
Click the image above to easily learn electronic knowledge by following “Chuangxue Electronics”.
Speech recognition is a high-tech that enables machines to automatically recognize and understand human spoken language through speech signal processing and pattern recognition. It is a cross-disciplinary field closely related to acoustics, phonetics, linguistics, information theory, pattern recognition theory, and neurobiology. Speech recognition technology is gradually becoming a key technology in computer information processing, and its applications have emerged as a competitive new high-tech industry.
1. Basic Principles of Speech Recognition
The speech recognition system is essentially a pattern recognition system consisting of three basic units: feature extraction, pattern matching, and reference pattern library. Its basic structure is shown in the figure below: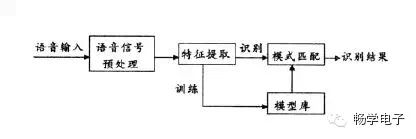
Unknown speech is converted into an electrical signal by a microphone and fed into the recognition system. It first undergoes preprocessing, and then a speech model is established based on human speech characteristics. The input speech signal is analyzed, and the required features are extracted, on the basis of which templates for speech recognition are created. During the recognition process, the computer compares the stored speech templates with the features of the input speech signal according to certain search and matching strategies to find a series of optimal templates that match the input speech. The recognition result can then be obtained through table lookup based on the definition of this template. Clearly, the optimal result is directly related to the choice of features, the quality of the speech model, and the accuracy of the templates.
2. Development History and Current Status of Speech Recognition Technology
In 1952, Davis and others at AT&T Bell Labs developed the first speech enhancement system for ten English digits, known as the Audry system. In 1956, Olson and Belar at RCA Labs of Princeton University developed a system capable of recognizing ten monosyllabic words, using spectral parameters obtained from bandpass filter groups as speech enhancement features. In 1959, Fry and Denes attempted to build a phoneme recognizer for 4 vowels and 9 consonants, using spectral analysis and pattern matching for decision-making. This greatly improved the efficiency and accuracy of speech recognition, drawing attention from researchers worldwide. In the 1960s, Matin and others in the Soviet Union proposed endpoint detection for speech, significantly raising the level of speech recognition; Vintsyuk introduced dynamic programming, which became indispensable in later recognition processes. Important achievements in the late 1960s and early 1970s included the introduction of Linear Predictive Coding (LPC) technology and Dynamic Time Warping (DTW) technology, which effectively solved the problems of feature extraction and matching of speech signals of unequal lengths. Additionally, Vector Quantization (VQ) and Hidden Markov Model (HMM) theories were proposed. The combination of speech recognition technology and speech synthesis technology allows users to move away from keyboard constraints, replacing them with a more user-friendly and natural speech input method, which is gradually becoming a key technology in human-computer interfaces in information technology.
3. Methods of Speech Recognition
Currently, representative speech recognition methods mainly include Dynamic Time Warping (DTW), Hidden Markov Models (HMM), Vector Quantization (VQ), Artificial Neural Networks (ANN), and Support Vector Machines (SVM).
Dynamic Time Warping (DTW) is a simple and effective method for non-specific speaker speech recognition. This algorithm, based on dynamic programming principles, addresses the problem of template matching for varying pronunciation lengths, making it one of the earliest and most commonly used algorithms in speech recognition technology. When applying the DTW algorithm for speech recognition, the preprocessed and framed speech test signal is compared with reference speech templates to obtain their similarity, yielding the best path based on a certain distance measure.
Hidden Markov Model (HMM) is a statistical model in speech signal processing that is derived from Markov chains, thus it is a parameter-based statistical recognition method. Its pattern library is formed through repeated training to achieve the best model parameters that match the training output signal probabilities, rather than relying on pre-stored pattern samples. During recognition, it uses the likelihood probabilities between the speech sequence to be recognized and the HMM parameters to identify the best state sequence corresponding to the maximum likelihood as the recognition output, making it an ideal speech recognition model.
Vector Quantization (VQ) is an important signal compression method. Compared to HMM, vector quantization is mainly suitable for small vocabulary isolated word speech recognition. The process involves forming a vector from several scalar data of speech signal waveforms or feature parameters for overall quantization in multi-dimensional space. The vector space is divided into several small regions, and a representative vector is sought for each small region. During quantization, vectors falling into the small region are replaced by the representative vector. The design of the vector quantizer involves training a good codebook from a large number of signal samples, seeking a good definition formula for distortion measures based on practical effects, and designing the best vector quantization system to achieve maximum possible average signal-to-noise ratio with minimal search and computation of distortion calculations.
In practical applications, various methods to reduce complexity have been studied, including memory-less vector quantization, memory vector quantization, and fuzzy vector quantization methods.
Artificial Neural Networks (ANN) is a new speech recognition method proposed in the late 1980s. It is essentially an adaptive nonlinear dynamic system that simulates human neural activities, possessing adaptability, parallelism, robustness, fault tolerance, and learning characteristics. Its powerful classification ability and input-output mapping capability are very appealing in speech recognition. The method simulates the engineering model of human brain thinking mechanisms, contrasting with HMM; its classification decision-making ability and capability to describe uncertain information are globally recognized. However, its ability to describe dynamic time signals is still lacking; typically, MLP classifiers can only solve static pattern classification problems, not involving time series processing. Although many scholars have proposed feedback structures, they still fall short of capturing the dynamic characteristics of time series signals like speech. Due to ANN’s inability to effectively describe the dynamic characteristics of speech signals, it is often combined with traditional recognition methods to leverage their respective advantages for speech recognition, overcoming the shortcomings of both HMM and ANN. In recent years, significant progress has been made in recognition algorithms combining neural networks and hidden Markov models, with recognition rates approaching those of HMM systems, further enhancing the robustness and accuracy of speech recognition.
