MLNLP ( Machine Learning Algorithms and Natural Language Processing ) community is a well-known natural language processing community both domestically and internationally, covering NLP master’s and Ph.D. students, university professors, and researchers in enterprises.The vision of the community is to promote communication between the academic and industrial communities of natural language processing and machine learning, especially for the progress of beginners.
Reprinted from | Harbin Institute of Technology SCIR
Author | Feng Xia Chong
1
『Summary』
Multi-modal summarization refers to the integration of various modalities of information, typically including text, speech, images, videos, etc., to produce a core summary that considers multiple modalities. Current summarization research usually focuses on text as the processing object and generally does not involve the processing of other modal information. However, information from different modalities can complement and verify each other. Effectively utilizing information from different modalities can help models better identify key content and generate better summaries. This article first classifies multi-modal summarization according to the type of task and whether the modal information is synchronized; then introduces some basic knowledge in multi-modal representation; finally, according to task type, briefly describes recent relevant work in multi-modal summarization in educational videos, multi-modal news, multi-modal input-output, and conferences, and concludes with some thoughts and summaries.
2
『Classification of Multi-Modal Summarization』
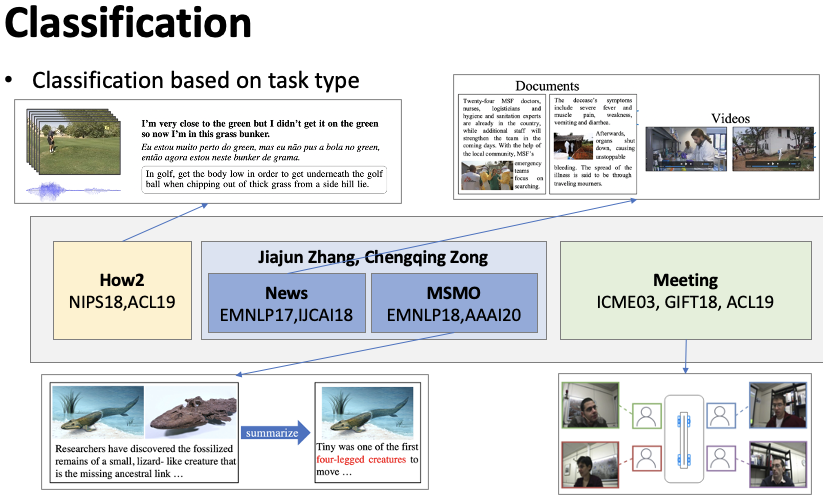
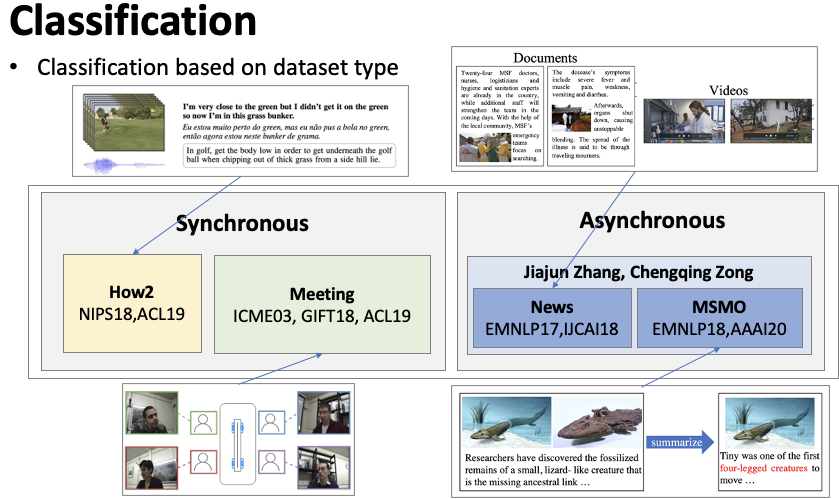
This article classifies multi-modal summarization based on (1) the type of task it addresses and (2) whether the modal information is synchronized.Figure 1 Classification by Task TypeAccording to the task type of multi-modal summarization, as shown in Figure 1. (1) Educational video summarization (How2), How2 is a dataset for educational video multi-modal summarization that includes video information, audio information from the author’s explanation, and corresponding text information, aiming to generate a teaching summary. (2) Multi-modal news summarization aims to summarize news that includes text, images, and videos. (3) Multi-modal input-output summarization (MSMO) refers to a scenario where the input is multi-modal, including a piece of text and some related images, and the output must provide not only a text summary but also select the most appropriate image from the input images. (2, 3) are mainly the work of Professor Zong Chengqing and Professor Zhang Jiajun from the Chinese Academy of Sciences. (4) Multi-modal conference summarization refers to generating a summary for a meeting given the video of the meeting and the audio information of each participant speaking.Figure 2 Classification by Synchronization of Modal InformationClassification based on whether modal information is synchronized, as shown in Figure 2. (1) Synchronized multi-modal summarization means that at every moment, the video, audio, and text correspond uniquely. For example, in a meeting, at a certain moment, the speaker’s video and the words spoken correspond uniquely. (2) Asynchronous multi-modal summarization means that the multi-modal information does not correspond one-to-one. For example, in a multi-modal news piece, there is often an initial video, followed by text information interspersed with images, thus the multi-modal information is asynchronous.
