In recent years, due to the development of deep learning technology, big data, mobile internet, cloud computing, and other fields, artificial intelligence technology has achieved rapid and leapfrog development. As an important area of artificial intelligence technology, intelligent voice interaction technology has gradually matured and become one of the most practical directions, attracting continuous and widespread attention from all sectors of the industry. The development of intelligent voice technology has rapidly advanced in mobile smart terminals, in-car voice interaction, wearable products, and smart home fields, further promoting the development and application of voice interaction technology.
Development of Intelligent Voice
Intelligent voice can achieve language interaction between humans and machines, mainly through key processes such as voice acquisition, speech recognition, natural language understanding, and speech synthesis, to realize a series of actions such as human-machine dialogue, human-machine interaction, and intelligent judgment and decision-making. The rapid application phase of global intelligent voice technology began after 2010, marked by Apple’s release of the intelligent voice assistant Siri, which greatly expanded the user base and audience for intelligent voice.
According to the “2019-2024 China Intelligent Voice Industry Market Prospects and Investment Opportunities Research Report” released by the China Business Industry Research Institute, the global intelligent voice market size is expected to grow from $8 billion in 2018 to $22.7 billion by 2024, with the rapid growth of demand for intelligent voice technology in healthcare, mobile banking, and smart terminals becoming the main driving factors.
1. Intelligent Voice Interaction System
The intelligent voice interaction system allows users to communicate with machines and terminal products through voice and receive feedback, involving key technologies such as speech recognition, natural language understanding, speech synthesis, multi-turn dialogue management, and audio-video integration.
According to application scenarios, consumer-grade intelligent voice interaction systems can be classified into in-car intelligent voice products (OEM and aftermarket), smart home voice interaction (smart speakers, traditional appliances, smart robots), virtual voice assistants (mobile applications), and intelligent voice wearable devices (watches, headphones); according to professional industry application scenarios, intelligent voice interaction systems can be classified into intelligent voice medical products (electronic medical records), intelligent voice education products (oral training and assessment), intelligent voice customer service (call centers, intelligent Q&A, voice quality inspection, corpus mining), etc.
2. Industry Structure
The intelligent voice industry structure is divided into three layers. The upstream basic layer focuses on resources such as server chips, sensors, computing platforms, and big data; the midstream technology layer provides research and services for technologies such as speech recognition, speech synthesis, deep/machine learning, and human-computer interaction; the downstream application layer refers to technology users, including typical applications in various fields such as smart homes, finance, healthcare, and security.
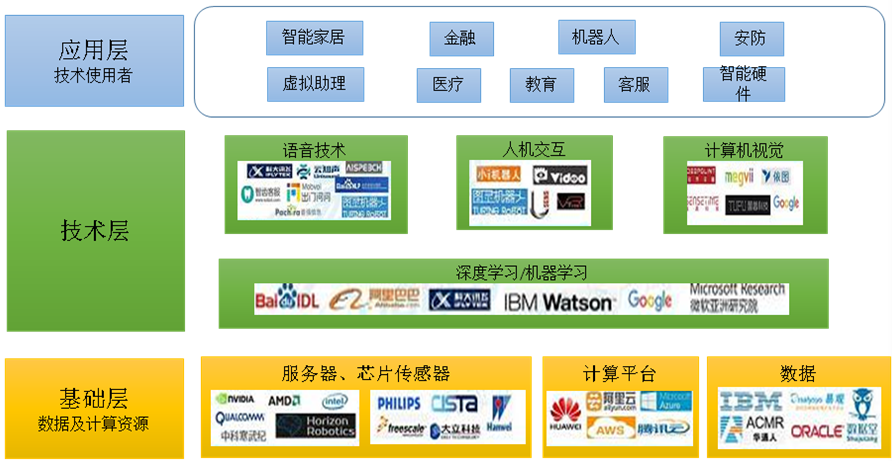
Figure 1 Intelligent Voice Industry Structure
3. Domestic Intelligent Voice Development
In the field of intelligent voice, foreign giants such as Google and Amazon started early, leading in basic algorithms and product innovation, and launched popular voice products like smart speakers, greatly promoting the development, implementation, and market application of voice technology. Domestic tech giants that have emerged alongside new industries can now compete with foreign companies, such as Baidu, which has reached a global leading level in speech recognition, AI operating systems, and deep learning; iFlytek’s intelligent voice technology has continuously won first place in global speech synthesis competitions, achieving accurate translation of Chinese in dialects and colloquialisms.
