
Voice recognition technology is not a new technology, and the technical threshold is not too high. In the demand-driven smart home market, can voice recognition replace smartphones as another major entry point? Which vendors worldwide are laying out voice recognition technology, and what are the technical principles and challenges of voice recognition?
The Internet of Things (IoT) market has enormous potential with numerous applications, among which smart homes may take the lead. However, besides the obstacles of IoT standards and concepts hindering the development of smart homes, the smartphone as the primary entry point significantly affects the experience. Voice recognition is not a new technology, but it could shine in the smart home and even artificial intelligence fields.
The Potential of the IoT and Smart Home Market is Promising
Market research consulting firm Gartner predicts that by 2020, the global shipment of IoT devices will reach 6.6 billion, with the total number of IoT devices reaching 20.8 billion, and total spending on IoT will reach approximately $242 billion.
Gartner also predicts that after 2017, smart homes will become the largest user of IoT. Some institutions predict that the growth rate of China’s smart home market will reach 50.1% in 2016 and maintain this growth rate, with the market size reaching 139.6 billion yuan by 2018, accounting for about 32% of the global total. By 2020, China’s smart home market size will exceed 300 billion yuan. Among the top 100 telecom operators globally, 60% plan to enter the smart home market, giving us reason to believe that smart homes will be the first IoT application to land.

Single Entry Point for Smart Homes
Whether in formal or informal settings, complaints about smartphones being the only entry point for smart homes are common. For example, when you have installed smart lighting but want to turn it on or adjust it, you first need to find your phone and open the app. At this moment, many people may choose to use the switch to solve the problem instead of using their phones.
The vision for smart homes is excellent, but the current experience indeed has a lot of room for improvement. Regarding the issue of smartphones as the only entry point for smart homes, Phillip Zhang Nanxiong, co-founder and president of Aira IoT, stated, “Smartphones may not be the only entry point for smart homes or even IoT; voice recognition is a significant entry point.” Li Qiang, general manager of Midea Smart, also stated that the situation of smartphones being the only entry point for smart homes will change.
Voice Recognition Becomes the Focus of Competition
It is reported that many AI companies globally focus on deep learning, while over 70% of about 200 AI startups in China focus on image or voice recognition. Which companies worldwide are laying out voice recognition? What is their development status?
In fact, even before the invention of computers, the concept of automatic speech recognition was already on the agenda. Early vocoders can be seen as the prototype of speech recognition and synthesis. The first speech recognition system based on electronic computers was developed by AT&T Bell Labs, known as the Audrey speech recognition system, which could recognize ten English digits. By the late 1950s, Denes from the College of London had already incorporated probabilistic grammar into speech recognition.
In the 1960s, artificial neural networks were introduced into speech recognition. The two major breakthroughs of this era were Linear Predictive Coding (LPC) and Dynamic Time Warping (DTW) technology. The most significant breakthrough in speech recognition technology was the application of the Hidden Markov Model (HMM). Following Baum’s relevant mathematical reasoning, through the research of Rabiner and others, Kai-Fu Lee from Carnegie Mellon University ultimately realized the first large vocabulary speech recognition system based on HMM, Sphinx.

Apple Siri
Many people may owe their recognition of voice recognition to Apple’s renowned voice assistant, Siri. In 2011, Apple integrated voice recognition technology into the iPhone 4S and released the Siri voice assistant, but Siri was not a technology developed by Apple but rather acquired from Siri Inc., founded in 2007. After the release of the iPhone 4S, the experience with Siri was not ideal and faced criticism. Therefore, in 2013, Apple acquired Novauris Technologies. Novauris is a voice recognition technology capable of recognizing entire phrases, not just individual words, attempting to utilize over 245 million phrases to assist in understanding context, further enhancing Siri’s functionality.
However, Siri did not become perfect after acquiring Novauris. In 2016, Apple acquired VocalIQ, a UK startup that developed AI software capable of helping computers engage in more natural conversations with users. Subsequently, Apple also acquired Emotient, an AI technology company in San Diego, USA, to receive its facial expression analysis and emotion recognition technology. It is reported that the emotion engine developed by Emotient can read people’s facial expressions and predict their emotional states.