3
『Basic Knowledge of Multi-Modal Representation』
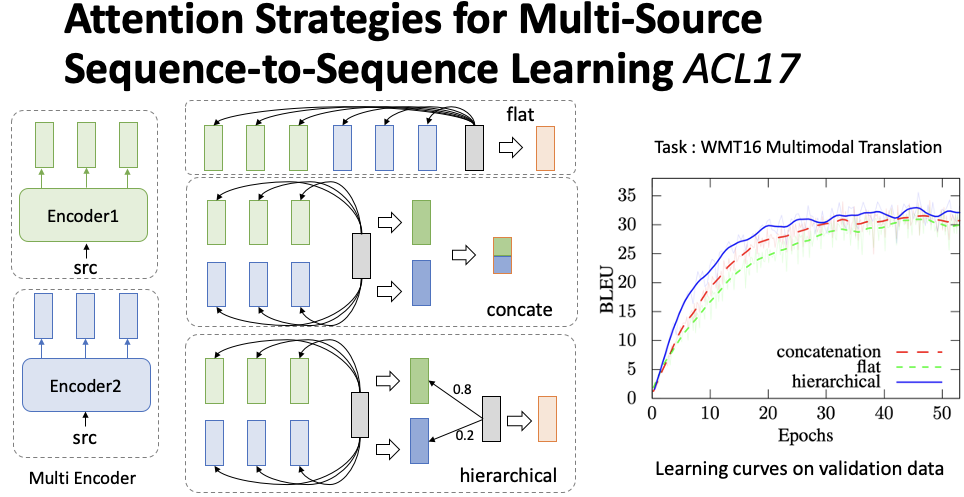
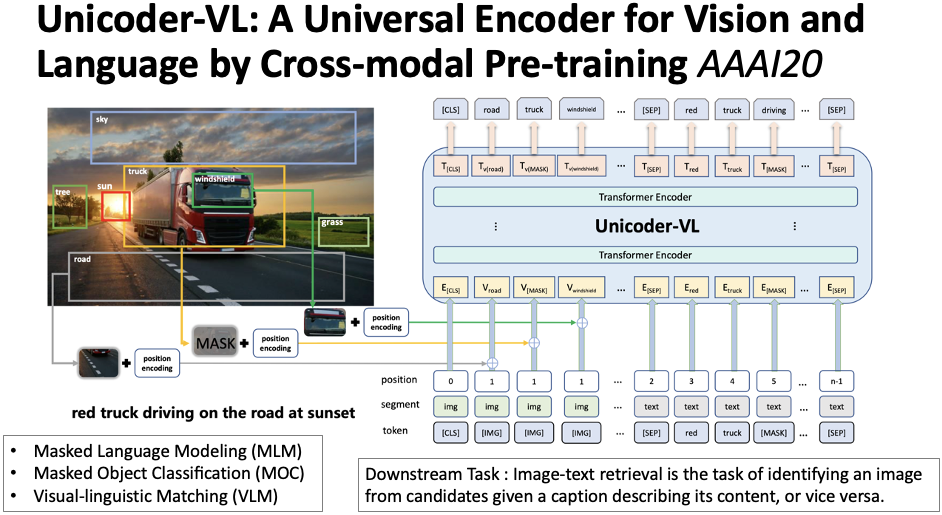
This section introduces some basic knowledge of multi-modal representation, including the attention mechanism in multi-modal sequence-to-sequence models, multi-modal word representations, and multi-modal pre-training models.Figure 3 Multi-Modal Generation Attention MechanismFirst, there is a paper from ACL17 by Libovický and Helcl, 2017[1], which proposed how to apply attention to multi-modal source data within a sequence-to-sequence framework. As shown in Figure 3, green and blue represent the hidden layer representations of two modalities in the encoder, gray represents the hidden state of the decoder, and orange represents the attention vector. Assuming we have multiple modality encoders, called Multi Encoder, after encoding, each modality will have a sequence of hidden layer representations. The paper proposed three types of attention mechanisms: (1) The first method is flat, which smooths all encoder hidden layer representations. The attention score is calculated using the decoder hidden state on the smoothed encoder hidden layer representations, resulting in the final attention vector; (2) The second method is concat, which calculates scores for the two sequences separately using the decoder hidden state, yielding separate attention vectors, which are then concatenated and transformed to a unified dimension; (3) The third method is hierarchical, which first obtains the attention vectors corresponding to the two modalities and then uses the decoder hidden representation to calculate the weight distribution for these two attention vectors, ultimately fusing multiple attention vectors based on the weights. The authors conducted experiments on multi-modal machine translation tasks and found that the hierarchical method yielded the best results, and subsequent works have largely adopted the hierarchical attention mechanism.Figure 4 Example of Hate Word RepresentationNext is a work on multi-modal word representation published by Tsinghua University and CMU in AAAI19 by Wang et al., 2019[2]. The core idea is to adjust word representations using non-verbal features such as video and audio. For example, the word ‘hate’ can have many meanings in Chinese, such as genuine hate, which is a negative sentiment, or a girlfriend’s acting cute, which is a positive sentiment. Therefore, relying solely on text and giving a fixed word representation may lead to insufficient semantic representation of the word, thus not effectively utilized in downstream tasks. The paper argues that introducing multi-modal information can alleviate this issue, as shown in Figure 4. When we provide an image of an eye roll, the representation of the word ‘hate’ can be adjusted to the blue point. When we provide another image, the representation can be adjusted to the orange position. This means utilizing information from non-verbal modalities to supplement the semantic information of word representations, making them more appropriate, or in other words: more context-sensitive with respect to multi-modal information.Figure 5 RAVEN ModelThe entire multi-modal word