
Is it far away for machines to listen, speak, understand, and think? The first function to achieve is the ability to “hear.”
Open Sesame!

Did you also command the door like this in your childhood?
Of course, the door remains still, indicating its “disregard” for you. Nevertheless, the enthusiastic child would occasionally shout at the door, hoping for a response, such as: the door opening.
What causes the command to fail? Because the door itself lacks the ability to hear sound. If we could make the door hear what you say and the commands you give, we could further activate a semantic and execution system to control its opening and closing.
This leads us to the key technology introduced this time—voice recognition.This insightful sharing is provided by the voice recognition product manager:@ Caramel Macchiato Hoping to open the door to voice recognition for everyone.
Voice recognition is a process that converts human voice signals into text. This article will classify and explain the industry’s voice recognition products from a product perspective. Different product types have different algorithms or interface characteristics, corresponding to various demand scenarios.
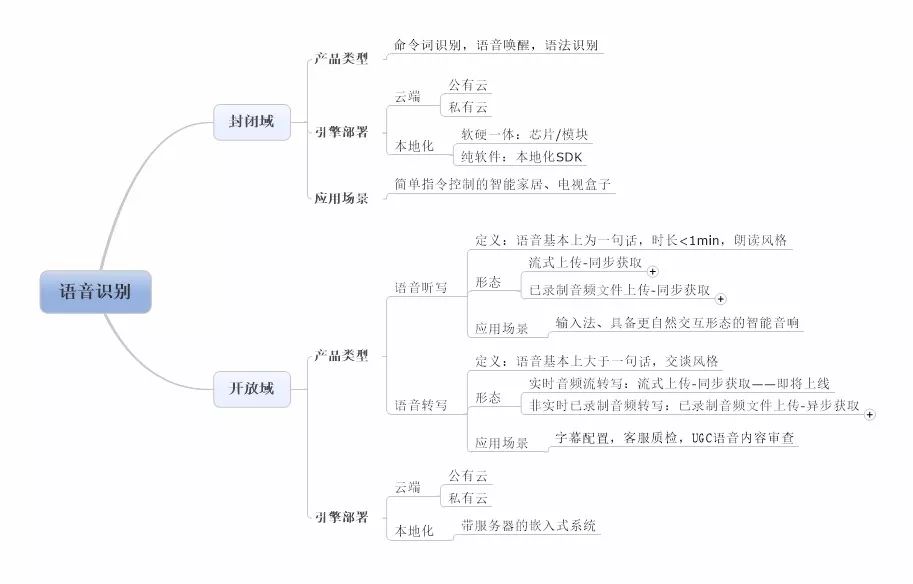
Based on the scope of recognition content, voice recognition is broadly categorized as follows:
1. Closed-domain recognition:
The recognition range is a pre-defined set of words/phrases, meaning the algorithm only performs voice recognition within the closed domain set defined by the developer, rejecting voices outside the range. Therefore, its acoustic model and language model can be trimmed, resulting in a smaller computational load for the recognition engine. It can also be embedded into chips or localized SDKs, allowing the recognition process to be completely independent of the cloud, eliminating reliance on the network, without affecting the recognition rate. The deployment methods provided by industry vendors include cloud and localization (e.g., chips, modules, and pure software SDKs).
Product types: Command word/phrase recognition, voice wake-up, grammar recognition
Product form: Streaming transmission – synchronous acquisition
Typical application scenarios: Scenarios that do not involve multi-turn interaction and various semantic expressions, such as simple command interactions in smart homes and TV boxes. The voice control commands generally include: “Open the curtains,” “Turn on the central channel,” etc. However, once commands are issued that are configured in the background outside the recognition word set by the developers, such as “Give the editor a tip for this article,” the recognition system will reject this voice, not returning any corresponding text results, nor performing any corresponding reply or command actions.
2. Open-domain recognition:
No pre-defined recognition word set is required; the algorithm will recognize within the entire language set. To accommodate such scenarios, the acoustic model and speech model are generally larger, resulting in a higher computational load for the engine. When packaged into embedded chips or localized SDKs, it consumes more energy and affects recognition performance. Vendors typically provide this in a cloud format, which includes both public and private cloud forms. The localized form is only available for embedded systems with server-level computing capabilities, such as conference captioning systems.
Product types based on speaking style characteristics are divided into:
(1)Voice Dictation: Voice duration is generally short (<1min), usually just a sentence. The training corpus is of a reading style, with a relatively even speech rate. Generally used in human-machine dialogue scenarios with good recording quality.
Defining product forms based on audio input and result acquisition:
(a) Streaming upload – synchronous acquisition; applications/software will automatically record the speaker’s voice and continuously upload it to the cloud, allowing the speaker to see the returned text in real-time as they finish speaking. Voice cloud service vendors provide audio recording interfaces and format encoding algorithms in their product interfaces for clients to record and upload simultaneously, establishing a long connection with the cloud to listen and obtain recognition results synchronously.