Google Google Now
Similar to Apple’s Siri, Google’s Google Now is also well-known. However, compared to Apple, Google’s actions in the voice recognition field were somewhat slower. In 2011, Google acquired the voice communication company SayNow and the voice synthesis company Phonetic Arts. SayNow can integrate voice communication, peer-to-peer conversations, and group calls with applications like Facebook, Twitter, MySpace, Android, and iPhone, while Phonetic Arts can convert recorded voice conversations into a voice library, then combine these sounds to generate very realistic human voice conversations.
Google Now made its debut at the 2012 Google I/O developer conference.

In 2013, Google also acquired the news reading application developer Wavii for over $30 million. Wavii specializes in “natural language processing” technology, capable of scanning the internet for news and directly providing a one-sentence summary and link. Subsequently, Google acquired multiple voice recognition-related patents from SR Tech Group, which were quickly applied to the market, such as YouTube providing automatic voice transcription support, Google Glass using voice control technology, and Android integrating voice recognition technology, among others, with Google Now boasting a complete voice recognition engine.
Google may have invested in China’s Outgoing Question due to strategic considerations. This is a company focused on voice navigation that recently released a smartwatch and has the backing of the well-known domestic acoustic component manufacturer GoerTek.
Microsoft Cortana and Xiaobing
Microsoft’s most eye-catching voice recognition initiatives are Cortana and Xiaobing. Cortana is Microsoft’s attempt in machine learning and AI, capable of recording user behaviors and habits, utilizing cloud computing, search engines, and “unstructured data” analysis to read and learn from data including images, videos, emails, etc., to understand user semantics and context, thereby achieving human-computer interaction.

Microsoft’s Xiaobing is an AI robot released by Microsoft Research Asia in 2014. In addition to intelligent conversation, Xiaobing also has practical skills such as group reminders, encyclopedia, weather, zodiac, jokes, traffic guides, and restaurant reviews.
In addition to Cortana and Xiaobing, Skype Translator can provide real-time translation services for users of English, Spanish, Chinese, and Italian.
Amazon
Amazon’s voice technology began in 2011 with the acquisition of voice recognition company Yap, which was founded in 2006 and primarily provided voice-to-text services. In 2012, Amazon acquired voice technology company Evi to further strengthen the application of voice recognition in product searches. Evi had also used Nuance’s voice recognition technology. In 2013, Amazon continued to acquire Ivona Software, a Polish company specializing in text-to-speech conversion; its technology has been applied in Kindle Fire’s text-to-speech conversion function, voice commands, and Explore by Touch applications. Amazon’s smart speaker, Echo, also utilizes this technology.

In 2013, Facebook acquired the startup voice recognition company Mobile Technologies, whose product Jibbigo allows users to choose from 25 languages, recording voice segments in one language or inputting text, then displaying the translation on the screen while reading it aloud based on the selected language. This technology made Jibbigo a commonly used tool for traveling abroad, effectively replacing common phrase manuals.
Afterward, Facebook continued to acquire voice interaction solution provider Wit.ai. Wit.ai’s solutions allow users to control mobile applications, wearable devices, and robots, as well as almost any smart device directly through voice. Facebook hopes to apply this technology to targeted advertising, closely integrating technology with its business model.
The Traditional Voice Recognition Industry Aristocrat Nuance
Besides the well-known tech giants’ developments in voice recognition, the traditional voice recognition industry aristocrat Nuance is also worth noting. Nuance once dominated the voice field, with over 80% of voice recognition using Nuance’s recognition engine technology. Its voice products support over 50 languages and have over 2 billion users globally, almost monopolizing the financial and telecommunications industries. Today, Nuance remains the largest voice technology company globally, holding the most voice technology patents. Apple’s voice assistant Siri, Samsung’s voice assistant S-Voice, and the automatic call centers of major airlines and top banks initially adopted their voice recognition engine technology.
However, due to Nuance’s overconfidence, it is not as dominant as it once was.
