Introduction
This article builds a complete Chinese speech recognition system, including acoustic models and language models, capable of recognizing input audio signals as Chinese characters.
The system implements acoustic model and language model modeling in speech recognition based on deep frameworks, where the acoustic models include CNN-CTC, GRU-CTC, CNN-RNN-CTC, and the language models include transformer and CBHG.
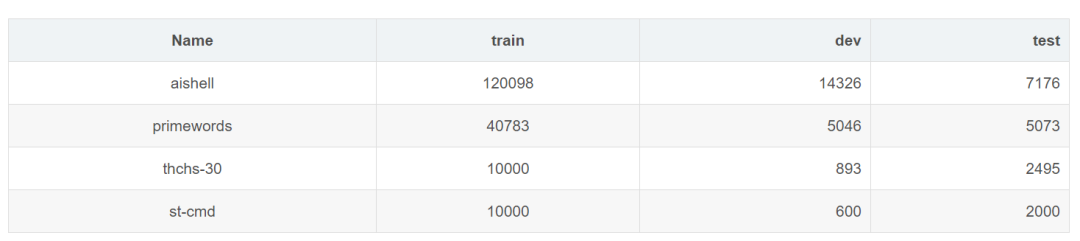
The dataset uses all currently available free Chinese data, including: thchs-30, aishell, primewords, and st-cmd, totaling approximately 450 hours of training data.
https://github.com/audier/DeepSpeechRecognition
To facilitate students to conduct their own experiments, a practical version of the tutorial has been written:
https://blog.csdn.net/chinatelecom08/article/details/85013535
2. Transformer-based Language Model:
https://blog.csdn.net/chinatelecom08/article/details/85051817
3. CBHG-based Language Model:
https://blog.csdn.net/chinatelecom08/article/details/85048019
Acoustic Model
Some example models of the acoustic model are currently open-sourced, and more models will be updated irregularly in the future.
1.1 GRU-CTC
We built the first acoustic model using the GRU-CTC structure, which is located in the project’s gru_ctc.py file. By utilizing recurrent neural networks, it can leverage context-related information in speech to obtain more accurate information, while GRU can selectively retain necessary long-term information, and using bidirectional RNN can fully utilize contextual signals.
However, the drawback of this method is that recognition can only occur after a sentence is completed, and training is relatively slower than CNN. This model is built using python/keras, and the entire system uses python.
The network structure is as follows:
def _model_init(self): self.inputs = Input(name='the_inputs', shape=(None, 200, 1)) x = Reshape((-1, 200))(self.inputs) x = dense(512, x) x = dense(512, x) x = bi_gru(512, x) x = bi_gru(512, x) x = bi_gru(512, x) x = dense(512, x) self.outputs = dense(self.vocab_size, x, activation='softmax') self.model = Model(inputs=self.inputs, outputs=self.outputs) self.model.summary()
1.2 DFCNN
We encounter issues when using GRU for speech recognition for two reasons.
On one hand, we often need to use bidirectional recurrent neural networks to achieve better recognition results, which can affect decoding real-time performance.
On the other hand, as the complexity of the network structure increases, the parameters of the bidirectional GRU are six times that of the fully connected layer with the same number of nodes, which can lead to very slow training speeds.
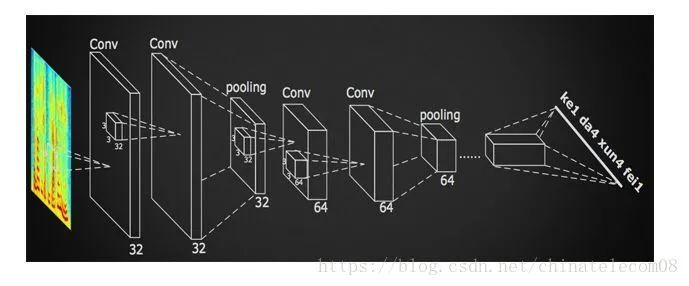
iFlytek proposed a method using deep convolutional neural networks to recognize spectrograms, known as DFCNN. The paper can be found at (see reference a at the end).