representation model is called RAVEN, which consists of three modules. As shown in Figure 5, for a word like ‘sick’, there is a corresponding continuous video and audio segment, utilizing existing feature extraction tools (FACET and COVAREP) to extract features, ultimately obtaining the feature representations corresponding to each modality, where red represents video feature representation, yellow represents audio feature representation, and green represents word feature representation. The video and audio representations are used to compute a score with the word representation, and based on this score, a non-verbal offset vector (purple) is obtained through feature fusion. Finally, this vector is normalized and added to the word vector to obtain a word representation that incorporates multi-modal information. The authors conducted experiments on multi-modal sentiment analysis and multi-modal dialogue emotion recognition tasks, finding that the results were significantly better in sentiment analysis.Figure 6 Unicoder-VL ModelFinally, this paper presents a multi-modal pre-training model proposed by Professor Zhou Ming’s group at AAAI20, Li et al., 2020[3]. The input includes information from both images and text. For images, the tool Faster R-CNN is first used to extract specific meaningful parts, such as trucks, trees, roads, etc., along with their corresponding feature vector representations and positional information. As shown in Figure 6, the model input is divided into three parts. For images, the word vectors are all [IMG], segments are img, and positions are all 1. Additionally, before entering the model, two extra inputs are required: (1) the feature vectors of each image; (2) image position features. The text part is consistent with BERT. There are three pre-training tasks, where MLM and MOC involve masking text and images for prediction, and VLM uses the [CLS] tag to indicate whether the input image and text match.
4
『Educational Video Summarization』
This section introduces relevant papers on multi-modal summarization for educational videos (How2).Figure 7 Example of How2 DatasetThe How2 dataset, proposed by Sanabria et al., 2018[4], published in NIPS18, is named after ‘how to do something’ and mainly describes educational videos, as shown in Figure 7, for a golf teaching video. This dataset includes video information, audio information from the author’s explanation, text information, and the final summary. It contains a total of 2000 hours of video, covering themes such as sports, music, cooking, etc. The summaries average 2 to 3 sentences.Figure 8 Multi-Modal Model for How2 Dataset
Palaskar et al., 2019[5] proposed a basic multi-modal summarization model for educational video summarization tasks at ACL19, as shown in Figure 8. The model includes a video encoder, text encoder, and decoder. The video encoder uses the ResNext-101 3D model, capable of recognizing 400 types of human action. The text encoder is based on an RNN. After obtaining the hidden layer representations of the two modalities, a hierarchical attention mechanism is used to generate the final summary. Experiments have shown that the model that integrates text and video achieves the best results.