Other Foreign Voice Recognition Companies
In 2013, Intel acquired the Spanish voice recognition technology company Indisys, while Yahoo acquired the natural language processing technology startup SkyPhrase in the same year. The largest cable company in the United States, Comcast, also began launching its own voice recognition interaction system, hoping to allow users to control the television more freely through voice and accomplish tasks that remote controls cannot.
Domestic Voice Recognition Vendors
iFlytek
iFlytek was established at the end of 1999, relying on the speech processing technology of the University of Science and Technology of China and strong national support, quickly getting on track. iFlytek went public in 2008, with a market value close to 50 billion yuan. According to data from the Voice Industry Alliance in 2014, iFlytek held over 60% of the market share, making it the leading domestic company in voice technology.

When mentioning iFlytek, people might think of voice recognition, but its largest revenue source actually comes from education, especially around 2013 when it acquired many voice assessment companies, including Qiming Technology, monopolizing the education market. After a series of acquisitions, the oral assessment engines used in all provinces are iFlytek’s, and due to its dominance in exams, all schools and parents are willing to pay for it.
Baidu Voice

Baidu Voice was established as a strategic direction early on, collaborating with the Institute of Acoustics of the Chinese Academy of Sciences to develop voice recognition technology in 2010, but market development was relatively slow. It wasn’t until 2014 that Baidu restructured its strategy, hiring AI master Andrew Ng, formally establishing a voice team dedicated to researching voice-related technologies. With Baidu’s strong financial support, it has since achieved significant results, capturing nearly 13% of the market share, and its technical strength can now be compared with iFlytek, which has over a decade of technological and experiential accumulation.
Jietong and Xinli
Jietong Huasheng relies on Tsinghua technology, and in its early stages, it invited Mr. Lü Shinan from the Institute of Acoustics of the Chinese Academy of Sciences to join, establishing the foundation for voice synthesis. Zhongke Xinli is entirely based on the Institute of Acoustics of the Chinese Academy of Sciences, with strong technical capabilities in its early stages, not only cultivating a large number of talents for the domestic voice recognition industry but also playing a crucial role in the industry, especially in the military sector.
The talents cultivated by the Institute of Acoustics of the Chinese Academy of Sciences are vital for the development of the domestic voice recognition industry. However, relative to the market, these two companies have fallen far behind iFlytek. Due to its industry market background, Zhongke Xinli has basically ceased market operations, while Jietong Huasheng has recently faced negative impacts due to the “Jiao Jiao” robot fraud incident from Nanjing University of Posts and Telecommunications.
iFlytek

Around 2009, DNN was applied in the field of voice recognition, significantly improving recognition rates, breaking through 90% and reaching commercial standards. This greatly promoted the development of the voice recognition field, leading to the establishment of many voice recognition-related startups in recent years.
iFlytek was founded in 2007, with most of its founders coming from the Cambridge team, and its technology has a certain foreign foundation. At that time, the company mainly focused on voice assessment, which is education, but after years of development, while it holds some market share, it is challenging to make breakthroughs under iFlytek’s dominance in the exam sector.
In 2014, iFlytek decided to spin off its education sector, selling it for 90 million to NetDragon, while focusing on smart hardware and mobile internet. Recently, it has concentrated on car voice assistants, launching “Luo Bo,” but market response has been mediocre.
Yunzhisheng
Taking advantage of the publicity momentum of Apple’s Siri in 2011, Yunzhisheng was founded in 2012. The Yunzhisheng team mainly comes from the Shengda Research Institute, and coincidentally, the CEO and CTO are also graduates of the University of Science and Technology of China, making them somewhat like brothers with iFlytek. However, its voice recognition technology largely originates from the Institute of Automation of the Chinese Academy of Sciences, with some unique advantages. For a brief period, its voice recognition rate even surpassed that of iFlytek. Hence, it received significant capital attention, with Series B financing reaching 300 million, primarily targeting the smart home market. However, after over three years of establishment, it has mostly generated publicity, with slow market development, and the B2B market has yet to show signs of life, while the B2C market has seen little actual application, likely still in a money-burning phase.