By utilizing the parameter sharing mechanism of CNN, the number of parameters can be reduced by several orders of magnitude, and the deep convolutional and pooling layers can fully consider the contextual information of speech signals, allowing for recognition results to be obtained in a shorter time, thus achieving better real-time performance.
This model is located in cnn_ctc.py and is currently the best performing model in experiments, capable of achieving good generalization ability. Its network structure is as follows:
def cnn_cell(size, x, pool=True): x = norm(conv2d(size)(x)) x = norm(conv2d(size)(x)) if pool: x = maxpool(x) return x
class Am(): def _model_init(self): self.inputs = Input(name='the_inputs', shape=(None, 200, 1)) self.h1 = cnn_cell(32, self.inputs) self.h2 = cnn_cell(64, self.h1) self.h3 = cnn_cell(128, self.h2) self.h4 = cnn_cell(128, self.h3, pool=False) self.h5 = cnn_cell(128, self.h4, pool=False) # 200 / 8 * 128 = 3200 self.h6 = Reshape((-1, 3200))(self.h5) self.h7 = dense(256)(self.h6) self.outputs = dense(self.vocab_size, activation='softmax')(self.h7) self.model = Model(inputs=self.inputs, outputs=self.outputs) self.model.summary()
1.3 DFSMN
Feedforward Memory Neural Networks also solve the problems of excessive parameters and poor real-time performance of bidirectional GRU. It utilizes a memory module that contains contextual information from several frames, achieving recognition results comparable to those of bidirectional GRU-CTC. The latest open-source system from Alibaba is based on the DFSMN acoustic model, implemented within the Kaldi framework.
We will consider implementing the DFSMN+CTC structure in Python. Essentially, this network can achieve the same effect using a special CNN. We will set the width of the CNN to the memory size, the height to the feature dimension, and the channel to the hidden units, allowing a single CNN layer to mimic the implementation of FSMN.
The structure is as follows: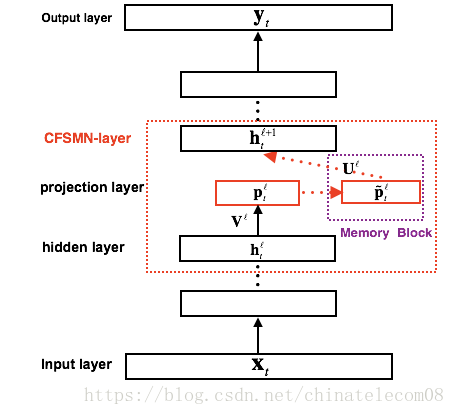
Language Model
2.1 n-gram
The n-gram model is a very classic language model, and I won’t elaborate on it here. If you want to train an n-gram model using a corpus, you can refer to my small experiment’s implementation method.
2.2 CBHG
This idea comes from a project by a genius working on input methods. The following part also references this: the SouMiao input method utilizes this model to establish a mapping from keystrokes to Chinese characters. This article makes slight modifications to its structure and data processing parts to serve as a language model.
Pinyin input is essentially a sequence-to-sequence model: inputting a sequence of pinyin, outputting a sequence of Chinese characters. Therefore, it is naturally suitable for use in sequence-to-sequence models like machine translation.
The initial input to the model is a randomly sampled character embedding of pinyin letters, processed through a CBHG model, and the output corresponds to labels for five thousand Chinese characters.
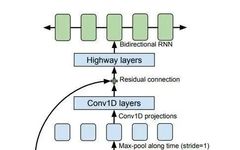
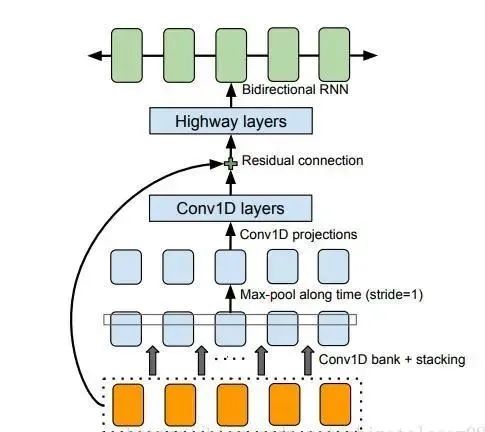
The CBHG module used here is a state-of-the-art seq2seq model, applied in Google’s machine translation and speech synthesis. The structure of this model is placed in cbhg.py as follows:
(Image source: Tacotron: Towards End-to-End Speech Synthesis)
The training experimental results of this model are as follows. In fact, in subsequent comparisons with transformer, this model is difficult to compete with transformer in terms of both convergence speed and recognition performance.