5
『Multi-Modal News Summarization』
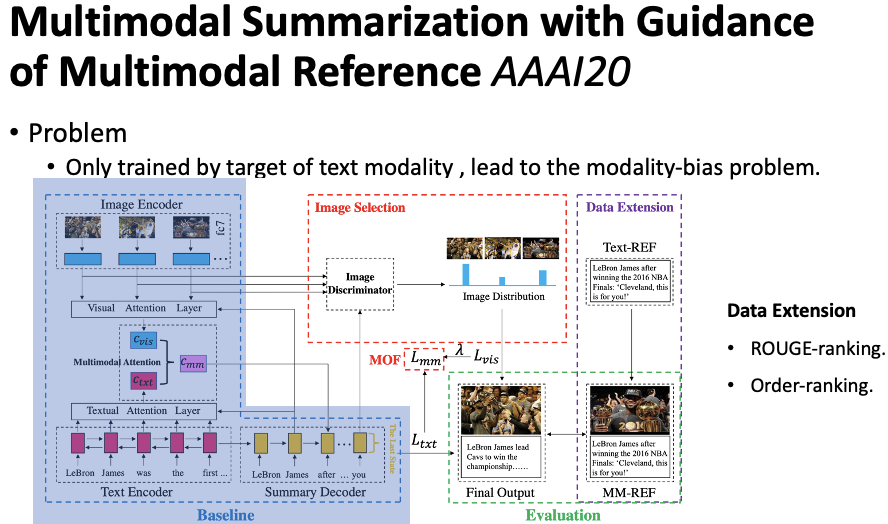
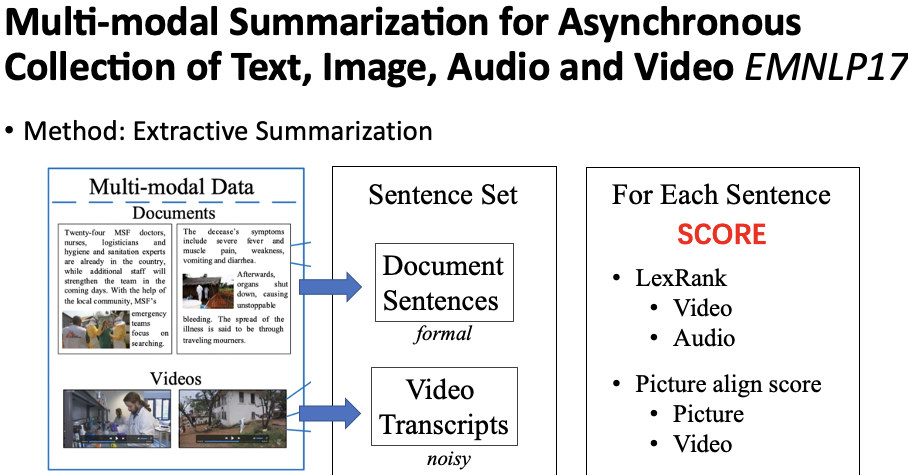
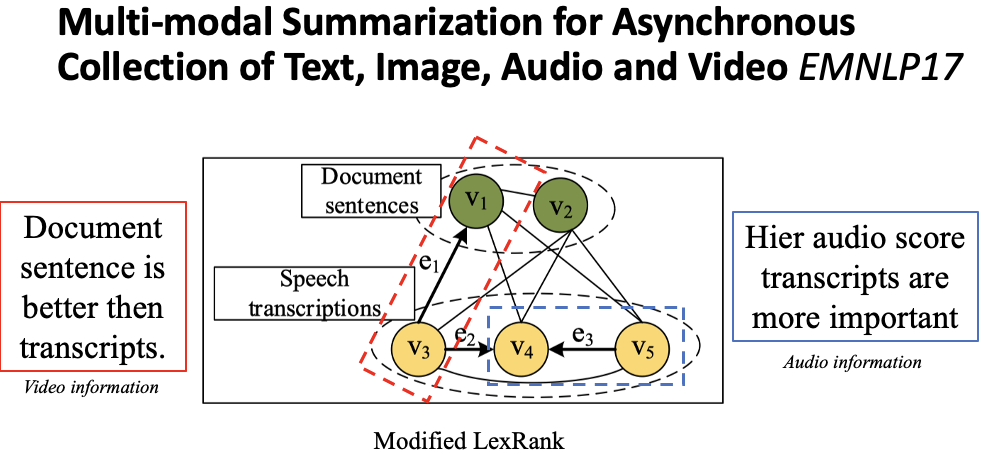
This section introduces the task of multi-modal news summarization.Figure 9 Extractive Multi-Modal News SummarizationLi et al., 2017[6] proposed an extractive multi-modal summarization method. The goal of extractive summarization is to select a subset of sentences from a collection of sentences as the final summary. For multi-modal input, this collection of sentences is divided into two parts: document sentences and video transcripts, collectively forming the sentence set, as shown in Figure 9. The core of the extractive method is to score each sentence. The simplest approach is to use similarity-based methods such as TextRank and LexRank to score each sentence. However, with the introduction of multi-modal information, we can improve upon these methods.Figure 10 Improved LexRankThe authors incorporated video and audio features into LexRank, modifying some undirected edges in the LexRank algorithm to directed edges, as shown in Figure 10. For video features, the authors believe that when the similarity between a sentence in a document and a transcript sentence is high, the document sentence is preferred, as document sentences tend to be cleaner and more organized, while transcripts may contain more noise. Therefore, the similarity calculation is directional. For example, when v1 and v3 have high similarity, the weight is transferred from the transcript to the document sentence, which increases the score of the document sentence. For audio features, the authors note that transcript sentences have corresponding audio features, such as acoustic confidence, audio, and volume. When a transcript sentence has a high audio score, it should be selected more. Thus, when two adjacent transcript sentences have one high and one low audio score, the lower scoring sentence passes its similarity weight to the higher scoring sentence. By incorporating video and audio features, each sentence will have a score.Figure 11 Image-Text Matching ScoreThe authors’ second hypothesis is that if the document provides images, those images should contain useful information, so sentences aligned with the images should score higher. As shown in Figure 11, when an image describes “imported frozen