Outgoing Questions
Outgoing Questions was established in 2012, and its CEO previously worked at Google. After obtaining angel investments from Sequoia Capital and Zhen Fund, he resigned from Google to establish Shanghai Yushan Intelligent Information Technology Co., Ltd., aiming to create the next generation of mobile voice search products – “Outgoing Questions.”
The success of Outgoing Questions lies in its ranking on the Apple App Store, but the author does not understand why, with so many built-in maps, there is still a need to download this software, which can sometimes be more cumbersome than directly searching the map. Outgoing Questions also has strong financing capabilities, having secured $75 million in Series C financing from Google in 2015. Outgoing Questions primarily targets the wearable market and has recently launched smartwatches, but it has also been more noise than results, with no significant sales reported for its smartwatches.
Other Domestic Voice Recognition Companies
The threshold for voice recognition is not high, so major domestic companies are gradually joining in. Sogou initially adopted Yunzhisheng’s voice recognition engine but quickly built its own, primarily applied in Sogou Input Method, with decent results.
Tencent certainly will not fall behind, as WeChat has also established its own voice recognition engine for converting speech to text, but it still lags somewhat.
Alibaba, iQIYI, 360, LeTV, and others are also building their own voice recognition engines, but these large companies are more focused on self-research and self-use, with generally mediocre technology and little influence in the industry.
Of course, besides the aforementioned industry voice recognition companies, academic tools like Cambridge’s HTK have significantly pushed research in the academic field, along with CMU, SRI, MIT, RWTH, ATR, and others contributing to the development of voice recognition technology.
What is the Principle of Voice Recognition Technology?
For voice recognition technology, everyone has had some exposure and application. We have also introduced the major voice recognition technology companies domestically and internationally. But you may still wonder what the principle of voice recognition technology is. Let me explain it to you.
Voice Recognition Technology
Voice recognition technology is the technology that allows machines to transform voice signals into corresponding text or commands through recognition and understanding processes. The purpose of voice recognition is to endow machines with human-like listening capabilities, understanding what people say and responding accordingly. Currently, most voice recognition technologies are based on statistical models. From the perspective of speech generation mechanisms, voice recognition can be divided into two parts: the speech layer and the language layer.
Essentially, voice recognition is a pattern recognition process, where the pattern of unknown speech is compared with known speech reference patterns one by one, and the best-matching reference pattern is taken as the recognition result.
Today’s mainstream algorithms in voice recognition technology mainly include Dynamic Time Warping (DTW) algorithms, vector quantization (VQ) methods based on non-parametric models, Hidden Markov Model (HMM) methods based on parametric models, and speech recognition methods based on artificial neural networks (ANN) and support vector machines.
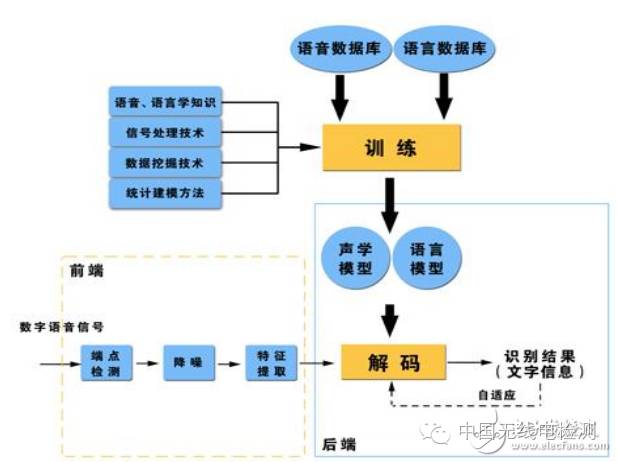
Basic Block Diagram of Voice Recognition
Classification of Voice Recognition:
According to the degree of dependence on the speaker, it can be divided into:
(1) Speaker-dependent voice recognition (SD): can only recognize the voice of specific users, training → usage.
(2) Speaker-independent voice recognition (SI): can recognize the voice of anyone without training.