Please input test pinyin: ta1 mei2 you3 duo1 shao3 hao2 yan2 zhuang4 yu3 dan4 ta1 que4 ba3 ai4 qin1 ren2 ai4 jia1 ting2 ai4 zu3 guo2 ai4 jun1 dui4 wan2 mei3 de tong3 yi1 le qi3 lai2她没有多少豪言壮语但她却把爱亲人爱家庭爱祖国爱军队完美地统一了起来
Please input test pinyin: chu2 cai2 zheng4 bo1 gei3 liang3 qian1 san1 bai3 wan4 yuan2 jiao4 yu4 zi1 jin1 wai4 hai2 bo1 chu1 zhuan1 kuan3 si4 qian1 wu3 bai3 qi1 shi2 wan4 yuan2 xin1 jian4 zhong1 xiao3 xue2除财政拨给两千三百万元教太资金外还拨出专款四千五百七十万元新建中小学
Please input test pinyin: ke3 shi4 chang2 chang2 you3 ren2 gao4 su4 yao2 xian1 sheng1 shuo1 kan4 jian4 er4 xiao3 jie3 zai4 ka1 fei1 guan3 li3 he2 wang2 jun4 ye4 wo4 zhe shou3 yi1 zuo4 zuo4 shang4 ji3 ge4 zhong1 tou2可是常常有人告诉姚先生说看见二小姐在咖啡馆里和王俊业握着族一坐坐上几个钟头
2.3 transformer
A new language model based on the transformer structure has been added, which has been proven to have stronger language expression capabilities than other frameworks.The paper can be found at (see reference b at the end).
It is recommended to use transformer as the language model. This model is the hottest model in natural language processing over the past two years, and this year’s BERT is based on this structure.The language model used in this system has recently been updated to transformer.
the 0 th example. Text result: lv4 shi4 yang2 chun1 yan1 jing3 da4 kuai4 wen2 zhang1 de di3 se4 si4 yue4 de lin2 luan2 geng4 shi4 lv4 de2 xian1 huo2 xiu4 mei4 shi1 yi4 ang4 ran2 Original result: lv4 shi4 yang2 chun1 yan1 jing3 da4 kuai4 wen2 zhang1 de di3 se4 si4 yue4 de lin2 luan2 geng4 shi4 lv4 de2 xian1 huo2 xiu4 mei4 shi1 yi4 ang4 ran2 Original Chinese characters: 绿是阳春烟景大块文章的底色四月的林峦更是绿得鲜活秀媚诗意盎然 Recognition result: 绿是阳春烟景大块文章的底色四月的林峦更是绿得鲜活秀媚诗意盎然
the 1 th example. Text result: ta1 jin3 ping2 yao1 bu4 de li4 liang4 zai4 yong3 dao4 shang4 xia4 fan1 teng2 yong3 dong4 she2 xing2 zhuang4 ru2 hai3 tun2 yi4 zhi2 yi3 yi1 tou2 de you1 shi4 ling3 xian1 Original result: ta1 jin3 ping2 yao1 bu4 de li4 liang4 zai4 yong3 dao4 shang4 xia4 fan1 teng2 yong3 dong4 she2 xing2 zhuang4 ru2 hai3 tun2 yi4 zhi2 yi3 yi1 tou2 de you1 shi4 ling3 xian1 Original Chinese characters: 他仅凭腰部的力量在泳道上下翻腾蛹动蛇行状如海豚一直以一头的优势领先 Recognition result: 他仅凭腰部的力量在泳道上下翻腾蛹动蛇行状如海豚一直以一头的优势领先
the 2 th example. Text result: pao4 yan3 da3 hao3 le zha4 yao4 zen3 me zhuang1 yue4 zheng4 cai2 yao3 le yao3 ya2 shu1 di4 tuo1 qu4 yi1 fu2 guang1 bang3 zi chong1 jin4 le shui3 cuan4 dong4 Original result: pao4 yan3 da3 hao3 le zha4 yao4 zen3 me zhuang1 yue4 zheng4 cai2 yao3 le yao3 ya2 shu1 di4 tuo1 qu4 yi1 fu2 guang1 bang3 zi chong1 jin4 le shui3 cuan4 dong4 Original Chinese characters: 炮眼打好了炸药怎么装岳正才咬了咬牙倏地脱去衣服光膀子冲进了水窜洞 Recognition result: 炮眼打好了炸药怎么装岳正才咬了咬牙倏地脱去衣服光膀子冲进了水窜洞
Dataset