shrimp,” the sentence in the upper right corner should be selected for the final summary. In addition to images in the document, key frames will also be extracted from the video, generally one image per scene. By utilizing images and key video frames, an external tool is used to align images and sentences. Ultimately, each sentence can obtain an aligned score. The final summary sentence selection combines the improved LexRank score with the image-text matching score.Figure 12 Multi-Modal Sentence SummaryLi et al., 2018[7] proposed a multi-modal sentence summarization task, where the input is a sentence and an image, and the output is a sentence summary, as shown in Figure 12. They constructed a task dataset by retrieving the top 5 related images for each sentence from the existing Gigaword English dataset and manually selecting the most appropriate one. The final dataset is divided into train, valid, and test sets of 62000, 2000, and 2000 respectively. Since the images are not originally included in the dataset, the externally obtained images may introduce some noise.Figure 13 Multi-Modal Sentence Summarization Model
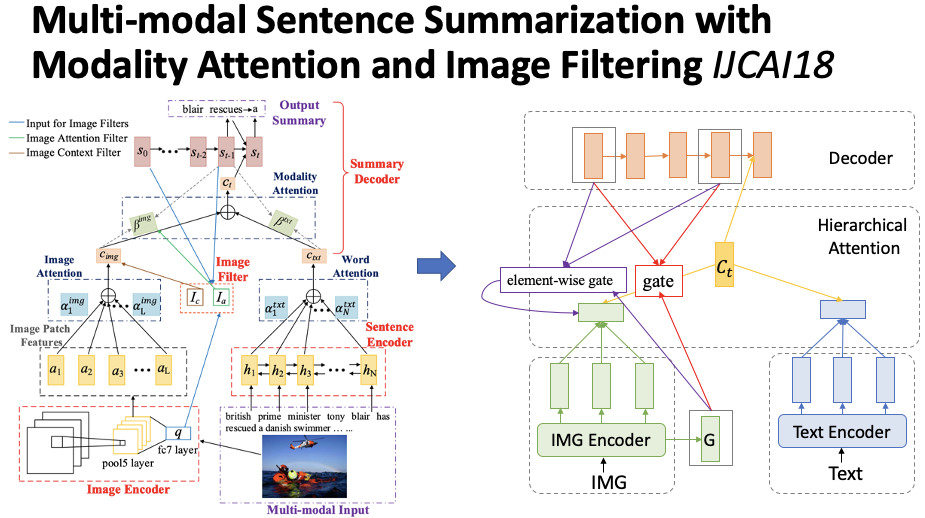
The core of the authors’ proposed model focuses on how to filter out noise from images. The core of the model includes three parts, as shown in Figure 13: a sentence encoder, an image encoder, and a decoder. The sentence encoder is a bidirectional GRU, and the image encoder is VGG, which will obtain a sequence of hidden layer representations. During decoding, the hierarchical attention mechanism is used to fuse the attention vectors from both modalities to generate the summary. This is the basic part of the model. Additionally, to filter out image noise, the authors propose two filtering mechanisms: (1) The first mechanism acts on the weights of the image attention vector, effectively acting as a gate. A number between 0 and 1 is calculated from the global representation of the image, the initial state of the decoder, and the current state of the decoder to further update the weights. (2) The second mechanism acts on the image attention vector, utilizing the outputs from the three components to compute a vector where each part is a number between 0 and 1, which is used to filter the image information. The experiments revealed that the first method yielded better results.