In terms of domestic policy, in December 2017, the Ministry of Industry and Information Technology released the “Three-Year Action Plan for Promoting the Development of a New Generation of Artificial Intelligence Industry (2018-2020)”, emphasizing breakthroughs in intelligent voice interaction systems, including support for new generation speech recognition frameworks, conversational speech recognition, personalized speech recognition, intelligent dialogue, audio-video integration, and speech synthesis technologies. By 2020, it aimed to achieve an average accuracy rate of 96% for Chinese speech recognition in multiple scenarios and an over 92% recognition rate at a distance of 5 meters, with user dialogue intent recognition accuracy exceeding 90%.
Key Technologies of Voice Interaction
Voice-based human-computer interaction is the main form of current human-computer interaction technology. Combining the human-computer interaction process, its key technologies mainly include: speech recognition, language processing, speech synthesis, logical processing, and content integration.
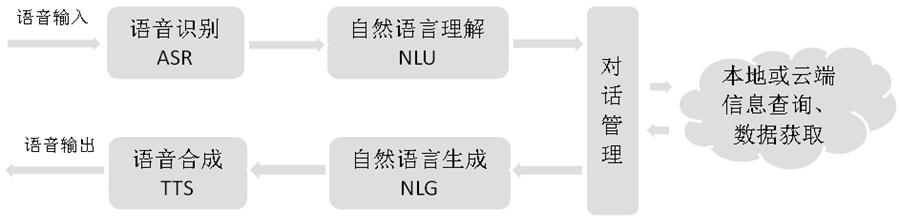
Figure 2 Technical Process of Intelligent Voice Interaction
1. Speech Recognition
Speech recognition refers to the machine reading what a person says, converting speech into text. This process involves extracting features from the training audio and building and training acoustic models and language models based on those features. The specific process is shown in Figure 3:
Before performing speech recognition, to ensure recognition effectiveness, the initial and final segments of the speech can be trimmed to avoid interference with subsequent processing, and the speech is framed. This preprocessing process is generally referred to as VAD (Voice Activity Detection), and subsequent operations for speech recognition are conducted on the effective segments extracted by VAD, thereby reducing the noise misrecognition rate and system power consumption. Each frame’s waveform is transformed into a multidimensional vector that contains the content information of that frame of speech; this process is called acoustic feature extraction, with common methods including Mel-Frequency Cepstral Coefficients (MFCC). Additionally, deep neural network models such as Convolutional Neural Networks (CNN), CNN-LSTM-DNN, etc., have achieved good results in speech feature extraction. The acoustic model converts speech into acoustic representations, outputting the probability of a given speech source corresponding to a certain acoustic symbol.
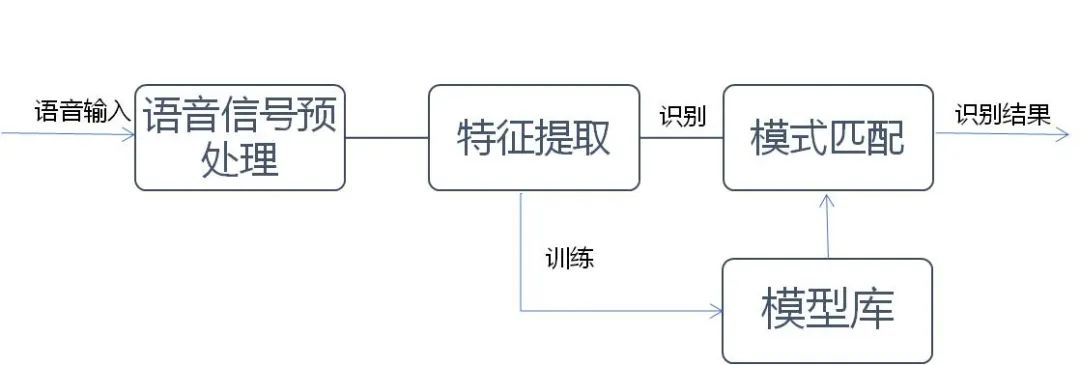
Figure 3 Speech Recognition Process
2. Natural Language Processing
Natural language processing integrates content from linguistics, computer science, mathematics, and other disciplines, and can be divided into natural language understanding, natural language generation, and dialogue management. Language understanding and generation refer to understanding the user’s language input and generating the system’s language output, directly affecting the performance of the dialogue system. Dialogue management acquires input information from language understanding, maintains the system’s internal state during the dialogue process, and generates dialogue strategies based on the state, outputting to language generation. Current natural language processing technology can only achieve relatively shallow human-computer interaction; for more complex communication scenarios, such as multi-turn dialogue, closely related context, logical reasoning, and emotional expression, human-computer interaction still cannot be as smooth and natural as communication between people.
3. Speech Synthesis
The mainstream speech synthesis technology currently refers to TTS (Text-to-Speech), which converts text into speech. The specific implementation process can be divided into front-end text analysis and back-end speech synthesis. Text processing converts text into phoneme sequences, marking the start and end times and frequency changes of each phoneme. There are three common speech synthesis algorithms: (1) Concatenation method, which selects the required basic units from a large amount of pre-recorded speech to splice together; (2) Parameter method, which generates speech feature parameters such as formant frequency and fundamental frequency through statistical models and outputs these parameters in waveform form; (3) HMM model method, which establishes a physical model of the vocal tract and generates waveforms through this physical model.