According to the requirements for the speaking method, it can be divided into:
(1) Isolated word recognition: can only recognize individual vocabulary at a time.
(2) Continuous speech recognition: users can speak normally, and the system can recognize the sentences.
Voice Recognition System
The model of a voice recognition system typically consists of two parts: the acoustic model and the language model, corresponding to the calculation of the probability from speech to syllables and the probability from syllables to words.
Sphinx is a large vocabulary, speaker-independent, continuous English speech recognition system developed by Carnegie Mellon University. A continuous speech recognition system can roughly be divided into four parts: feature extraction, acoustic model training, language model training, and decoder.
(1) Preprocessing Module
Processes the raw speech signal input, filtering out unimportant information and background noise, and performing endpoint detection (finding the beginning and end of the speech signal), speech framing (approximating that within 10-30ms, the speech signal is short-term stationary, dividing the speech signal into segments for analysis), and pre-emphasis (enhancing high-frequency components).
(2) Feature Extraction
Removes redundant information in the speech signal that is useless for voice recognition, retaining information that reflects the essential characteristics of speech and expressing it in a certain form. This means extracting key feature parameters that reflect the characteristics of the speech signal to form a feature vector sequence for subsequent processing.
Currently, there are various commonly used methods for extracting features, but these methods are mostly derived from spectral analysis.
(3) Acoustic Model Training
Trains the acoustic model parameters based on the feature parameters of the training speech library. During recognition, the feature parameters of the speech to be recognized can be matched with the acoustic model to obtain recognition results.
Most mainstream voice recognition systems currently use the Hidden Markov Model (HMM) for acoustic model modeling.
(4) Language Model Training
The language model is a probabilistic model used to calculate the probability of a sentence’s occurrence. It mainly determines which word sequence is more likely or predicts the content of the next word that is about to appear based on several previously appeared words. In other words, the language model is used to constrain word searches. It defines which words can follow the last recognized word (matching is a sequential processing process), thus eliminating some impossible words from the matching process.
Language modeling can effectively combine knowledge of Chinese grammar and semantics to describe the internal relationships between words, thereby improving recognition rates and reducing search scope. Language models are divided into three levels: lexical knowledge, grammatical knowledge, and syntactic knowledge.
Language modeling methods mainly include rule-based models and statistical models.
(5) Speech Decoding and Search Algorithms
Decoder: refers to the recognition process in speech technology. For the input speech signal, a recognition network is established based on the trained HMM acoustic model, language model, and dictionary, and the best path is sought in that network using search algorithms. This path is the word string that can output the maximum probability for the speech signal, thus determining the text contained in the speech sample. Therefore, decoding operations refer to search algorithms: methods of finding the optimal word string through search technology at the decoding end.
In continuous speech recognition, searching involves finding a word model sequence to describe the input speech signal, thus obtaining a word decoding sequence. The search is based on scoring the acoustic model and language model in the formula. In practical use, it is often necessary to assign a high weight to the language model based on experience and set a long-word penalty score. Today’s mainstream decoding technologies are mostly based on the Viterbi search algorithm, and Sphinx is no exception.
Challenges of Voice Recognition Technology
Speaker Variability
• Different speakers: pronunciation organs, accents, speaking styles
• Same speaker: different times, different states
Noise Interference
• Background noise
• Transmission channels, microphone frequency response
Robustness Technology
• Discriminative training
• Feature compensation and model compensation
Specific Applications of Voice Recognition
• Command Word Systems
Ø The recognition grammar network is relatively limited and has strict requirements for users
Ø Menu navigation, voice dialing, in-car navigation, digital letter recognition, etc.
• Intelligent Interaction Systems
Ø More relaxed requirements for users, requiring integration with other technical fields
Ø Call routing, POI voice fuzzy queries, keyword detection
• Large Vocabulary Continuous Speech Recognition Systems
Ø Massive vocabulary, wide coverage, ensuring accuracy while having poor real-time performance
Ø Audio transcription
• Voice Search Combined with the Internet
Ø Implementing voice-to-text and voice-to-voice searches