Support Vector Machine (SVM) is a new learning model based on statistical theory that employs the principle of Structural Risk Minimization (SRM) to effectively overcome the shortcomings of traditional empirical risk minimization methods. It balances training error and generalization ability, demonstrating superior performance in solving small sample, non-linear, and high-dimensional pattern recognition problems, and has been widely applied in the field of pattern recognition.
4. Classification of Speech Recognition Systems
Speech recognition systems can be classified based on the constraints on input speech. From the perspective of the relationship between the speaker and the recognition system, they can be divided into three categories: (1) Specific speaker speech recognition systems, which only consider recognizing speech from specific individuals. (2) Non-specific speaker speech systems, where the recognized speech is independent of the speaker, typically requiring a large database of different speakers’ voices to train the recognition system. (3) Multi-speaker recognition systems, which can recognize speech from a group of individuals, or can be referred to as specific group speech recognition systems, which only require training on the speech of that specific group.
From the perspective of speaking style, recognition systems can also be divided into three categories: (1) Isolated word speech recognition systems, which require a pause after each word input. (2) Connected word speech recognition systems, which require clear pronunciation of each word, with some connected speech phenomena beginning to appear. (3) Continuous speech recognition systems, which accept natural fluent continuous speech input, with a large amount of connected speech and sound changes.
From the perspective of vocabulary size, recognition systems can also be classified into three categories: (1) Small vocabulary speech recognition systems, usually including tens of words. (2) Medium vocabulary speech recognition systems, usually including hundreds to thousands of words. (3) Large vocabulary speech recognition systems, usually including thousands to tens of thousands of words. With the improvement of computing and digital signal processing capabilities, as well as the accuracy of recognition systems, the classification of recognition systems based on vocabulary size has also been changing. Currently, medium vocabulary recognition systems are prevalent, and in the future, small vocabulary speech recognition systems may become common. These various constraints also determine the difficulty level of speech recognition systems.
5. Applications of Speech Recognition
The fields where speech recognition can be applied can be broadly divided into five categories:
Office or business systems. Typical applications include filling data forms, database management and control, enhancing keyboard functions, etc.
Manufacturing: In quality control, speech recognition systems can provide a “hands-free” and “eyes-free” inspection method for manufacturing processes (component inspection).
Telecommunications: A wide range of applications are feasible in dial-up telephone systems, including automation of operator-assisted services, remote e-commerce, voice call distribution, voice dialing, and order classification.
Medical: The main application in this field is generating and editing professional medical reports via voice.
Others: Including games and toys controlled by voice, speech recognition systems to assist disabled individuals, and voice control for non-critical functions while driving, such as in-vehicle traffic condition control systems and audio systems.
6. Latest Developments in Speech Recognition Systems
Today, speech recognition technology, especially for medium and small vocabulary non-specific speaker recognition systems, has achieved an accuracy greater than 98%, with even higher accuracy for specific speaker systems. These technologies can meet the requirements of typical applications. With the advancement of large-scale integrated circuit technology, these complex speech recognition systems can now be produced as dedicated chips for mass production. In economically developed Western countries, a large number of speech recognition products have entered the market and service sectors. Some user exchanges, telephones, and mobile phones now include voice dialing functions, voice notepads, voice intelligent toys, and also incorporate both speech recognition and synthesis functions. People can query relevant flight, travel, and banking information through spoken dialogue systems over telephone networks. Surveys indicate that more than 85% of users express satisfaction with the performance of speech recognition information query service systems. It can be predicted that in the next five years, the application of speech recognition systems will become even more widespread, with various speech recognition system products continuously appearing on the market. The role of speech recognition technology in automated mail sorting is also becoming increasingly apparent, presenting a promising development outlook. Postal departments in some developed countries have already adopted this system, and speech recognition technology is gradually becoming a new technology for mail sorting. It can overcome the limitations of manual sorting that relies solely on the sorter’s memory, addressing the issue of high personnel costs and improving the efficiency and effectiveness of mail processing. In the field of education, the most direct application of speech recognition technology is to help users better practice language skills.
Another branch of development in speech recognition technology is telephone speech recognition technology, with Bell Labs being a pioneer in this field. Telephone speech recognition technology will enable telephone queries, automatic call connections, and operations for specialized services like travel information. After banks adopted voice understanding technology for their inquiry systems, they can provide 24-hour telephone banking services to customers without interruption. In the securities industry, if telephone speech recognition inquiry systems are used, users can directly state the stock name or code to query market conditions, and the system will automatically read out the latest stock prices upon confirming the user’s request, greatly facilitating the user experience. Currently, there are still many manual services at directory assistance, but with the adoption of speech technology, computers can automatically respond to user needs and playback queried phone numbers, thereby saving human resources.
> > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > >