Machine Heart Column
Author: Principal Engineer Dong Bingfeng, Chubao AI Lab
The input vector X in traditional CRF is generally in the one-hot format of words, which loses a lot of semantic information about words. With the advent of word embedding methods, the word representation in vector form generally performs better than the one-hot representation. This article primarily introduces LSTM, word embedding, and Conditional Random Fields (CRF), and then explores the application of BiLSTM and CRF in sequence labeling problems.
Word Embedding and LSTM
Word Embedding is simply the mapping of a high-dimensional one-hot vector representing a word (the dimension of the space is usually the size of the dictionary) in a high-dimensional space to a low-dimensional (dozens of dimensions) continuous space vector, which is called a word vector.
Word vectors can contain a lot of semantic information about words and have some amazing properties, for example: v(queen) – v(king) = v(woman) – v(man) (using v(x) to denote the word vector of word x, see Figure 1); however, word embedding is more often used in DNN as preprocessing for high-dimensional discrete features (as is the case in this application).
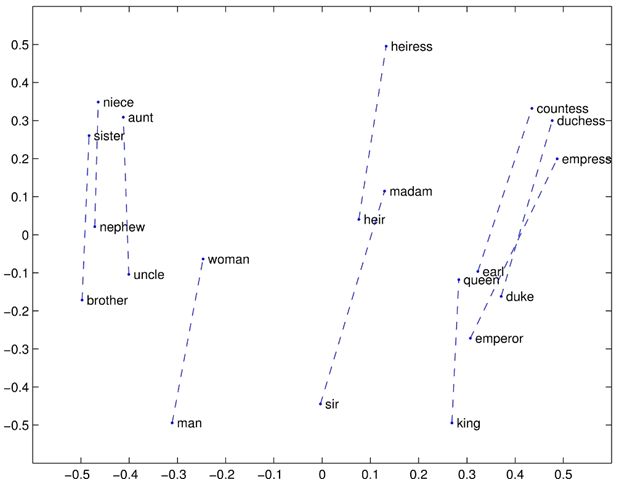
Figure 1: Some word vectors in two-dimensional space
A detailed explanation of word vectors and algorithms can be found in this article: http://mccormickml.com/2016/04/19/word2vec-tutorial-the-skip-gram-model/
LSTM (Long Short Term Memory) is a special type of RNN (Recurrent Neural Network) capable of learning long-term dependencies. It was proposed by Sepp Hochreiter and Jürgen Schmidhuber in 1997, and has been refined and popularized. LSTM performs well on various tasks, thus it is widely used for sequence data processing.
A typical LSTM chain has the structure shown in Figure 2:
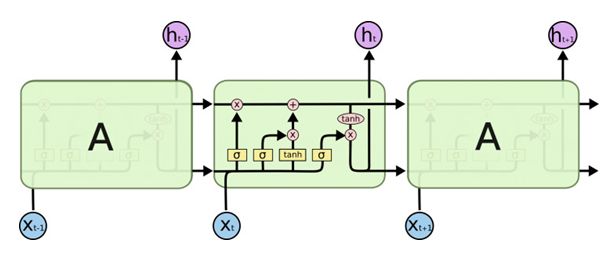
Figure 2: LSTM network structure, where X represents the input sequence and h represents the output.
The core of LSTMs lies in the cell state, which is the line going right in Figure 2. The cell state acts like a conveyor belt, transmitting information along the entire chain, with only a few places having some linear interactions. If information is transmitted in this way, it will remain unchanged. LSTM controls the cell state through a structure called a “gate” and can add or remove information from it. An LSTM has three such gates: the forget gate, the input gate, and the output gate, which control the cell state.
For example, in a language model, the cell state may need to consider the gender of the subject to find the correct pronoun. Therefore, if we see a new subject, the “forget gate” is used to forget the gender represented by the old subject. Then we use the “input gate” to add the new subject’s gender information into the cell state to replace the old information to be forgotten. Finally, we need to determine the output content; when it only sees a subject, it might output information related to the verb. For instance, it will output whether the subject is singular or plural. In this case, if a verb appears later, we can determine its form.
Related materials on LSTM can be found at: http://colah.github.io/posts/2015-08-Understanding-LSTMs/
If we can access future context information as we access past context information, it would be very beneficial for many sequence labeling tasks. For example, in sequence labeling, knowing the upcoming words as well as the previous words would be very helpful.
The basic idea of Bidirectional LSTM (Bi-LSTM) is to propose that each training sequence has two LSTMs, one processing the sequence forward and the other backward, both connected to an output layer. This structure provides the output layer with complete past and future context information for each point in the input sequence. Figure 3 shows a Bi-LSTM unfolded over time.