6
『Multi-Modal Input-Output Summarization』
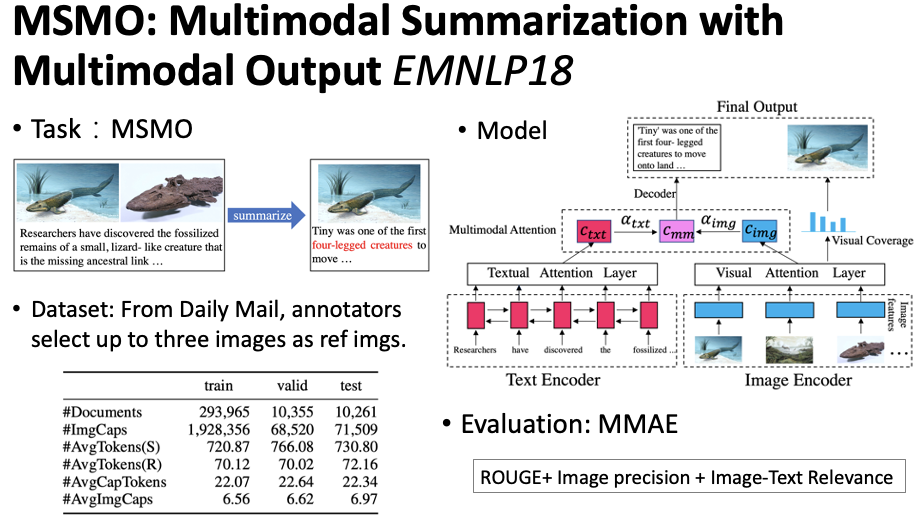
This section introduces relevant work on multi-modal input-output summarization (Multimodal Summarization with Multimodal Output, MSMO).Figure 14 MSMO Multi-Modal SummarizationThis work was published by Professor Zhang Jiajun’s group at EMNLP18, Zhu et al., 2018[8]. The authors proposed a new multi-modal summarization task where the input is multi-modal and the output is also multi-modal. Specifically, it involves inputting text along with several related images, producing a corresponding summary, and selecting the most important image from the input images, as shown in Figure 14. The proposed model architecture is similar to previous ones, including a text encoder, image encoder, decoder, and hierarchical attention mechanism. Due to the task’s characteristics, which require selecting the most important image from the input images, the authors designed a Visual Coverage mechanism to achieve this, which will be detailed further below. Additionally, to assess the final summary’s effectiveness, they proposed a multi-modal evaluation metric (MMAE), where ROUGE is used for text, image precision indicates whether the selected image is among the standard images (0 or 1), and image-text relevance calculates the matching score between the final summary and the selected image using an external tool, finally combining these three scores using logistic regression. To accomplish this task, the authors constructed a relevant dataset using the existing Daily Mail dataset to obtain the original corresponding images, manually selecting up to three images as the standard images.Figure 15 Visual Coverage MechanismAs shown in Figure 15, a simple example of the Visual Coverage mechanism is displayed. At each decoding step, an attention distribution is generated for different images. When generating the entire text, the attention scores from all previous steps are accumulated, and the image with the highest cumulative score is selected as the final image.Figure 16 Introducing Multi-Modal Supervision Signals in MSMO Tasks
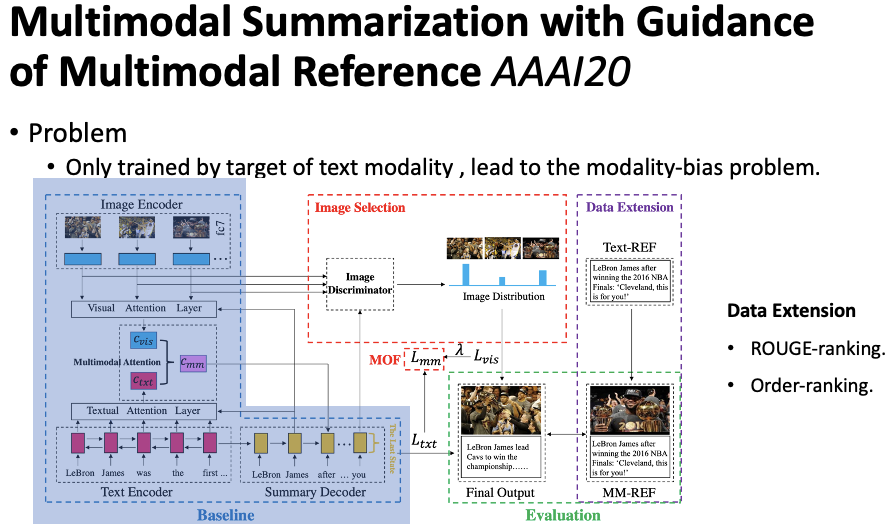
Building on the previous work, Zhu et al., 2020[9] argued that prior summarization models relied solely on text annotations for training, neglecting the utilization of image annotations. This work incorporates not only the text loss during summary generation but also the classification loss for image selection, as shown in Figure 16. Specifically, after obtaining the global representation of each image, the similarity with the last hidden state of the decoder is computed, and the probability is normalized to select the image. However, the current dataset has multiple standard annotations for images, and there is no unique image annotation. To provide supervision signals for image annotations during training, the authors proposed two methods to construct a unique annotated image: (1) ROUGE-ranking, where for each image there is a corresponding description (caption). The ROUGE score is calculated between this description and the standard text summary, and the image corresponding to the description with the highest ROUGE score is selected as the unique standard annotated image; (2) Order-ranking, where the first image in the dataset is selected based on the order of images.