The dataset uses all currently available free Chinese data, including:thchs-30, aishell, primewords, st-cmd four datasets, totaling approximately 450 hours of training data. In previous experiments, thethchs-30+aishell+st-cmd dataset was used to train the DFCNN acoustic model with a batch size of 64.
Including stc, primewords, Aishell, thchs30, a total of about 430 hours.
http://www.openslr.org/resources.php
The data labels are organized in the data path, where primewords and st-cmd have not yet been separated into training and testing sets.If you need to use all datasets, simply unzip them to a unified path and then set the datapath in utils.py accordingly.
This project has now trained a mini speech recognition system. Download the project locally, download the thchs dataset and unzip it to the data folder, run test.py, and it should recognize without issues. The results are as follows:
the 0 th example. Text result: lv4 shi4 yang2 chun1 yan1 jing3 da4 kuai4 wen2 zhang1 de di3 se4 si4 yue4 de lin2 luan2 geng4 shi4 lv4 de2 xian1 huo2 xiu4 mei4 shi1 yi4 ang4 ran2 Original result: lv4 shi4 yang2 chun1 yan1 jing3 da4 kuai4 wen2 zhang1 de di3 se4 si4 yue4 de lin2 luan2 geng4 shi4 lv4 de2 xian1 huo2 xiu4 mei4 shi1 yi4 ang4 ran2 Original Chinese characters: 绿是阳春烟景大块文章的底色四月的林峦更是绿得鲜活秀媚诗意盎然 Recognition result: 绿是阳春烟景大块文章的底色四月的林峦更是绿得鲜活秀媚诗意盎然
If you build your own model, you need to delete the existing model and reconfigure the parameters for training.
Data-related parameters are in utils.py:
▪ data_type: train, test, dev
▪ data_path: path corresponding to the unzipped data
▪ thchs30, aishell, prime, stcmd: whether to use this dataset
▪ data_length: I made it smaller for testing effects, normally set it to None
▪ shuffle: set to True for normal training, whether to shuffle the training order
def data_hparams(): params = tf.contrib.training.HParams( # vocab data_type = 'train', data_path = 'data/', thchs30 = True, aishell = True, prime = False, stcmd = False, batch_size = 1, data_length = None, shuffle = False) return params
Use train.py to train the model.
The acoustic model can be chosen between cnn-ctc and gru-ctc, just modify the import path:
from model_speech.cnn_ctc import Am, am_hparamsfrom model_speech.gru_ctc import Am, am_hparams
The language model can be chosen between transformer and cbhg:
from model_language.transformer import Lm, lm_hparamsfrom model_language.cbhg import Lm, lm_hparams
Paper address【a】
http://xueshu.baidu.com/usercenter/paper/show?paperid=be5348048dd263aced0f2bdc75a535e8&site=xueshu_se
https://arxiv.org/abs/1706.03762
Source
https://blog.csdn.net/chinatelecom08/article/details/82557715
Add Customer Service『Yezi』』
Receive a collection of speech recognition papers