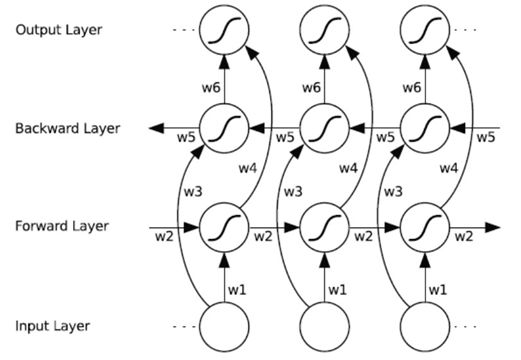
Figure 3: Bi-LSTM schematic diagram
CRF (Conditional Random Fields)
To understand Conditional Random Fields, we need to explain a few concepts: probabilistic graphical models and Markov random fields.
Probabilistic graphical models (Graphical Models): A graph is a set consisting of nodes and edges connecting the nodes, with nodes and edges denoted as v and e, respectively. The set of nodes and edges is denoted as V and E, and the graph is denoted as G = (V, E). An undirected graph is a graph with edges that have no direction. A probabilistic graphical model is a probability distribution represented by a graph. Let P(Y) be the joint probability distribution, 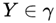 be a set of random variables. The probability distribution P(Y) is represented by an undirected graph G = (V, E), meaning that in graph G, node
be a set of random variables. The probability distribution P(Y) is represented by an undirected graph G = (V, E), meaning that in graph G, node 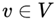 represents a random variable,
represents a random variable,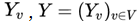 ; the edge
; the edge 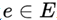 represents the probabilistic dependency relationship between random variables.
represents the probabilistic dependency relationship between random variables.
Pairwise Markov Property: Let u and v be any two nodes in the undirected graph G that are not connected by an edge, with nodes u and v corresponding to random variables Y_u and Y_v. The pairwise Markov property states that given a set of random variables Y_o, the random variables Y_u and Y_v are conditionally independent, i.e.:
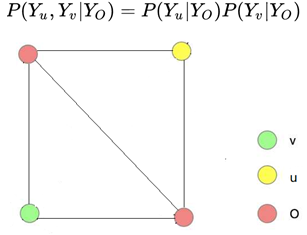
Figure 4: Pairwise Markov property
Local Markov Property: Let 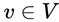 be any node in the undirected graph G, W be all nodes connected to v by an edge, and O be all other nodes except v and W, where v represents the random variable Y_v , W represents the random variable set, and O represents the random variable set Y_w. The local Markov property states that given the random variable set Y_w, the random variable and the random variable set are independent, i.e.:
be any node in the undirected graph G, W be all nodes connected to v by an edge, and O be all other nodes except v and W, where v represents the random variable Y_v , W represents the random variable set, and O represents the random variable set Y_w. The local Markov property states that given the random variable set Y_w, the random variable and the random variable set are independent, i.e.:
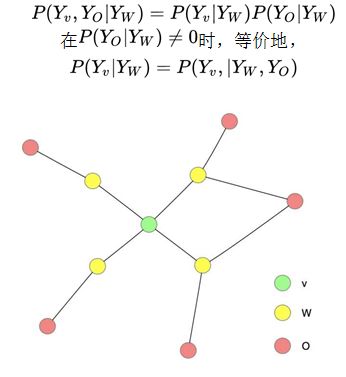
Figure 5: Local Markov property
Global Markov Property: Let the node sets A and B be any node sets in the undirected graph G separated by the node set C, and the random variable sets corresponding to the node sets A, B, and C be Y_A, Y_B, and Y_C, respectively. The global Markov property states that given the random variable set Y_C, the random variable sets Y_A and Y_B are conditionally independent, i.e.
Figure 6: Global Markov property
The global Markov property, local Markov property, and pairwise Markov property can be proven to be equivalent.
Markov Random Field (MRF): Given a joint probability distribution P(Y) represented by an undirected graph G = (V, E), in graph G, nodes represent random variables, and edges represent the dependency relationships between random variables. If the joint probability distribution P(Y) satisfies the pairwise, local, or global Markov property, it is called a Markov random field.
Cliques: A subset of nodes in an undirected graph G in which any two nodes are connected by an edge is called a clique. If C is a clique in the undirected graph G and cannot add any node from G to become a larger clique, then C is called a maximum clique.
