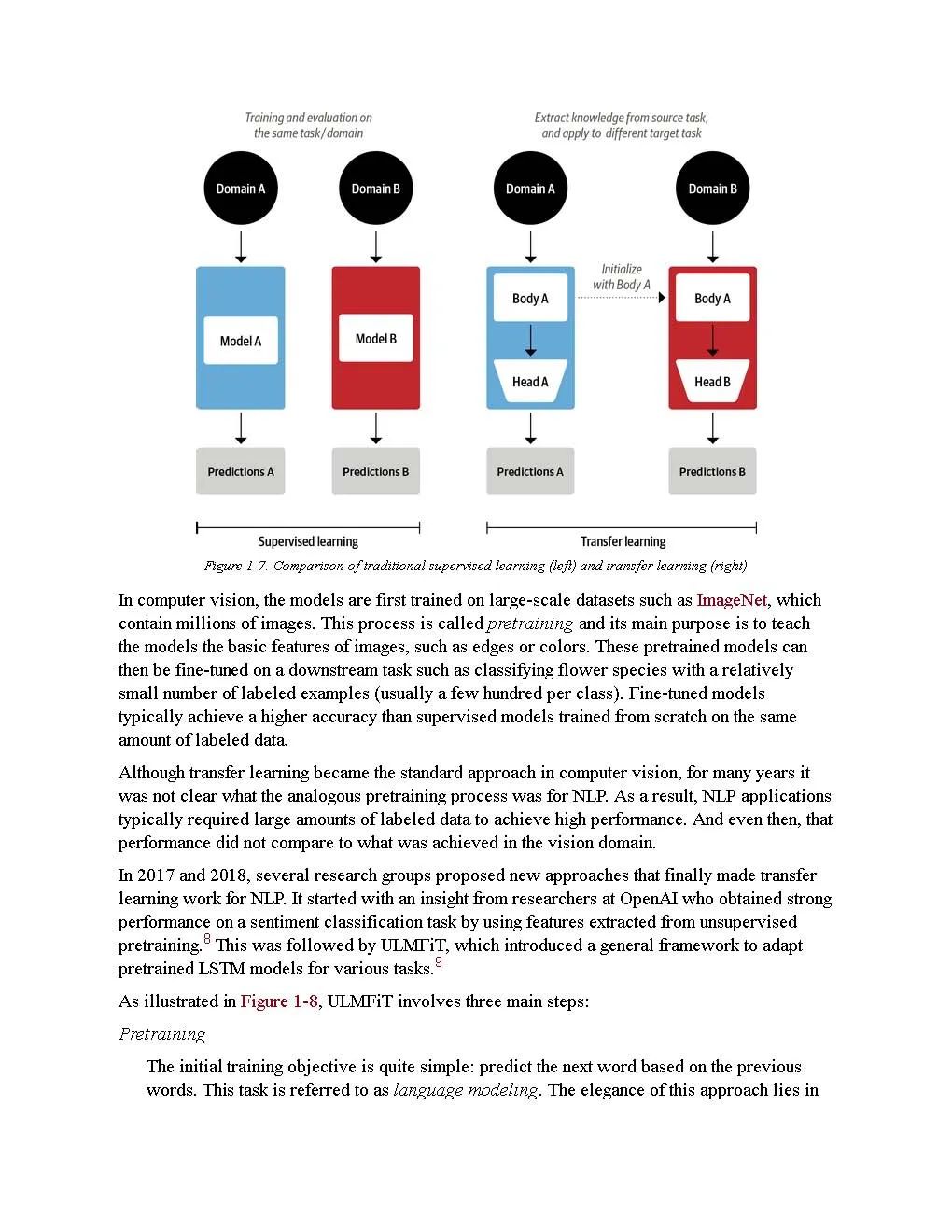
The goal of this book is to empower you to build your own language applications. To achieve this, it focuses on practical use cases and only delves into theory when necessary. The style of this book is hands-on, and we strongly recommend that you run the code examples yourself for experimentation. This book covers all major applications of Transformers in NLP, with each chapter (except for a few exceptions) dedicated to a specific task, combined with a practical use case and dataset. Each chapter also introduces some additional concepts. Here is a high-level overview of the tasks and topics we will cover:
-
Chapter 1, Hello Transformers, introduces Transformers and puts them in context. It also introduces the “Hugging Face” ecosystem.
-
Chapter 2 Text Classification focuses on sentiment analysis (a common text classification problem) and introduces the Trainer API.
-
Chapter 3, Transformer Dissection, provides a deeper understanding of the Transformer architecture, preparing for the subsequent chapters.
-
Chapter 4, Multilingual Named Entity Recognition, focuses on the task of recognizing entities in multilingual text (a token classification problem).
-
Chapter 5, Text Generation, explores the ability of Transformers models to generate text and introduces decoding strategies and metrics.
-
Chapter 6, Summarization, delves into the complex sequence-to-sequence task of text summarization and discusses the metrics used for this task.
-
Chapter 7, Question Answering, focuses on building a review-based question-answering system and introduces methods for retrieval using Haystack.
-
Chapter 8, Efficiently Running Transformers in Production, focuses on model performance. We will look at the task of intent detection (a type of sequence classification problem) and explore techniques such as knowledge distillation, quantization, and pruning.
-
Chapter 9, Handling Few or No Labels, focuses on methods to improve model performance without large amounts of labeled data. We will build a GitHub issue labeling system and explore techniques such as zero-shot classification and data augmentation.
-
Chapter 10, Training Transformers from Scratch, shows you how to build and train a model that autocompletes Python source code from scratch. We will explore data pipeline and large-scale training, and build our own tokenizer.
-
Chapter 11, Future Directions, discusses the challenges faced by Transformers and some exciting new directions for research that will emerge in this field.








Convenient Access to Professional Knowledge
Convenient Download, please followZhuanzhi‘s WeChat public account (click the bluefollow link above)
Reply “TNLP” in the background to getthe download link for《Hugging Face Hardcore Book: Transformer Natural Language Processing》