7
『Multi-Modal Conference Summarization』
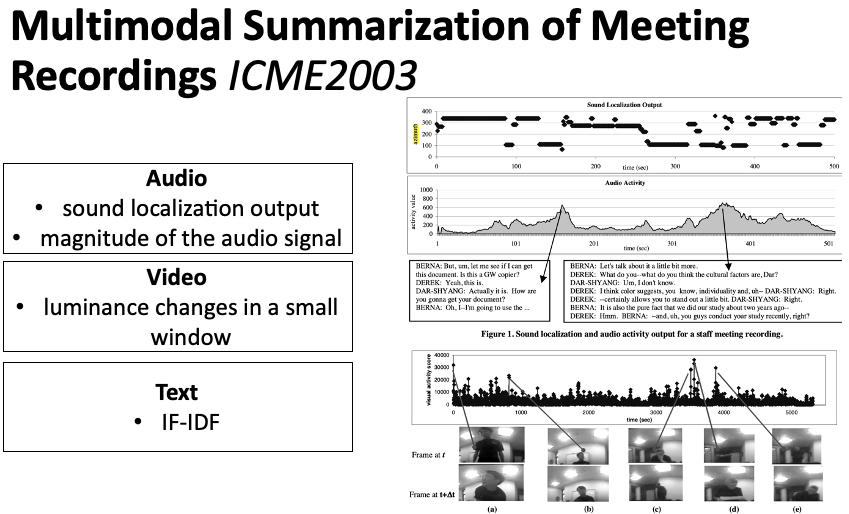
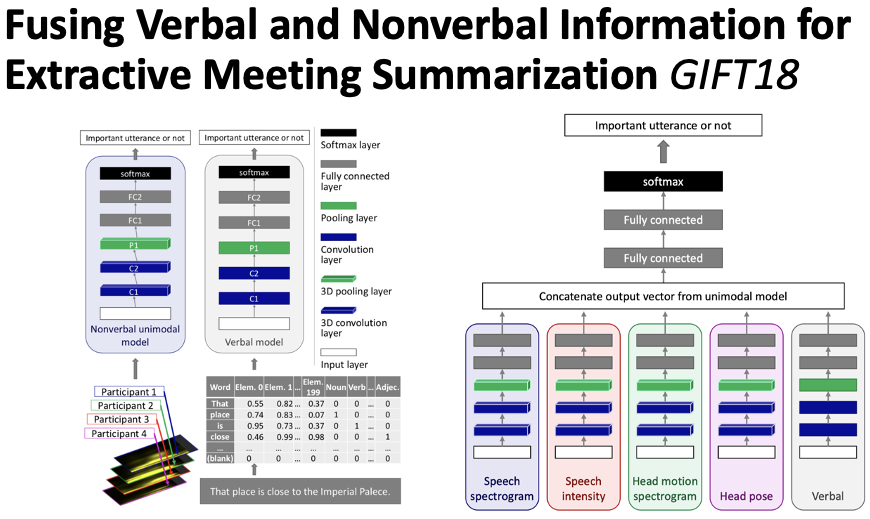
This section introduces relevant work on multi-modal conference summarization. Improving productivity through NLP, Microsoft pointed out that employees spend 37% of their work time attending meetings, with an average of 5000 words spoken in each meeting. Such frequent meetings and lengthy content place a significant burden on employees. Therefore, conference summarization can help quickly summarize meeting decision information, question information, task information, and other core content, alleviating employee pressure and improving work efficiency. However, relying solely on meeting text information is insufficient; multi-modal information, such as video and audio, can provide more comprehensive information. For example, it can reveal who joined or left the meeting, and through gestures, vocal tone, and facial expressions, it can identify whether discussions are emotional or contentious. Thus, multi-modal conference summarization has gradually gained attention.Figure 17 Multi-Modal Conference SummarizationErol et al., 2003[10] proposed utilizing multi-modal features to locate important content in meetings. As shown in Figure 17, features are established from three modalities. For audio, there are two features: the number of changes in sound direction within a time window and sound amplitude. For visual aspects, the brightness change between two adjacent frames is analyzed. For text, TF-IDF features are used. By combining these three modalities’ features, key content can be identified.Figure 18 Extractive Multi-Modal SummaryNihei et al., 2018[11] used neural networks to perform extractive conference summarization. They fused video information, action information, sound information, and text information to locate key content in meetings, as shown in Figure 18.Figure 19 Generative Multi-Modal Summary
Li et al., 2019[12] proposed integrating multi-modal features into generative conference summarization through the Visual Focus Of Attention (VFOA). The authors argue that when a participant is speaking, if others are focused on that speaker, it indicates that the sentence being stated is important. Therefore, for a sentence in the meeting, there will be corresponding videos of four participants, each consisting of a set of frames. Each frame corresponds to a five-dimensional feature, as shown in Figure 19, which is input into a neural network to predict the target the participant is currently focusing on (with standard annotations in the dataset). After training, for a sentence in the meeting, the corresponding video information from the four participants is input into the network to obtain an output, which is then concatenated to yield a VFOA feature vector for that sentence. This visual feature vector is utilized during the decoding of the meeting summary.