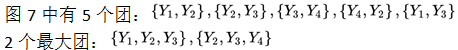
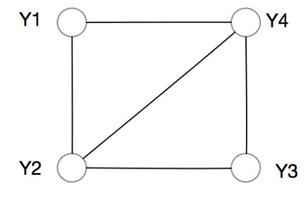
One important role of introducing probabilistic undirected graphs is that it can decompose the joint probability distribution represented by the probabilistic undirected graph into the product of the joint probability distributions of each clique:
Hammersley-Clifford theorem: The joint probability distribution P(Y) of a probabilistic undirected graph model can be represented in the following form:
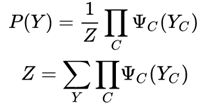
Where C is the clique of the undirected graph, Y_C is the random variable corresponding to the nodes of C,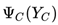 is a strictly positive function defined on C (also known as the potential function), and the product is taken over all cliques in the undirected graph (these cliques cover all nodes in the undirected graph).
is a strictly positive function defined on C (also known as the potential function), and the product is taken over all cliques in the undirected graph (these cliques cover all nodes in the undirected graph).
We generally write the potential function in the following form:
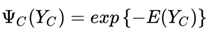
Where E(Y_c) becomes the energy function of clique C, inspired by the property of the Boltzmann distribution in thermodynamics that “the probability of states with lower energy is greater.”
Furthermore, we model the energy function E(Y_c) of clique C as a linear combination of a series of functions f_k(Y_c) of the random variables Y_c in C:
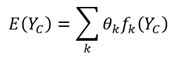
Where f_k(Y_c) is called the feature function.
Conditional Random Fields (CRF) are a conditional probability distribution model of another set of output random variables given a set of input random variables, characterized by the assumption that the output variables form a Markov random field.
We can simply replace Y in the above expressions with Y|X, thus we have:
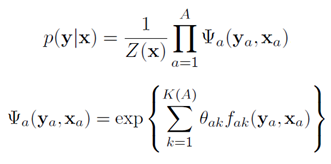
Conditional random fields can be used in different prediction problems; this article only discusses its application in labeling problems. Therefore, we mainly describe linear chain conditional random fields (Linear Chain CRFs), with the corresponding probability graph shown in Figure 8:
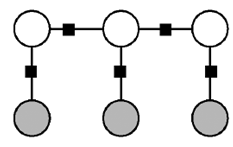
Figure 8: Linear chain conditional random field
Where the white nodes represent output random variables Y, and the gray nodes represent input random variables X. In the linear chain conditional random field, each output variable only has dependencies with the two adjacent output variables and the input variable X. At this point, we can simplify the general CRF model to:
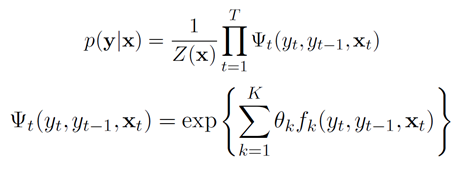
Sequence Labeling Problem
The sequence labeling problem here is to label different types of named entities (person names, location names, organization names) that appear in the sequence, for example:
John(B-PER) lives(O) in(O) New(B-LOC) York(I-LOC) and(O) works(O) for(O) the(O) European(B-ORG) Union(I-ORG).
The content in parentheses is the label: PER indicates person name, LOC indicates location name, ORG indicates organization name, O indicates non-named entity, B-X indicates the first word of the named entity (B-PER indicates the first word of the person name), and I-X indicates the words after the second word of the named entity.
A simple method to solve the named entity recognition problem is to pre-store all these named entities in a list and match each subsequence that appears in the sequence against the list. One major problem with this method is that it cannot recognize named entities that are not in the list. We can imagine the process of human named entity recognition: besides using prior knowledge (New York is a location), we also make inferences about words without prior knowledge based on context. For example, in the above case, if we do not know what the European Union is, we can infer from the capitalization that it might be a proper noun and, combined with the previous works for, we can speculate that it is likely to be an organization name.
Sequence Labeling Model
To achieve this goal with machines, we can proceed in the following steps:
-
Word vector representation: Represent individual words with vectors in a low-dimensional continuous space. We can use pre-trained word embeddings or break words into individual letters for two reasons: first, many proper nouns rarely appear and do not have corresponding word embeddings; second, capitalized words may help us identify proper nouns (morphological information).
-
Context vector representation: Each word’s context needs to be represented with a vector in a low-dimensional continuous space, here we will use LSTM.
-
Named entity labeling: Use word vectors and context vectors to obtain predicted labeling results.