(b) Pre-recorded audio file upload – synchronous acquisition; users need to pre-record audio in the specified format and use the interface provided by the voice cloud service vendor to upload the audio. The connection and result acquisition method between the client and the cloud are similar to the audio stream.
Typical application scenarios: Application development has matured considerably: mainly in input scenarios, such as input methods; and in human-machine interaction scenarios combined with microphone arrays and semantics, such as smart speakers with more natural interaction forms, like “Ding dong ding dong, forward this article from the editor.” Even without configuration, the recognition system can recognize this voice and return the corresponding text result.
(2)Voice Transcription: Voice duration is generally longer (within five hours), with many sentences. The training corpus is of a conversational style, meaning the speaker’s speech is quite unorganized, resulting in uneven speech rates, with many instances of slurring and blending words. Recordings are mostly from a distance or noisy environments.
Besides the model differences, defining product forms based on audio input and result acquisition:
(a) Audio stream transcription: Streaming upload – synchronous acquisition, similar to the above voice dictation, with the only difference being that there is no one-sentence limit on the recognition duration.
(b) Non-real-time pre-recorded audio transcription: Pre-recorded audio file upload – asynchronous acquisition; users need to call the software interface or hardware platform to pre-record audio in the specified format and use the interface provided by the voice cloud service vendor to upload the audio. After uploading, they can disconnect. Users can obtain results by polling the voice cloud server or using a callback interface.
Due to the large computational load of long voice and the longer computation time, asynchronous acquisition can avoid result loss due to network issues. Because voice transcription systems are typically processed non-real-time, this engineering form allows the recognition algorithm more time for multiple decoding iterations. The long training corpus also provides the algorithm with more extended information for long-short term memory network modeling. With the same input audio, this product form sacrifices some real-time capability and incurs higher resource consumption, but achieves the highest recognition rate. In scenarios where time allows, non-real-time pre-recorded audio transcription is undoubtedly the most recommended product form!
Typical application scenarios: Such as subtitle configuration, customer service voice quality inspection, UGC voice content review.
Clarification of Concepts
1. Offline VS Online
In the product definitions of the iFlytek open platform and many customers’ awareness, the distinction between offline/online lies in whether the recognition process requires a cloud request, i.e., whether the recognition engine is in the cloud or local. In cloud computing, both offline and online product engines are cloud-based; the difference lies in whether the client needs to interact with the cloud for real-time data during the computation process, as mentioned above in audio streams and non-real-time pre-recorded audio transcription. The definitions of the two conflict, so it is not recommended to use the offline/online concept for related product definitions.
2. 8K VS 16Khz Sampling Rate Voice Models
Among many voice cloud service vendors, classification is based on audio sampling rates to train more suitable voice models for various sampling rates, with the most typical being 8K and 16K models. The more original audio information retained, the more beneficial it is for improving recognition rates. Therefore, 16K audio uses a 16K voice model, and its recognition rate will generally be higher than that of 8K audio using an 8K model.
3. Voice Recognition VS Semantic Recognition
Voice recognition is the fundamental basis for semantic recognition. Voice recognition converts sound into text, and semantic recognition extracts relevant information and corresponding intent from the text, executing corresponding question responses or feedback actions through the execution module.
Conclusion (Example Combining a Little Semantics):
Finally, let’s conclude with an example: “Ding dong ding dong, give the editor a thumbs up for this article.” In the absence of backend configuration, the closed-domain voice recognition system will reject this voice, while the open-domain recognition system can recognize it and return the corresponding text result. However, the current open-domain semantic system, in most cases, still responds quite rigidly and does not automatically identify the relevant intent and take command actions. According to existing common methods, this function requires using closed-domain semantic recognition to pre-configure relevant answers in the background, extract intent based on pre-configured information, and execute corresponding actions according to intent categories and slot information—i.e., calling WeChat’s like interface (assuming it is possible) to perform the corresponding like action.
It sounds complicated, doesn’t it? You might think it’s much simpler and more straightforward to just manually give a thumbs up! However, every modern human action that seems natural and effortless is built on millions of years of learning evolution and billions of closed-loop repetitions in Homo sapiens’ genes! And any artificial intelligence technology also requires a massive amount of data training and a certain evolutionary cycle. Moreover, throughout the technological development process, breakthroughs and maturity in application fields often first occur in closed domains, just as semantic recognition (e.g., AIUI, echo, etc.) is currently in the closed domain productization phase, while the maturity of voice recognition products has transitioned from closed to open domains, delivering the power of artificial intelligence to various industries!
writer by Caramel Macchiato
editor by Class Teacher
Attached Image: Voice Recognition Product Category Diagram
Does anyone have any other questions about voice recognition? Feel free to speak up in the comments!


Follow us for more courses (*^▽^*)
Recommended Reading:
Benefits | 20 Top AI Textbooks for Free