8
『Conclusion』
This article briefly introduces relevant work on multi-modal summarization from the perspective of task classification. Despite the progress made in multi-modal summarization, several key points still warrant serious consideration:(1) Existing model structures are simple. Current model architectures primarily consist of sequence-to-sequence models combined with hierarchical attention mechanisms, with different works making slight modifications based on task characteristics. To more effectively integrate multi-modal information and leverage the complementary nature of modal information, more suitable architectures should be considered based on the current frameworks.(2) There is limited interaction between different modal information. The core of current work on modality fusion relies on hierarchical attention mechanisms, and beyond this, there is a lack of explicit methods for interaction between different modalities, which prevents fully harnessing the complementary relationships between modal information.(3) There is a reliance on manual prior knowledge. Generally, it is necessary to manually select different types of pre-trained feature extraction models for feature extraction, a process that heavily depends on human judgment to pre-determine effective features, requiring a certain level of domain expertise.(4) Data privacy considerations are minimal. While multi-modal data provide richer information, they also pose certain challenges for data confidentiality. For example, in multi-modal meeting data, features such as voiceprints and facial characteristics are critical personal privacy information. Therefore, data privacy issues must be thoroughly considered in practical implementations.(5) Single text outputs lack diversity. Current work has begun to explore multi-modal input-output, where the output summary contains multiple modalities, meeting the needs of a broader audience. For instance, when language proficiency is low, one can quickly grasp important content through videos and images. In the future, multi-modal summarization outputs will also become an important research focus.Overall, in the context of the rapid development of multi-modal technologies, multi-modal summarization, as a branch, not only shares common issues with multi-modal learning but also possesses unique challenges pertaining to summarization tasks. This task has seen vigorous development in recent years and is expected to become an important research direction in the future.
References
[1] Jindřich Libovický and Jindřich Helcl. Attention strategies for multi-source sequence-to-sequence learning. ACL 2017. https://www.aclweb.org/anthology/P17-2031[2] Yansen Wang, Ying Shen, Zhun Liu, P. P. Liang, Amir Zadeh, and Louis-Philippe Morency. Words can shift: Dynamically adjusting word representations using nonverbal behaviors. AAAI 2019.[3] Gen Li, N. Duan, Yuejian Fang, Daxin Jiang, and M. Zhou. Unicoder-vl: A universal encoder for vision and language by cross-modal pre-training. AAAI 2020.[4] R. Sanabria, Ozan Caglayan, Shruti Palaskar, Desmond Elliott, Loïc Barrault, Lucia Specia, and F. Metze. How2: A large-scale dataset for multimodal language understanding. NeurIPS 2018.[5] Shruti Palaskar, Jindřich Libovický, Spandana Gella, and F. Metze. Multimodal abstractive summarization for how2 videos. ACL 2019.[6] Haoran Li, Junnan Zhu, C. Ma, Jiajun Zhang, and C. Zong. Multi-modal summarization for asynchronous collection of text, image, audio and video. 2017.[7] Haoran Li, Junnan Zhu, Tianshang Liu, Jiajun Zhang, and C. Zong. Multi-modal sentence summarization with modality attention and image filtering. IJCAI 2018.[8] Junnan Zhu, Haoran Li, Tianshang Liu, Y. Zhou, Jiajun Zhang, and C. Zong. Msmo: Multimodal summarization with multimodal output. EMNLP 2018.[9] Junnan Zhu, Yin qing Zhou, Jiajun Zhang, Haoran Li, Chengqing Zong, and Changliang Li. Multimodal summarization with guidance of multimodal reference. AAAI 2020.[10] B. Erol, Dar-Shyang Lee, and J. Hull. Multimodal summarization of meeting recordings. ICME 2003.[11] Fumio Nihei, Yukiko I. Nakano, and Yutaka Takase. Fusing verbal and nonverbal information for extractive meeting summarization. GIFT 2018.[12] Manling Li, L. Zhang, H. Ji, and R. Radke. Keep meeting summaries on topic: Abstractive multimodal meeting summarization. ACL 2019.Technical Communication Group Invitation
△ Long press to add assistant
Scan the QR code to add the assistant’s WeChat
Please note: Name-School/Company-Research Direction(e.g., Xiao Zhang-Harbin Institute of Technology-Dialogue Systems)to apply to join the Natural Language Processing/Pytorch technical communication group
About Us
MLNLP Community ( Machine Learning Algorithms and Natural Language Processing ) is a civil academic community jointly constructed by natural language processing scholars from home and abroad. It has now developed into a well-known natural language processing community both domestically and internationally, including well-known brands such as Ten Thousand People Top Conference Communication Group, AI Selection, AI Talent Exchange, and AI Academic Exchange , aiming to promote progress among the academic and industrial communities of machine learning and natural language processing.The community can provide an open communication platform for related practitioners’ further education, employment, and research. Everyone is welcome to follow and join us.