Word Vector Representation
First, break individual words into sequences of individual letters, and use Bi-LSTM to generate word vectors W(char), with the network structure shown in Figure 9:
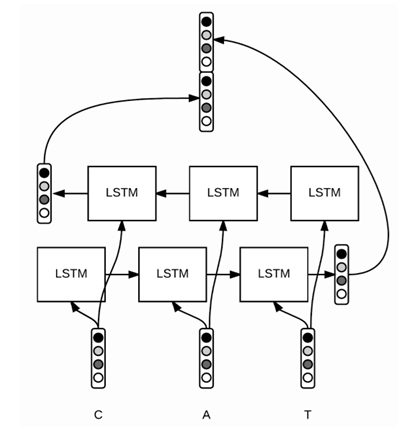
Figure 9: Character sequence generates word embedding
Then we can use word-based embedding algorithms (such as GloVe, CBOW, etc.) to generate word vectors W(glove).
We concatenate the two word vectors W = [W(glove), W(char)], which contain both the semantic and morphological information of the word.
Context Vector Representation
We use another Bi-LSTM to generate the vector representation of words in context, with the network structure shown in Figure 10.
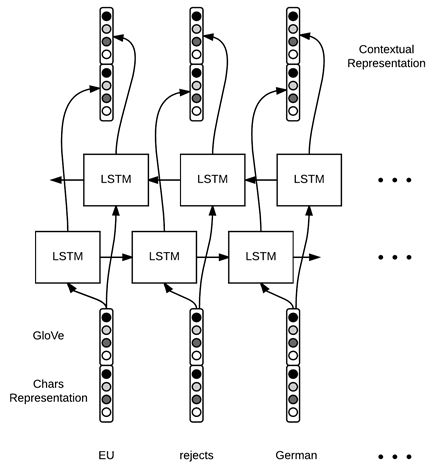
Figure 10: Generation of word vector representations in context
Named Entity Labeling
For a given sequence X of length m, assuming the labeling result is [y1, …, ym] where yi = PER/LOC/ORG/O, the named entity labeling problem can be expressed as finding the sequence [Y1, …, Ym] that maximizes the probability P(y1, …, ym) given the known sequence X.
This problem is suitable for modeling with linear chain conditional random fields:
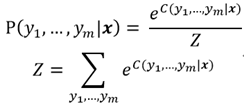
Combining the general form of the previous model, we define the energy function of this problem as follows:
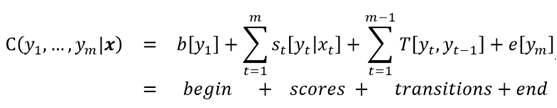
b[y_1] represents the score of the sequence starting with label y1; e[y_m] represents the score of the sequence ending with label y_m,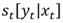 represents the score under the condition that the current word label is y, and represents the score of the transition between previous and next label states.
represents the score under the condition that the current word label is y, and represents the score of the transition between previous and next label states.
The above four items clearly describe several factors we consider when labeling: the current word’s relevant information and the positional information of that label.
The optimal solution for the labeling sequence y 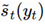 satisfies the following conditions:
satisfies the following conditions:
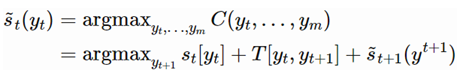
The optimal labeling sequence can be solved using the Viterbi algorithm (dynamic programming).
Bi-LSTM Combined with CRF
In traditional CRF, the input vector X is generally in the one-hot format of words, which loses a lot of semantic information about words. With word embedding methods, the word representation in vector form generally performs better than the one-hot representation.
In this application, the term in the CRF model energy function 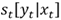 can be replaced with the result of concatenating the word vectors generated from the letter sequence W(char) and the word vectors generated from GloVe W = [W(glove), W(char)].
can be replaced with the result of concatenating the word vectors generated from the letter sequence W(char) and the word vectors generated from GloVe W = [W(glove), W(char)].
CRF Implementation in TensorFlow
In TensorFlow, there is already a CRF package that can be called directly, with sample code as follows (for specifics, please refer to the official TensorFlow documentation https://www.tensorflow.org/api_docs/python/tf/contrib/crf):
labels= tf.placeholder(tf.int32, shape=[None, None], name=”labels”)
log_likelihood,transition_params = tf.contrib.crf.crf_log_likelihood(
scores, labels, sequence_lengths)
loss= tf.reduce_mean(-log_likelihood)
References
-
Sutton, Charles, and Andrew McCallum. “An introduction to conditional random fields.” Machine Learning 4.4 (2011): 267-373
-
https://zhuanlan.zhihu.com/p/30606513
-
https://guillaumegenthial.github.io/sequence-tagging-with-tensorflow.html
-
http://blog.echen.me/2012/01/03/introduction-to-conditional-random-fields/
-
https://zhuanlan.zhihu.com/p/28343520
This article is part of the Machine Heart column, please contact this public account for authorization to reproduce.
✄————————————————
Join Machine Heart (Full-time reporter/intern): [email protected]
Submissions or seeking coverage: [email protected]
Advertising & Business Cooperation: [email protected]