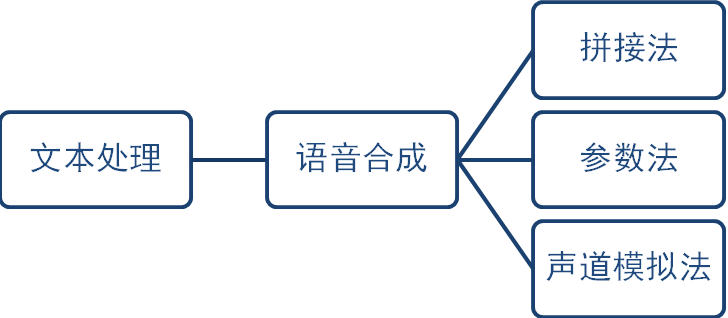
Figure 4 Speech Synthesis Process
4. Speech Database
The speech database is the foundation for the development of key technologies in voice interaction, as all key algorithm optimizations and innovations rely on high-quality speech data for training and testing. Generally, the speech database includes training speech data and testing speech data, where training speech data is used for algorithm construction, parameter tuning, etc., and testing speech data is used to validate recognition effectiveness. The construction of high-quality standard speech databases is a guarantee for the development of intelligent voice. Currently, commonly used public Chinese speech databases are as follows:
(1) Tsinghua University THCHS-30 Chinese Speech Database
The THCHS-30 speech database is an open-source Chinese speech database published by the Speech and Language Technology Center (CSLT) at Tsinghua University. The initial recordings were conducted in 2002 by Professor Zhu Xiaoyan in the Key Laboratory of Intelligent Systems at the Department of Computer Science at Tsinghua University. This database is a classic Chinese speech dataset, containing over 10,000 speech files, approximately 40 hours of Chinese speech data, primarily composed of articles and poems, all recorded by female voices. They hope to provide a toy-level database for new researchers in the field of speech recognition, so the database is completely free for academic users.
(2) Mandarin Chinese Read Speech Corpus
This corpus contains 755 hours of speech data, mainly recorded data from mobile terminals. 1,080 speakers from key regions across China participated in the recordings, with a sentence transcription accuracy exceeding 98%, and the recordings were conducted in quiet indoor environments. The database is divided into training, validation, and testing sets, with a ratio of 51:1:2. Details such as speech data encoding and speaker information are stored in metadata files, and the recording text fields are diverse, including interactive Q&A, music search, SNS information, home command and control, etc. This corpus aims to support researchers in speech recognition, machine translation, speaker identification, and other speech-related fields. Therefore, the corpus is completely free for academic use.
(3) ST-CMDS
The ST-CMDS Chinese speech dataset contains over 100,000 speech files, approximately 100 hours of speech data. The data content mainly consists of daily online voice chat and intelligent voice control sentences, with 855 different speakers, including both male and female voices, suitable for use in various scenarios.
(4) AISHELL Open Source Version
The AISHELL Chinese speech dataset contains approximately 178 hours of open-source data. This dataset includes voices from 400 individuals from different regions of China with various accents. Recordings were conducted in quiet indoor environments using high-fidelity microphones and sampled down to 16kHz. Through professional speech annotations and strict quality checks, the manual transcription accuracy exceeds 95%.
With the research and development of intelligent voice technology, speech databases that meet various needs are continuously being released. Due to China’s vast territory, numerous ethnic groups, and long language history, in addition to standard Mandarin Chinese, there are various regional dialects, accented Mandarin from different regions, and languages from different ethnic groups, creating an urgent demand for speech databases across different dimensions in the industry.
Conclusion
In the field of artificial intelligence, the application of voice interaction technology has penetrated various vertical industries, and an increasing number of smart products equipped with voice interaction systems have emerged in the market, which has raised higher requirements for the voice performance evaluation of these products. Therefore, the technical requirements and evaluation standards for voice technology and products must be improved and implemented as soon as possible.
Currently, various research institutions, standard organizations, and associations in China, such as CCSA, TAF, AIIA, etc., have done a lot of work on AI voice standards, and the relevant standards are relatively complete. However, as new forms of voice products continue to emerge, standard work should start from the actual needs of the industry and market, collaborating with all parties in the industry to research new technologies and products to ensure the feasibility and implementability of standard research work.
Author Introduction
Li Wei, Master of Engineering, Engineer at the Telecommunication Terminal Laboratory of the China Academy of Information and Communications Technology, mainly engaged in voice evaluation research and standard work for intelligent terminal products.
Contact:[email protected]
